Spark Shuffle中的数据结构
文章目录
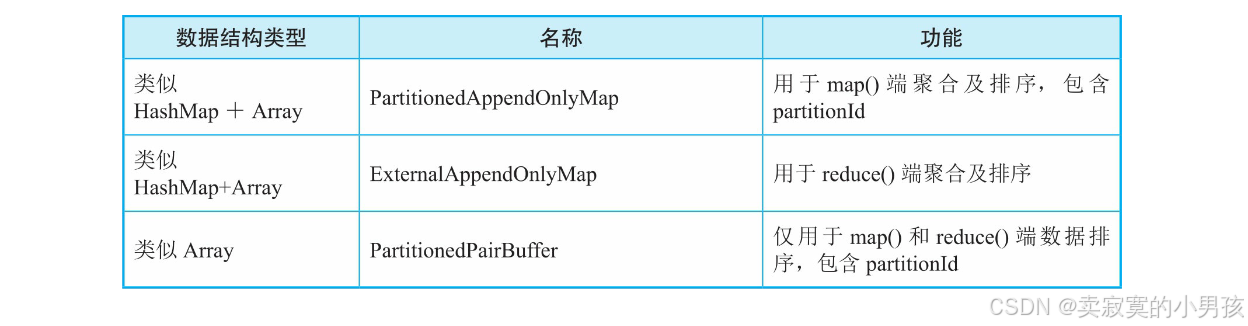
- 1.Shuffle中的三种数据结构
- 2.AppendOnlyMap原理
- 2.1 聚合
- 2.2 扩容
- 2.3 排序
- 2.4 为什么是数组?
- 3.ExternalAppendOnlyMap原理
- 3.1 工作原理
- 3.2 AppendOnlyMap大小估计
- 3.2.1 为什么要估计大小?
- 3.2.2 估计大小浅析
- 3.2.2.1 什么时候采样?
- 3.2.2.2 大小估算
- 3.2.2.3 采样后
- 3.3 Spill过程与排序
- 3.4 全局聚合merge-sort Shuffle
- 4.PartitionedAppendOnlyMap原理
- 5.PartitionedPairBuffer原理
1.Shuffle中的三种数据结构
在Spark Shuffle机制原理中,介绍了三种Shuffle的数据结构。
Spark中的PartitionedAppendOnlyMap和ExternalAppendOnlyMap都基于AppendOnlyMap实现。因此,我们先介绍AppendOnlyMap的原理。
2.AppendOnlyMap原理
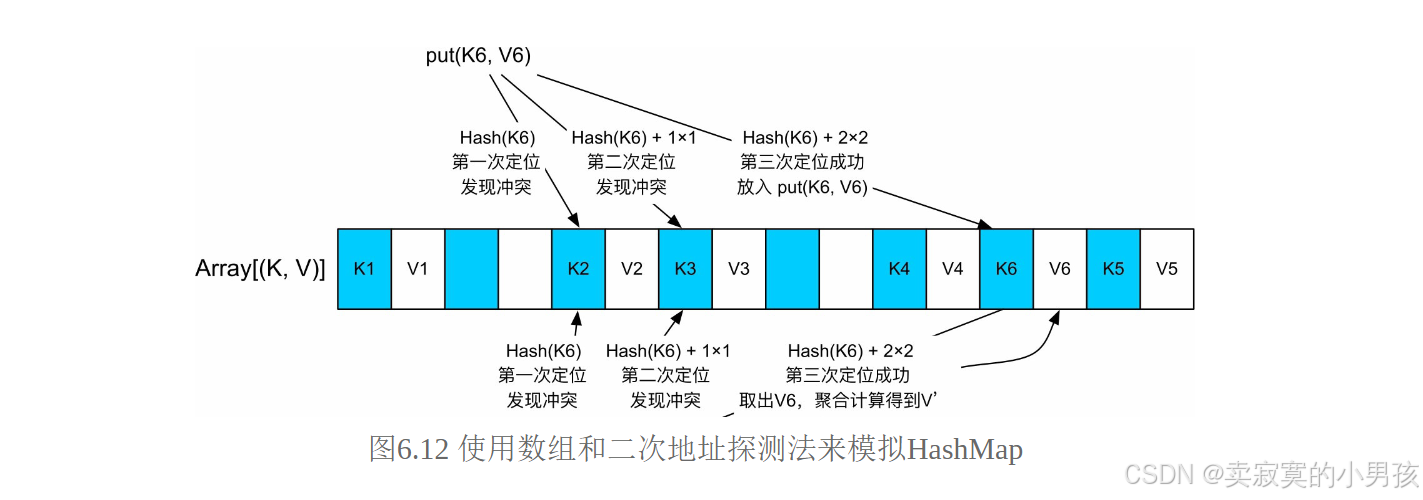
AppendOnlyMap实际上是一个只支持record添加和对Value进行更新的HashMap。AppendOnlyMap只使用数组来存储元素,根据元素的 Hash值确定存储位置,如果存储元素时发生Hash值冲突,则使用二次地址探测法来解决Hash值冲突。
对于每个新来的<K,V>record,先使用Hash(K)计算其存放位置,如果存放位置为空,就把record存放到该位置。如果该位置已经被占用,就使用二次探测法来找下一个空闲位置。
2.1 聚合
- 首先要明确的是,我们是对相同的key做聚合,而不是对相同的key的哈希值做聚合,不同的key哈希值有可能相等。
