(Arxiv-2025)OPENS2V-NEXUS:一个面向主体到视频生成的详细基准与百万规模数据集
OPENS2V-NEXUS:一个面向主体到视频生成的详细基准与百万规模数据集
paper title:OPENS2V-NEXUS: A Detailed Benchmark and Million-Scale Dataset for Subject-to-Video Generation
paper是PKU发布在Arxiv 2025的工作
Code:链接
Abstract
主体到视频(Subject-to-Video, S2V)生成旨在创建能够忠实融入参考内容的视频,从而在视频制作中提供更高的灵活性。为建立S2V生成的基础设施,我们提出了OPENS2V-NEXUS,它由 (i) OpenS2V-Eval,一个细粒度基准,以及 (ii) OpenS2V-5M,一个百万规模数据集组成。与现有从VBench [36]继承而来的S2V基准不同,这些基准更关注生成视频的全局和粗粒度评估,而OpenS2V-Eval专注于模型生成主体一致性视频的能力,要求主体外观自然并保持身份一致性。为此,OpenS2V-Eval引入了来自S2V七大类别的180个提示,涵盖真实和合成测试数据。此外,为了更准确地将人类偏好与S2V基准对齐,我们提出了三个自动化指标:NexusScore、NaturalScore和GmeScore,分别用于量化生成视频中的主体一致性、自然性和文本相关性。在此基础上,我们对18个具有代表性的S2V模型进行了全面评估,展示了它们在不同内容上的优势和不足。同时,我们创建了首个开源的大规模S2V生成数据集OpenS2V-5M,该数据集包含500万条高质量的720P主体-文本-视频三元组。具体而言,我们通过以下方式确保数据集中主体信息的多样性:(1) 对主体进行分割,并通过跨视频关联构建配对信息;(2) 在原始帧上调用GPT-Image来合成多视角表示。通过OPENS2V-NEXUS,我们提供了一个稳健的基础设施,以加速未来S2V生成研究。
1 Introduction
随着视频基础模型的发展 [50, 89, 59, 124, 41, 70, 86, 105],主体到视频(S2V)生成逐渐受到越来越多的关注,使得能够生成以参考主体为核心的视频。先前的基于微调的方法 [69, 30, 65, 24] 在推理过程中需要针对每个样本进行微调,代价高且耗时。近期,多个开源S2V模型 [123, 97, 21](如 ConsisID [113]、Phantom [55]、VACE [40]),以及部分闭源模型 [44, 5, 43, 87, 18],已经展示了无需微调的S2V生成能力。尽管这些方法表现出令人鼓舞的结果,但仍缺乏能够客观评估S2V模型优劣的基准。