ARM 架构简明教程学习笔记
FreeRTOS 前置知识 - ARM 架构底层原理超详细复习笔记
一、知识总览
这部分内容是理解嵌入式程序运行的基石,从芯片指令集(RISC)、CPU 数据暂存(寄存器),到操作硬件的汇编指令,层层拆解程序在 ARM 硬件上 “如何跑起来”“如何控制数据和流程”,为后续 FreeRTOS 任务调度、硬件交互打基础。
二、核心概念分步解析
(一)1.1 RISC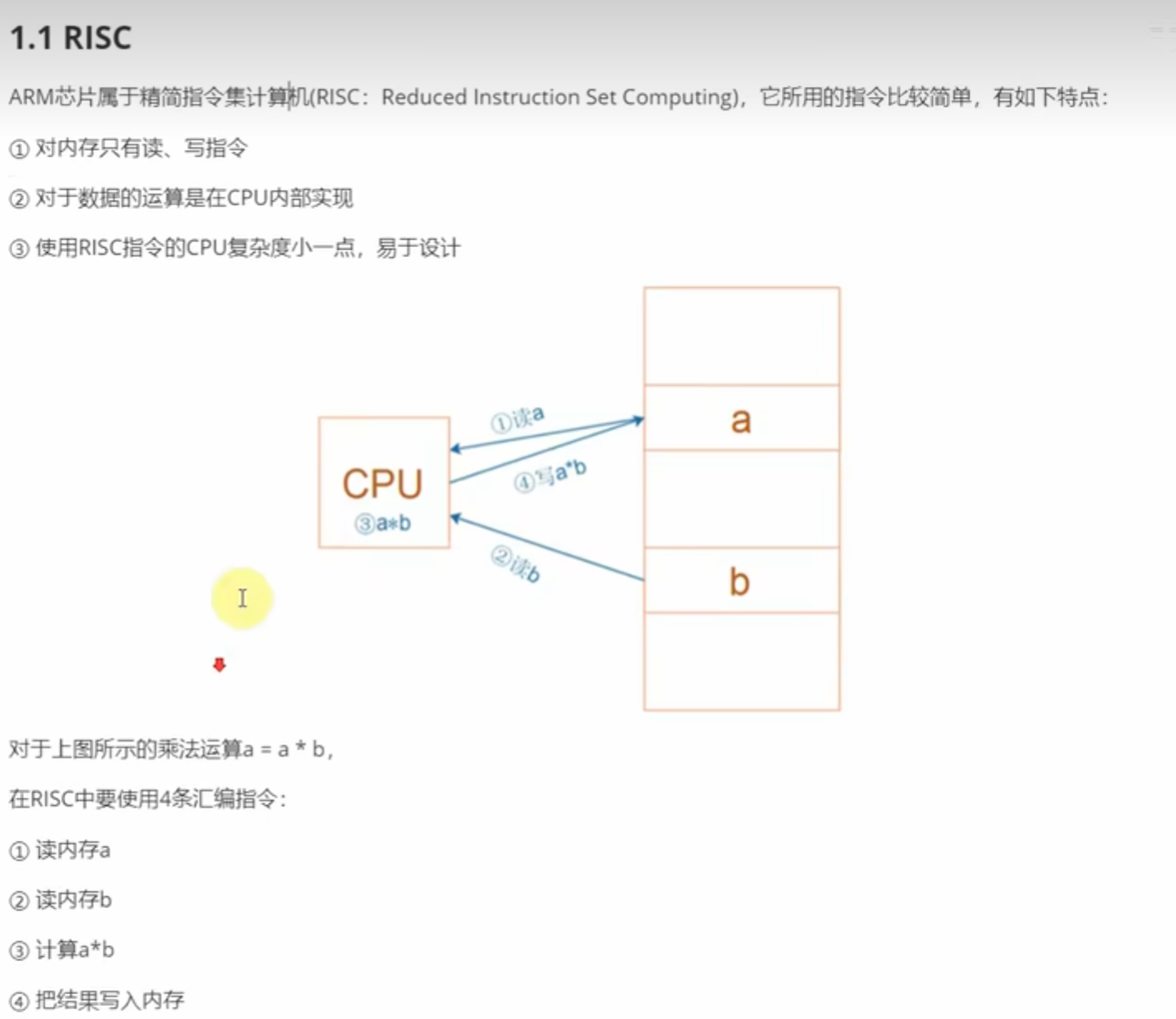
- 定义:ARM 芯片采用的精简指令集计算机架构(Reduced Instruction Set Computing),指令简单且遵循 3 大规则:
- 对内存 只有读(Load)、写(Store)指令:数据运算必须先把内存数据读到 CPU 内部,运算完再写回内存,无法 “跨内存直接运算” 。
- 数据运算在 CPU 内部实现:依赖 CPU 里的运算单元(如 ALU )处理数据 。
- CPU 复杂度低:指令简单,硬件设计、实现难度小,适配嵌入式设备资源受限场景 。
- 乘法运算示例(a = a * b 流程 ):
- 步骤拆解:①读内存
a→ ②读内存b→ ③CPU 内部计算a*b→ ④写结果回内存a。 - 本质:因 RISC 指令 “精简”,复杂运算需拆分为 “读 - 算 - 写” 步骤,不像复杂指令集(CISC)可一条指令完成多操作 。
- 步骤拆解:①读内存
(二)1.3 CPU 内部寄存器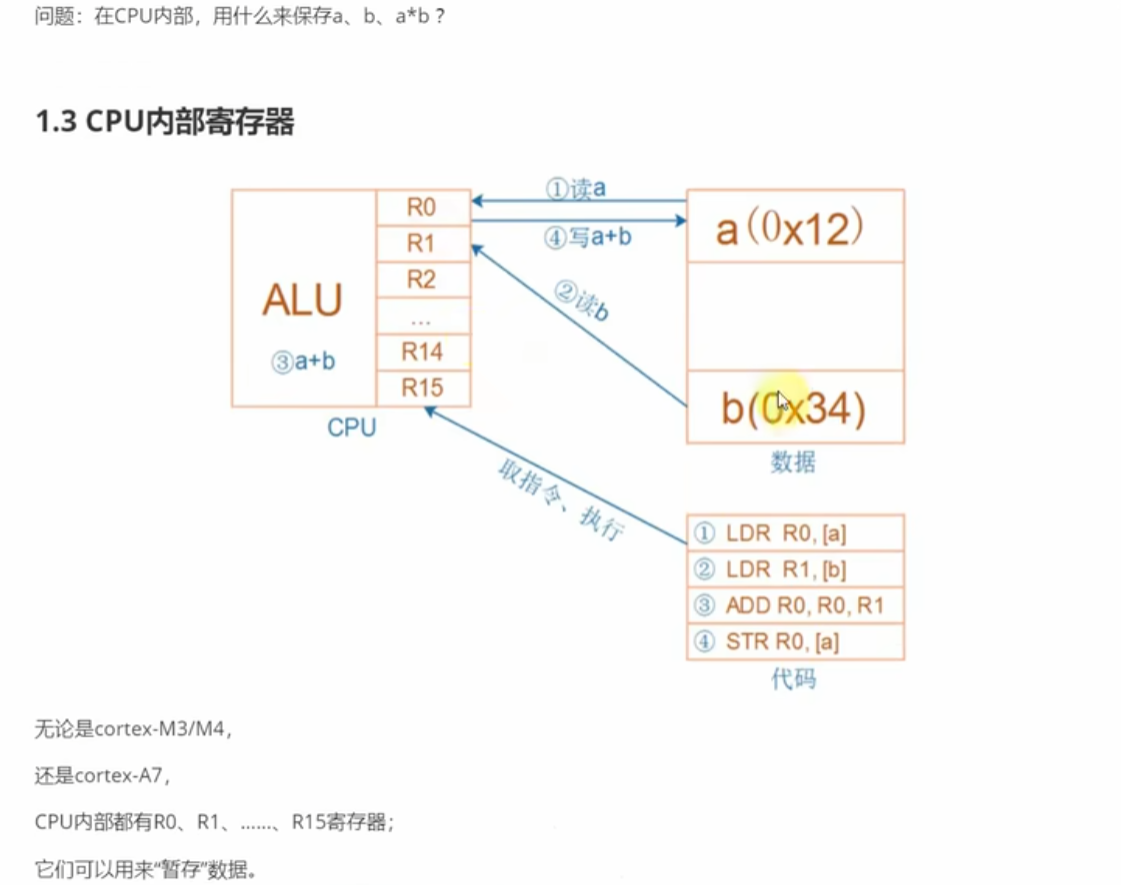
- 核心作用:临时存储数据、地址、程序状态!不管是 Cortex - M3/M4 还是 A7,CPU 都有 R0 - R15 通用寄存器 + 程序状态寄存器(xPSR ),用于运算时暂存数据、标记程序状态 。
- 运算流程示例(以 a + b 为例,a = 0x12,b = 0x34 ):
- 读数据到寄存器:
- 用
LDR R0, [a]指令,把内存地址a里的数据(0x12 )读到 R0 寄存器 。 - 用
LDR R1, [b]指令,把内存地址b里的数据(0x34 )读到 R1 寄存器 。
