【运维实战】系统全链路监测方案~架构到实践
在企业数字化转型进程中,内部系统日趋复杂,服务间调用关系错综复杂。一旦出现故障,传统监测方式往往难以快速定位根源,严重影响业务连续性。本文将分享一套适用于企业内部系统的全链路监测方案,涵盖架构设计、核心组件选型、实施流程等关键内容,助力企业实现系统运行状态的全面掌控。
一、方案概述
1.1 背景与分析
随着企业业务的快速发展,内部系统逐渐形成由多个服务、组件构成的复杂生态。当前多数企业的监测体系存在明显局限:仅能覆盖基础设施和部分中间件的基础指标,缺乏对业务全链路的端到端追踪。当用户请求出现延迟或失败时,运维人员需在多系统间逐一排查,效率低下,难以满足业务对稳定性和可靠性的高要求。
现有监测能力的短板主要体现在:
- 支撑组件监测不全面:数据库、Web 服务中间件、大数据组件等关键节点的深度指标缺失;
- 应用服务调用链断裂:缺乏全局唯一标识关联各服务节点,无法追踪请求流转路径;
- 日志与指标脱节:业务日志与性能指标未形成联动,难以通过日志定位性能问题。
1.2 方案目标
- 实现企业内部系统全链路实时监测,覆盖从用户请求到后端处理的完整路径,及时发现性能瓶颈与故障隐患;
- 建立统一的调用链追踪机制,通过全局唯一标识关联各服务节点,实现问题的精准定位;
- 打通日志、指标、追踪数据,为性能优化和资源调整提供数据支撑;
- 构建完善的告警体系,确保异常情况能被及时感知并处理;
- 满足企业服务等级目标(SLS)和服务等级协议(SLA)的监测需求。
1.3 适用范围
方案主要适用于企业内部各类应用服务的全链路监测,包括:
- 前端用户请求至后端处理的完整链路(含网关、应用服务、数据库、中间件等节点);
- 核心业务服务:网关服务、平台服务、内部系统、第三方支撑系统等;
- 支撑服务运行的关键组件:各类网关、数据库、消息中间件、缓存、大数据组件等。
二、全链路监测核心设计
2.1 监测链路设计
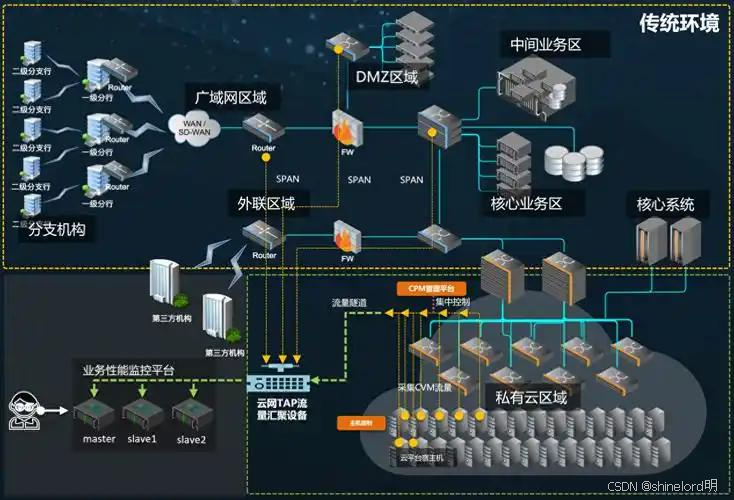
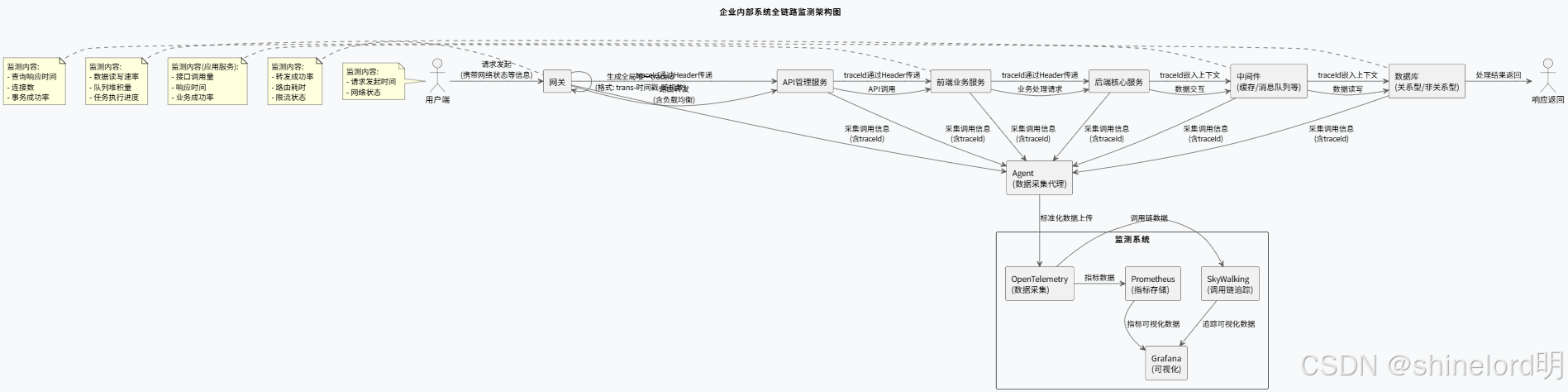
企业内部系统的全链路监测需覆盖从用户请求发起至响应返回的完整路径,核心链路为:
用户端→网关→API 管理服务→前端业务服务→后端核心服务→中间件→数据库→响应返回
各节点的关键监测内容如下:
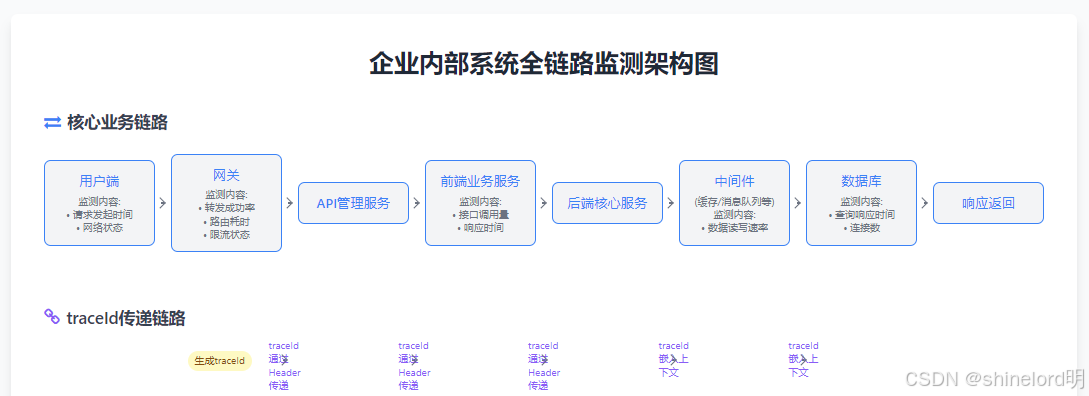
- 用户端:记录请求发起时间、网络状态等基础信息;
- 网关:负责请求路由与负载均衡,监测转发成功率、路由耗时、限流状态;
- 应用服务:包括前端交互服务和后端业务服务,监测接口调用量、响应时间、业务成功率;
- 中间件:涵盖缓存、消息队列、大数据处理组件等,监测数据读写速率、队列堆积量、任务执行进度;
- 数据库:包括关系型、非关系型及缓存数据库,监测查询响应时间、连接数、事务成功率。
2.2 调用链追踪机制
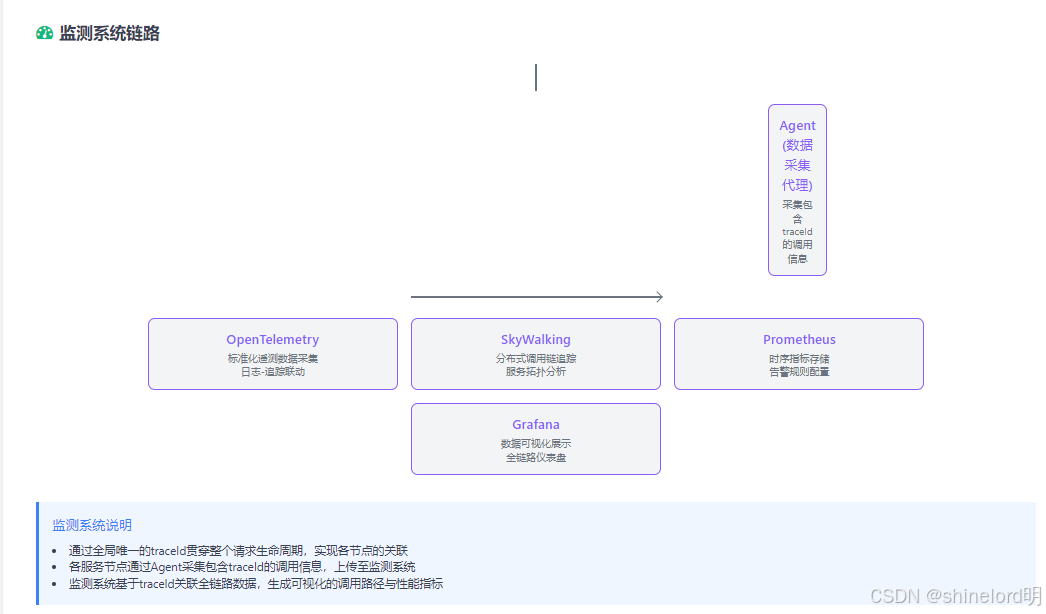
调用链追踪是全链路监测的核心,通过全局唯一的 traceId 贯穿整个请求生命周期,实现各节点的关联。其核心流程如下:
用户请求进入网关时,由网关生成全局唯一的 traceId(格式示例:trans - 时间戳 - 随机数);
traceId 通过请求 Header 在服务间传递,涵盖 API 调用、数据库操作、中间件交互等场景;
各服务节点通过 Agent 采集包含 traceId 的调用信息,上传至监测系统;
监测系统基于 traceId 关联全链路数据,生成可视化的调用路径与性能指标。
三、监测指标体系
3.1 整体监测指标
指标类别 | 具体指标 | 数据类型 | 说明 |
可用性指标 | 全链路可用性 | 百分比型 | 成功请求数 / 总请求数,目标≥99.9% |
