解锁 Docker:一场从入门到源码的趣味解谜之旅
概况
- 一、基础知识
- 二、网络
- 四、隔离技术
- (1)NameSpace
- 源码角度看NameSpace
- (2)Cgroup
- 源码角度看Cgroup精华版
一、基础知识
docker的航海图如下:
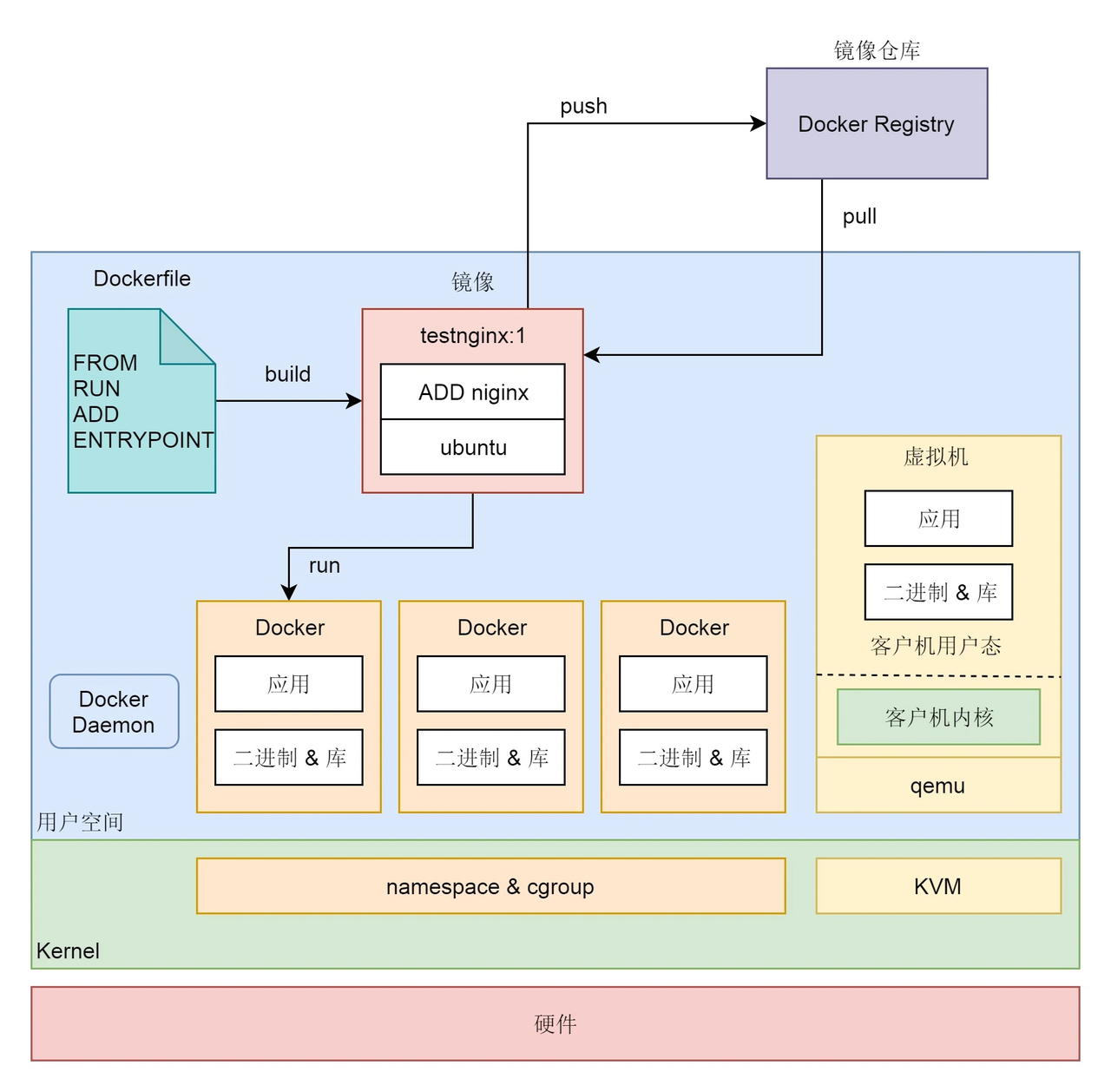
镜像是磁盘中的文件,基于镜像创建出容器,运行的容器就是内存中的进程
制作者为了尽量减小镜像的体积,会只将必要的程序打包进镜像。
docker exec -it /A /bin/bash
vim xx.txt //报错,因为A这个容器里面只安装了必要的程序!并没有安装vim文本编辑器工具
-i参数表示interactive,即交互模式。
-t参数表示分配一个伪终端。详细解读:
docker exec -td 容器名/ID /bin/bash
如果只使用-d选项,不使用-t选项,会无法正常运行容器。
这些操作系统类的基础镜像默认运行的程序通常都是shell,比如bash,
也就是说,bash是容器中的主进程,pid是1,如果不使用-t选项为bash分配伪终端,
单独执行bash命令后,bash进程就直接结束了
(没有绑定任何终端,相当于执行bash命令后一闪而过,没有任何输入输出,直接结束进程)
所以,我们需要让bash持续运行,从而实现持续运行容器的目的,
使用-t选项就是为了给bash分配伪终端,让其可以通过终端占用前台,
从而达到持续运行pid1进程的目的。
容器也是优缺点的:
- 共用内核
容器和宿主机共享同一个 Linux 内核,如果内核存在漏洞,可能会被容器逃逸利用,影响宿主机安全。
参考文章: 容器安全管理 - 隔离程度低于虚拟机
容器主要依靠 Namespace + Cgroups 做隔离,不像虚拟机有独立内核和硬件虚拟化层,防护层次较少。
二、网络
[root@cos7-1 ~]# docker start test2
test2
[root@cos7-1 ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024274071ed7 no veth025eb04veth9aa1954