如表1所示,现有视频生成基准主要聚焦于文本到视频任务,典型例子包括 VBench [37] 和 ChronoMagic-Bench [115]。虽然 ConsisID-Bench [113] 可应用于S2V,但它仅限于人脸一致性的评估。Alchemist-Bench [13]、VACE-Benchmark [40] 和 A2 Bench [21] 支持开放域S2V的评估,但它们的评估主要是全局和粗粒度的。例如,它们忽略了对主体自然性的考察。此外,后两者 [40, 21] 的主体一致性度量继承自 VBench [37],其相似度是通过直接比较未裁剪的视频帧与参考图像计算的——这种方法不可避免地引入背景噪声并降低精度。
表1:我们的 OpenS2V-Eval 与现有基准的特性对比。大多数现有基准聚焦于 T2V,而忽视了对主体自然性的评估。_ 表示次优。
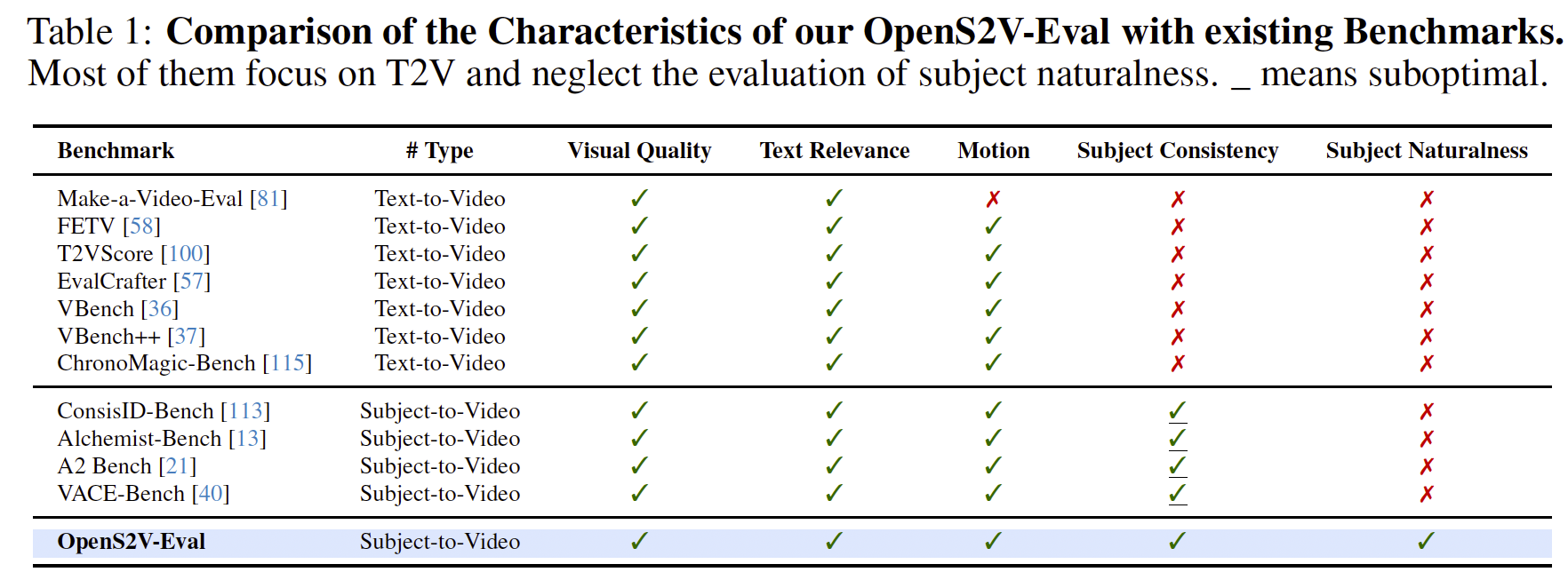
当前S2V模型面临三大挑战:(1) 泛化性差:当遇到训练过程中未见过的主体类别时,模型表现往往较差 [40, 113]。例如,仅在西方主体上训练的模型在生成亚洲主体时表现不佳;(2) 拷贝-粘贴问题:模型倾向于直接将参考图像中的姿态、光照和轮廓复制到视频中,导致结果不自然 [21];(3) 人体保真度不足:当前模型在保持人类身份一致性方面常常不如对非人类实体的保持效果 [55]。一个有效的基准应当能够识别这些问题。然而,即便生成的主体不自然或保真度较低,现有的基准 [40, 21, 121] 仍然会给出较高的分数,从而阻碍了该领域的进展。
为解决这一挑战,我们提出了 OpenS2V-Eval,这是该领域首个综合性的S2V基准。具体而言,我们定义了七个类别:① 单人脸到视频,② 单身体到视频,③ 单实体到视频,④ 多人脸到视频,⑤ 多身体到视频,⑥ 多实体到视频,⑦ 人体-实体到视频(如图1所示)。针对每个类别,我们设计了30个视觉内容丰富的测试样例,用于评估模型在不同主体上的泛化能力。为解决现有自动指标鲁棒性不足的问题,我们首先提出了 NexusScore,它结合图像-提示检测模型 [15] 与多模态检索模型 [119] 来精确评估主体一致性。其次,我们引入了 NaturalScore,这是一个基于GPT的指标,用于弥补主体自然性评估的空白。最后,我们提出了 GmeScore,基于MLLM [119],其在文本相关性评估上比传统的CLIPScore [73] 更为精确。通过OpenS2V-Eval,我们对几乎所有开源和闭源S2V模型进行了定性和定量的评估,为模型选择提供了宝贵的参考。
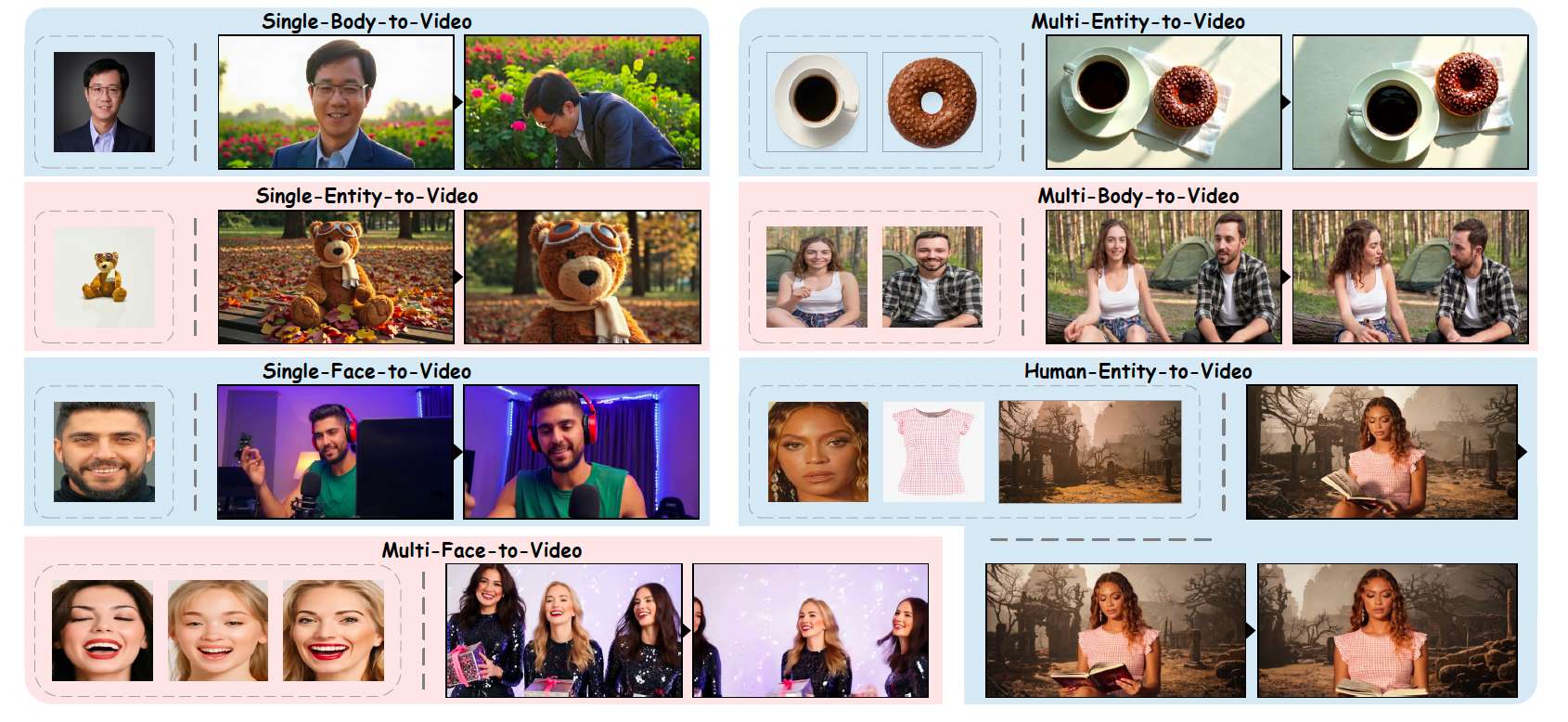
图1:OpenS2V-Eval 中七个类别的示例。这些类别全面涵盖了主体到视频任务,从而实现了综合评估。视频由 Kling [43] 生成。
