Flink Stream API 源码走读 - print()
概述
本文深入分析了 Flink 中 print() 方法的源码实现,展示了 Sink 操作的完整流程,并通过调试验证了整个 Transformation 链条的构建过程。这是 Flink Stream API 系列课程的重要一环,帮助我们理解流处理 Pipeline 的终端操作机制。
1. print() 方法概览
1.1 在 WordCount 示例中的使用
// 数据处理流水线
DataStream<Tuple2<String, Integer>> wordCounts = text.map(value -> value).flatMap(new Splitter()) // 分词.keyBy(value -> value.f0) // 按单词分组.window(TumblingProcessingTimeWindows.of(Time.seconds(5))) // 5秒滚动窗口.sum(1); // 对计数字段求和// 打印结果 - 这里调用了 print()
wordCounts.print();
1.2 print() 方法的作用
核心特点:
- 终端操作 - 标志着流处理 Pipeline 的结束
- 返回类型变化 - 从
DataStream变为DataStreamSink - 断开链式调用 - 不能再调用 map、filter 等转换操作
2. print() 方法源码深度分析
2.1 DataStream.print() 入口方法
// DataStream.java 中的实现
@PublicEvolving
public DataStreamSink<T> print() {// 创建打印输出函数PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();return addSink(printFunction).name("Print to Std. Out");
}
执行流程:
- 创建
PrintSinkFunction实例 - 调用
addSink()方法 - 设置算子名称为 “Print to Std. Out”
- 返回
DataStreamSink对象
2.2 PrintSinkFunction 业务逻辑分析
@PublicEvolving
public class PrintSinkFunction<IN> extends RichSinkFunction<IN>implements SupportsConcurrentExecutionAttempts {private final PrintSinkOutputWriter<IN> writer;public PrintSinkFunction() {writer = new PrintSinkOutputWriter<>(false); // 输出到 stdout}@Overridepublic void invoke(IN record) {writer.write(record); // 实际的打印逻辑}
}
关键组件说明:
- RichSinkFunction - 提供丰富的生命周期方法
- PrintSinkOutputWriter - 负责具体的输出格式化和写入
- invoke() - 每条数据都会调用此方法进行处理
3. addSink() 方法核心流程
3.1 addSink 方法源码分析
// DataStream.java
public DataStreamSink<T> addSink(SinkFunction<T> sinkFunction) {// 1. 读取输出类型,检查类型信息transformation.getOutputType();// 2. 配置类型(如果需要)if (sinkFunction instanceof InputTypeConfigurable) {((InputTypeConfigurable) sinkFunction).setInputType(getType(), getExecutionConfig());}// 3. 调用静态工厂方法return DataStreamSink.forSinkFunction(this, clean(sinkFunction));
}
addSink 执行步骤:
- 类型检查 - 确保类型信息正确
- 类型配置 - 为支持类型配置的 SinkFunction 设置输入类型
- 函数清理 - 通过
clean()方法处理闭包和序列化 - 委托创建 - 调用
DataStreamSink.forSinkFunction()静态方法
3.2 DataStreamSink.forSinkFunction() 详解