# docker0 不就是一个虚拟交换机?
当容器连接到默认的网络时,不支持对容器指定固定的IP地址,
只有连接到自定义网络时,才能对容器指定固定的IP地址。[root@cos7-1 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
ffe9bc57a881 bridge bridge local
7d79c20080e2 host host local
1b62645fd07d none null local
第一个网络名为bridge,使用bridge类型的驱动,这个网络就是我们一直在用的默认网络,此网络使用docker0作为虚拟交换机。
第二个网络名为host,使用host类型的驱动,当容器接入此网络时,会共享宿主机的网络空间。
第三个网络名为none,没有使用任何类型的网络驱动,当容器使用none网络时,表示禁用网络。
新创建的网络的网段是172.18.0.0/16,默认网络的网段是172.17.0.0/16
docker run -itd --name test4 --network test_net --ip 172.18.0.66 alpine
#采用默认网桥时会报错
[root@cos7-1 ~]# docker run -itd --name test5 --network bridge --ip 172.17.0.88 alpine
99319026874a0a439bd39137fd339e0fd60f25cf16acf48dac2174e70e301715
docker: Error response from daemon: user specified IP address is supported on user defined networks only.
还需要注意,docker会生成对应的iptables规则,阻断了默认网络和自定义桥网络之间的通讯。
Chain DOCKER-ISOLATION-STAGE-2 (2 references)pkts bytes target prot opt in out source destination 0 0 DROP all -- * docker0 0.0.0.0/0 0.0.0.0/0 0 0 DROP all -- * test_bridge 0.0.0.0/0 0.0.0.0/0 0 0 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
四、隔离技术
(1)NameSpace
假设,现在有两个容器,一个nginx容器,一个redis容器,在nginx容器中,nginx的master进程的pid为1,在redis容器中,redis-server进程的pid为1,对于nginx-master进程或者redis-server进程来说,它们都以为自己是这个世界上的王者,因为它们只能看到自己的世界,而且在自己看到的世界中,自己是主进程(PID为1),其实,它们都只不过是host主机中的一个普通进程罢了,nginx容器的master进程在host主机中的PID可能是1234,redis容器中的server进程在host主机中的PID可能是5678,即使在各自的容器中,它们的PID都是1,也许这就是pid namespace进程隔离最直观的感受吧。
