【论文笔记】STORYWRITER: A Multi-Agent Framework for Long Story Generation
论文信息
论文标题:StoryWriter: A Multi-Agent Framework for Long Story Generation
论文作者:Haotian Xia, Hao Peng et al. (Tsinghua University)
论文链接:https://arxiv.org/abs/2506.16445
代码链接:https://github.com/THU-KEG/StoryWriter 未提供运行代码
研究背景与动机
核心挑战: 现有大语言模型(LLMs)生成长篇故事(>1000词)存在两大瓶颈:
- 语篇连贯性(Discourse Coherence):长文本中难以维持情节一致性、逻辑连贯性与完整性(如角色/事件关系丢失)。
- 叙事复杂性(Narrative Complexity):LLM生成故事同质化严重,缺乏人类叙事的交织结构与吸引力。
现有方法局限: 传统基于LLM的提纲生成方法缺乏细粒度事件控制,导致生成内容单一且逻辑松散。
核心贡献
- 提出了一种多智能体框架 STORYWRITER ,用于高质量长篇故事生成。
- 构建了一个高质量的长篇故事数据集 LONGSTORY ,包含约6000个平均长度为8000词的故事。
- 基于 LONGSTORY 对 Llama3.1-8B 和 GLM4-9B 进行监督微调,训练出性能优越的长篇故事生成模型 STORYWRITERLLAMA 和 STORYWRITERGLM 。
- 在多个评估指标上验证了 STORYWRITER 的有效性,并通过消融实验分析各模块的作用。
StoryWriter
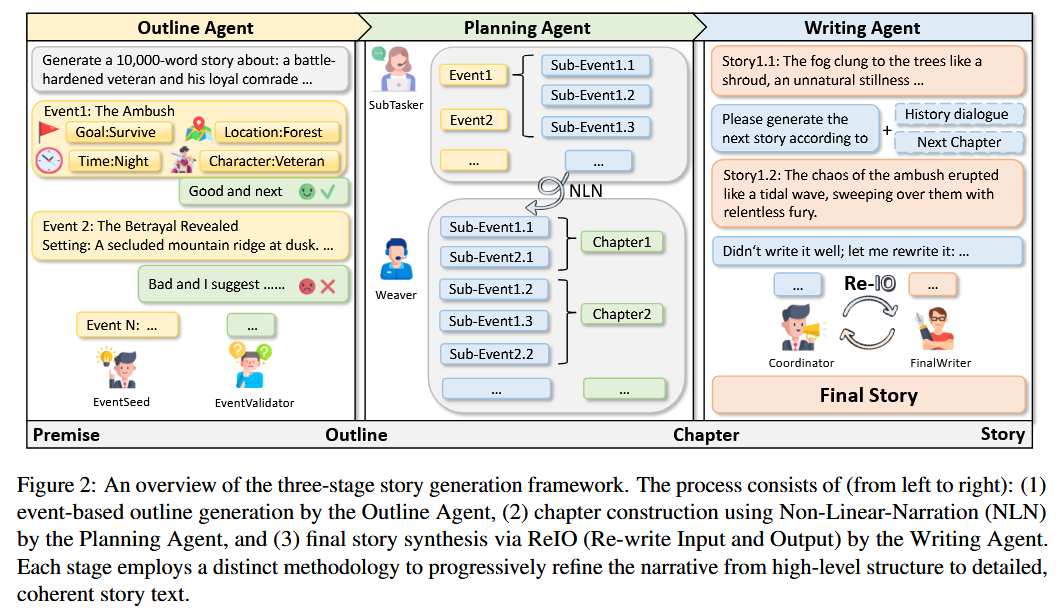
StoryWriter 框架在 Auto-Gen 框架下实现 ,其 Agent 网络由以下三个主要模块组成:
Outline Agent
- 该模块负责生成基于事件的大纲,其中包含丰富的事件情节、人物和事件-事件关系 。
- 它由两个专门的Agent构成:
EventSeed和EventValidator EventSeed负责根据给定的前提(premise)顺序生成事件,为每个事件提供时间、地点和关系等基本信息 。EventValidator持续监控和评估生成的大纲,提供反馈以确保每个事件的合理性和叙事连贯性 。- 与传统的大纲生成方法不同,该方法将大纲构建为一系列事件元组,从而增强了可控性和逻辑一致性 。
Planning Agent
- 该模块进一步细化事件,并全局规划每个章节应包含哪些事件,以保持故事的交织性和吸引力 。
- 它引入了“非线性叙事”(Non-Linear Narration, NLN)策略,将事件分解为子事件,并有策略地将它们分布在不同的章节中 。
- 该模块由
SubTasker和Weaver组成 。 SubTasker负责将高级别事件分解为更细粒度的叙事单元,即子事件 。Weaver则将这些子事件分配到不同的章节中,即使它们以非时间顺序呈现,也能保持整体叙事结构的连贯性 。- 这种方法克服了线性叙事的单调性,增强了叙事的多样性和读者的参与度 。
Writing Agent
- 该模块根据历史上下文生成和完善具体的故事内容 。
- 它采用了一个名为“重写输入和输出”(Re-write Input and Output, ReIO)的机制,由
Coordinator和FinalWriter两个Agent协作完成 。 - 在输入处理阶段,
Coordinator动态地压缩历史叙事上下文,只保留与当前子事件相关的信息,从而有效减少输入长度并保持关键上下文 。 - 在输出处理阶段,
Coordinator会评估生成的文本,并在必要时对其进行重写,以确保其与预定叙事结构和风格要求的一致性 。 - 这种分工确保了宏观结构连贯性和微观叙事流畅性 。
实验部分
实验设置
- 数据集: 评估采用 MoPS 数据集 。
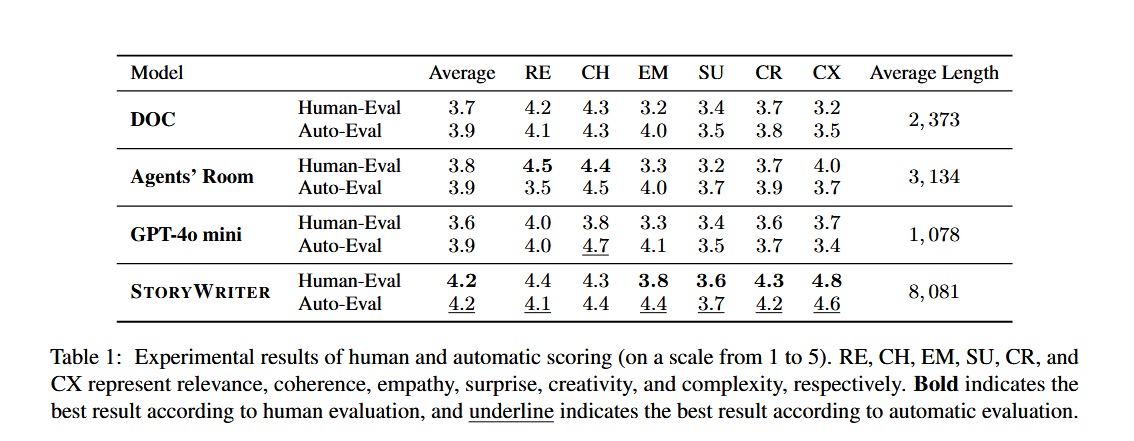
- 评估方法: 采用人工评估和基于GPT-4o的自动评估,涵盖六个维度:相关性(Relevance)、连贯性(Coherence)、同理心(Empathy)、意外性(Surprise)、创造性(Creativity)和复杂性(Complexity)。
- 基线模型: DOC、Agents’ Room 和 GPT-4o-mini 。
实验结果
主要实验
StoryWriter 在人工和自动评估中均显著优于所有基线模型 。它在保持高质量的同时,显著超越了以往基线模型的生成长度 。在内容多样性和创造性方面 StoryWriter 表现突出 。