// DataStreamSink.java
static <T> DataStreamSink<T> forSinkFunction(DataStream<T> inputStream, SinkFunction<T> sinkFunction) {// 1. Function → Operator:将 SinkFunction 包装成 StreamSink 命名不好,再次吐槽为啥不叫StreamSinkOperatorStreamSink<T> sinkOperator = new StreamSink<>(sinkFunction);final StreamExecutionEnvironment executionEnvironment =inputStream.getExecutionEnvironment();// 2. Operator → Transformation:创建 LegacySinkTransformationPhysicalTransformation<T> transformation =new LegacySinkTransformation<>(inputStream.getTransformation(), // 上游 transformation"Unnamed", // 算子名称sinkOperator, // Sink 算子executionEnvironment.getParallelism(), // 并行度false); // 并行度是否已配置// 3. 添加到执行环境executionEnvironment.addOperator(transformation);// 4. 创建 DataStreamSinkreturn new DataStreamSink<>(transformation);
}
3.3 分层抽象设计
转换层次详解:
- Function 层 - 用户定义的业务逻辑(PrintSinkFunction)
- Operator 层 - Flink 内部算子封装(StreamSink)
- Transformation 层 - 执行图节点(LegacySinkTransformation)
- DataStream 层 - 流式 API 封装(DataStreamSink)
- Environment 层 - 全局管理和优化
3.4 StreamSink 详情
public class StreamSink<IN> extends AbstractUdfStreamOperator<Object, SinkFunction<IN>>implements OneInputStreamOperator<IN, Object> {public StreamSink(SinkFunction<IN> sinkFunction) {super(sinkFunction);chainingStrategy = ChainingStrategy.ALWAYS; // 总是可以链接}
}
StreamSink 的核心特性:
- 继承 AbstractUdfStreamOperator - 获得用户函数管理能力
- 实现 OneInputStreamOperator - 单输入流算子接口
- ChainingStrategy.ALWAYS - 总是可以与上游算子链接优化
3.4 DataStreamSink 的结构分析
@Public
public class DataStreamSink<T> {private final PhysicalTransformation<T> transformation;protected DataStreamSink(PhysicalTransformation<T> transformation) {this.transformation = checkNotNull(transformation);}// 注意:没有继承 DataStream,没有 map、filter 等方法
}
DataStreamSink 的设计特点:
- 不继承 DataStream - 有意断开链式调用链
- 只持有 Transformation - 极简设计,表示流的终止
- 终端节点 - 标志 Pipeline 的结束点
- 不可扩展 - 防止在终端节点后继续添加操作
3.5 print() 方法完整时序图
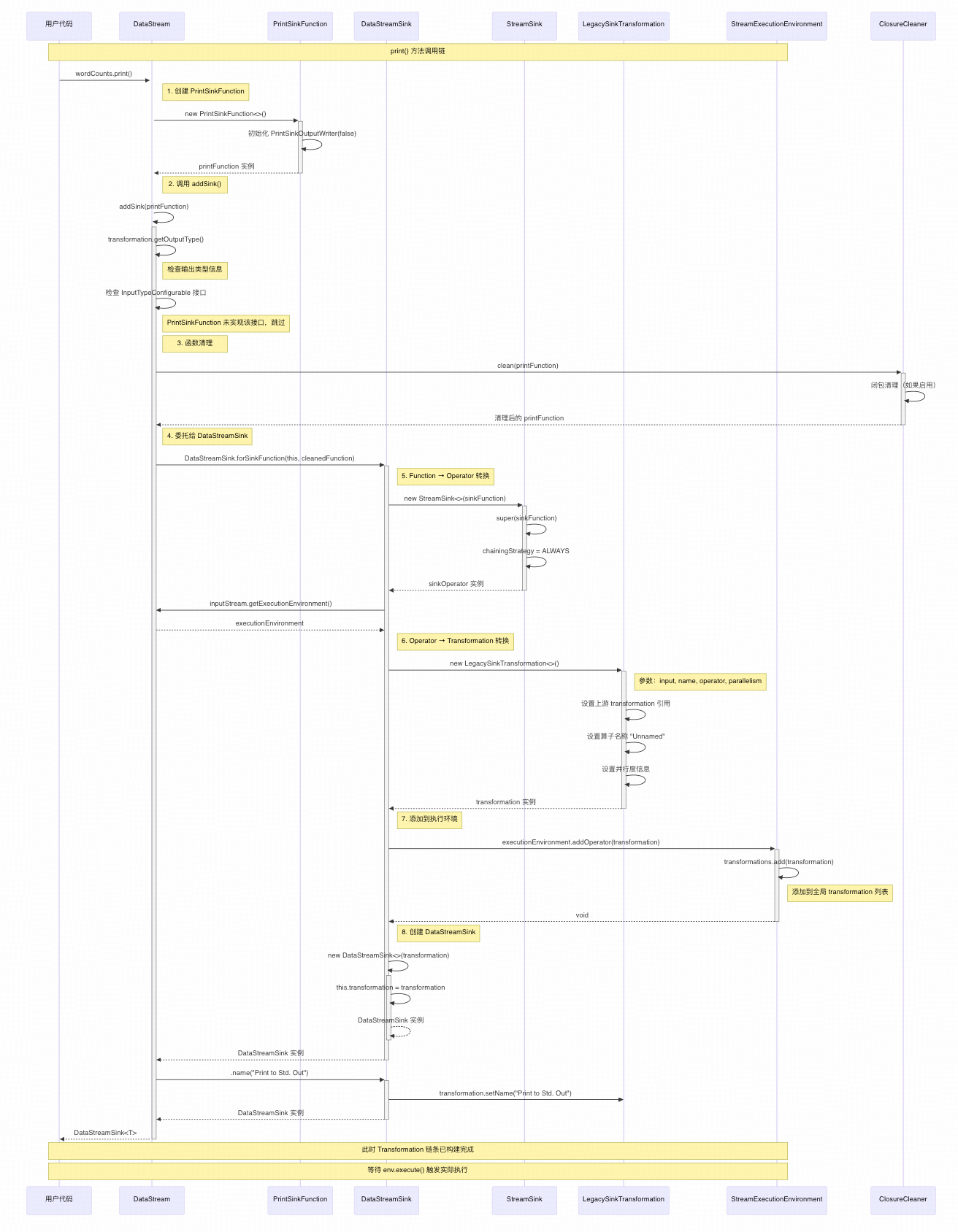
时序图关键步骤说明:
- Function 创建 - 实例化 PrintSinkFunction,内部创建 PrintSinkOutputWriter
- 类型检查 - 验证输出类型信息,确保类型安全