性能指标 | 平均响应时间 | 时间型(ms) | 全链路请求处理平均耗时,目标≤500ms |
性能指标 | 95% 响应时间 | 时间型(ms) | 95% 的请求处理耗时,目标≤1000ms |
错误指标 | 全链路错误率 | 百分比型 | 错误请求数 / 总请求数,目标≤0.1% |
稳定性指标 | 服务中断时长 | 时间型(min) | 月度累计中断时长,目标≤5min |
3.2 节点监测指标
针对链路中各关键节点,需设置专项监测指标:
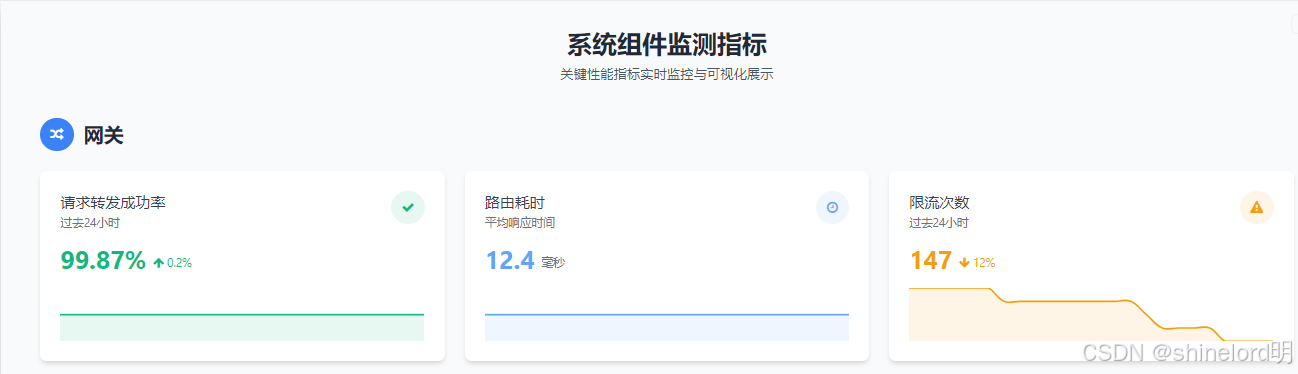
- 网关:请求转发成功率、路由耗时、限流次数;
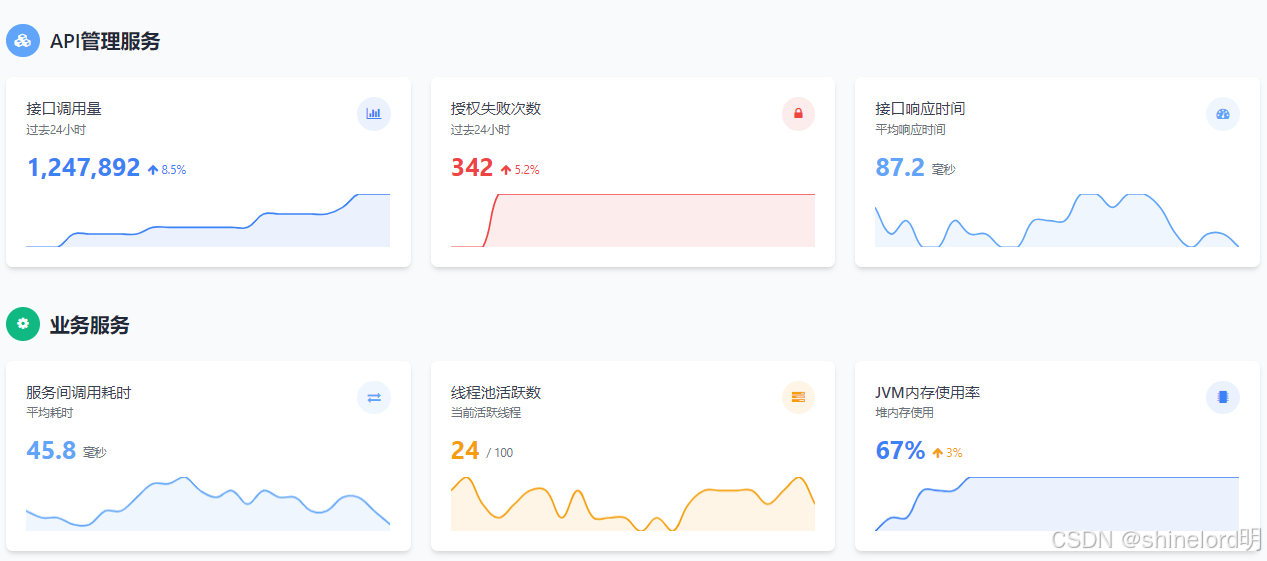
- API 管理服务:接口调用量、授权失败次数、接口响应时间;
- 业务服务:服务间调用耗时、线程池活跃数、JVM 内存使用率;
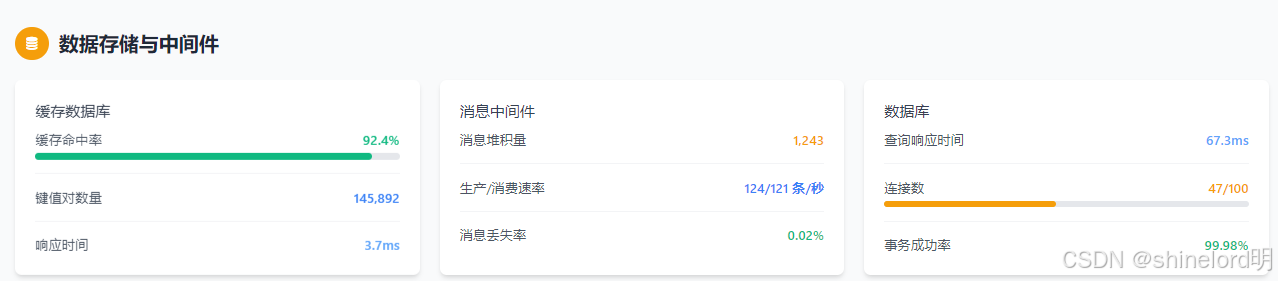
- 缓存数据库:缓存命中率、键值对数量、响应时间;
- 消息中间件:消息堆积量、生产 / 消费速率、消息丢失率;
- 数据库:查询响应时间、连接数、事务成功率。
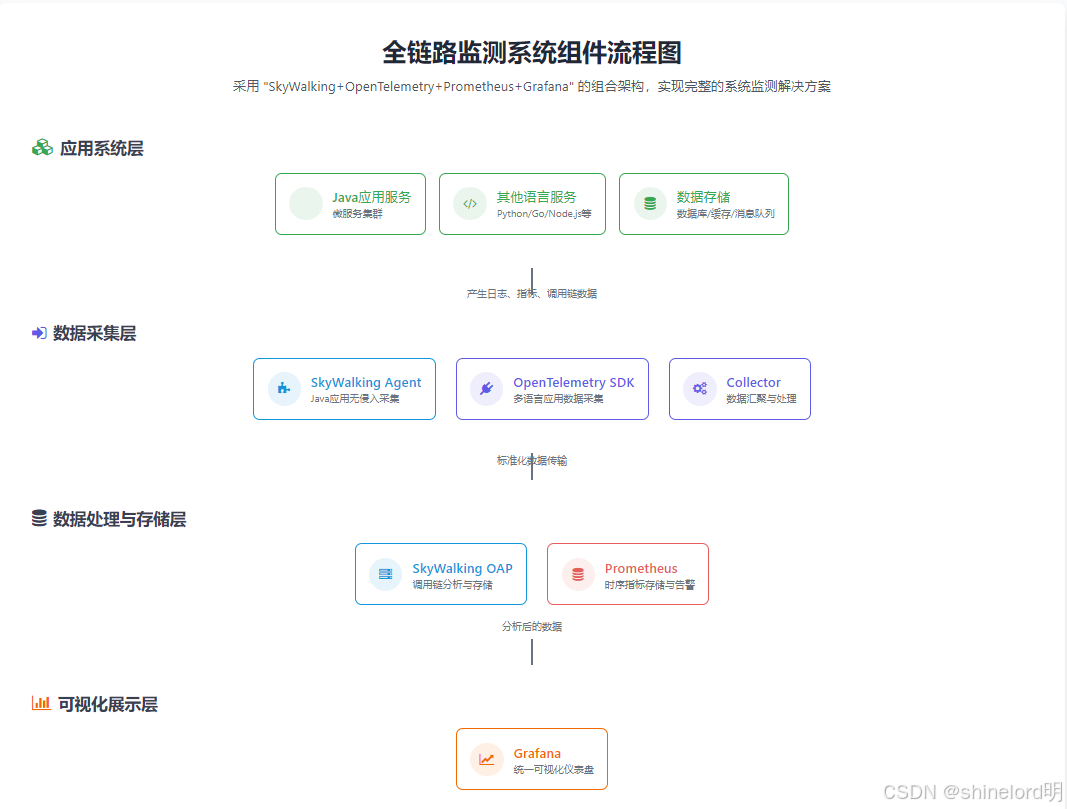
四、主要组件选型
4.1 组件功能对比
企业内部系统的全链路监测需结合多种工具,形成协同能力:
组件 | 功能描述 | 优势 | 适用场景 |
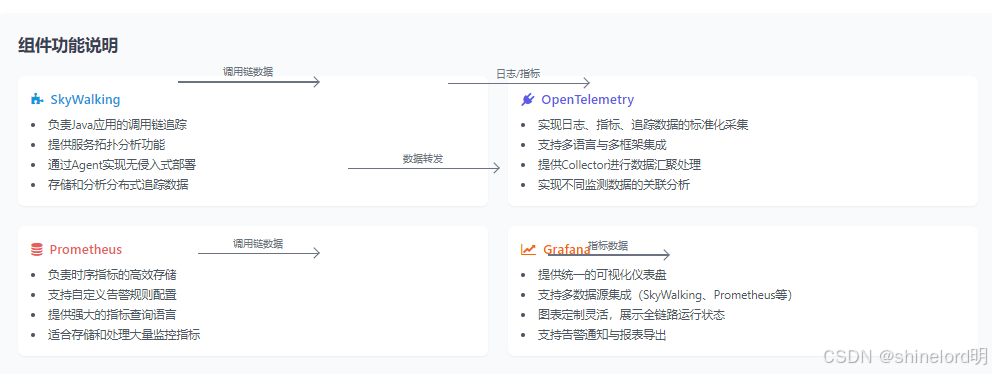
SkyWalking | 分布式追踪系统,支持调用链追踪与性能分析 | 对 Java 系统支持完善,无侵入式部署 | 内部自研 Java 系统的调用链追踪 |
OpenTelemetry | 标准化遥测数据采集工具集 | 兼容多语言与多框架,支持日志 - 追踪联动 | 全链路数据的统一采集与关联 |
Prometheus | 时序指标采集与存储系统 | 指标处理能力强,支持自定义告警 | 各类系统的性能指标监测 |
Grafana | 数据可视化工具 | 支持多数据源集成,图表定制灵活 | 监测数据的可视化展示 |
4.2 推荐组合方案
采用 “SkyWalking+OpenTelemetry+Prometheus+Grafana” 的组合架构:
- SkyWalking 负责 Java 应用的调用链追踪与服务拓扑分析;
- OpenTelemetry 实现日志、指标、追踪数据的标准化采集与关联;
- Prometheus 负责时序指标的存储与告警规则配置;
- Grafana 提供统一的可视化仪表盘,展示全链路运行状态。
java举例:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>monitoring-demo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><opentelemetry.version>1.30.0</opentelemetry.version><spring.boot.version>2.7.15</spring.boot.version></properties><dependencies><!-- Spring Boot Web --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>${spring.boot.version}</version></dependency><!-- OpenTelemetry 自动配置 --><dependency><groupId>io.opentelemetry.instrumentation</groupId><artifactId>opentelemetry-spring-boot-starter</artifactId><version>${opentelemetry.version}</version></dependency><!