- 用
- CPU 内部运算:
- 执行
ADD R0, R0, R1,CPU 的 ALU(算术逻辑单元 )用 R0、R1 的数据做加法,结果存回 R0 寄存器(R0 = 0x12 + 0x34 = 0x46 ) 。
- 执行
- 写结果回内存:
- 用
STR R0, [a]指令,把 R0 里的结果(0x46 )写回内存地址a。
- 用
- 读数据到寄存器:
- 寄存器角色:R0、R1 是 “临时工作台”,存运算的输入 / 输出数据;ALU 是 “计算器”,负责算术逻辑运算;xPSR 存运算状态(如进位、借位标志 ) 。
(三)1.4 汇编指令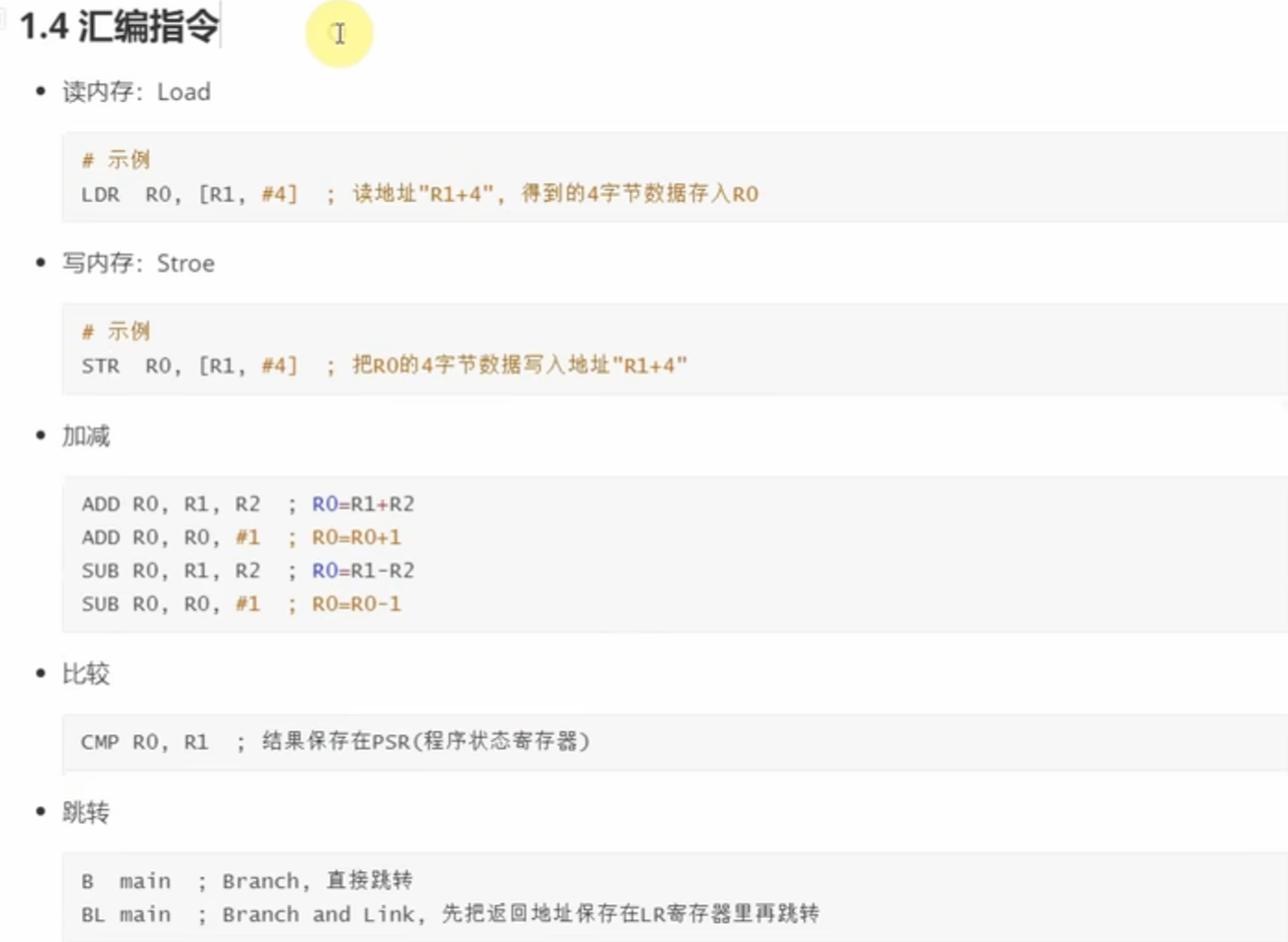
汇编指令是直接操作 CPU 寄存器、内存、控制程序流程的底层指令,基于 RISC 特性设计,核心分类及用法:
1. 内存读写指令
- 读内存(Load - LDR ):
- 示例:
LDR R0, [R1, #4] - 功能:读取 地址 = R1 + 4 处的 4 字节内存数据,存入 R0 寄存器 。
- 原理:R1 是 “基地址”,#4 是 “偏移量”,合起来定位内存位置,把数据 “抓” 到 CPU 内部(契合 RISC “读内存” 需求 ) 。
- 示例:
- 写内存(Store - STR ):
- 示例:
STR R0, [R1, #4] - 功能:把 R0 里的 4 字节数据,写入 地址 = R1 + 4 的内存位置 。
- 原理:与 LDR 相反,把 CPU 寄存器的数据 “推” 回内存(契合 RISC “写内存” 需求 ) 。
- 示例:
2. 算术运算指令
- 加法(ADD ):
- 格式 1:
ADD R0, R1, R2→ 功能:R0 = R1 + R2 (三寄存器参与,前一个存结果,后两个存加数 ) 。 - 格式 2:
ADD R0, R0, #1→ 功能:R0 = R0 + 1 (寄存器自增,常用写法 ) 。
- 格式 1:
- 减法(SUB ):
- 格式 1:
SUB R0, R1, R2→ 功能:R0 = R1 - R2 。 - 格式 2:
SUB R0, R0, #1→ 功能:R0 = R0 - 1 (寄存器自减 ) 。
- 格式 1:
- 原理:依托 CPU 内部 ALU 实现运算,直接操作寄存器数据(契合 RISC “运算在 CPU 内部” 的规则 ) 。
3. 比较指令(CMP )
- 示例:
CMP R0, R1 - 功能:比较 R0 和 R1 的数据,结果存入 程序状态寄存器(xPSR )(如记录 “相等 / 不等”“大于 / 小于” 标志 ) ,后续跳转指令(如
BEQ“相等则跳转” )依据这些标志决定是否执行 。 - 原理:修改程序状态寄存器,为流程控制提供判断依据 。
4. 跳转指令(B、BL )
直接跳转(B ):
- 示例:
B main - 功能:直接跳转到标签
main(函数 / 地址 )处执行,不保存返回地址 。 - 原理:修改 程序计数器(PC,即 R15 ) 的值,让 CPU 从新地址取指令执行 。
- 示例:
带返回跳转(BL ):
- 示例:
BL main - 功能:跳转前,把当前 PC 的值(返回地址 ) 存入 链接寄存器(LR,即 R14 ) ;执行完
main后,可通过恢复 LR 的值回到跳转前的代码位置 。 - 原理:依靠 LR 暂存返回地址,实现 “去 - 回” 的函数调用流程 。
- 示例:
笔记位置:讲完寄存器,汇编指令是操作寄存器、内存、控制流程的 “具体工具”,顺着知识链深入解析 。插入第二张图,展示汇编指令分类及示例 。
(四)特殊寄存器解析
除通用寄存器,ARM 还有 3 个关键特殊寄存器:
- R13(SP - 栈指针 ):
- 功能:指向 栈顶位置 ,栈用于存储函数局部变量、函数调用的上下文(如参数、返回地址 ) 。
- 示例:函数调用时,
PUSH {R0, R1}会把 R0、R1 的值压入栈,SP 自动减小(栈向下生长 );POP {R0, R1}会从栈弹出数据到 R0、R1,SP 自动增大 。
- R14(LR - 链接寄存器 ):
- 功能:保存返回地址 ,执行
BL跳转指令时,当前 PC 的值(跳转前的指令地址 )会存入 LR;函数返回时,把 LR 的值恢复到 PC,即可回到跳转前的代码 。