- 当两个key的哈希值相同时,后来的key会将Hash(Key)+n*n来找到该key应该在的位置。
- 当相同的key到来时,直接在列表中相同key的位置进行聚合。
2.2 扩容
如果插入的record太多,则很快会被填满。Spark的解决方案是,如果AppendOnlyMap的利用率达到70%,那么就扩张一倍,扩张意味着原来的Hash()失效,因此对所有Key进行rehash,重新排列每个Key的位置。
2.3 排序
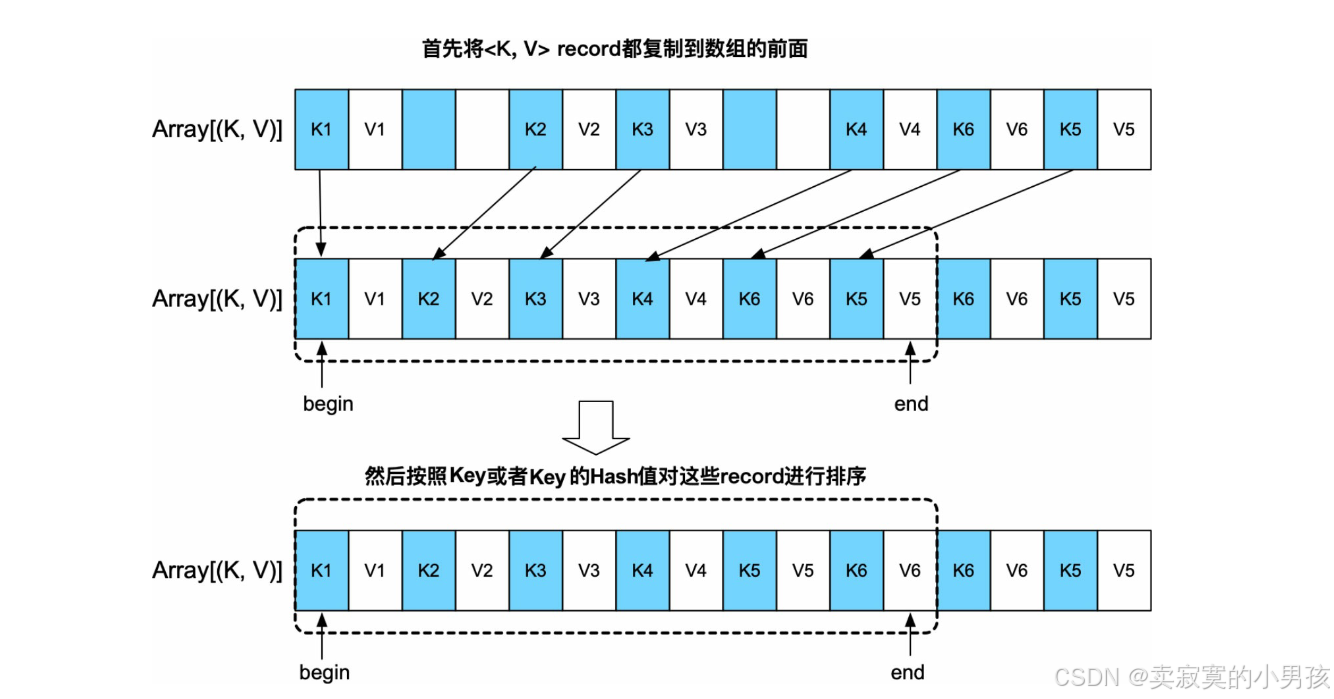
由于AppendOnlyMap采用了数组作为底层存储结构,可以支持快速排序等排序算法。先将数组中所有的<K,V>record转移到数组的前端,用begin和end来标示起始位置,然后调用排序算法对[begin,end]中的record进行排序。对于需要按Key进行排序的操作,如sortByKey(),可以按照Key值进行排序;对于其他操作,只按照Key的Hash值进行排序即可。
2.4 为什么是数组?
- 减少内存开销:传统哈希表(如 Java HashMap)为解决哈希冲突,采用 “数组 + 链表 / 红黑树” 结构,每个节点需要额外存储指针(如链表节点的next引用),这会增加内存占用。而AppendOnlyMap仅使用单个数组存储键值对,通过二次探测法解决冲突,避免了指针开销,更适合存储海量数据。
- 便于直接排序:AppendOnlyMap的底层数组可以直接作为排序的数据源。
3.ExternalAppendOnlyMap原理
3.1 工作原理
Spark基于AppendOnlyMap设计实现了基于内存+磁盘的ExternalAppendOnlyMap,用于Shuffle Read端大规模数据聚合。
ExternalAppendOnlyMap的工作原理是:
- 先持有一个AppendOnlyMap来不断接收和聚合新来的record,AppendOnlyMap快被装满时检查一下内存剩余空间是否可以扩展,可直接在内存中扩展,不可扩展则对AppendOnlyMap中的record进行排序,然后将record都spill到磁盘上。
