因果知识图谱:文本预处理的革命性突破
摘要
自然语言处理(NLP)正从表层统计关联向深层语义理解迈进。在这一进程中,为了解决深层语义分析而设计的、基于因果性的知识图谱(Causality-based Knowledge Graph, CKG)展现出巨大的潜力。本报告旨在深入探讨这种新型知识图谱对文本预处理三大核心环节——1. 数据清洗、2. 文本规范化、3. 词向量化——所带来的革命性积极影响。报告将结合现有研究成果和深度推理,通过具体的技术流程和详实示例,系统阐述CKG如何通过引入因果逻辑,提升预处理的准确性、鲁棒性和语义保真度。
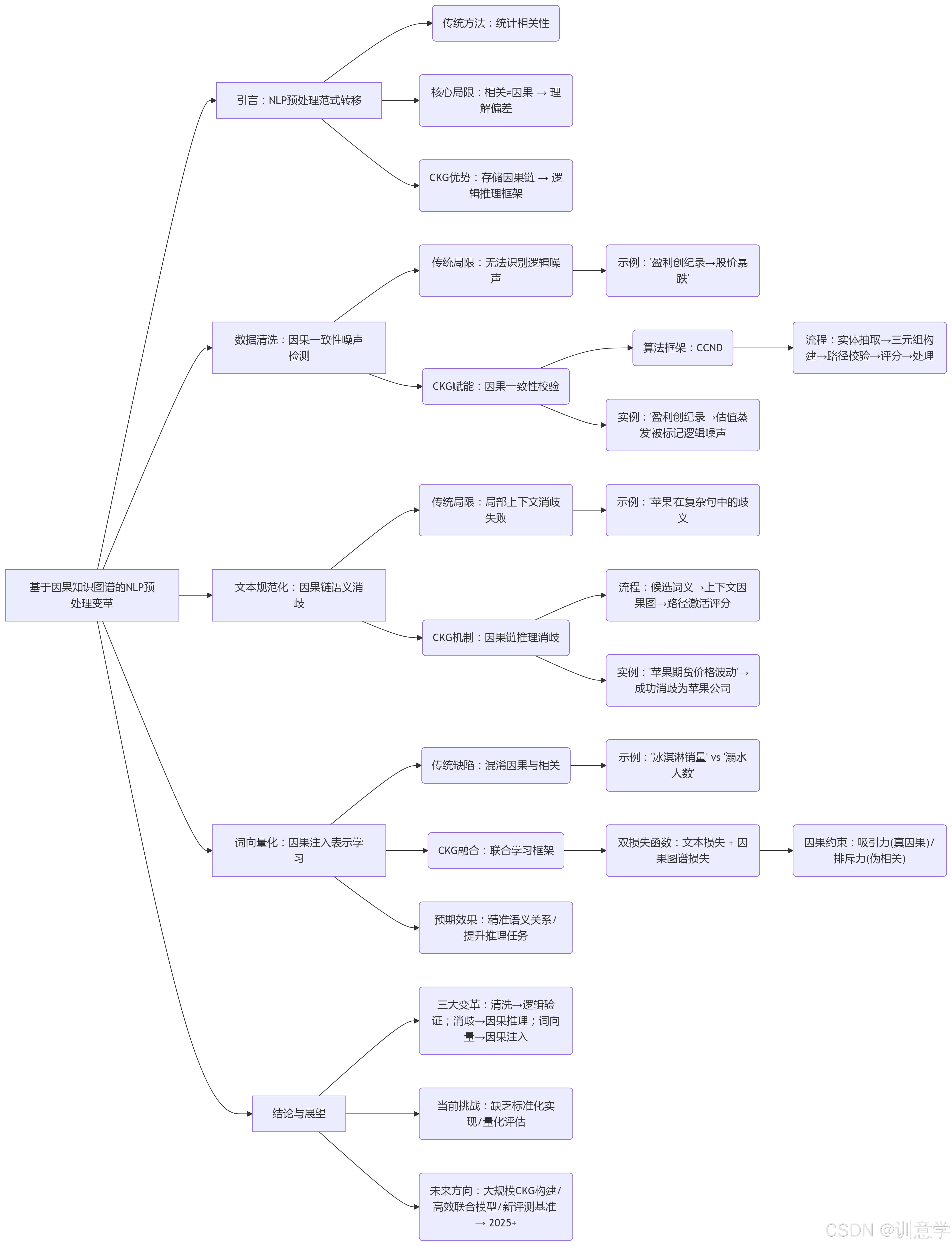
1. 引言:从关联到因果,NLP预处理的范式转移
传统的文本预处理技术,无论是数据清洗、文本规范化还是词向量化,在很大程度上依赖于统计学和模式匹配。例如,噪声检测依赖于异常值发现,词义消歧依赖于局部上下文共现,而词向量(如Word2Vec、GloVe)则完全基于词语的分布假设 。这些方法的核心是挖掘数据中的 “相关性”。然而,相关性不等于因果性 。仅仅依赖相关性会导致模型在面对复杂、反直觉或包含伪关系(spurious correlation)的文本时,表现出理解上的偏差和脆弱性。
一个专为深层语义分析设计的、基于因果性的知识图谱(CKG),其核心优势在于它不仅存储实体及其关系,更重要的是,它编码了实体与事件之间的 因果链条(Causal Chains)。这种图谱能够理解“什么导致了什么”,从而为机器提供了一种接近人类的、基于逻辑和世界知识的推理框架 。将CKG应用于文本预处理,意味着将这种深层因果推理能力前置到NLP流程的最开端,从根本上提升了后续所有任务的数据质量和语义表示的深度。
2. 对数据清洗的积极影响:基于因果一致性的智能噪声识别
数据清洗是NLP流水线的第一道防线,旨在识别并处理原始文本中的噪声,如事实错误、矛盾信息或不合逻辑的表述。传统方法通常难以辨别深层的语义噪声。
2.1. 传统数据清洗的局限
传统噪声检测方法多基于统计离群点、规则模板或简单的模式匹配。它们可以有效处理拼写错误、格式问题等表层噪声,但对于那些“语法正确但逻辑错误”的深层噪声则束手无策。例如,对于句子“该公司因产品创新获得巨额利润,导致其股价暴跌”,传统方法很难将其识别为噪声,因为它在语法和词汇层面均无懈可击。
2.2. 因果知识图谱如何赋能噪声检测
CKG通过引入“因果一致性校验”机制,彻底改变了噪声检测的逻辑。其核心思想是:一个真实、无噪声的陈述,在逻辑上应当与其所处世界知识的因果网络相容。CKG存储了大量的因果规则,例如 (产品创新成功) --[导致]--> (利润增加) 以及 (利润增加) --[导致]--> (投资者信心增强) --[导致]--> (股价上涨)。当文本中的陈述与CKG中的因果链发生冲突时,该陈述就极有可能是噪声 。
