机器学习案例——《红楼梦》文本分析与关键词提取
红楼梦》作为中国古典文学巅峰之作,其丰富的内涵和复杂的结构一直是文学研究和文本分析的重要对象。本文将详细介绍如何运用Python技术对《红楼梦》进行系统化的文本分析,包括分卷处理、分词技术、停用词过滤以及TF-IDF关键词提取等关键步骤。
一、文本预处理:分卷处理
1.1 分卷逻辑实现
import os# 初始化计数器
b = 0# 打开红楼梦全文文件
with open('红楼梦.txt', 'r', encoding='utf-8') as file:for line in file:# 检查是否为分卷标题行if '卷 第' in line:# 创建分卷文件名name = line.strip() + '.txt'# 构建分卷文件路径path = os.path.join('.\\红楼梦\\分卷', name)print("正在创建分卷文件:", path)# 创建新分卷文件afile = open(path, 'w', encoding='utf-8')b = 1 # 标记进入正文部分continue# 跳过非正文内容if '手机电子书' in line or b == 0:continueelse:# 将正文内容写入分卷文件afile.write(line)分卷内容如下

1.2 分卷语料库构建
import os
import pandas as pd# 初始化存储路径和内容的列表
paths = []
contents = []for (dirpath, dirnames, filenames) in os.walk('.\红楼梦\分卷'):for filename in filenames:# 构建完整文件路径filepath = os.path.join(dirpath, filename)paths.append(filepath)# 读取文件内容with open(filepath, 'r', encoding='utf-8') as f:contents.append(f.read())# 创建语料库DataFrame
corpus = pd.DataFrame({'filepath': paths, # 文件路径列'content': contents # 文件内容列该部分代码:
- 使用os.walk遍历分卷目录
- 将每个分卷文件路径和内容存入DataFrame
- 构建结构化语料库,便于后续分析
二、中文分词处理
1. 自定义词典与分词
import jieba# 加载自定义词典
jieba.load_userdict(r'红楼梦词库.txt')# 读取停用词表
stop_dict = pd.read_csv('StopwordsCN.txt',encoding='utf-8',engine='python',index_col=False)# 创建分词结果文件
with open('红楼梦\分词汇总.txt','w',encoding='utf-8') as file_to_jieba:for index, row in corpus.iterrows():space = '' # 初始化分词结果字符串filepath = row['filepath'] # 获取文件路径content = row['content'] # 获取文件内容# 使用jieba进行分词seg_list = jieba.cut(content)# 过滤停用词和非空词for word in seg_list:if (word not in stop_dict.stopword.values and len(word.strip()) > 0):space += word + ' ' # 用空格分隔词语# 写入分词结果file_to_jieba.write(space + '\n')
- 自定义词典:加载"红楼梦词库.txt"提高专有名词识别准确率
- 停用词过滤:去除无实际意义的虚词和常见词
- 分词优化:确保每个有效词语用空格分隔
三、TF-IDF关键词提取
3.1 TF-IDF原理简介
F-IDF(词频-逆文档频率)通过两个维度的计算评估词语重要性:
TF(词频):词语在当前文档中出现的频率
- 计算公式:TF(t,d) = (t在d中出现的次数)/(d中所有词语的总数)
IDF(逆文档频率):衡量词语在整个语料库中的普遍重要性
- 计算公式:IDF(t) = log(总文档数/(包含t的文档数+1))
TF-IDF值:TF × IDF
- 值越高表示词语对当前文档越重要
实现代码解析
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd# 读取分词结果
with open('./红楼梦/分词汇总.txt', 'r', encoding='utf-8') as file:content = file.readlines()# 初始化TF-IDF向量器
vectorizer = TfidfVectorizer()# 计算TF-IDF矩阵
tfidf = vectorizer.fit_transform(content)# 获取特征词列表
vocabulary = vectorizer.get_feature_names()# 创建TF-IDF数据框
df = pd.DataFrame(data=tfidf.T.todense(), # 转置并转换为密集矩阵index=vocabulary) # 以词语作为行索引# 跳过前8行(可能是标点符号等)
df = df.iloc[8:]# 对每回进行TF-IDF排序并输出前10个关键词
for i in df.columns:# 按降序排序results = df.sort_values(by=i, ascending=False)# 输出当前回数和前10个关键词print(f'第{i+1}回:\n', results.iloc[:10,i])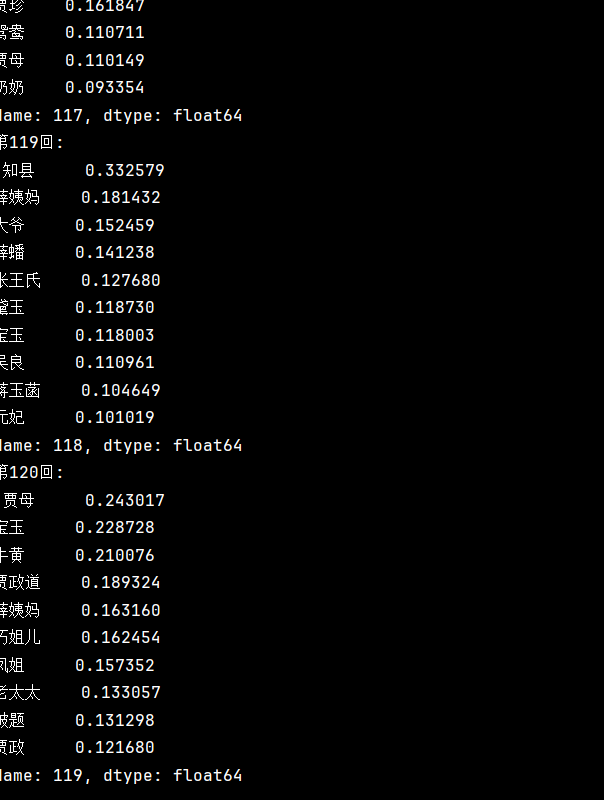
运行上述代码后,我们将得到每个分卷的TF-IDF权重最高的前10个关键词。这些关键词可以反映:
- 章节主题:高频关键词往往指向该章节的核心内容
人物关系:主要人物的出现频率变化
- 情节发展:关键事件和场景的分布
例如,某章节的关键词可能是"宝玉"、"黛玉"、"诗社"等,反映了该章节的主要内容。