- 因为record不断到来,可能会多次填满AppendOnlyMap,所以这个spill过程可以出现多次,最终形成多个spill文件。
- 等record都处理完,此时AppendOnlyMap中可能还留存一些聚合后的record,磁盘上也有多个spill文件。因为这些数据都经过了部分聚合,还需要进行全局聚合(merge)。
3.2 AppendOnlyMap大小估计
3.2.1 为什么要估计大小?
一种简单的解决方法是在每次插入record或对现有record的Value进行更新后,都扫描一下AppendOnlyMap中存放的record,计算每个record的实际对象大小并相加,但这样会非常耗时。而且一般AppendOnlyMap会插入几万甚至几百万个record,如果每个record进入AppendOnlyMap都计算一遍,则开销会很大。
Spark设计
了一个增量式的高效估算算法,在每个record插入或更新时根据历史统计值和当前变化量直接估算当前AppendOnlyMap的大小,算法的复杂度是 O (1),开销很小。在record插入和聚合过程中会定期对当前AppendOnlyMap中的record进行抽样,然后精确计算这些record的总大小、总个数、更新个数及平均值等,并作为历史统计值。进行抽样是因为AppendOnlyMap中的record可能有上万个,难以对每个都精确计算。之后,每当有record插入或更新时,会根据历史统计值和历史平均的变化值,增量估算AppendOnlyMap的总大小,详见Spark源码中的SizeTracker.estimateSize()方法。抽样也会定期进行,更新统计值以获得更高的精度。这个后面有时间研究一下。
3.2.2 估计大小浅析
经过翻阅spark源码,发现估计不同类型对象的方式有所不同,这里只分析数组方式。
对于普通数组来说,元素类型是int,float等,可以直接获取准确大小,不需要进行估计了。但是AppendOnlyMap中通常是java复杂对象。
3.2.2.1 什么时候采样?