-- OpenTelemetry exporters --><dependency><groupId>io.opentelemetry</groupId><artifactId>opentelemetry-exporter-otlp</artifactId><version>${opentelemetry.version}</version></dependency><!-- Micrometer Prometheus 集成 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId><version>${spring.boot.version}</version></dependency><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId><version>1.9.13</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring.boot.version}</version></plugin></plugins></build>
</project># 服务端口
server.port=8080
# OpenTelemetry 配置
opentelemetry.resource.attributes.service.name=java-monitoring-demo
opentelemetry.traces.exporter=otlp
opentelemetry.metrics.exporter=otlp
opentelemetry.logs.exporter=otlp
opentelemetry.exporter.otlp.endpoint=http://localhost:4317
# actuator与Prometheus配置
management.endpoints.web.exposure.include=health,prometheus
management.endpoint.prometheus.enabled=true
management.metrics.export.prometheus.enabled=true
management.metrics.tags.application=${spring.application.name:java-monitoring-demo}
package com.example;import io.opentelemetry.api.trace.Span;
import io.opentelemetry.api.trace.Tracer;
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.actuate.autoconfigure.metrics.MeterRegistryCustomizer;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.Random;@SpringBootApplication
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}// 自定义Prometheus指标@BeanMeterRegistryCustomizer<MeterRegistry> metricsCommonTags() {return registry -> registry.config().commonTags("application", "monitoring-demo");}@RestControllerclass DemoController {private final