- 函数清理 - 通过 ClosureCleaner 处理闭包和序列化问题
- 分层转换 - Function → Operator → Transformation 的逐层包装
- 环境注册 - 将 Transformation 添加到执行环境的全局列表
- API 封装 - 创建 DataStreamSink 作为用户 API 的返回值
4. Transformation 拓展
4.1 Environment 中的 Transformation 管理
// StreamExecutionEnvironment 中的核心管理
private final List<Transformation<?>> transformations = new ArrayList<>();public void addOperator(Transformation<?> transformation) {// 只有物理 Transformation 才会被添加transformations.add(transformation);
}
4.2 Environment 添加规则分析
重要发现:Environment 中只有 4个 Transformation(不是6个)
| ID | Transformation类型 | 算子名称 | 物理/虚拟 | 添加到Environment |
|---|---|---|---|---|
| 1 | LegacySourceTransformation | socketTextStream | 物理 | ❌ 特殊处理 |
| 2 | OneInputTransformation | map | 物理 | ✅ |
| 3 | OneInputTransformation | flatMap | 物理 | ✅ |
| 4 | PartitionTransformation | keyBy | 虚拟 | ❌ 虚拟节点 |
| 5 | OneInputTransformation | window.sum | 物理 | ✅ |
| 6 | LegacySinkTransformation | 物理 | ✅ |
核心规律:
- 物理 Transformation - 代表真实的计算操作,添加到 Environment
- 虚拟 Transformation - 仅用于逻辑表示和优化,不添加到 Environment
- Source Transformation - 特殊的物理节点,但不添加到 Environment(特殊处理)
4.3 链式引用的数据结构
// 每个 Transformation 都持有上游的引用
public abstract class Transformation<T> {// 大部分 Transformation 都有 input 字段
}// 示例:OneInputTransformation
public class OneInputTransformation<IN, OUT> extends PhysicalTransformation<OUT> {private final Transformation<IN> input; // 指向上游
}// 示例:LegacySinkTransformation
public class LegacySinkTransformation<T> extends PhysicalTransformation<T> {private final Transformation<T> input; // 指向上游
}
4.4 完整的链式引用追溯

4.5 链式引用的核心价值
通过最后一个 Transformation 获取完整执行图:
// 从 DataStreamSink 开始追溯
DataStreamSink<String> sink = wordCounts.print();
LegacySinkTransformation sinkTransformation = sink.getTransformation();// 递归追溯整个链条
Transformation current = sinkTransformation;
while (current != null) {System.out.println("Transformation: " + current.getName());current = current.getInput(); // 获取上游
}
链式引用的优势:
- 完整性 - 通过最后一个节点可以追溯到整个执行图
- 简洁性 - 每个节点只需保存直接上游的引用
- 灵活性 - 支持复杂的 DAG 结构(多输入、分支等)
- 优化友好 - 便于执行计划的分析和优化
返回目录
Flink 源码系列 - 前言