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/util/collection/SizeTracker.scala#L67
https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/util/SizeEstimator.scala
- 初始化时采样:初始化时调用 resetSamples(),将首次采样时机 nextSampleNum 设为 1(即第 1 次更新后采样)。nextSampleNum表示的就是下一次采样的时机。
- 初始化后采样:
nextSampleNum = math.ceil(numUpdates * SAMPLE_GROWTH_RATE).toLong,其中SAMPLE_GROWTH_RATE的值为1.1,经查阅,应该是一个经验值,numUpdates表示的是当前数组的更新次数,如果当前是100,那么下一次采样的时机为100+100+1.1=110次时。
3.2.2.2 大小估算
数组元素的大小由两部分构成,一个是数组对象本身的固定开销(对象头),这里的数组对象本身是由数组封装的,通常大小比较固定;一个是数组元素本身内存的开销,数组元素可能是java对象或者对象指针。
- 一个数组元素的精确总大小 = 数组元素头+指针大小+指针指向的对象大小
- 抽样时机与抽样个数:
private val ARRAY_SIZE_FOR_SAMPLING = 400,这里的400的数字在源码中是写死的,也就是说当数组长度超过400的时候,才会去进行抽样,private val ARRAY_SAMPLE_SIZE = 100抽样的方式也很简单,进行两次抽样,每次抽取100个元素。 - 抽样的大小:先取两次抽样的最小值为
val size = math.min(s1, s2)(减小共享对象对抽样的影响)。整体元素的大小为max(s1, s2) + size × ((总长度 - 100) / 100)。
3.2.2.3 采样后
- 采样后,将采样结果封装成对象,放进一个队列中。并且该队列仅保留最近的两次采样。根据这两次最近的采样估算每次更新的平均字节数。
- 每次更新平均字节数:
val bytesDelta = 最近两次采样的大小差 / 最近两次采样的更新次数差,注意这两次指的不是上面大小计算的两次,而是两次大小估算整个流程输出的结果。 - 本次采样估算:根据平均字节增长量,估算本次采样后的增量,
当前估算大小 = 上次采样大小 + 增量。
时间复杂度:估算过程仅依赖内存中的采样数据和累计更新次数,因此是 O(1) 时间复杂度,高效且适合高频调用。
