【完整源码+数据集+部署教程】太阳能面板污垢检测系统源码和数据集:改进yolo11-RVB-EMA
背景意义
研究背景与意义
随着全球对可再生能源的关注不断增加,太阳能作为一种清洁且可持续的能源形式,逐渐成为各国能源结构的重要组成部分。然而,太阳能面板的效率受多种因素影响,其中污垢和污染物的积累是影响其发电效率的主要因素之一。面板表面的污垢不仅会遮挡阳光,还可能导致热量积聚,从而降低面板的使用寿命。因此,及时检测和清洁太阳能面板上的污垢显得尤为重要。
在这一背景下,基于计算机视觉的污垢检测系统应运而生。通过深度学习技术,尤其是目标检测算法的应用,可以实现对太阳能面板表面污垢的自动化检测。这不仅提高了检测的效率和准确性,还减少了人工检测所需的时间和成本。近年来,YOLO(You Only Look Once)系列算法因其高效的实时检测能力而受到广泛关注。改进YOLOv11模型,结合针对太阳能面板污垢的特定数据集,可以显著提升污垢检测的性能。
本研究所使用的数据集包含3800张经过精细标注的图像,涵盖了六种不同的污垢类别,包括“Az Kirli”(轻微污垢)、“Cok Kirli”(严重污垢)、“Kirik”(破损)、“Kus Pisligi”(鸟粪)、“Lekeli”(污渍)和“Temiz”(干净)。这些多样化的类别为模型的训练提供了丰富的样本,有助于提高其在实际应用中的泛化能力。通过对数据集的深入分析和模型的改进,本研究旨在开发出一种高效、准确的太阳能面板污垢检测系统,以促进太阳能行业的可持续发展,提升太阳能发电的经济效益和环境效益。
图片效果

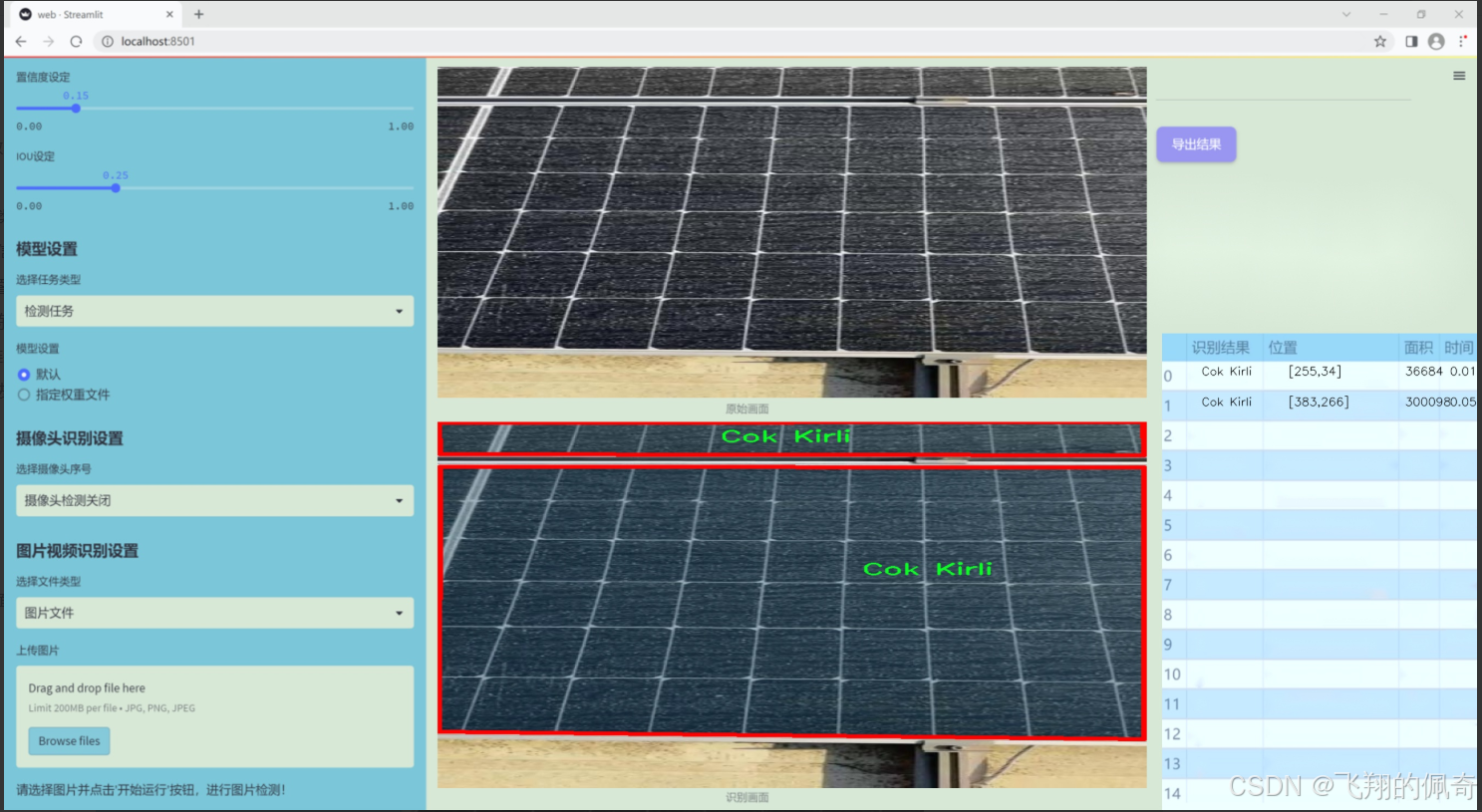
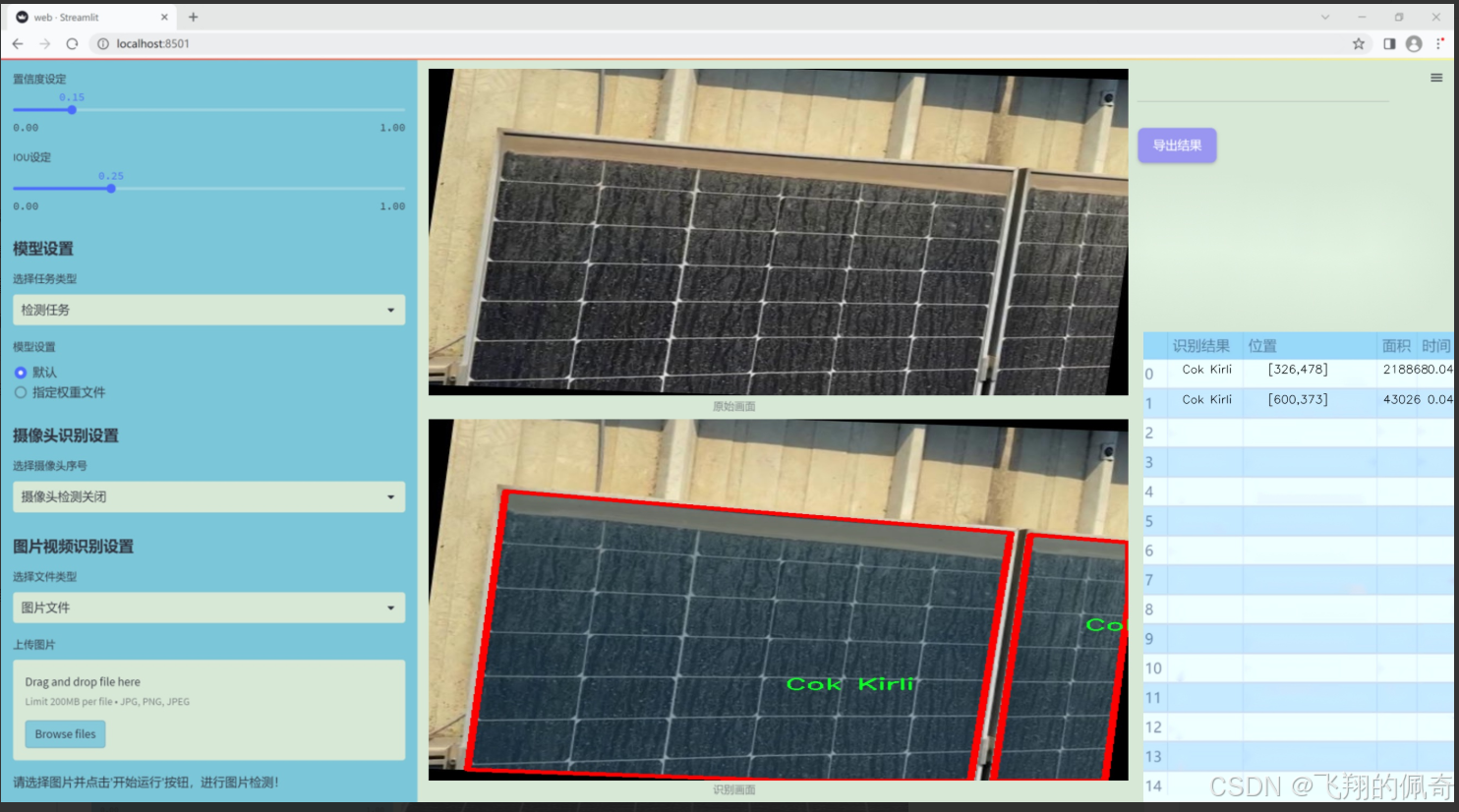
数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在支持改进YOLOv11的太阳能面板污垢检测系统,专注于对太阳能面板表面污垢状态的精准识别与分类。数据集的主题为“gunes_panelleri”,涵盖了多种与太阳能面板清洁度相关的类别,具体包括六个主要类别:‘Az Kirli’(轻微污垢)、‘Cok Kirli’(严重污垢)、‘Kirik’(破损)、‘Kus Pisligi’(鸟粪)、‘Lekeli’(污渍)和‘Temiz’(干净)。这些类别的设定不仅反映了太阳能面板在实际使用过程中可能遭遇的各种污染情况,也为模型的训练提供了丰富的样本。
数据集中的每个类别均包含大量高质量的图像,确保了模型在训练过程中能够获得充分的特征学习。通过对不同污垢状态的图像进行标注,数据集为YOLOv11的训练提供了坚实的基础,使其能够在实际应用中有效区分面板的清洁程度。这种细致的分类不仅有助于提高检测的准确性,也为后续的清洁维护决策提供了科学依据。
在数据集的构建过程中,考虑到了光照、角度、背景等多种因素,以确保模型在不同环境下的鲁棒性。此外,数据集的多样性和丰富性使得模型能够适应不同地区和气候条件下的太阳能面板清洁度检测需求。通过不断优化和扩展数据集,我们期望能够提升YOLOv11在实际应用中的表现,从而推动太阳能行业的可持续发展。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class KACNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, dropout=0.0):
super(KACNConvNDLayer, self).init()