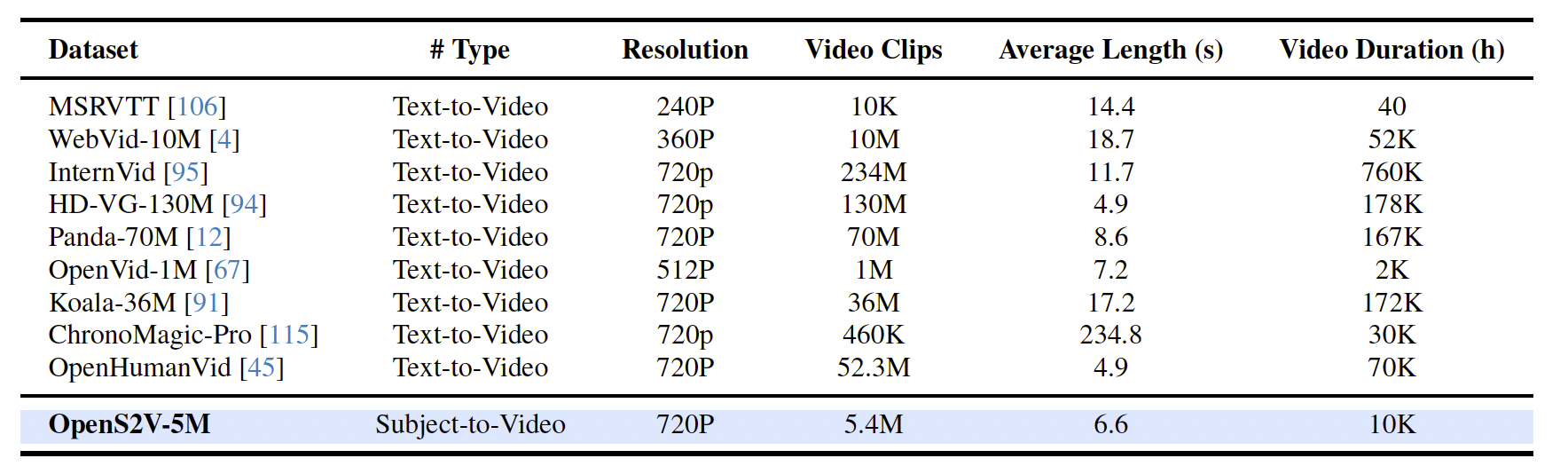
此外,当社区尝试将基础模型扩展到下游任务时,现有数据集在支持复杂任务方面存在局限 [8, 31, 69, 82, 32, 83, 61],如表2所示。为解决这一限制,我们提出了 OpenS2V-5M,这是首个专门为S2V设计的百万级数据集,同时也适用于文本到视频任务 [105, 78]。与以往方法 [113, 40, 21, 13, 55] 仅依赖常规的主体-文本-视频三元组不同(这些方法通常从训练帧中分割主体图像,可能导致模型学习捷径而非内在知识),我们通过引入 Nexus Data 进行扩展:(1) 通过跨视频关联构建配对信息;(2) 在原始帧上调用 GPT-Image-1 [1] 合成多视角表示,从而在数据层面上解决前述三大核心挑战。
表2:OpenS2V-5M 与现有视频生成数据集的统计对比。大多数现有数据集不足以支持将基础模型扩展到主体到视频生成任务。
本文的贡献总结如下:
i) 新的S2V基准:我们提出了 OpenS2V-Eval,用于全面评估S2V模型,并提出了三个与人类感知一致的新自动指标。
ii) 针对S2V模型选择的新见解:基于 OpenS2V-Eval 的评估,为不同主体到视频生成模型的优劣提供了关键性洞察。
iii) 大规模S2V数据集:我们创建了 OpenS2V-5M,其中包含510万条高质量常规数据和35万条 Nexus Data,后者有望在数据层面解决S2V的三大核心挑战。
2 Related Work
主体到视频生成的自动指标。现有的视频生成基准通常集中于文本到视频任务 [42, 101, 108, 96, 19, 28]。典型例子包括 MSR-VTT [106] 和 Make-a-Video-Eval [81],它们是视频生成评估的开创性基准。随后,VBench [36, 37, 121] 和 EvalCrafter [57] 引入了多维度的评估,结合更多模式相关因素,提供了更全面的基准。ConsisID-Bench [113] 是S2V的早期工作,但仅限于人类领域。虽然近期的基准(如 A2 Bench [21] 和 VACE-Benchmark [40])可应用于开放域S2V任务,但它们依赖于 VBench [36] 的指标来计算主体一致性,而并未针对S2V进行专门优化。因此,我们开发了首个综合性的S2V基准,其中包含180个平衡的测试对。此外,我们引入了 NexusScore、NaturalScore 和 GmeScore,分别用于准确衡量生成视频中的主体一致性、自然性和文本相关性,从而弥补了该领域的不足。