Tracer tracer;private final Counter requestCounter;private final Random random = new Random();@Autowiredpublic DemoController(Tracer tracer, MeterRegistry registry) {this.tracer = tracer;this.requestCounter = Counter.builder("demo.requests").description("Number of requests to demo endpoint").register(registry);}@GetMapping("/api/demo")public String demo() {// 记录请求计数requestCounter.increment();// 创建自定义追踪 spanSpan span = tracer.spanBuilder("demo-processing").startSpan();span.makeCurrent();try {// 模拟处理时间Thread.sleep(random.nextInt(200));// 添加自定义属性span.setAttribute("user_id", "test-user-123");span.setAttribute("processing_time", System.currentTimeMillis());return "Demo response from Java service";} catch (InterruptedException e) {span.recordException(e);Thread.currentThread().interrupt();return "Error processing request";} finally {span.end(); // 结束span}}}
}
docker:
version: '3.8'services:# SkyWalking OAP 服务器skywalking-oap:image: apache/skywalking-oap-server:9.7.0container_name: skywalking-oapports:- "12800:12800" # gRPC- "11800:11800" # HTTPenvironment:- SW_STORAGE=h2- SW_CORE_REST_PORT=12800- SW_CORE_GRPC_PORT=11800restart: always# SkyWalking UIskywalking-ui:image: apache/skywalking-ui:9.7.0container_name: skywalking-uiports:- "8080:8080"environment:- SW_OAP_ADDRESS=http://skywalking-oap:12800depends_on:- skywalking-oaprestart: always# OpenTelemetry Collectorotel-collector:image: otel/opentelemetry-collector:0.85.0container_name: otel-collectorports:- "4317:4317" # gRPC receiver- "4318:4318" # HTTP receivervolumes:- ./otel-collector-config.yaml:/etc/otelcol/config.yamldepends_on:- skywalking-oap- prometheusrestart: always# Prometheusprometheus:image: prom/prometheus:v2.45.0container_name: prometheusports:- "9090:9090"volumes:- ./prometheus.yml:/etc/prometheus/prometheus.ymlrestart: always# Grafanagrafana:image: grafana/grafana:9.5.10container_name: grafanaports:- "3000:3000"environment:- GF_SECURITY_ADMIN_PASSWORD=adminvolumes:- grafana-data:/var/lib/grafanadepends_on:- prometheus- skywalking-oaprestart: alwaysvolumes:grafana-data:
nodejs:
const express = require('express');
const { OTLPTraceExporter } = require('@opentelemetry/exporter-trace-otlp-grpc');
const { Resource } = require('@opentelemetry/resources');
const { SemanticResourceAttributes } = require('@opentelemetry/semantic-conventions');
const { SimpleSpanProcessor } = require('@opentelemetry/sdk-trace-base');
const { TracerProvider } = require('@opentelemetry/sdk-trace-node');
const { trace } = require('@opentelemetry/api');
const { expressInstrumentation } = require('@opentelemetry/instrumentation-express');
const { NodeTracerProvider } = require('@opentelemetry/sdk-trace-node');
const { registerInstrumentations } = require('@opentelemetry/instrumentation');
const promClient = require('prom-client');// 初始化Prometheus指标注册表
const register = new promClient.Registry();
promClient.collectDefaultMetrics({ register });// 创建自定义Prometheus指标
const requestCounter = new promClient.Counter({name: 'nodejs_request_count',help: 'Total number of requests',labelNames: ['endpoint', 'method']
});const requestLatency = new promClient.Histogram({name: 'nodejs_request_latency_seconds',help: 'Request latency in seconds',labelNames: ['endpoint', 'method'],buckets: [0.1, 0.3, 0.5, 0.7, 1, 3, 5]
});// 注册指标
register.registerMetric(requestCounter);