# 初始化输入和输出维度、卷积参数等self.inputdim = input_dimself.outdim = output_dimself.degree = degreeself.kernel_size = kernel_sizeself.padding = paddingself.stride = strideself.dilation = dilationself.groups = groupsself.ndim = ndim# 如果设置了dropout,则根据维度选择相应的Dropout层self.dropout = Noneif dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查groups参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 为每个组创建归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 创建多项式卷积层self.poly_conv = nn.ModuleList([conv_class((degree + 1) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 注册一个缓冲区,用于存储0到degree的范围arange_buffer_size = (1, 1, -1,) + tuple(1 for _ in range(ndim))self.register_buffer("arange", torch.arange(0, degree + 1, 1).view(*arange_buffer_size))# 使用Kaiming均匀分布初始化卷积层的权重for conv_layer in self.poly_conv:nn.init.normal_(conv_layer.weight, mean=0.0, std=1 / (input_dim * (degree + 1) * kernel_size ** ndim))def forward_kacn(self, x, group_index):# 对输入应用激活函数,并进行线性变换x = torch.tanh(x) # 应用tanh激活函数x = x.acos().unsqueeze(2) # 计算反余弦并增加维度x = (x * self.arange).flatten(1, 2) # 与arange相乘并展平x = x.cos() # 计算余弦x = self.poly_conv[group_index](x) # 通过对应的卷积层x = self.layer_norm[group_index](x) # 进行归一化if self.dropout is not None:x = self.dropout(x) # 应用dropoutreturn xdef forward(self, x):# 将输入按组分割split_x = torch.split(x, self.inputdim // self.groups, dim=1)output = []for group_ind, _x in enumerate(split_x):y = self.forward_kacn(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone())y = torch.cat(output, dim=1) # 将输出拼接return y
代码核心部分说明:
KACNConvNDLayer类:这是一个自定义的神经网络层,支持任意维度的卷积操作。它的构造函数接受多个参数,包括输入和输出维度、卷积核大小、分组数等。
前向传播方法:
forward_kacn方法:对输入进行一系列变换,包括激活、反余弦、乘以arange、余弦计算、卷积和归一化。
forward方法:将输入按组分割,逐组调用forward_kacn进行处理,并将结果拼接。
权重初始化:使用Kaiming均匀分布初始化卷积层的权重,以便于训练开始时的表现。
Dropout:根据输入的维度选择合适的Dropout层,帮助防止过拟合。
通过这些核心部分的组合,KACNConvNDLayer能够实现灵活的卷积操作,并支持多种归一化和激活方式。