主体到视频生成的数据集。大规模、高质量的视频数据集 [4, 95, 94, 67, 93] 对新兴的基于DiT的生成模型 [118, 79, 54, 7, 20, 54, 60, 111, 52, 122] 至关重要。例如,近期发布的 Panda-70M [12]、Koala-36M [91] 和 ChronoMagic-Pro [115] 均包含数百万条高分辨率视频-文本对,为该领域的进展做出了重大贡献。然而,当社区尝试将基础模型扩展到下游任务时,现有的开源数据集不足以支持主体到视频任务 [18, 55]。此外,我们发现无论模型是闭源 [44, 5, 43] 还是开源,它们在S2V任务中都存在相同的三大核心问题。为弥补这一空白,我们提出了首个百万规模的S2V数据集——OpenS2V-5M。除了从分割的训练帧中提取主体图像外,我们进一步提出通过 (1) 跨视频关联构建配对信息,(2) 在原始帧上调用 GPT-Image-1 [1] 合成多视角表示,从而增强社区能力。
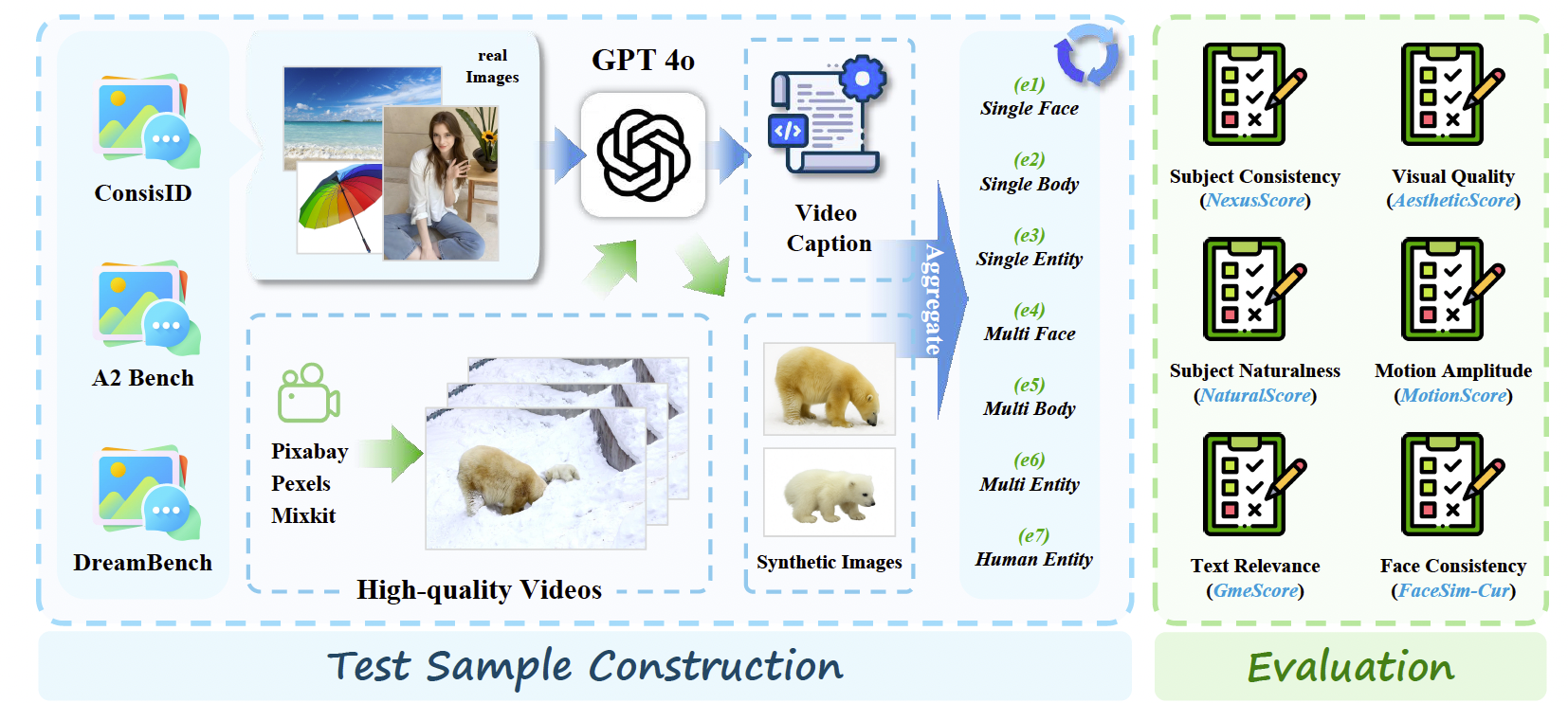
图2:构建 OpenS2V-Eval 的流程。(左) 我们的基准不仅包含真实的主体图像,还包含通过 GPT-Image-1 [1] 合成的图像,从而实现更全面的评估。(右) 指标专为主体到视频生成设计,不仅评估 S2V 特性(如一致性),还评估基本的视频要素(如运动)。
3 OpenS2V-Eval
3.1 Prompt Construction
为了全面评估主体到视频模型 [18, 55, 22] 的能力,所设计的文本提示必须涵盖广泛的类别,相应的参考图像也必须满足高质量标准。因此,为构建一个包含多样视觉概念的主体到视频基准,我们将该任务划分为七个类别:① 单人脸到视频,② 单身体到视频,③ 单实体到视频,④ 多人脸到视频,⑤ 多身体到视频,⑥ 多实体到视频,⑦ 人体-实体到视频。在此基础上,我们从 ConsisID [113] 和 A2 Bench [21] 中分别收集了50个和24个主体-文本对,用于构建①、②和⑥。此外,我们从 DreamBench [71] 中收集了30张参考图像,并利用 GPT-4o [1] 生成描述,用于构建③。随后,我们从版权自由网站获取高质量视频,利用 GPT-Image-1 [1] 从视频中提取主体图像,并使用 GPT-4o 对视频进行描述,从而获得其余的主体-文本对。每个样本的收集均通过人工方式完成,以确保基准的质量。与以往仅依赖真实图像的基准 [13, 40] 不同,加入合成样本增强了评估的多样性和精确性。
3.2 Benchmark Statistics
我们共收集了180对高质量的主体-文本对,其中包含80个真实样本和100个合成样本。除了④和⑤类别各包含15个样本外,其余类别均包含30个样本。数据统计如图3所示。© 和 (d) 展示了S2V任务的七大类别覆盖了广泛的测试场景,包括各种物体、背景和动作。此外,与人类相关的词汇(如“woman”和“man”)占据了相当大的比例,使得我们能够全面评估现有方法在人类身份保持方面的能力——这是S2V任务中特别具有挑战性的部分。