UTS,对应的宏为 CLONE_NEWUTS,表示不同的 namespace 可以配置不同的 hostname。
User,对应的宏为 CLONE_NEWUSER,表示不同的 namespace 可以配置不同的用户和组。
Mount,对应的宏为 CLONE_NEWNS,表示不同的 namespace 的文件系统挂载点是隔离的
PID,对应的宏为 CLONE_NEWPID,表示不同的 namespace 有完全独立的 pid,也即一个 namespace 的进程和另一个 namespace 的进程,pid 可以是一样的,但是代表不同的进程。
Network,对应的宏为 CLONE_NEWNET,表示不同的 namespace 有独立的网络协议栈。
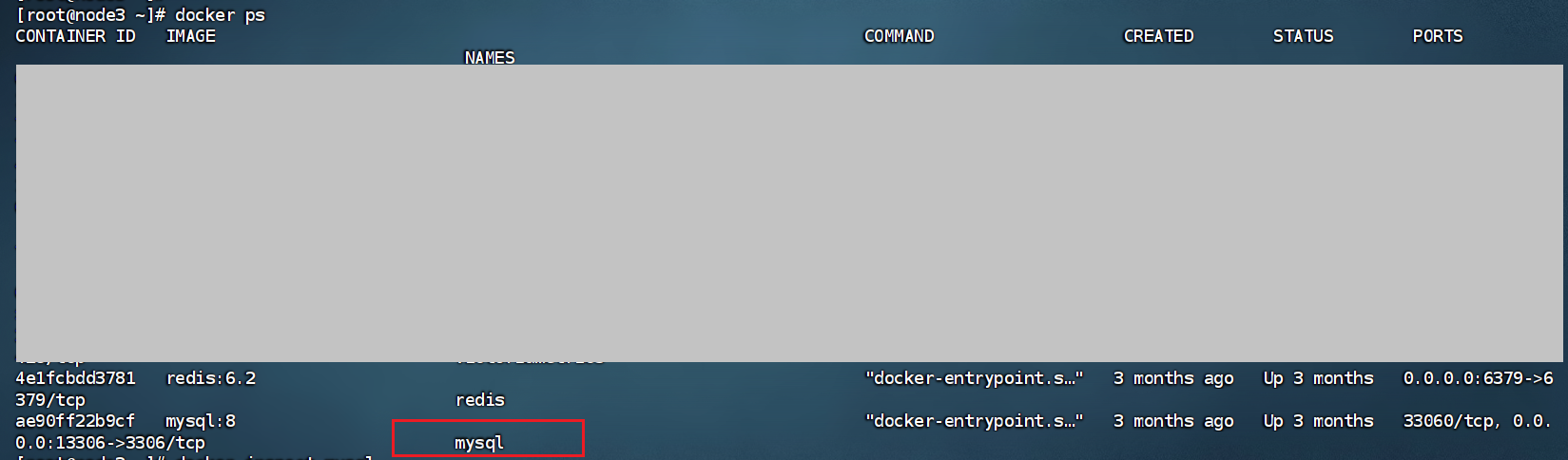
我们接着看mysql里面的内部细节:
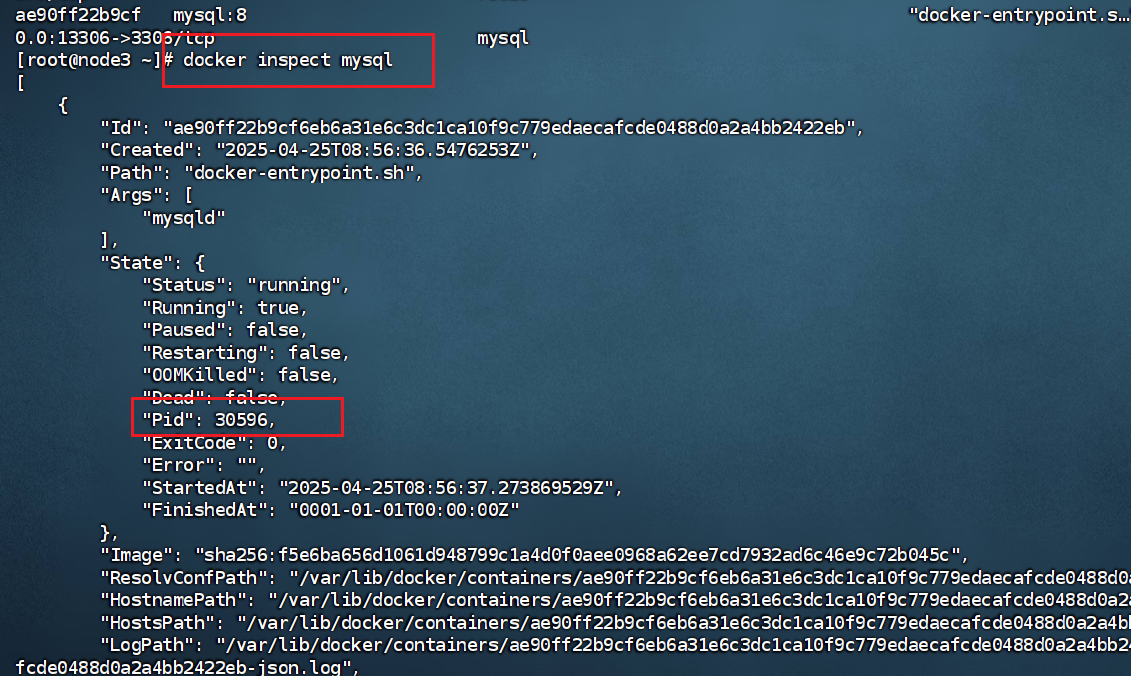
接着查看30596所属的命名空间(Namespace) 信息。
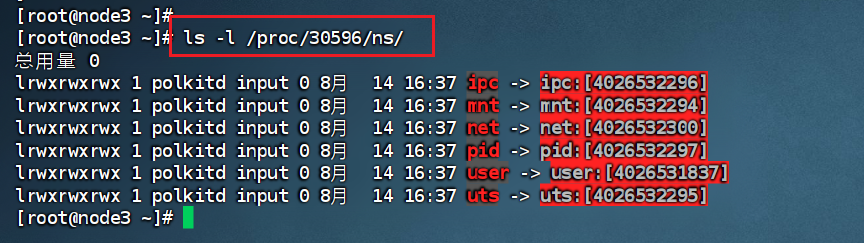
如图,其中 ipc:[4026532296]的4026532296是一个命名空间的唯一标识符(inode 编号),用于区分不同的命名空间实例。通过比较不同进程的命名空间 inode 编号,可以判断它们是否处于同一隔离环境:
若两个进程的某类命名空间的 inode 编号相同,说明它们共享该命名空间(例如同一容器内的进程,或宿主机上未隔离的进程)。
若编号不同,则它们处于独立的命名空间(例如不同容器的进程,彼此隔离)。
【场景操作namespace的命令】
1)nsenter,可以用来运行一个进程,进入指定的 namespace。
# nsenter --target 58212 --mount --uts --ipc --net --pid -- env --ignore-environment -- /bin/bashroot@f604f0e34bc2:/# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft forever
23: eth0@if24: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ffinet 172.17.0.3/16 brd 172.17.255.255 scope global eth0valid_lft forever preferred_lft forever命令解释:
1. nsenter
这是核心命令,全称为 namespace enter,用于进入另一个进程的命名空间,从而获得与目标进程相同的资源隔离环境(如网络、文件系统、PID 等)。
2. --target 58212
指定目标进程的 PID(这里是 58212),表示要进入该进程所在的命名空间。
该进程通常是容器的初始化进程(如 Docker 容器的 sh 或 bash 进程),通过它可以获取容器的完整隔离环境。
3. 命名空间参数(--mount --uts --ipc --net --pid)