这个程序文件定义了一个名为 kacn_conv.py 的 PyTorch 模块,主要实现了一种新的卷积层,称为 KACN(K-阶激活卷积网络)。该模块包含了一个基础的多维卷积层 KACNConvNDLayer,以及针对不同维度(1D、2D、3D)的具体实现类。
首先,KACNConvNDLayer 类是一个继承自 nn.Module 的自定义层。它的构造函数接收多个参数,包括卷积类型、归一化类型、输入和输出维度、卷积核大小、组数、填充、步幅、扩张、维度数量和丢弃率等。构造函数中首先对输入参数进行验证,确保组数为正整数,并且输入和输出维度能够被组数整除。
在构造函数中,还会根据给定的维度创建相应的丢弃层(Dropout),并初始化多个卷积层和归一化层。卷积层的数量与组数相同,每个卷积层的输入通道数为 (degree + 1) * input_dim / groups,输出通道数为 output_dim / groups。此外,使用 Kaiming 正态分布初始化卷积层的权重,以帮助模型更好地收敛。
forward_kacn 方法实现了 KACN 的前向传播逻辑。它首先对输入进行激活,然后通过一系列的数学变换(如反余弦、乘以预定义的缓冲区、余弦等)处理输入,最后通过对应的卷积层和归一化层进行处理。如果定义了丢弃层,则在最后应用丢弃操作。
forward 方法负责处理整个输入数据。它将输入数据按组进行分割,然后对每个组调用 forward_kacn 方法进行处理,最后将所有组的输出拼接在一起。
接下来的三个类 KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer 分别继承自 KACNConvNDLayer,用于实现三维、二维和一维的 KACN 卷积层。这些类在初始化时指定了对应的卷积和归一化层类型(如 nn.Conv3d、nn.Conv2d 和 nn.Conv1d),并传递其他参数。
总体来说,这个模块提供了一种灵活的方式来创建多维卷积层,结合了多项式卷积和归一化操作,适用于各种深度学习任务。
10.4 fadc.py
以下是代码中最核心的部分,保留了主要的类和方法,并添加了详细的中文注释。
import torch
import torch.nn as nn
import torch.nn.functional as F
class OmniAttention(nn.Module):
def init(self, in_planes, out_planes, kernel_size, groups=1, reduction=0.0625, kernel_num=4, min_channel=16):
super(OmniAttention, self).init()
# 计算注意力通道数
attention_channel = max(int(in_planes * reduction), min_channel)
self.kernel_size = kernel_size
self.kernel_num = kernel_num
self.temperature = 1.0 # 温度参数,用于控制注意力的平滑程度
# 定义平均池化层self.avgpool = nn.AdaptiveAvgPool2d(1)# 定义全连接层和批归一化层self.fc = nn.Conv2d(in_planes, attention_channel, 1, bias=False)self.bn = nn.BatchNorm2d(attention_channel)self.relu = nn.ReLU(inplace=True)# 定义通道注意力的全连接层self.channel_fc = nn.Conv2d(attention_channel, in_planes, 1, bias=True)self.func_channel = self.get_channel_attention# 根据输入和输出通道数决定过滤器的注意力函数if in_planes == groups and in_planes == out_planes: # 