此外,由于部分方法更偏好长文本描述 [40],而另一些方法更偏好短文本描述 [55],我们在构建时确保了提示文本在长度上的多样性,如(b)所示。我们还对收集的参考图像进行了美学评分,结果表明大多数图像得分高于5,显示出较高的质量。同时,我们保留了一些质量较低的图像,以保持评估的多样性。由于现有S2V模型 [43, 18, 44] 的局限性,我们将每个样本的主体图像数量限制为不超过三张。

图3:OpenS2V-Eval 的统计信息。该基准覆盖了多样化的类别和提示词,主体图像具有较高的美学质量,从而支持全面的评估。
3.3 New Automatic Metrics
如前所述,现有的S2V基准通常是从T2V改编而来,而不是专门为S2V设计的。对于主体到视频任务而言,评估不仅需要关注全局方面(如视觉质量和运动),还必须考察生成结果中的主体一致性与自然性。
NexusScore 为了计算主体一致性,以往的研究 [40, 55, 21, 36, 37] 通常直接在DINO [116] 或 CLIP [73] 特征空间中计算未裁剪视频帧与参考图像之间的相似度。然而,这种方法会引入背景噪声,并且该特征空间已被证明不合理 [100, 58, 115]。为解决这一问题,我们提出了NexusScore SNexusS_{Nexus}SNexus,它结合了图像-提示检测模型Mdetect\mathcal{M}_{detect}Mdetect [15] 与多模态检索模型Mretrieve\mathcal{M}_{retrieve}Mretrieve [119]。具体而言,参考图像{Ri}i=1I\{R_i\}_{i=1}^I{Ri}i=1I和视频帧{It}t=1T\{I_t\}_{t=1}^T{It}t=1T首先输入到Mdetect\mathcal{M}_{detect}Mdetect,该模型识别出每帧中相关目标并生成其边界框Bi,tB_{i,t}Bi,t:
Bi,t=Mdetect(Ri,It),(1)B_{i,t} = \mathcal{M}_{detect}(R_i, I_t), \tag{1} Bi,t=Mdetect(Ri,It),(1)
为提高边界框的精确度,我们在每个主体上裁剪区域Bi,tB_{i,t}Bi,t,得到裁剪后的参考图像Ci,tC_{i,t}Ci,t。接着,我们在统一的文本-图像特征空间中计算Ci,tC_{i,t}Ci,t与对应目标实体名称Ei,tE_{i,t}Ei,t之间的相似度,该相似度记为sss,计算方式如下:
si,t=Mretrieve(Ci,t,Ei,t),(2)s_{i,t} = \mathcal{M}_{retrieve}(C_{i,t}, E_{i,t}), \tag{2} si,t=Mretrieve(Ci,t,Ei,t),(2)