这些参数指定要进入的命名空间类型,对应 Linux 内核的 5 种核心隔离资源:
--mount:进入目标进程的挂载命名空间(隔离文件系统挂载点,如容器内的独立目录结构)。
--uts:进入UTS 命名空间(隔离主机名和域名,如容器的独立主机名)。
--ipc:进入IPC 命名空间(隔离进程间通信,如消息队列、共享内存)。
--net:进入网络命名空间(隔离网络设备、IP、端口等,如容器的独立网络栈)。
--pid:进入PID 命名空间(隔离进程 ID,如容器内的进程 ID 与宿主机独立)。
2)unshare,离开当前的 namespace,创建且加入新的 namespace,然后执行参数中指定的命令。
unshare --mount --ipc --pid --net --mount-proc=/proc --fork /bin/bash
用于创建一个新的、与当前进程隔离的命名空间环境,并在其中启动一个 bash 终端。
它是 Linux 中手动创建隔离环境(类似容器的基础环境)的底层工具,
比 nsenter 更侧重于新建隔离环境而非进入已有环境。
3) 函数操作 namespace
第一个函数是 clone,也就是创建一个新的进程,并把它放到新的 namespace 中。
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);这里面有一个参数 flags,原来我们没有注意它。
其实它可以设置为 CLONE_NEWUTS、CLONE_NEWUSER、CLONE_NEWNS、
CLONE_NEWPID。CLONE_NEWNET 会将 clone 出来的新进程放到新的 namespace 中。
第二个函数是 setns,用于将当前进程加入到已有的 namespace 中。
int setns(int fd, int nstype);fd 指向 /proc/[pid]/ns/ 目录里相应 namespace 对应的文件,
表示要加入哪个 namespace。nstype 用来指定 namespace 的类型,
可以设置为 CLONE_NEWUTS、CLONE_NEWUSER、CLONE_NEWNS、
CLONE_NEWPID 和 CLONE_NEWNET。
第三个函数是 unshare,它可以使当前进程退出当前的 namespace,并加入到新创建的 namespace。
int unshare(int flags);
flags 用于指定一个或者多个上面的 CLONE_NEWUTS、CLONE_NEWUSER、
CLONE_NEWNS、CLONE_NEWPID 和 CLONE_NEWNET。
clone 和 unshare 的区别是,unshare 是使当前进程加入新的 namespace;clone 是创建一个新的子进程,然后让子进程加入新的 namespace,而当前进程保持不变。
源码角度看NameSpace
调用链如下:
clone 会调用 _do_fork->copy_process->copy_namespaces
首先看一下 namespace的结构体
struct task_struct {
....../* Namespaces: */struct nsproxy *nsproxy;
......