深度可分离卷积self.func_filter = self.skipelse:self.filter_fc = nn.Conv2d(attention_channel, out_planes, 1, bias=True)self.func_filter = self.get_filter_attention# 根据卷积核大小决定空间注意力函数if kernel_size == 1: # 点卷积self.func_spatial = self.skipelse:self.spatial_fc = nn.Conv2d(attention_channel, kernel_size * kernel_size, 1, bias=True)self.func_spatial = self.get_spatial_attention# 根据卷积核数量决定核注意力函数if kernel_num == 1:self.func_kernel = self.skipelse:self.kernel_fc = nn.Conv2d(attention_channel, kernel_num, 1, bias=True)self.func_kernel = self.get_kernel_attentionself._initialize_weights() # 初始化权重def _initialize_weights(self):# 权重初始化for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)if isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)def get_channel_attention(self, x):# 计算通道注意力channel_attention = torch.sigmoid(self.channel_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return channel_attentiondef get_filter_attention(self, x):# 计算过滤器注意力filter_attention = torch.sigmoid(self.filter_fc(x).view(x.size(0), -1, 1, 1) / self.temperature)return filter_attentiondef get_spatial_attention(self, x):# 计算空间注意力spatial_attention = self.spatial_fc(x).view(x.size(0), 1, 1, 1, self.kernel_size, self.kernel_size)spatial_attention = torch.sigmoid(spatial_attention / self.temperature)return spatial_attentiondef get_kernel_attention(self, x):# 计算核注意力kernel_attention = self.kernel_fc(x).view(x.size(0), -1, 1, 1, 1, 1)kernel_attention = F.softmax(kernel_attention / self.temperature, dim=1)return kernel_attentiondef forward(self, x):# 前向传播x = self.avgpool(x) # 平均池化x = self.fc(x) # 全连接层x = self.bn(x) # 批归一化x = self.relu(x) # ReLU激活return self.func_channel(x), self.func_filter(x), self.func_spatial(x), self.func_kernel(x) # 返回四种注意力
class AdaptiveDilatedConv(nn.Module):