- 功能:保存返回地址 ,执行
- R15(PC - 程序计数器 ):
- 功能:存储 下一条要执行的指令地址 ,CPU 按 PC 的值从内存取指令执行;修改 PC 的值可实现跳转(如
B、BL指令本质是修改 PC ) 。
- 功能:存储 下一条要执行的指令地址 ,CPU 按 PC 的值从内存取指令执行;修改 PC 的值可实现跳转(如
- xPSR(程序状态寄存器 ):
- 功能:存储程序运行的 状态标志(如 CMP 指令的比较结果、中断状态 ) ,控制程序流程(如条件跳转依赖 xPSR 的标志位 ) 。
三、知识串联(从指令集到程序执行 )
数据运算流程:
若要执行a = a * b(RISC 场景 ),需先通过 汇编指令(LDR ),借助 通用寄存器(如 R0、R1 ) 作为 “临时仓库”,将内存中的a、b读入 CPU;再由 CPU 内部的运算单元(ALU ),通过 算术指令(如 MUL 乘法指令 ) 处理数据;最后用 汇编指令(STR ),把结果写回内存 。流程控制逻辑:
想跳转到main函数?通过B或BL指令修改 PC 寄存器 的值实现跳转;若用BL指令,还需依靠 LR 寄存器 暂存返回地址,确保 “去得回、回得来” 。程序状态管理:
CMP指令会修改 xPSR 寄存器 的状态,后续的条件跳转指令(如BEQ“相等则跳转”、BNE“不等则跳转” ),依据 xPSR 的标志位决定是否执行跳转 。
四、易错点 & 补充说明
易错点
内存读写与运算指令混用:
RISC 架构严格区分 “内存读写” 和 “运算” 指令,无法用一条指令同时完成 “读内存 + 运算”(如不能直接写ADD R0, [R1], [R2])。必须先通过LDR读数据到寄存器,再用ADD等运算指令处理 。特殊寄存器功能混淆:
SP、LR、PC 各自承担特殊职责,不可滥用!例如,若将普通数据存入 LR,会覆盖返回地址,导致函数调用无法正确返回 。跳转指令理解偏差:
B指令是 “单向跳转”(若需返回,需额外处理 ),BL指令是 “往返跳转”(自动保存返回地址 )。编写函数调用逻辑时,需根据需求选择指令(通常函数调用用BL)。
