视觉语言导航(14)——VLN ON ROBOTIC 4.4
这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
从仿真到物理世界
在机器人学中,直接在物理硬件上进行训练不仅成本高昂、耗时,还存在安全风险。因此,仿真环
境成为了训练智能体策略的理想平台,它允许安全、快速且大规模地进行实验 。然而,仿真器终究是现实世界的简化模型,这导致了“仿真到现实鸿沟”(Sim-to-Real Gap)的产生,其核心表现为
在仿真中表现优异的策略,部署到真实机器人上时性能会大幅下降


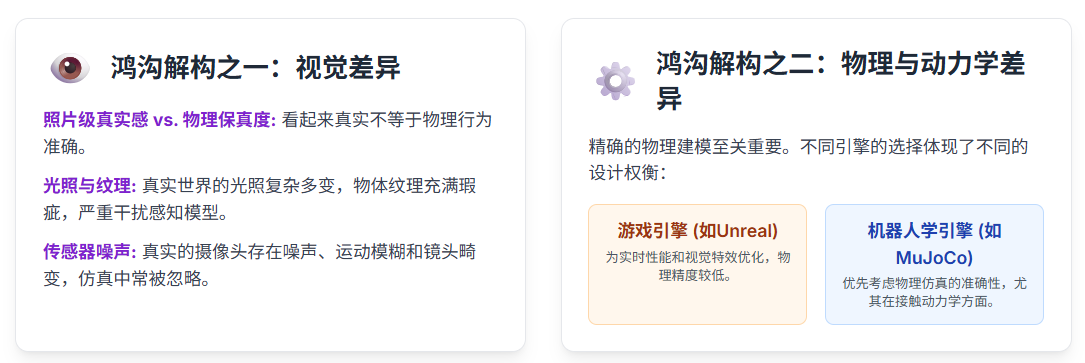 具身VLN的鸿沟解构
具身VLN的鸿沟解构

弥合鸿沟:核心Sim-to-Real方法论
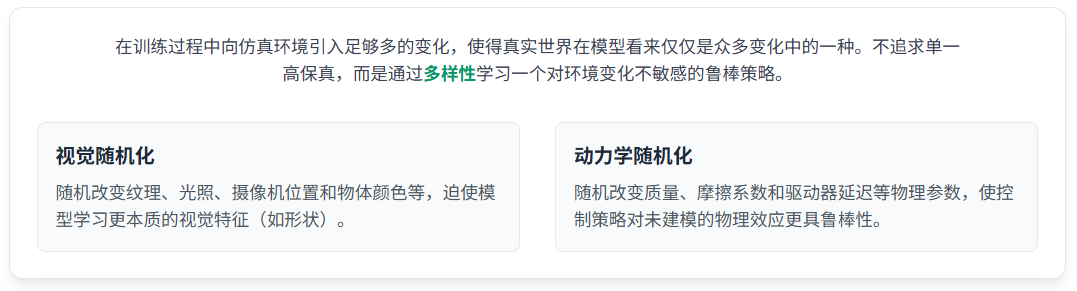
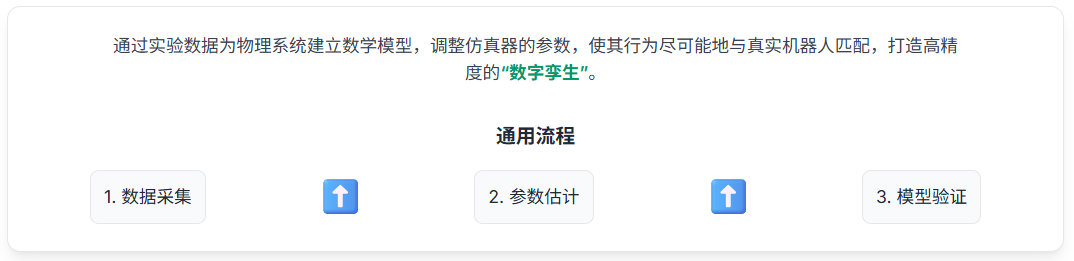
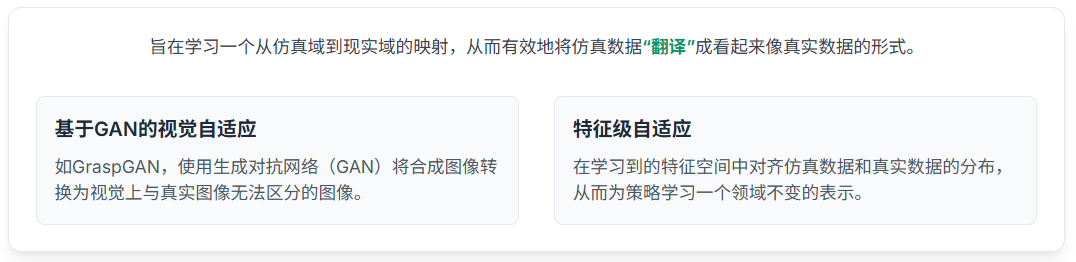