}/** A structure to contain pointers to all per-process* namespaces - fs (mount), uts, network, sysvipc, etc.** The pid namespace is an exception -- it's accessed using* task_active_pid_ns. The pid namespace here is the* namespace that children will use.*/
struct nsproxy {atomic_t count;struct uts_namespace *uts_ns;struct ipc_namespace *ipc_ns;struct mnt_namespace *mnt_ns;struct pid_namespace *pid_ns_for_children;struct net *net_ns;struct cgroup_namespace *cgroup_ns;
};
接着在具体到函数里面去,首先是-copy_namespaces函数,
// 如果 clone 的参数里面没有 CLONE_NEWNS | CLONE_NEWUTS |
CLONE_NEWIPC | CLONE_NEWPID | CLONE_NEWNET | CLONE_NEWCGROUP,
就返回原来的 namespace,调用 get_nsproxy。否则就会调用create_new_namespaces创建新的ns。int copy_namespaces(unsigned long flags, struct task_struct *tsk)
{struct nsproxy *old_ns = tsk->nsproxy;struct user_namespace *user_ns = task_cred_xxx(tsk, user_ns);struct nsproxy *new_ns;if (likely(!(flags & (CLONE_NEWNS | CLONE_NEWUTS | CLONE_NEWIPC |CLONE_NEWPID | CLONE_NEWNET |CLONE_NEWCGROUP)))) {get_nsproxy(old_ns);return 0;}if (!ns_capable(user_ns, CAP_SYS_ADMIN))return -EPERM;
......new_ns = create_new_namespaces(flags, tsk, user_ns, tsk->fs);tsk->nsproxy = new_ns;return 0;
}
我们接着看create_new_namespaces这个函数的具体实现:
static struct nsproxy *create_new_namespaces(unsigned long flags,struct task_struct *tsk, struct user_namespace *user_ns,struct fs_struct *new_fs)
{struct nsproxy *new_nsp;new_nsp = create_nsproxy();
......new_nsp->mnt_ns = copy_mnt_ns(flags, tsk->nsproxy->mnt_ns, user_ns, new_fs);
......new_nsp->uts_ns = copy_utsname(flags, user_ns, tsk->nsproxy->uts_ns);
......new_nsp->ipc_ns = copy_ipcs(flags, user_ns, tsk->nsproxy->ipc_ns);
......new_nsp->pid_ns_for_children =copy_pid_ns(flags, user_ns, tsk->nsproxy->pid_ns_for_children);
......new_nsp->cgroup_ns = copy_cgroup_ns(flags, user_ns,tsk->nsproxy->cgroup_ns);
......new_nsp->net_ns = copy_net_ns(flags, user_ns, tsk->nsproxy->net_ns);
......return new_nsp;
......
}struct net *copy_net_ns(unsigned long flags,struct user_namespace *user_ns, struct net *old_net)
{struct ucounts *ucounts;struct net *net;int rv;if (!(flags & CLONE_NEWNET))return get_net(old_net);ucounts = inc_net_namespaces(user_ns);
......net = net_alloc();
......get_user_ns(user_ns);net->ucounts = ucounts;rv = setup_net(net, user_ns);
......return net;
}
===============================================================
注意:
如果 flags 中不包含 CLONE_NEWNET,也就是不会创建一个新的 network namespace,则返回 old_net;
否则需要新建一个 network namespace。然后,copy_net_ns 会调用 net = net_alloc(),
分配一个新的 struct net 结构,然后调用 setup_net 对新分配的 net 结构进行初始化,
之后调用 list_add_tail_rcu,将新建的 network namespace,
添加到全局的 network namespace 列表 net_namespace_list 中。
===============================================================
/** setup_net runs the initializers for the network namespace object.*/
static __net_init int setup_net(struct net *net, struct user_namespace *user_ns)
{/* Must be called with net_mutex held */const struct pernet_operations *ops, *saved_ops;LIST_HEAD(net_exit_list);atomic_set(&net->count, 1);refcount_set(&net->passive, 1);net->dev_base_seq = 1;net->user_ns = user_ns;idr_init(&net->netns_ids);spin_lock_init(&net->nsid_lock);list_for_each_entry(ops, &pernet_list, list) {error = ops_init(ops, net);
===============================================================
很多网络子系统的数据是按 netns 隔离的(路由表、邻居表、计数器、sysctl、/proc 视图、设备列表等)。
新建 netns 时,必须让所有相关子系统都知道新 ns 的存在,并为之分配并注册自己的那一份数据结构;
这个循环就是把这些工作一次性、按顺序完成。
===============================================================
......}
......