“”“自适应膨胀卷积类,封装了可调节的变形卷积层”“”
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True):super(AdaptiveDilatedConv, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)self.omni_attention = OmniAttention(in_planes=in_channels, out_planes=out_channels, kernel_size=kernel_size)def forward(self, x):# 前向传播attention_weights = self.omni_attention(x) # 计算注意力权重x = self.conv(x) # 卷积操作return x * attention_weights # 加权输出
这里可以添加更多的类和方法
代码说明:
OmniAttention 类:实现了一个多通道注意力机制,包括通道、过滤器、空间和核注意力的计算。
AdaptiveDilatedConv 类:封装了自适应膨胀卷积,结合了注意力机制,能够根据输入动态调整卷积的输出。
注意事项:
该代码依赖于 PyTorch 库,确保在使用前已安装该库。
具体的使用场景和数据预处理未包含在此代码中,需根据实际需求进行调整。
这个程序文件 fadc.py 实现了一些用于深度学习的自适应膨胀卷积(Adaptive Dilated Convolution)和频率选择模块,主要依赖于 PyTorch 框架。文件中包含多个类和函数,下面对其进行逐一说明。
首先,文件引入了必要的库,包括 torch 和 torch.nn,以及一些功能性模块,如 torch.fft 和 numpy。接着,尝试从 mmcv 库中导入 ModulatedDeformConv2d 和 modulated_deform_conv2d,如果导入失败,则将 ModulatedDeformConv2d 设置为普通的 nn.Module。
接下来,定义了 OmniAttention 类,该类实现了一种全局注意力机制。构造函数中初始化了多个卷积层和激活函数,计算通道、过滤器、空间和内核的注意力。通过 _initialize_weights 方法初始化权重,使用 Kaiming 正态分布初始化卷积层的权重,并将偏置初始化为零。forward 方法则计算输入的注意力特征。
然后,定义了 generate_laplacian_pyramid 函数,用于生成拉普拉斯金字塔。该函数通过逐层下采样输入张量,计算每一层的拉普拉斯差分,并将结果存储在金字塔列表中。可以选择对每一层进行大小对齐。
接下来是 FrequencySelection 类,它实现了频率选择机制。构造函数中初始化了多个卷积层和池化层,根据不同的配置生成频率选择的特征。forward 方法则根据不同的频率选择策略对输入进行处理。
随后,定义了 AdaptiveDilatedConv 类,它是对 ModulatedDeformConv2d 的封装,增加了自适应的特性。构造函数中根据输入参数初始化了偏移卷积和掩码卷积,并可以选择是否使用频率选择模块。forward 方法中计算偏移和掩码,并通过 modulated_deform_conv2d 函数执行卷积操作。
最后,定义了 AdaptiveDilatedDWConv 类,类似于 AdaptiveDilatedConv,但主要用于深度可分离卷积。构造函数中同样初始化了偏移和掩码卷积,并实现了 forward 方法。
整体来看,这个文件实现了复杂的卷积操作和注意力机制,适用于需要自适应卷积和频率选择的深度学习任务,尤其是在图像处理和计算机视觉领域。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式