Pytorch模型复现笔记-VGG讲解+架构搭建(可直接copy运行)+冒烟测试
Very Deep Convolutional Networks for Large Scale Image Recognition
- 中文名:专门用来做大规模图像识别的超深卷积神经网络 (VGG)
- 论文发表年份:2014
目录
- Very Deep Convolutional Networks for Large Scale Image Recognition
- 模型简介
- 提出背景
- 设计思路
- 达到效果
- 对后续模型的影响
- VGG网络结构
- Pytorch模型实现+冒烟测试
模型简介
VGG 架构由牛津大学视觉几何小组的 Karen Simonyan 和 Andrew Zisserman 于 2014 年开发,因此被命名为 VGG。该模型与当时的过去模型相比表现出显着改进——具体来说是 2014 年 Imagenet 挑战赛,也称为 ILSVRC。
提出背景
之前有哪些相同目的的模型?
在VGG模型被提出之前,深度卷积网络(CNN)的先驱是LeNet和AlexNet。LeNet在较小的灰度图像数据集上取得了成功,为后来的模型奠定了基础。而AlexNet则在2012年的ILSVRC挑战赛中取得了巨大成功,证明了深度卷积网络在大规模图像识别任务上的巨大潜力。
之前的模型有什么不足?
-
模型深度有限:例如,AlexNet只有8层(5个卷积层和3个全连接层),这使得它难以捕捉到图像中更复杂、更抽象的特征。研究者们普遍认为增加网络深度可以提升性能,但如何有效地做到这一点仍然是一个挑战。
-
卷积核尺寸不统一:AlexNet等模型使用了不同大小的卷积核(如11x11、5x5和3x3),这使得网络结构相对复杂,设计上缺乏一致性,也增加了超参数调优的难度。
设计思路
这个模型针对不足提出了什么改进方案?解决了什么问题?
VGG团队正是针对这些不足,提出了一个核心假设:通过增加网络的深度,并使用非常小的、统一的3x3卷积核,可以显著提高模型的性能。 他们的目标是系统性地研究网络深度对准确率的影响,并证明深度的增加是提高图像识别性能的关键因素。这直接导致了VGG架构的诞生,其设计思想简洁而有效,为后续的深度学习模型(如ResNet)提供了重要启示。
- Uniform Convolution FIlters: 始终使用3x3卷积滤波器,有助于简化结构,保持一致性(uniformity)
- 多个具有 ReLU 激活的小型 (3X3) 感受野滤波器而不是一个大型(7X7 或 11X11)滤波器可以更好地学习复杂特征。较小的卷积核也意味着每层的参数更少,中间引入了额外的非线性。
说实话不是很理解这里的uniformity是什么意思,设计一致性?还是设计更简洁?
-
Deep Architecture: 比之前所有的图片分类网络都深(AlexNet八层卷积层),以学习到更复杂的模式和特征
-
Multiscale training and inference: 多尺度训练和推理。每张图像都经过多轮不同比例的训练,以确保在不同尺寸下捕获相似的特征。
达到效果
在使用多网络和密集评估策略后
- top-1 val 性能吊打2014其他所有SOTA
- top-5 val/test 性能略逊googleLeNet 0.1个百分点