FreeRTOS 前置知识 - ARM 架构函数调用与指令执行 超详细复习笔记
一、知识总览
这部分内容聚焦 ARM 架构下函数调用的完整流程,从 C 函数编写,到编译生成反汇编、汇编指令执行,再到 CPU 与内存交互、栈操作,拆解 “函数如何被调用”“数据如何传递 / 返回”“底层指令如何执行”,为理解 FreeRTOS 任务切换、函数嵌套调用打基础。
二、核心概念分步解析
(一)C 函数编写
- 代码示例:
int add(volatile int a, volatile int b) {volatile int sum;sum = a + b;return sum;
}
- 关键语法:
volatile:确保变量a、b、sum每次从内存读写(而非寄存器缓存 ),避免编译器优化干扰(嵌入式场景操作硬件寄存器时必用 )。- 函数逻辑:接收两个
int参数,做加法后返回结果 。
(二)反汇编生成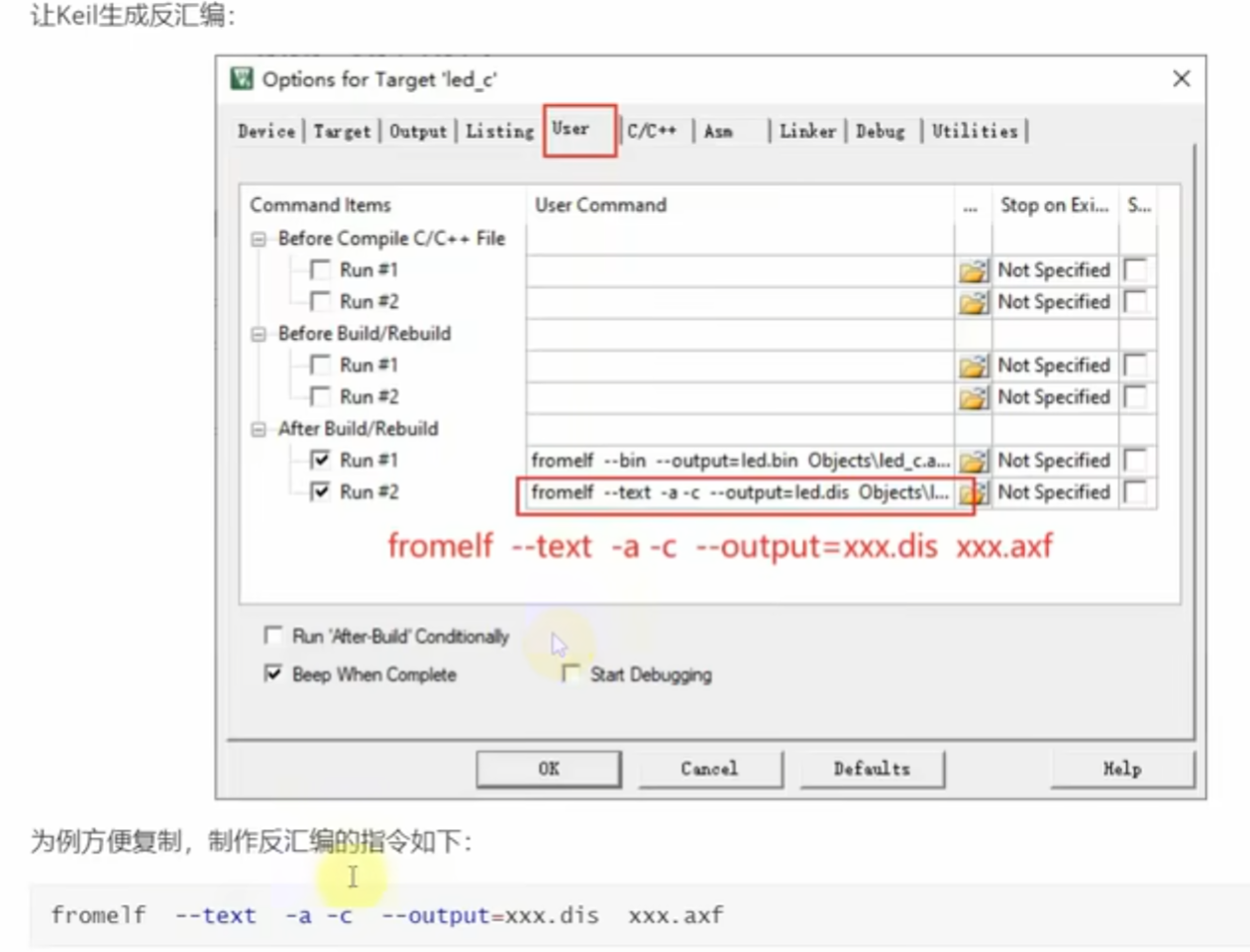
- 操作步骤:在 Keil 中,通过
Options for Target→User标签页,配置After Build/Rebuild命令:plaintext
fromelf --text -a -c --output=xxx.dis xxx.axf
编译工程后,自动生成反汇编文件(xxx.dis),用于查看 C 函数对应的 汇编指令 + 机器码 。 - 核心作用:将人类编写的 C 代码,转换为机器可执行的汇编 / 机器码,是连接 “上层逻辑” 与 “底层执行” 的桥梁 。
(三)add 函数反汇编解析
反汇编文件中,add 函数对应的指令如下:
i.add
add
0x08002f34: b503 .. PUSH {r0, r1, lr}
0x08002f36: b081 .. SUB sp, sp, #4
0x08002f38: e9dd0101 .... LDRD r0, r1, [sp, #4]
0x08002f3c: 4408 .D ADD r0, r0, r1