若边界框Bi,tB_{i,t}Bi,t的置信度ci,tc_{i,t}ci,t与si,ts_{i,t}si,t均超过预定义阈值α\alphaα和β\betaβ,则进入下一阶段。最后,Ci,tC_{i,t}Ci,t与RiR_iRi之间的相似度在图像特征空间中进行评估,得到:
SNexus=1I×T′∑i=0I∑t=0T′Mretrieve(Ci,t,Ri),where ci,t>αand si,t>β(3)S_{Nexus} = \frac{1}{I \times T'} \sum_{i=0}^{I} \sum_{t=0}^{T'} \mathcal{M}_{retrieve}(C_{i,t}, R_i), \quad \text{where } c_{i,t} > \alpha \text{ and } s_{i,t} > \beta \tag{3} SNexus=I×T′1i=0∑It=0∑T′Mretrieve(Ci,t,Ri),where ci,t>α and si,t>β(3)
其中T′T'T′表示检测到目标的帧总数。详情见附录D.4。
NaturalScore 与现有仅关注主体一致性的S2V基准 [113, 21, 40, 55] 不同,我们额外评估生成的主体是否自然,即是否符合物理规律。这是由于当前S2V方法普遍存在“拷贝-粘贴”问题,模型往往直接将参考图像复制到生成场景中,即便输出未能符合人类直觉,也会获得较高的一致性得分。
为解决这一问题,一个直接的方案是采用AIGC异常检测模型 [107, 46, 66]。但我们发现开源模型的准确性不理想。另一种替代方法是使用开源多模态大模型 [3, 51, 85] 进行视频评分,但这些模型指令跟随性能较差,且容易出现幻觉。因此,我们采用GPT-4o [1] 来模拟人工评估,具备更高的准确性和灵活性。具体来说,我们设计了一个基于常识与物理规律的五分制评价标准,记为C={c1,c2,c3,c4,c5}C = \{c_1, c_2, c_3, c_4, c_5\}C={c1,c2,c3,c4,c5},其中每个cic_ici表示一个特定评价等级。对于每个视频,我们均匀采样TTT帧,记为{It}t=1T\{I_t\}_{t=1}^T{It}t=1T。这些帧被输入到GPT-4o的MGPT\mathcal{M}_{GPT}MGPT,该模型为每帧分配一个得分sts_tst,并基于五分制给出解释。最终得分SNaturalS_{Natural}SNatural为所有TTT帧得分的平均值:
SNatural=1T∑t=1TMGPT(It)(4)S_{Natural} = \frac{1}{T} \sum_{t=1}^{T} \mathcal{M}_{GPT}(I_t) \tag{4} SNatural=T1t=1∑TMGPT(It)(4)