这种方法能够将噪声检测从表层语法检查提升到深层逻辑验证的层面。尽管当前直接针对NLP数据清洗的、基于CKG的噪声检测算法的已发表文献和开源实现尚不丰富 但结合现有的知识图谱清理 和因果发现框架 我们可以构建一个可行的技术框架。
2.3. 具体算法框架与示例
我们可以设计一个名为“ 因果一致性噪声检测(Causal Consistency Noise Detection, CCND) ”的算法框架。
算法流程:
- 实体与关系抽取: 从输入文本中抽取出核心的实体(如“公司A”、“产品X”)和关系事件(如“发布财报”、“股价上涨”)。
- 事实三元组构建: 将抽取的信息构建成事实三元组,例如
(公司A, 原因, 产品创新成功)和(公司A, 结果, 股价暴跌)。 - 因果路径校验: 将事实三元组在CKG中进行校验。算法会查询从“因果”节点(产品创新成功)到“结果”节点(股价暴跌)是否存在一条或多条高置信度的因果路径。
- 不一致性评分: CKG中的路径表明“产品创新成功”极大概率导向“股价上涨”。输入文本的陈述
(产品创新成功) -> (股价暴跌)与CKG的知识相悖。算法将基于这种冲突的严重程度(例如,路径方向完全相反),为该文本片段计算一个“因果不一致性分数”。 - 噪声标记与处理: 当不一致性分数超过预设阈值时,系统将该文本标记为“潜在逻辑噪声”。处理方式可包括:
- 高亮提示: 供人工审核员进一步确认。
- 自动修正建议: 如果CKG中有强证据表明“暴跌”可能是“飙升”的误写或错误报告,系统可以提出修正建议。
- 数据过滤: 在用于模型训练时,降低该条数据的权重或直接剔除。
详细示例:
- 输入文本: “在宣布全年盈利创纪录后,这家科技巨头的市场估值蒸发了20%。”
- 1. 实体与关系抽取:
- 实体:科技巨头
- 事件/原因:宣布全年盈利创纪录
- 事件/结果:市场估值蒸发20%
- 2. 事实三元组构建:
(科技巨头, 盈利创纪录, 导致, 估值蒸发20%) - 3. 因果路径校验 (在CKG中查询):
- CKG中存在一条强因果链:
(公司, 盈利创纪录)--[通常导致]-->(投资者信心, 增强)--[通常导致]-->(股票购买需求, 上升)--[通常导致]-->(市场估值, 上涨)。
- CKG中存在一条强因果链:
- 4. 不一致性评分: 输入文本的因果方向(盈利 -> 估值下降)与CKG中的主导因果路径(盈利 -> 估值上涨)完全相反。系统判定为高度因果不一致,给予高分。
- 5. 噪声标记: 系统将此句标记为 【高度疑似逻辑噪声】 ,并提示审核员:“盈利创纪录通常导致估值上涨,请核实该信息的准确性或是否存在其他未提及的关键负面因素。”
通过这种方式,CKG使数据清洗不再是盲目的异常检测,而是有理有据的逻辑推理过程。
3. 对文本规范化的积极影响:基于因果链的深度语义消歧
文本规范化的核心任务之一是解决词义歧义(Word Sense Disambiguation, WSD),特别是同形异义词(homograph)的问题。传统WSD方法严重依赖局部上下文,但对于需要更广阔世界知识和逻辑推理的场景则力不从心 。