0x08002f3e: 9000 .. STR r0, [sp, #0]
0x08002f40: bd0e .. POP {r1 - r3, pc}
- 指令逐行解析:
PUSH {r0, r1, lr}(地址0x08002f34):
把寄存器r0(参数a)、r1(参数b)、lr(链接寄存器,存返回地址 )压入栈,保存 “函数调用前的现场”,避免被后续操作覆盖 。SUB sp, sp, #4(地址0x08002f36):
调整 栈指针(sp ),为局部变量sum分配 4 字节栈空间(int占 4 字节 ) 。LDRD r0, r1, [sp, #4](地址0x08002f38):
从栈中sp + 4位置,加载 8 字节数据到r0、r1(因LDRD是双字加载指令 )。实际对应从栈中读取参数a(r0)、b(r1) 。ADD r0, r0, r1(地址0x08002f3c):
执行加法运算:r0 = r0 + r1(即sum = a + b) 。STR r0, [sp, #0](地址0x08002f3e):
把r0的值(加法结果sum)存入栈中sp + 0位置(即分配给sum的栈空间 ) 。POP {r1 - r3, pc}(地址0x08002f40):
从栈中恢复r1 - r3寄存器,并将 栈中保存的返回地址(之前PUSH存入的lr值 )弹入pc(程序计数器 ),实现 “函数返回”,回到调用处继续执行 。
- 笔记位置:解析完反汇编生成,详细拆解
add函数的汇编指令,理解 “C 代码 → 汇编指令” 的转换逻辑 。插入第五张图,展示add函数的反汇编内容 。
(四)函数调用流程
1. 调用前准备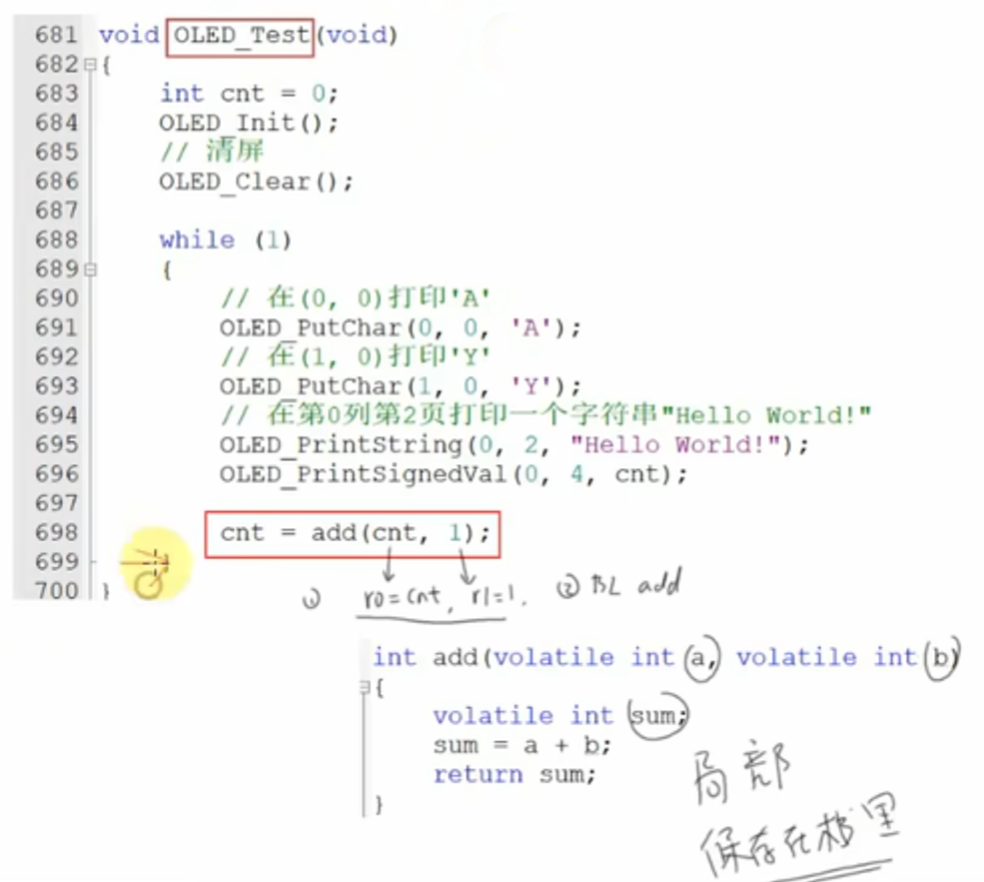
- C 代码:
cnt = add(cnt, 1);(OLED_Test函数中 )- 功能:
cnt是循环计数器,每次调用add实现cnt += 1。 - 传参逻辑:
cnt的值存入r0寄存器(作为add的参数a)。- 常量
1存入r1寄存器(作为add的参数b)。 - 执行
BL add指令(BL= Branch with Link ),跳转至add函数 。
- 功能:
- 关键细节:
BL指令会自动将 当前pc的值(返回地址,如0x08002a36) 存入lr寄存器,为 “返回调用处” 做准备 。
2. 函数执行与栈操作
- 栈变化流程:
- 压栈保存现场:进入
add函数后,执行PUSH {r0, r1, lr},将r0(cnt)、r1(1)、lr(返回地址0x08002a36)压入栈,栈指针sp减小(栈向下生长 )。 - 分配局部变量空间:执行
SUB sp, sp, #4,sp继续减小,为sum分配 4 字节栈空间 。 - 运算与存结果:执行
LDRD读参数、ADD运算、STR存结果,数据在 “栈 + 寄存器” 间流转 。 - 弹栈恢复现场:执行
POP {r1 - r3, pc},恢复r1 - r3寄存器,将lr中保存的返回地址弹入pc,回到OLED_Test函数继续执行 。
- 压栈保存现场:进入
- 栈空间图示:
图中展示栈内存储的lr(返回地址0x08002a36)、r1 = 1、r0 = cnt等数据,以及sp指针的移动过程(sp = A→ 压栈后sp = A - 12→ 分配局部变量后sp = A - 16),直观呈现 “保存 - 运算 - 恢复” 的栈操作逻辑 。 - 笔记位置:深入分析函数调用时 “栈 + 寄存器” 的交互,理解 ARM 架构的 “函数调用约定”(参数传递、返回地址保存、栈帧管理 ) 。插入第二张图,辅助理解栈操作流程 。
3. 调用后返回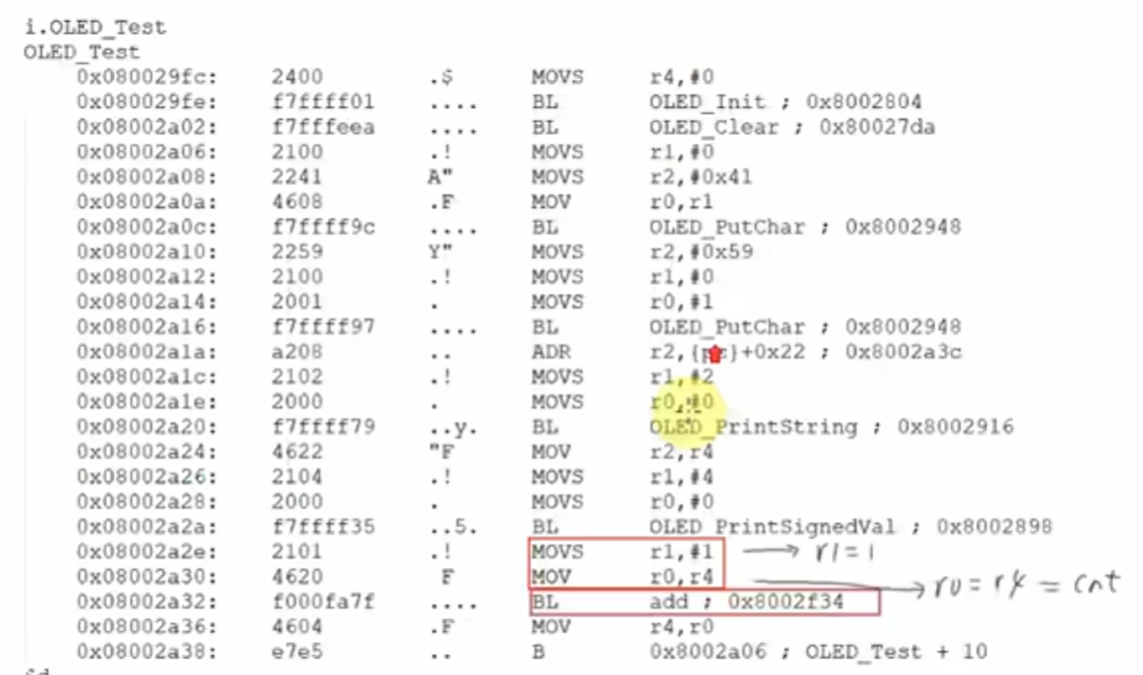
- 返回值传递:
add函数的返回值(sum),通过r0寄存器 传递回OLED_Test函数(ARM 架构约定:函数返回值优先存入r0)。 - 程序计数器恢复:
POP {r1 - r3, pc}指令将栈中保存的返回地址(lr的值 )弹入pc,CPU 从pc指向的地址(如0x08002a36)继续执行OLED_Test函数后续代码 。 - 笔记位置:完整梳理 “调用 → 执行 → 返回” 的全流程,串联栈操作、寄存器交互、指令执行 。插入第一张图,展示
OLED_Test函数的汇编代码及add调用逻辑 。
