Kafka分区
目录
- Kafka分区的好处
- 生产者发送消息的分区策略
- 默认的分区器 DefaultPartitioner
- 自定义分区器
Kafka分区的好处
- 便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上,合理控制分区的任务,可以实现负载均衡的效果
- 提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据
生产者发送消息的分区策略
默认的分区器 DefaultPartitioner
在IDEA中ctrl+n,全局查找DefaultPartitioner
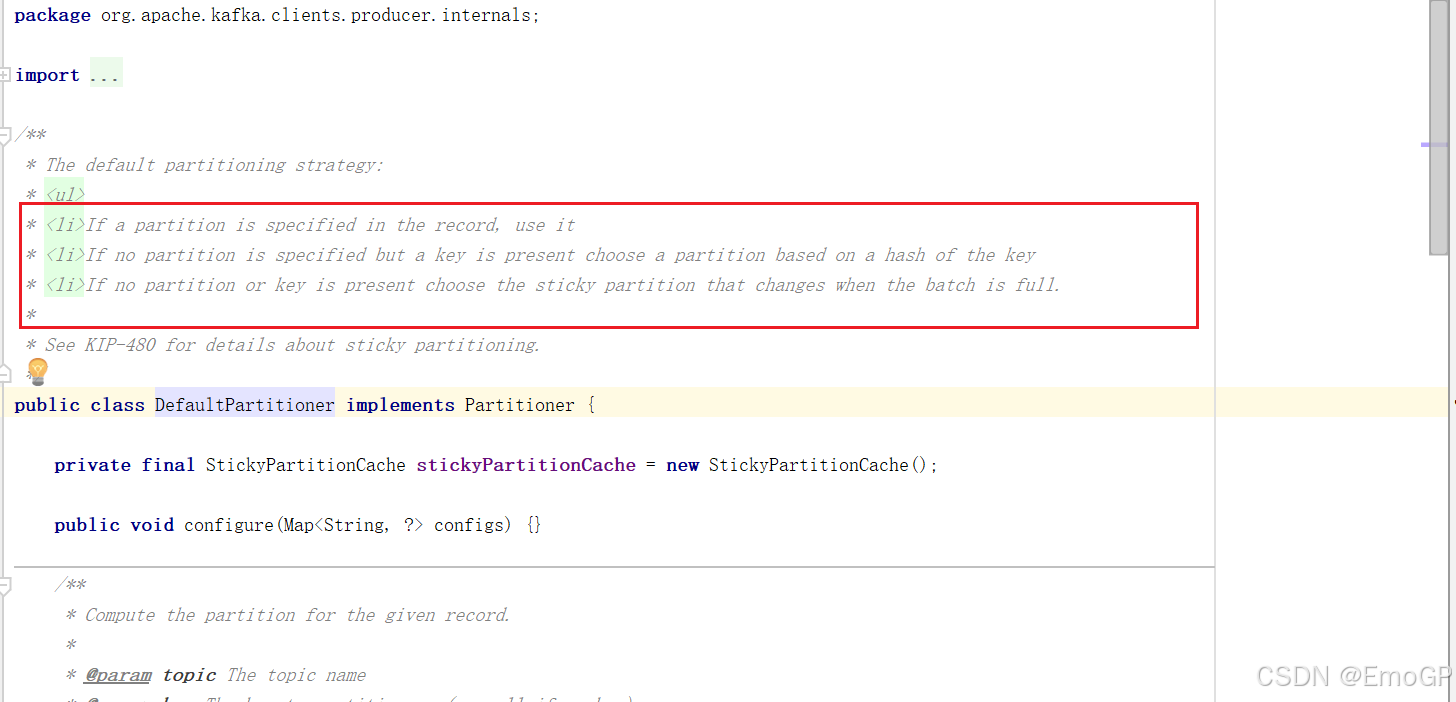
在IDEA中全局查找ctrl+n ProducerRecord类,在类中可以看到如下构造

-
指明
partition的情况下,直接将指明的值作为partition值;例如partiton=0,所有数据写入分区0 -
没有指明partition值但有key的情况下,将key的hash值与topic的partition数进行取余得到partition值;例如key1的hash值
= 5,key2的hash值 = 6,topic的partition数 = 2,那么key1对应的value1写入1号分区,key2对应的value2写入0号分区 -
既没有partition值又没有key值得情况下,Kafka采用
Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区得batch已满或者已完成,Kafka再随机一个分区进行使用(和上一次得分区不同)例如:第一次随机选择0号分区,等0号分区当前批次满了(默认16k)或者linger.ms设置得时间到,Kafka再随机一个分区进行使用(如果还是0会继续随机)
自定义分区器
需求:
例如我们实现一个分区器实现,发送过来的数据中如果包含了kafka,就发往0号分区,不包含就发往1号分区
实现步骤:
- 定义类实现Partitoner接口
- 重写方法(重点是partition())
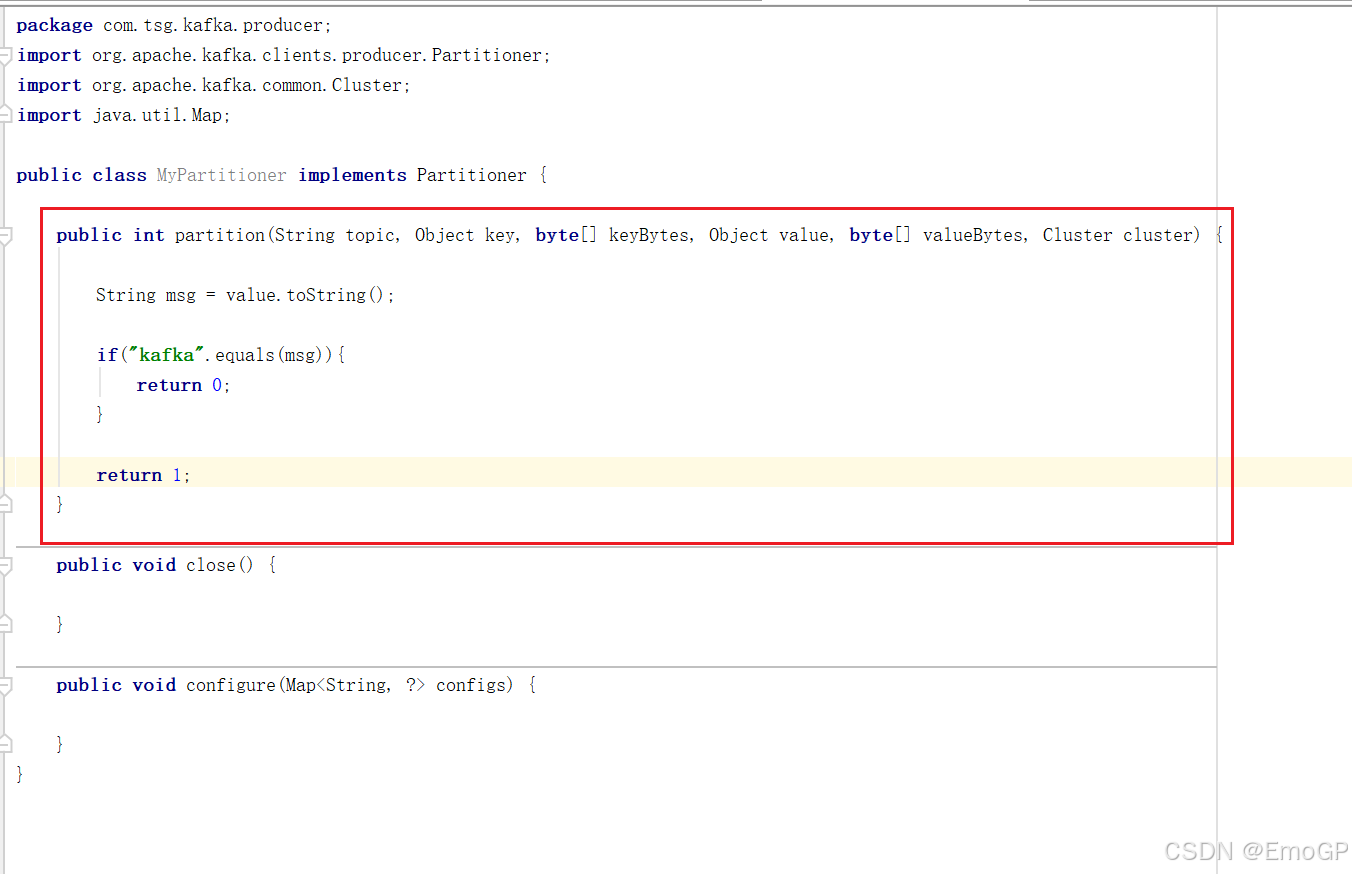
package com.tsg.kafka.producer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;public class MyPartitioner implements Partitioner {public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {String msg = value.toString();if("kafka".equals(msg)){return 0;}return 1;}public void close() {}public void configure(Map<String, ?> configs) {}
}
关联自定义分区器
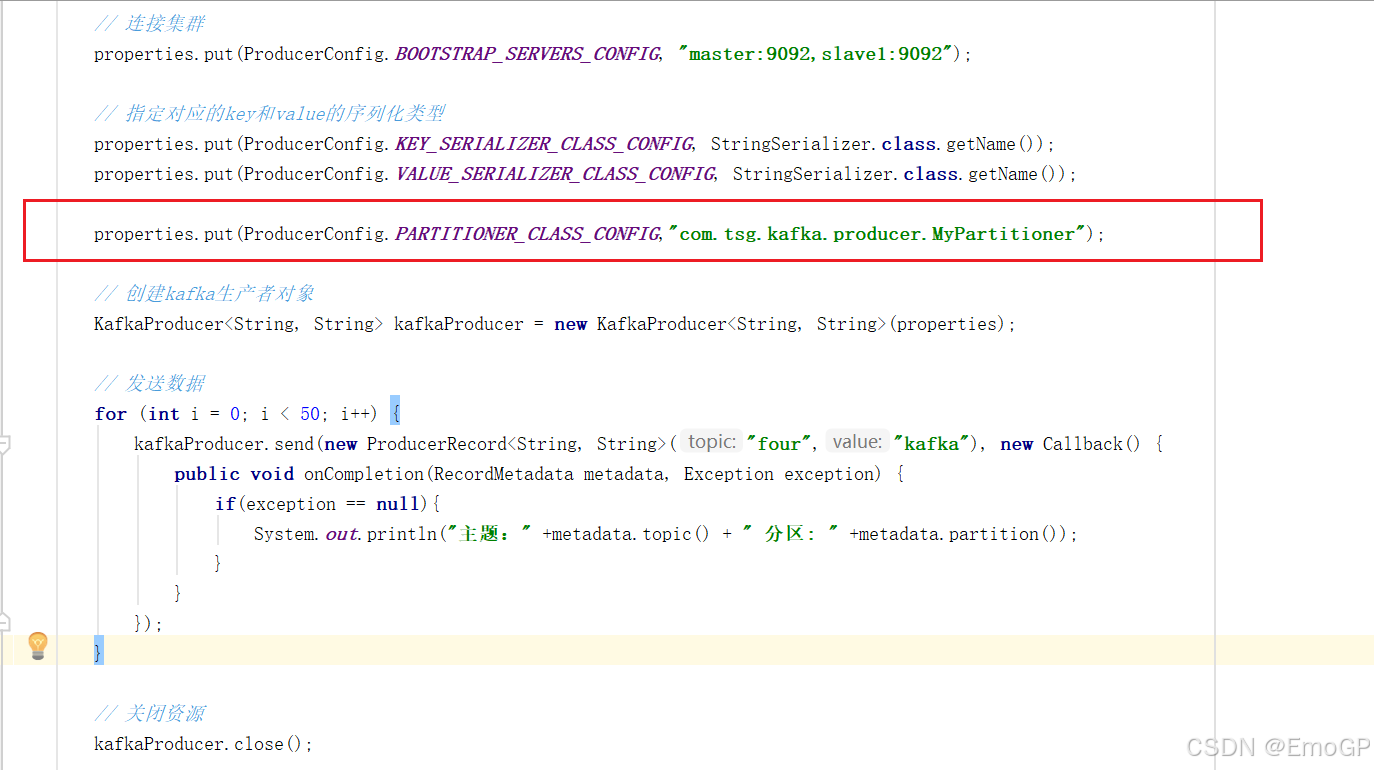
package com.tsg.kafka.producer;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;public class CustomProducerCallback {public static void main(String[] args) {Properties properties = new Properties();// 连接集群properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "master:9092,slave1:9092");// 指定对应的key和value的序列化类型properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.tsg.kafka.producer.MyPartitioner");// 创建kafka生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 发送数据for (int i = 0; i < 50; i++) {kafkaProducer.send(new ProducerRecord<String, String>("four","kafka"), new Callback() {public void onCompletion(RecordMetadata metadata, Exception exception) {if(exception == null){System.out.println("主题:" +metadata.topic() + " 分区: " +metadata.partition());}}});}// 关闭资源kafkaProducer.close();}
}