3.1. 传统消歧方法的局限
以句子“苹果的股价最近不太稳定”为例。传统方法可能会分析“股价”、“稳定”等词与“苹果”的共现频率,从而推断此处的“苹果”指代公司。但如果句子变为“乔布斯创立的苹果,和砸在牛顿头上的苹果,都改变了世界”,传统方法仅靠局部窗口就很难准确区分两个“苹果”的不同含义。
3.2. 基于因果链的语义消歧机制
CKG为WSD提供了一个全新的、更强大的工具:因果链推理。其核心逻辑是:一个词语的正确含义,是那个能够与上下文中其他元素构成一条合乎逻辑的因果链的含义 。CKG中不仅有关于“苹果公司”的知识(如创始人是乔布斯、产品有iPhone、拥有股价),也有关于“苹果(水果)”的知识(如是一种水果、可以吃、从树上长出),更重要的是,它包含了这些实体参与的因果事件。
当遇到歧义词时,系统不再是简单地看周围有什么词,而是尝试将每个候选词义代入句子中,看哪个词义能与上下文形成最通顺、最强的因果通路。
3.3. 技术流程与详细示例
技术流程:
- 歧义词识别: 在文本中识别出存在多个词义的词语,如“苹果”。
- 候选词义提取: 从CKG中提取该词语的所有候选词义节点,例如
苹果(公司)和苹果(水果)。每个节点都连接着各自的属性和因果关系网络。 - 上下文因果图构建: 分析歧义词所在的句子及段落上下文,抽取出关键实体和事件,如“股价”、“上涨”、“财报”等,并将其映射到CKG中的相应节点。
- 因果路径激活与评分:
- 假设1: 假设“苹果”是
苹果(公司)。系统尝试在CKG中寻找连接苹果(公司)与上下文节点(如“股价”)的因果路径。它会轻易找到一条强路径:(苹果公司, 发布, 财报)--[影响]-->(苹果公司, 股价, 变动)。 - 假设2: 假设“苹果”是
苹果(水果)。系统尝试连接苹果(水果)与“股价”。在CKG中,苹果(水果)与股价之间几乎不存在直接或间接的强因果关联。苹果(水果)的因果链主要指向(价格, 变动)、(农业, 收成)等。
- 假设1: 假设“苹果”是
- 最佳词义选择: 能够与上下文形成最强、最合理因果路径的候选词义,即被选为最终的消歧结果。
苹果(公司)在该场景下得分远高于苹果(水果)。
端到端示例:
- 输入歧义句子: “受新iPhone发布和供应链中断双重影响,苹果的期货价格波动剧烈。”
- 1. 歧义词识别: “苹果”
- 2. 候选词义提取:
苹果(公司),苹果(水果) - 3. 上下文因果图构建:
- 上下文元素:
新iPhone发布(事件),供应链中断(事件),期货价格(实体),波动剧烈(状态)
- 上下文元素:
- 4. 因果链推理与解析:
- 路径激活(针对
苹果(公司)):苹果(公司)--[产品是]-->iPhone(新iPhone发布)--[是...的事件]-->苹果(公司)(供应链中断)--[影响]-->苹果(公司)的生产/销售苹果(公司)--[有金融衍生品]-->期货(供应链中断)和(新iPhone发布)--[共同导致]-->(市场预期, 变化)--[导致]-->(苹果公司期货价格, 波动剧烈)- 结论: 一条完整、强关联的因果链被构建起来。