前沿架构

GVNav整体框架
就是VLN-BERT加上多视角观测,也是一种基于图的导航策略
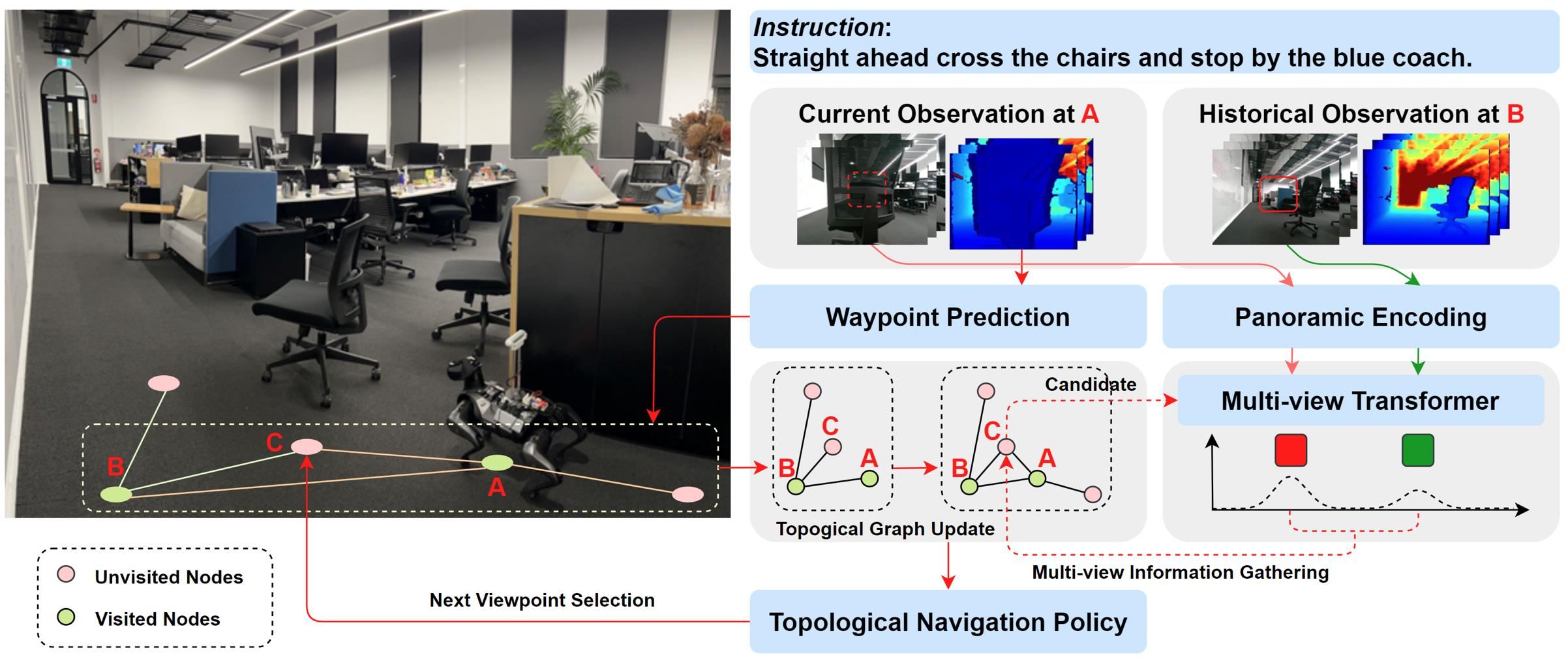
指令接收(Instruction):系统首先接收一个导航指令,例如“直行穿过椅子并停在蓝色沙发旁”。
当前观察(Current Observation at A)与历史观察(Historical Observation at B):系统会同时考虑当前位置A的实时观测数据以及之前位置B的历史观测数据。这些观测数据包括视觉图像和深度信息。
Waypoint Prediction:基于当前和历史的观测数据,系统进行路径点预测。这一步骤可能涉及对环境中的障碍物、目标物体等进行识别和定位,以确定下一步应该朝哪个方向移动。
Panoramic Encoding:全景编码将当前和历史的多视角信息整合成一个全局视图,以便更好地理解环境的全貌。
Multi-view Transformer:通过一个多视图Transformer处理整合后的信息。这个Transformer能够捕捉不同视角之间的关系,帮助系统做出更准确的决策。
Topological Graph Update:系统会根据新的观测数据更新其内部的拓扑图。拓扑图是一种抽象的地图表示,记录了已访问节点和未访问节点之间的连接关系。
Next Viewpoint Selection:基于更新后的拓扑图和多视图信息,系统选择下一个视角或位置作为移动目标。
Topological Navigation Policy:最后,系统根据上述所有信息执行拓扑导航策略,指导机器人或代理向目标位置移动。