}
这里面有一个循环 list_for_each_entry,对于 pernet_list 的每一项 struct pernet_operations,
运行 ops_init,也就是调用 pernet_operations 的 init 函数。#####################
pernet_list 保存了各网络子系统(如 loopback 设备、IPv4/IPv6 协议栈、路由、
邻居子系统、netfilter、/proc 条目、sysctl 等)通过
register_pernet_device() / register_pernet_subsys() 注册的 struct pernet_operations。
setup_net() 在创建一个新的 struct net 后,遍历这个列表,逐个调用 ops->init(net),
让每个子系统在该netns中完成自己的初始化与资源分配(例如分配 hash 表、注册该 ns 的 /proc 节点、创建并注册 lo 设备等)。
#####################
在网络设备初始化的时候,我们要调用 net_dev_init 函数,这里面有下面的代码。
register_pernet_device(&loopback_net_ops)
int register_pernet_device(struct pernet_operations *ops)
{int error;mutex_lock(&net_mutex);error = register_pernet_operations(&pernet_list, ops);if (!error && (first_device == &pernet_list))first_device = &ops->list;mutex_unlock(&net_mutex);return error;
}
struct pernet_operations __net_initdata loopback_net_ops = {.init = loopback_net_init,
};
register_pernet_device 函数注册了一个 loopback_net_ops,
在这里面,把 init 函数设置为 loopback_net_init.
static __net_init int loopback_net_init(struct net *net)
{struct net_device *dev;dev = alloc_netdev(0, "lo", NET_NAME_UNKNOWN, loopback_setup);
......dev_net_set(dev, net);err = register_netdev(dev);
......net->loopback_dev = dev;return 0;
......
}
在 loopback_net_init 函数中,我们会创建并且注册一个名字为"lo"的 struct net_device。
注册完之后,在这个 namespace 里面就会出现一个这样的网络设备,称为 loopback 网络设备。举个栗子:
通知所有部门:“有一座新城市建好了,你们去里面各自建好自己的办公楼、设施和数据表。”
list_for_each_entry(ops, &pernet_list, list) {
error = ops_init(ops, net);
}
你可以把 network namespace(struct net) 想成一座新建的独立城市,而 Linux 内核里的各种网络子系统(路由系统、网卡设备、协议栈、统计模块等)就像是不同的部门:
- 路由部门:管理城市的交通路线(路由表)。
- 邻居部门:管理 ARP/邻居缓存。
- 设备部门:负责注册城市里的道路和桥梁(网卡,比如 lo)。
- 统计部门:负责城市的网络统计(/proc/net/* 里的数据)。
- 配置部门:负责 sysctl 配置项(比如 /proc/sys/net/ipv4/…)。
当你创建一个新城市(新的 netns),如果这些部门啥也不干,那这个城市就是一片空地——没有路由、没有设备、没有配置,网络功能完全不可用。
docker启动实现隔离的步骤