3.3 Spill过程与排序
- 当AppendOnlyMap达到内存限制时,会将record排序后写入磁盘中。排序是为了方便下一步全局聚合(聚合内存和磁盘上的record)时可以采用更高效的merge-sort(外部排序+聚合)。注意,这里为了后面的高效聚合,因此进行了排序。
- sortByKey()等操作定义了按照Key进行的排序。
- 如groupByKey(),并没有定义Key的排序方法,也不需要输出结果是按照Key进行排序的。在这种情况下,Spark采用按照Key的Hash值进行排序的方法,这样既可以进行merge-sort,又不要求操作定义Key排序的方法。这种方法的问题是会出现Hash值冲突,也就是不同Key具有相同的Hash值。为了解决这个问题,Spark在merge-sort的同时会比较Key的Hash值是否相等,以及Key的实际值是否相等。
3.4 全局聚合merge-sort Shuffle
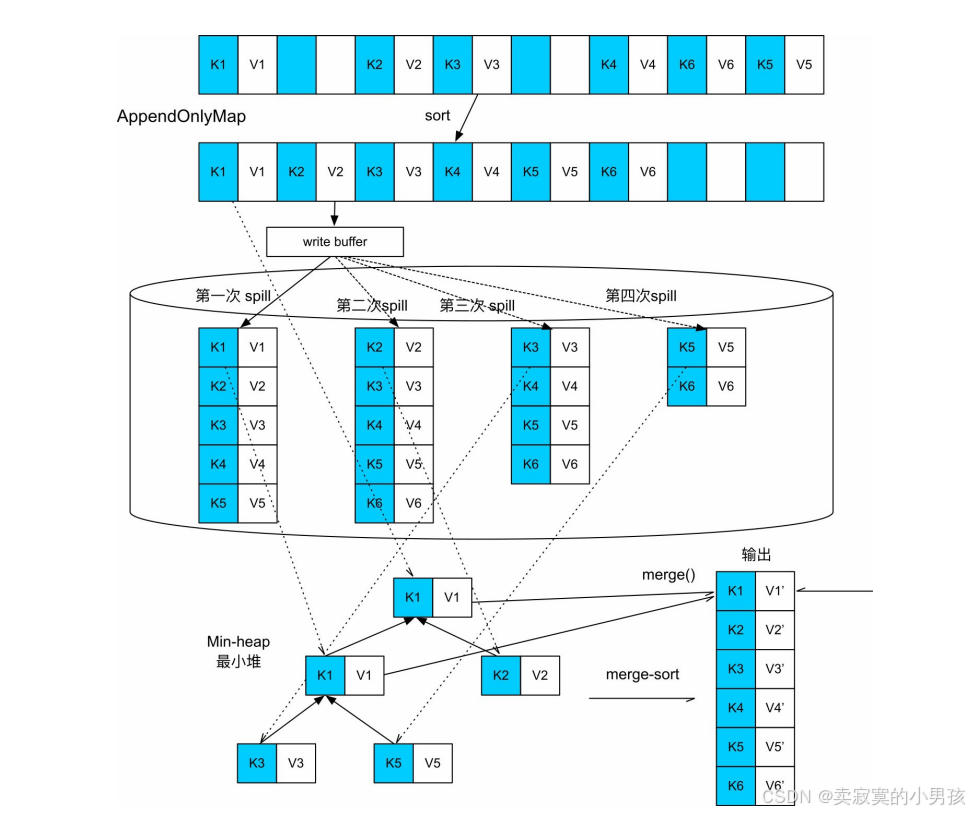
- 当所有数据输入完成后,会对当前内存中的AppendOnlyMap进行排序,并且所有的spill文件都是排序好的,现在需要进行全局聚合。
- 聚合使用的是一个最小堆的结构,将AppendOnlyMap中的第一个元素,和所有spill在磁盘上的文件都读取第一个元素维护一个最小堆。每次取堆顶元素进行聚合,直到堆顶元素不相同为止,再取堆顶元素进行下一轮聚合。
4.PartitionedAppendOnlyMap原理
PartitionedAppendOnlyMap用于在Shuffle Write端对record进行聚合(combine)。PartitionedAppendOnlyMap的功能和实现与ExternalAppendOnlyMap的功能和实现基本一样,唯一区别是PartitionedAppendOnlyMap中的Key是“PartitionId+Key”,这样既可以根据partitionId进行排序(面向不需要按Key进行排序的操作),也可以根据partitionId+Key进行排序(面向需要按Key进行排序的操作),从而在Shuffle Write阶段可以进行聚合、排序和分区。
5.PartitionedPairBuffer原理
PartitionedPairBuffer本质上是一个基于内存+磁盘的Array,随着数据添加,不断地扩容,当到达内存限制时,就将Array中的数据按照partitionId或partitionId+Key进行排序,然后spill到磁盘上,该过程可以进行多次,最后对内存中和磁盘上的数据进行全局排序,输出或者提供给下一个操作。