- 路径激活(针对
苹果(水果)):苹果(水果)--[是一种农产品]-->(有, 期货)(例如,苹果汁期货)(供应链中断)--[可能影响]-->苹果(水果)的运输- 冲突/弱连接:
新iPhone发布这个事件与苹果(水果)之间不存在任何合理的因果联系。
- 路径激活(针对
- 5. 消歧后输出对照表:
| 原始词 | 上下文线索 | 推理依据(因果链) | 消歧结果 |
|---|---|---|---|
| 苹果 | 新iPhone发布, 供应链中断, 期货价格 | “新iPhone发布”是苹果公司的标志性事件,直接关联公司实体,与水果无关。 | 苹果(公司) |
通过这种方式,文本规范化不再是浅层的词汇替换,而是基于深度语义理解和逻辑推理的精确概念对齐,极大地提升了文本的语义清晰度和一致性。
4. 对词向量化的积极影响:从共现统计到因果注入的表示学习
词向量化旨在将词语映射到低维连续向量空间,以捕捉其语义信息。然而,主流的Word2Vec和GloVe等模型仅依赖词语共现的统计信息,这导致它们只能学到“相关性”而非“因果性” 。
4.1. 传统词向量的内在缺陷
- 因果与相关的混淆: 在夏季,“冰淇淋销量”和“溺水人数”的文本共现频率都很高。传统模型会认为它们的词向量很接近,但实际上它们之间没有因果关系,只是共享一个共同的原因——“炎热天气”。
- 语义关系表达粗糙: 传统模型难以区分不同类型的语义关系。例如,“医生”与“医院”(地点)、“手术刀”(工具)、“疾病”(对象)、“治疗”(行为)在文本中都可能与“医生”共现,但它们与“医生”的语义关系类型截然不同。
- 缺乏对世界知识的显式建模: 词向量完全从数据中学来,无法利用人类已经总结好的大量结构化知识。
4.2. 融合因果关系的词向量增强
将CKG融入词向量训练过程,可以从根本上解决上述问题。其核心思想是:让词向量的学习不仅要满足文本的分布一致性,还要满足知识图谱中的因果逻辑约束 。
实现机制:
这通常通过一个联合学习(Joint Learning)框架实现。模型的损失函数(Loss Function)由两部分构成:
- 文本损失 (Text Loss): 与传统模型类似,例如Word2Vec的Skip-gram损失,最大化文本中相邻词语的共现概率。
- 因果图谱损失 (Causal Graph Loss): 这部分是关键创新。它将CKG中的因果三元组(如
<原因, 导致, 结果>)转化为向量空间中的几何约束。例如:- 吸引力: 对于因果关系
<病毒, 导致, 疾病>,损失函数会促使vector("病毒")+vector("导致")的结果尽可能接近vector("疾病")。这会“拉近”在因果上强相关的概念。 - 排斥力: 对于已知的伪关系或非因果关系,可以设计损失项来“推开”它们的向量,比如之前提到的“冰淇淋销量”和“溺水人数”。