1)Docker daemon 接收 run 命令,它会调用底层 OCI runtime(默认是 runc)。
2)runc 调用 clone/unshare 创建新进程用上面这些 CLONE_NEW* 标志,新进程会进入新的 namespace:
clone(CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWNET |CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWUSER |CLONE_NEWCGROUP, ...);
3)初始化新的 namespace
- NET:通过 veth 对创建容器的虚拟网卡,并接到宿主机的网桥(如 docker0)。
- MNT:挂载容器的 rootfs(镜像 + 可写层)。
- UTS:设置容器 hostname。
- PID:启动容器的 init 进程(PID 1)
4)启动用户命令
在这些隔离好的 namespace 里执行 /bin/sh 或容器入口命令。
在 /proc//ns 里观察会看到它的 net, pid, mnt 等链接的 inode ID 跟宿主机进程的不一样,说明它们在不同的 namespace 实例里。Ls -l /proc/pid/ns
(2)Cgroup
cgroup 定义了下面的一系列子系统,每个子系统用于控制某一类资源。
CPU 子系统,主要限制进程的 CPU 使用率。
cpuacct 子系统,可以统计 cgroup 中的进程的 CPU 使用报告。
cpuset 子系统,可以为 cgroup 中的进程分配单独的 CPU 节点或者内存节点。
memory 子系统,可以限制进程的 Memory 使用量。
blkio 子系统,可以限制进程的块设备 IO。devices 子系统,可以控制进程能够访问某些设备。
net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
freezer 子系统,可以挂起或者恢复 cgroup 中的进程。
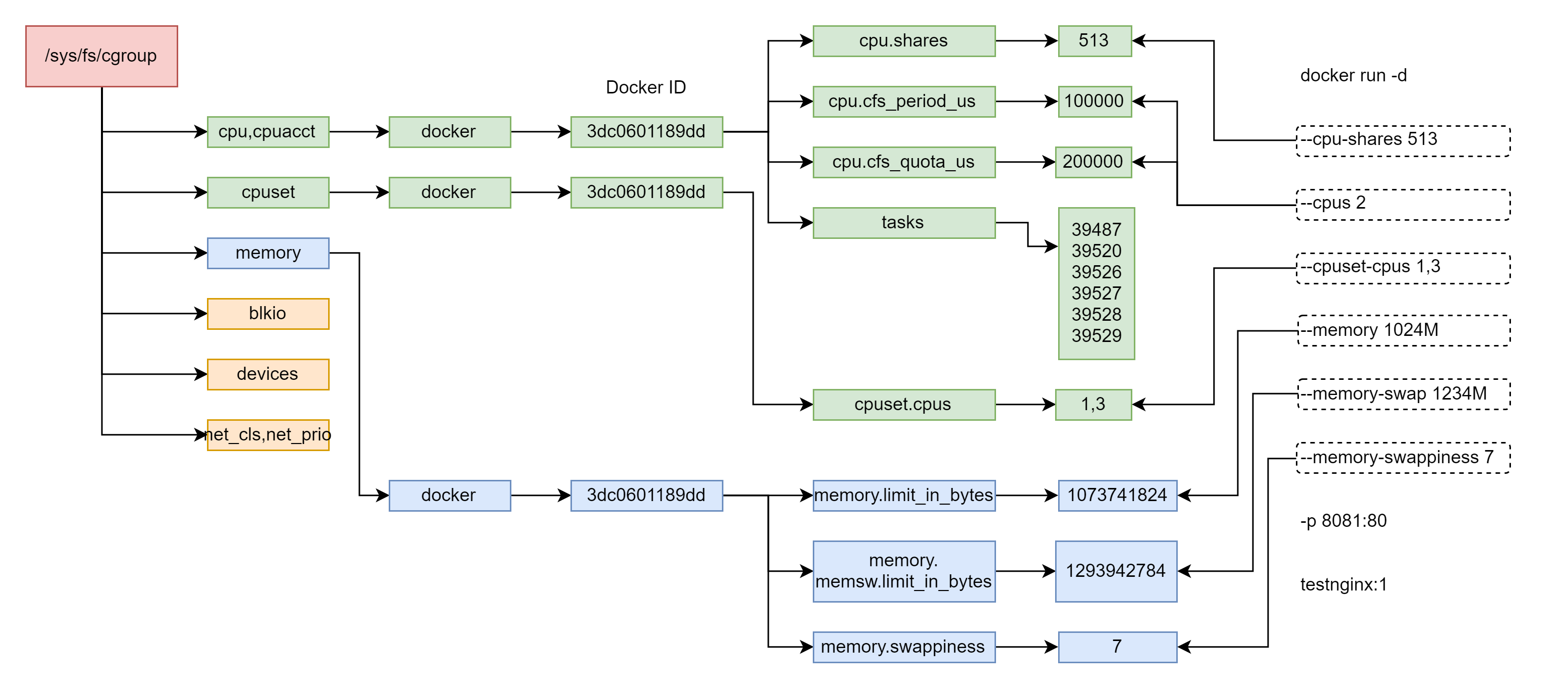
docker run -d --cpu-shares 513 --cpus 2 --cpuset-cpus 1,3 --memory 1024M --memory-swap 1234M --memory-swappiness 7 -p 8081:80 testnginx:1# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3dc0601189dd testnginx:1 "/bin/sh -c 'nginx -…" About a minute ago Up About a minute 0.0.0.0:8081->80/tcp boring_cohen
上面命令对应图片如下:
在 Linux 上,为了操作 cgroup,有一个专门的 cgroup 文件系统,
cgroup 文件系统多挂载到 /sys/fs/cgroup 下:

1. blkio
功能:控制块设备(如硬盘、SSD)的 I/O 资源,限制进程对磁盘的读写速率、IOPS(每秒 I/O 操作数)等。
常见用途:防止某个进程占用过多磁盘带宽,影响其他进程的 I/O 性能(例如限制数据库备份进程的写速度)。
2. cpu
功能:控制进程对 CPU 的使用,通过调度策略(如 CFS 调度器)限制进程的 CPU 时间占比。
核心参数:cpu.shares(相对权重,用于多个进程竞争 CPU 时分配比例)、cpu.cfs_quota_us(限制 CPU 使用率上限)。
3. cpuacct
功能:统计进程或进程组的 CPU 使用情况,包括用户态、内核态的 CPU 时间消耗。
输出文件:cpuacct.usage(总 CPU 时间,单位纳秒)、cpuacct.stat(按用户态 / 系统态分类的时间统计)。
用途:结合 cpu 子系统实现 “限制 + 监控” 闭环,常用于计费或性能分析。
4. cpu,cpuacct
功能:cpu 和 cpuacct 子系统的组合(绑定在一起),同时提供 CPU 资源限制和统计功能。
说明:部分系统会将功能相关的子系统合并为一个目录,简化配置(如同时需要限制和统计 CPU 时,可直接操作此目录)。