register.registerMetric(requestLatency);// 配置OpenTelemetry
const resource = new Resource({[SemanticResourceAttributes.SERVICE_NAME]: 'nodejs-monitoring-demo',
});const traceExporter = new OTLPTraceExporter({url: 'http://localhost:4317',
});const provider = new NodeTracerProvider({ resource });
provider.addSpanProcessor(new SimpleSpanProcessor(traceExporter));
provider.register();const tracer = trace.getTracer('nodejs-demo-tracer');// 初始化Express应用
const app = express();
const port = 8082;// 注册OpenTelemetry instrumentation
registerInstrumentations({tracerProvider: provider,instrumentations: [expressInstrumentation({requestHook: (span, request) => {span.setAttribute('custom-attribute', 'request');},}),],
});// Prometheus指标端点
app.get('/metrics', async (req, res) => {res.set('Content-Type', register.contentType);res.end(await register.metrics());
});// 业务端点
app.get('/api/nodejs-demo', async (req, res) => {const end = requestLatency.startTimer({ endpoint: '/api/nodejs-demo', method: 'GET' });requestCounter.inc({ endpoint: '/api/nodejs-demo', method: 'GET' });// 创建自定义spanconst span = tracer.startSpan('nodejs-demo-processing');try {// 模拟处理时间const processingTime = Math.random() * 200 + 50; // 50-250msawait new Promise(resolve => setTimeout(resolve, processingTime));// 添加自定义属性span.setAttribute('user_agent', req.headers['user-agent'] || 'unknown');span.setAttribute('processing_time_ms', processingTime);res.send('Demo response from Node.js service');} catch (error) {span.recordException(error);span.setStatus({ code: trace.SpanStatusCode.ERROR });res.status(500).send('Error processing request');} finally {span.end();end();}
});// 启动服务器