(五)CPU 执行流程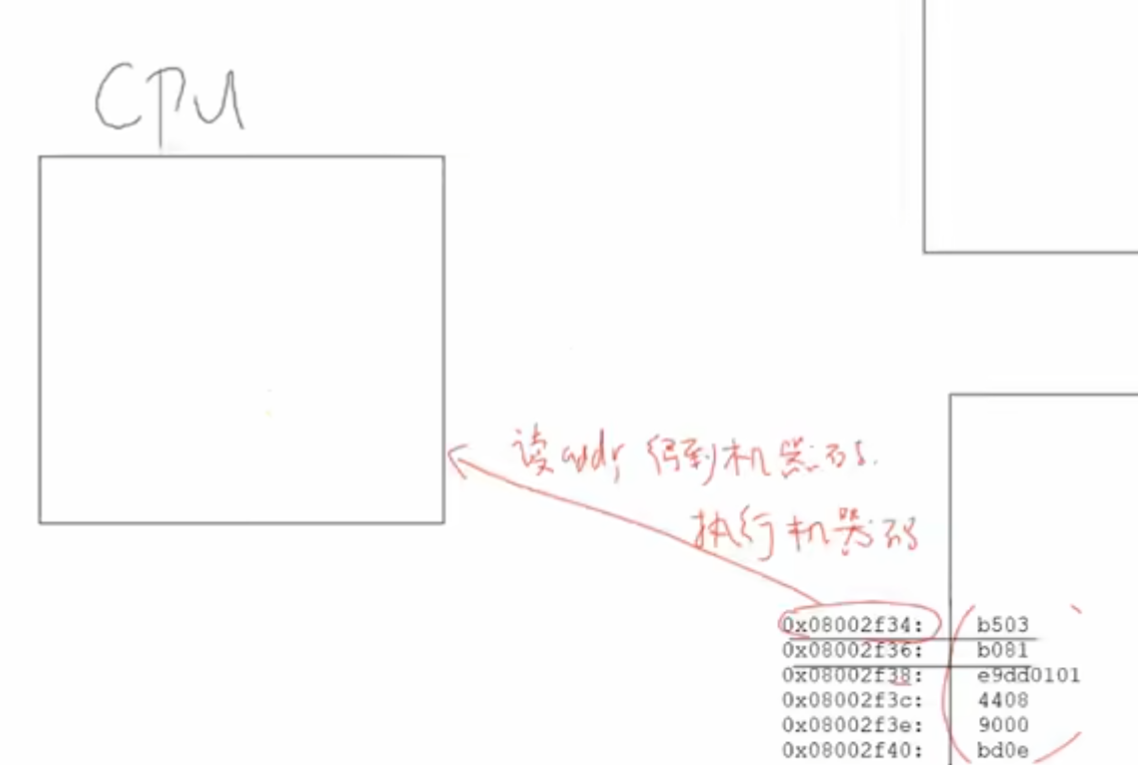
- 核心逻辑:CPU 从内存中 读取指令的机器码(如
add函数的机器码b503、b081等 ),通过 指令译码器 解析为汇编指令,再调度运算单元(如 ALU )执行操作,完成 “取指 → 译码 → 执行” 的流程 。 - 图示解析:第四张图展示 CPU 从内存地址
0x08002f34读取机器码(b503等 ),执行对应的汇编指令(PUSH等 ),体现 “硬件如何执行指令” 的最底层逻辑 。 - 笔记位置:最后,从 “CPU 与内存交互” 的最底层视角,总结程序在 ARM 架构下的运行流程,串联函数调用、栈操作、指令执行的完整逻辑 。插入第四张图,呈现 CPU 执行指令的基本流程 。
三、知识串联(从 C 函数到 CPU 执行 )
- 代码转换:
add函数的 C 代码,通过编译器编译、Keil 配置反汇编,生成对应的 汇编指令 + 机器码 。 - 函数调用:
OLED_Test调用add时,通过BL指令跳转,自动将返回地址存入lr;add函数内,通过 栈操作 保存现场、分配局部变量,执行加法后,通过POP恢复寄存器、将返回地址写入pc,实现 “调用 - 返回” 。
- 指令执行:CPU 从内存中读取
add函数的机器码,解析为汇编指令并执行,依托 寄存器 暂存数据、栈 管理函数上下文,最终完成加法逻辑并返回结果 。
四、易错点 & 补充说明
易错点
volatile关键字理解偏差:
忘记volatile会导致编译器优化变量读写(如将变量缓存到寄存器 ),在嵌入式场景(如操作硬件寄存器、多任务共享变量 )中,可能引发 “数据不同步” 问题。需牢记:volatile变量 每次从内存读写,禁止编译器优化 。栈操作顺序混淆:
函数调用时,栈的 “压入(PUSH)” 和 “弹出(POP)” 需严格对称。若手动修改栈操作指令,可能导致 “现场保存不完整”,引发程序崩溃 。返回值传递误解:
ARM 架构中,函数返回值默认通过r0传递(若返回复杂类型,需额外处理 )。若在汇编中手动修改r0,可能覆盖返回值,导致上层逻辑错误 。