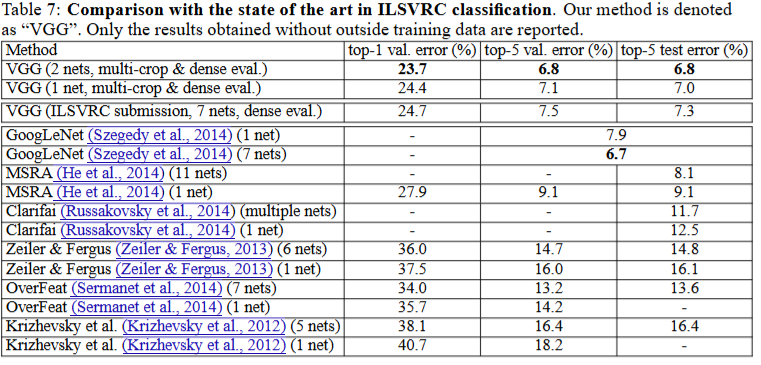
证明了VGG模型在图像分类任务上表现出色,特别是使用多网络和特定评估策略时。
对后续模型的影响
VGG结构上的简约有效性对后续深度学习模型的设计产生了深远影响,例如ResNet和Inception等架构都从VGG模型架构设计中的Deep Architecture 和 Uniform design思想中汲取了灵感。
其论文的最重要影响是证明了增加深度可以显著提高图像识别任务的性能。
VGG网络结构
这里以VGG19为例:
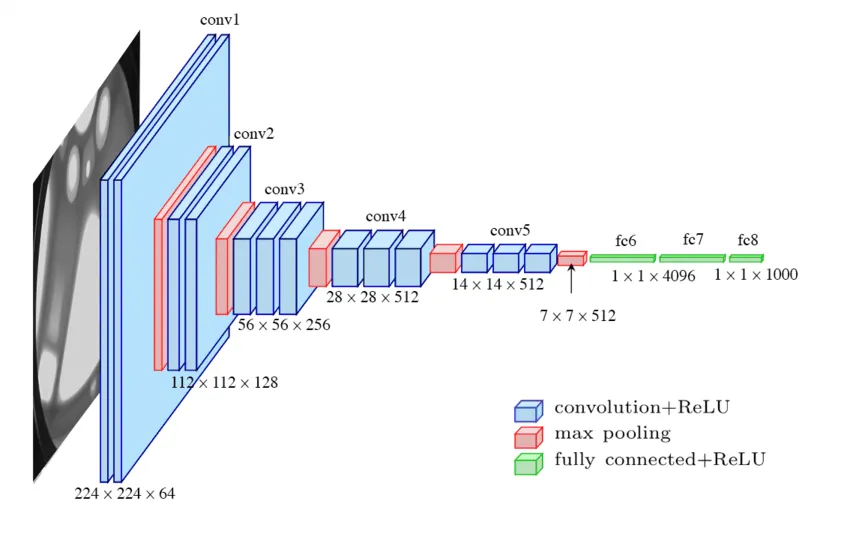
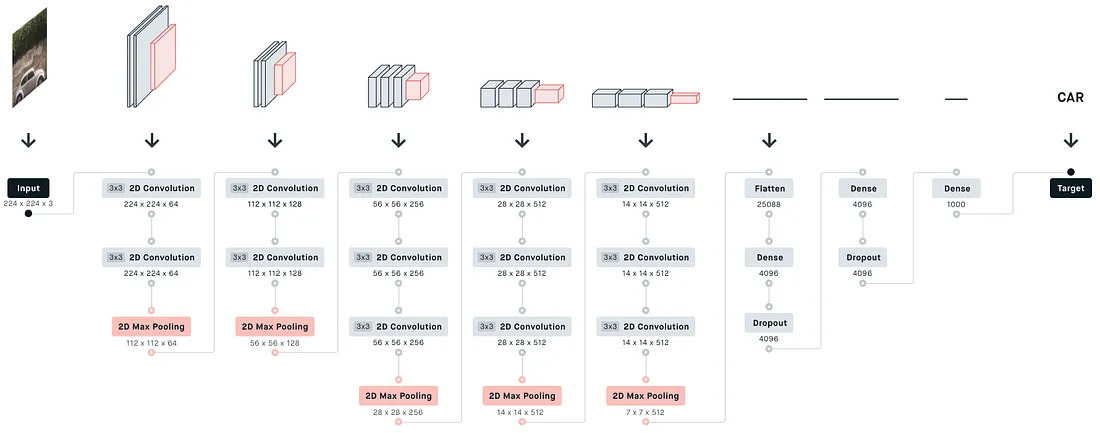
Pytorch模型实现+冒烟测试
import torch.nn as nn
import torchclass VGG19(nn.Module):def __init__(self, num_classes=1000):super().__init__()# 特征提取骨架,卷积和池化层self.feature_extractor = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.MaxPool2d(kernel_size=2, stride=2), # 此时尺寸减半nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.MaxPool2d(kernel_size=2, stride=2), # 尺寸再减半nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)# Pooling Layer, 一个神奇的层,无论输入特征图的尺寸是多少,它都会将其自适应地调整为指定的输出尺寸self.avgpool = nn.AdaptiveAvgPool2d(output_size=(7, 7))# 全连接层,用于分类self.classifier = nn.Sequential(nn.Flatten(), # 作为全连接层的第一步,展平向量nn.Linear(512 * 7 * 7, 4096),nn.ReLU(),nn.Dropout(0.5), # 随机给你禁用50%的神经元,加强鲁棒性nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(0.5),nn.Linear(4096, num_classes),)def forward(self, x):x = self.feature_extractor(x)x = self.avgpool(x)x = self.classifier(x)return x
# 冒烟测试
device = torch.accelerator.current_accelerator().type if torch.accelerator.is_available() else "cpu"
print(f"Using {device} device")
model = VGG19()
print(model)
input = torch.randn(1, 3, 224, 224, device=device)
output = model(input)
print(output[0].shape)