app.listen(port, () => {console.log(`Node.js demo app listening at http://localhost:${port}`);console.log('Metrics available at http://localhost:8082/metrics');
});
ptyon代码:
from flask import Flask, request
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.resources import SERVICE_NAME, Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.instrumentation.flask import FlaskInstrumentor
import prometheus_client
from prometheus_client import Counter, Histogram
import time
import random# 初始化Prometheus指标
REQUEST_COUNT = Counter('python_request_count', 'Total number of requests',['endpoint', 'method']
)
REQUEST_LATENCY = Histogram('python_request_latency_seconds', 'Request latency in seconds',['endpoint', 'method']
)# 配置OpenTelemetry
resource = Resource(attributes={SERVICE_NAME: "python-monitoring-demo"
})provider = TracerProvider(resource=resource)
processor = BatchSpanProcessor(OTLPSpanExporter(endpoint="http://localhost:4317"))
provider.add_span_processor(processor)
trace.set_tracer_provider(provider)tracer = trace.get_tracer(__name__)# 初始化Flask应用
app = Flask(__name__)
FlaskInstrumentor().instrument_app(app)@app.route('/api/python-demo')
@REQUEST_LATENCY.labels(endpoint='/api/python-demo', method='GET').time()
def python_demo():# 增加请求计数REQUEST_COUNT.labels(endpoint='/api/python-demo', method='GET').inc()# 创建自定义追踪spanwith tracer.start_as_current_span("python-demo-processing") as span:# 添加自定义属性user_agent = request.headers.get('User-Agent', 'unknown')span.set_attribute("http.user_agent", user_agent)# 模拟处理时间processing_time = random.uniform(0.05, 0.3)time.sleep(processing_time)span.set_attribute("processing_time_ms", processing_time * 1000)return "Demo response from Python service"if __name__ == '__main__':# 启动Prometheus指标暴露服务prometheus_client.start_http_server(8000)# 启动Flask应用app.run(host='0.0.0.0', port=8081)