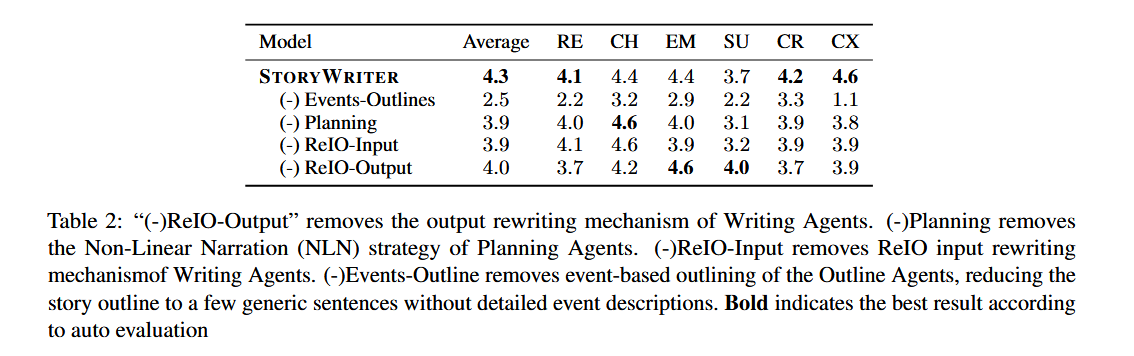
消融实验
- 移除大纲Agent: 故事大纲缺乏深度和结构,导致所有评估指标显著下降 。
- 移除规划Agent: 子事件严格按时间顺序排列,导致复杂性得分显著降低 。
- 移除ReIO-Input: 输入文本长度大幅增加,导致计算成本上升和整体性能下降 。
- 移除ReIO-Output: 生成文本的相关性得分显著下降,因为该模块对于维持结构连贯性至关重要。
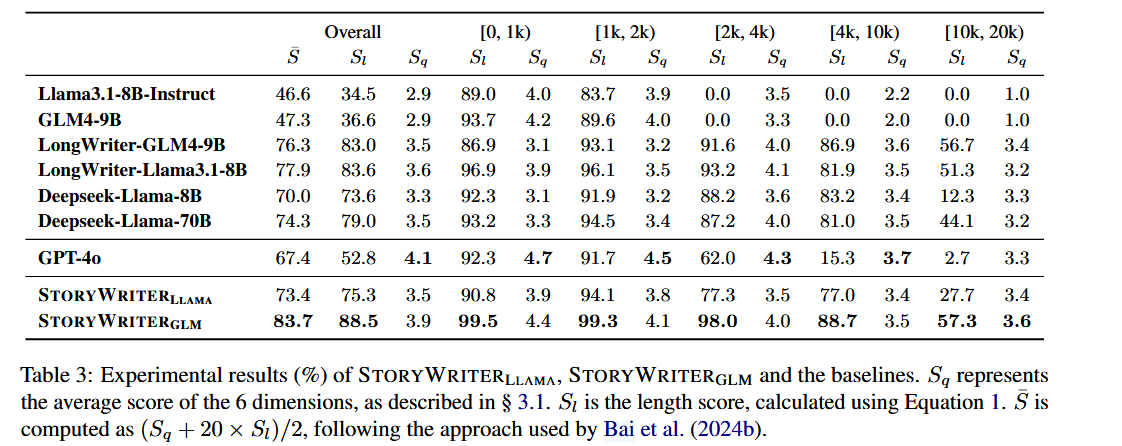
LONGSTORY 数据集与模型训练
- 数据集构建: LONGSTORY 数据集是使用 StoryWriter 框架,从 MoPS 训练集中收集的6000个故事前提生成而成的 。经过数据清洗,最终包含5500个平均长度约8000字的高质量长篇故事 。
- 模型微调: 使用 LONGSTORY 数据集,通过监督微调(SFT)训练了基于 Llama3.1-8B 和 GLM-4-9B 的模型 。
- 评估指标: 采用 LongBench-Write 评估方法,包括内容质量分数 SqS_qSq、SlS_lSl,和综合分数 Sˉ\bar{S}Sˉ。
- 结果:
- StoryWriter-GLM 在故事质量 SqS_qSq 上显著优于其基础模型,尤其是在生成超过 4000 字的故事时。
- StoryWriter-Llama 和 StoryWriter-GLM 在长度分数 SlS_lSl 也远优于 Llama3.1-8B-Instruct 和 GPT-4o,这表明即使训练中没有明确的长度约束增强,训练长文本也能提高模型遵循长度约束的能力 。
总结
- 研究只考虑了英文,并不支持多语言生成
- 只关注了小说故事生成,并未考虑其他艺术风格
- 该文章中的复杂叙事结构,其实就是把 生成的 Outline 在扩写后,交给 LLM 重构了 Outline 的顺序,这样不能解决实际问题,只是表面上的工作,该处可以参考 Multi-Agent Based Character Simulation for Story Writing 中对于复杂叙事结构的描述,或许有参考价值。
- 生成长度为 4000 字,并不能很好的解决小说的故事生成,还是个 toy。