GmeScore 现有方法通常使用 CLIP [73] 或 BLIP [117] 来计算文本相关性。然而,已有多项研究 [58, 115, 100] 指出这些模型的特征空间存在固有缺陷,导致得分不准确。此外,它们的文本编码器仅限于77个token,这使得它们无法处理当前基于DiT的视频生成模型 [59, 79, 109, 89] 所偏好的长文本提示。鉴于此,我们选择采用 GME [119],该模型在 Qwen2-VL [90] 上进行过微调,能够自然地处理不同长度的文本提示,并产生更可靠的得分。

图 4:OpenS2V-5M 的构建流程。首先,我们基于美学分数和运动分数等指标过滤低质量视频,然后利用 GroundingDino [56] 和 SAM2.1 [76] 提取主体图像,得到 Regular Data。随后,我们通过跨视频关联和 GPT-Image-1 [1] 构建 Nexus Data,以解决 S2V 模型面临的三大核心问题。
4 OpenS2V-5M
4.1 Data Construction
对于GPT-Frame对:令I0I_0I0表示给定视频的第一帧,令K={k1,k2,…,kn}K=\{k_1, k_2, \ldots, k_n\}K={k1,k2,…,kn}为与视频主体相关的一组关键词。我们将I0I_0I0和KKK输入到GPT-Image-1 MGPT\mathcal{M}_{GPT}MGPT中,该模型生成对应主体的完整图像IgenI_{gen}Igen,从而形成对⟨I0,Igen⟩\langle I_0, I_{gen} \rangle⟨I0,Igen⟩,我们称之为GPT-Frame对。由于GPT-Image-1强大的生成能力,它可以重建不完整的主体,并从多个视角生成一致的内容,从而确保与我们的数据需求保持一致。这种关系可以形式化为:
Igen=MGPT(I0,K)I_{gen} = \mathcal{M}_{GPT}(I_0, K) Igen=MGPT(I0,K)
对于Cross-Frame对:由于片段是从长视频中切分出来的,因此这些片段之间存在固有的时间和语义相关性。为捕捉这一点,我们聚合来自同一长视频的片段,记为C={C1,C2,…,Cm}C = \{C_1, C_2, \ldots, C_m\}C={C1,C2,…,Cm},其中每个CiC_iCi对应视频的不同片段。使用多模态检索模型Mretrieval\mathcal{M}_{retrieval}Mretrieval计算这些片段中主体的相似性,得到任意片段CijC_{ij}Cij和CklC_{kl}Ckl之间的相似度分数S(Cij,Ckl)S(C_{ij}, C_{kl})S(Cij,Ckl),其中i≠ki \neq ki=k表示不同视频片段,jjj和lll表示不同的主体:
S(Cij,Ckl)=sim(Mretrieval(Cij),Mretrieval(Ckl))S(C_{ij}, C_{kl}) = \text{sim}(\mathcal{M}_{retrieval}(C_{ij}), \mathcal{M}_{retrieval}(C_{kl})) S(Cij,Ckl)=sim(Mretrieval(Cij),Mretrieval(Ckl))
其中sim(⋅,⋅)\text{sim}(\cdot,\cdot)sim(⋅,⋅)表示计算相似度。该过程使得我们能够形成Cross-Frame对⟨Cij,Ckl⟩\langle C_{ij}, C_{kl} \rangle⟨Cij,Ckl⟩。最后,我们为每个样本分配美学分数和GmeScore。
4.2 Dataset Statistics
OpenS2V-5M 是首个开源的百万级 subject-to-video 数据集。它包含 510 万条 Regular Data,这类数据在现有方法中被广泛使用 [40, 21, 55],以及 35 万条 Nexus Data,这部分数据通过 GPT-Image-1 [1] 和跨视频关联生成。该数据集有望解决 S2V 模型面临的三大核心挑战。详细统计数据见附录 C.2。
5 Experiments
5.1 Evaluation Setups
评估基线。我们几乎评估了所有 S2V 模型,包括四个闭源和十四个开源模型,其中既有支持所有类型主体的模型(例如 Vidu [5]、Pika [44]、Kling [43]、VACE [40]、Phantom [55]、SkyReels-A2 [21] 和 HunyuanCustom [33]),也有仅支持人类身份的模型(例如 Hailuo [87]、ConsisID [113]、Concat-ID [123]、FantasyID [120]、EchoVideo [97]、VideoMaker [103] 和 ID-Animator [29])。
应用范围。OpenS2V-Eval 提出了一个自动评分方法,用于评估主体一致性、主体自然性和文本相关性。结合现有的视觉质量、运动幅度和人脸相似度等指标(例如 Aesthetic Score [16]、Motion Score [6] 和 FaceSim-Cur [113]),它能够在六个维度上对 S2V 模型进行全面评估。此外,还可以利用人工评估以提供更精确的判断。
实现细节。闭源 S2V 模型只能通过其接口手动执行,而开源模型的推理速度相对较慢(例如 VACE-14B [40] 在单个 Nvidia A100 上生成一段 81 × 720 × 1280 的视频需要超过 50 分钟)。因此,对于每个基线模型,我们仅为 OpenS2V-Eval 中的每个测试样本生成一段视频。随后,我们使用前述六个自动化指标对所有生成的视频进行评估。所有推理设置均遵循官方实现,随机种子固定为 42。更多细节见附录 D。