五、日志规范与 traceId 设计
5.1 日志格式规范
应用系统日志需采用 JSON 格式,包含以下必填字段:
{
"timestamp": "2025-08-07 14:30:22.123","level": "INFO","serviceName": "order-service","traceId": "trans-1628325022123-789","message": "订单ID:12345处理成功,耗时:200ms","threadName": "http-nio-8080-exec-1","extJson": "业务类型:线上订单"}关键业务节点(请求接收、外部调用、数据库操作、异常抛出等)必须输出日志,错误日志需包含完整堆栈信息,便于问题定位。
5.2 traceId 生成与传递
推荐采用 “后端生成(网关层)+ 前端关联” 的方案:
- 网关在请求入口处生成 traceId,通过 Header 传递至下游服务;
- 服务间调用(如 Feign)通过拦截器自动携带 traceId;
- 数据库操作、中间件调用时,将 traceId 嵌入请求上下文;
- 前端如需关联,可从响应 Header 中获取 traceId 并记录至前端日志。
该方案既能确保后端链路的完整覆盖,又能实现前后端日志的联动分析,且对业务代码侵入性低。
六、系统接入流程
6.1 接入步骤
- 基础设施与组件准备:部署 SkyWalking、OpenTelemetry、Prometheus、Grafana 等组件,配置持久化存储与资源限制;
- 应用服务改造:
部署 SkyWalking Agent 至各 Java 服务,配置服务名称与 Collector 地址;
引入 OpenTelemetry SDK,实现日志与追踪数据的关联;
暴露业务指标至 Prometheus,配置自定义监测项;
- 日志与 traceId 适配:按规范改造应用日志输出格式,确保 traceId 在全链路传递;
告警规则配置:在 Prometheus 中设置指标阈值告警,在 SkyWalking 中配置调用链异常告警;
可视化仪表盘搭建:在 Grafana 中创建全链路监测面板,包含服务拓扑、响应时间趋势、错误率等关键指标。
6.2 阶段目标
阶段 | 核心任务 | 输出成果 |
第一阶段 | 完善基础设施与组件监测 | 完成 Prometheus 配置,Grafana 基础设施面板可用 |
第二阶段 | 部署调用链追踪系统 | 实现核心服务的调用链追踪,traceId 传递正常 |
第三阶段 | 集成日志与指标数据 | 日志与调用链关联查询功能可用 |
第四阶段 | 优化告警与可视化 | 全链路监测仪表盘上线,告警机制生效 |
七、风险与应对措施
- 技术风险:组件间集成可能存在兼容性问题。应对措施:搭建 POC 环境进行兼容性测试,优先选择社区成熟的集成方案;
- 性能风险:Agent 采集数据可能影响应用性能。应对措施:在测试环境评估性能损耗,根据结果调整采集频率与指标范围;
- 进度风险:多系统改造同步推进难度大。应对措施:按业务优先级分批接入,优先覆盖核心服务。
八、总结
全链路监测是保障企业内部系统稳定运行的关键手段,通过构建 “追踪 - 指标 - 日志” 三位一体的监测体系,可实现从问题发现到根源定位的全流程高效处理。方案的成功实施需业务、开发、运维团队协同配合,结合企业实际场景持续优化监测指标与告警策略,最终实现系统可靠性与运维效率的双重提升。