- 吸引力: 对于因果关系
通过优化这个联合损失函数,模型学到的词向量将内嵌因果逻辑。
4.3. 预期效果与评估指标
尽管在提供的搜索结果中,直接对比因果知识图谱增强词向量与Word2Vec/GloVe在标准基准(如WordSim-353, SimLex-999)上的公开量化结果非常稀缺 这本身就是一个重要的研究发现,表明该领域尚处在早期探索阶段。然而,我们可以从理论上预期以下积极效果:
- 更精准的语义相似度/相关性计算:
- 传统模型:
sim("医生", "医院")可能很高。 - 因果增强模型: 模型能区分关系类型,
sim("医生", "治疗")(因果/行为关系)的相关性得分会显著高于sim("医生", "医院")(地点关系),这更符合人类认知。
- 传统模型:
- 提升下游任务性能,特别是需要推理的任务:
- 因果问答(Causal QA): 对于问题“为什么A公司的股价下跌了?”,因果增强词向量能更好地理解“财报亏损”、“高管离职”等词语与“股价下跌”之间的因果联系,从而更准确地从文本中找到答案。
- 情感分析: 在“这家餐厅的食物很美味,但服务太慢了”中,模型能更好地将“美味”与“食物”关联,将“慢”与“服务”关联,实现更细粒度的情感归因。
- 评估指标:
- 内在评估: 除了传统的WordSim-353等相关性基准,需要设计新的、专门评估因果关系推理能力的基准数据集。例如,给出一对词(如“干旱”,“歉收”),看模型判断它们是否有因果关系的能力。
- 外在评估: 在需要深度语义理解的下游任务上进行评估,如关系抽取、事件抽取、文本蕴含和对话系统,并比较其性能提升(如准确率、F1分数)。
5. 结论与展望
基于因果性的知识图谱为文本预处理的三个核心环节带来了深刻的变革。
- 在数据清洗阶段,它通过因果一致性校验,将噪声检测从表层模式匹配提升至深层逻辑验证,能有效识别并处理以往难以发现的语义噪声。
- 在文本规范化阶段,它利用因果链推理进行语义消歧,超越了传统依赖局部上下文的局限,使得歧义词的解析更加精准、更符合全局逻辑。
- 在词向量化阶段,它通过将因果约束注入表示学习,使得词向量能够区分相关性与因果性,捕捉更丰富、更结构化的语义关系,为下游任务提供了质量更高的输入。
然而,本研究也发现,尽管这一方向前景广阔,但目前仍处于发展的初期。相关研究的一个显著空白是, 缺乏标准化的、经过同行评审的、可复现的算法实现(包括伪代码和复杂度分析) 以及在公认基准上与传统方法进行全面比较的量化实证研究 。
展望未来(2025年以后),我们预测该领域的研究将集中在以下几个方面:1)构建更大规模、更高质量的开放域因果知识图谱;2)设计更高效、更鲁棒的因果关系与文本表示的联合学习模型;3)创建全新的评测基准,以更全面地衡量模型在因果推理方面的能力。毫无疑问,随着这些研究的深入,基于因果的深层语义理解必将成为下一代自然语言处理技术的核心驱动力。