5. cpuset
功能:为进程或进程组分配特定的 CPU 核心和内存节点(NUMA 架构下)。
核心参数:cpuset.cpus(允许使用的 CPU 核心,如 0-1 表示核心 0 和 1)、cpuset.mems(允许使用的内存节点)。
用途:在多核心服务器上优化进程布局,例如将实时进程绑定到专属 CPU 核心,避免干扰。
6. devices
功能:控制进程对设备文件(如 /dev/sda、/dev/null)的访问权限(允许 / 禁止读、写、创建等操作)。
核心参数:devices.allow(允许访问的设备及权限)、devices.deny(禁止访问的设备及权限)。
安全意义:限制容器内进程访问宿主机敏感设备(如物理硬盘),增强隔离性。
7. freezer
功能:暂停或恢复进程组的执行(类似 “冻结” 和 “解冻”)。
核心参数:freezer.state(取值为 FROZEN 冻结进程,THAWED 恢复执行)。
用途:调试时暂停进程、资源紧张时临时冻结低优先级任务释放资源。
8. hugetlb
功能:控制进程对大页内存(HugeTLB)的使用,限制大页的分配数量。
说明:大页内存用于减少内存地址转换开销(适合数据库、虚拟化等场景),此子系统防止大页被某一进程耗尽。
9. memory
功能:限制进程的内存使用量(物理内存、swap 交换分区),并统计内存消耗。
核心参数:memory.limit_in_bytes(内存使用上限)、memory.swappiness(控制 swap 倾向)。
用途:防止进程内存泄漏导致系统 OOM(内存溢出),是容器内存限制的核心子系统。
10. net_cls
功能:为进程的网络数据包打上 “类别标签”(classid),结合 Linux 流量控制(tc)工具限制网络带宽。
工作流程:通过标签识别特定进程的流量,再用 tc 配置带宽规则(如限制容器的出站速率)。
11. net_cls,net_prio
功能:net_cls 和 net_prio 子系统的组合,同时提供网络标签和优先级控制。
net_prio 作用:为进程的网络流量设置优先级,影响数据包在网络栈中的处理顺序(如保障关键服务的网络响应速度)。
12. net_prio
功能:单独控制进程网络流量的优先级(与 net_cls 分离的子系统,部分系统可能合并为 net_cls,net_prio)。
13. perf_event
功能:允许 perf 工具(性能分析工具)对 Cgroup 内的进程进行性能采样和分析。
用途:精准监控特定进程组的 CPU 指令执行、缓存命中、函数调用等性能指标。
14. pids
功能:限制进程组内的总进程数量,防止 “fork 炸弹” 或恶意程序创建过多进程耗尽系统资源。
核心参数:pids.max(最大进程数限制)、pids.current(当前进程数统计)。
15. systemd
功能:与 systemd 服务管理器集成,用于管理 systemd 启动的进程的 Cgroup 分组。
说明:systemd 会自动为每个服务创建 Cgroup 目录,方便通过 systemctl 命令管理服务的资源限制。
如上面的命令配置了 cpus,这个值其实是由 cpu.cfs_period_us 和 cpu.cfs_quota_us 共同决定的。cpu.cfs_period_us 是运行周期,cpu.cfs_quota_us 是在周期内这些进程占用多少时间。我们设置了 cpus 为 2,代表的意思是,在周期 100000 微秒的运行周期内,这些进程要占用 200000 微秒的时间,也即需要两个 CPU 同时运行一个整的周期。
对于 cpuset,也即 CPU 绑核的参数,在另外一个文件夹里面 /sys/fs/cgroup/cpuset,这里面同样有一个 docker 文件夹,下面同样有 docker id 文件夹,这里面的 cpuset.cpus 就是配置的绑定到 1、3 两个核。
源码角度看Cgroup精华版
【总结】
注册子系统(提供数据结构+操作函数) → 挂载 cgroupfs → 写文件设置参数(更新内核结构) → 写 tasks 文件绑定进程 → 在内核关键路径读取这些结构并施加限制。
【步骤】
第一步,系统初始化的时候,初始化 cgroup 的各个子系统的操作函数,分配各个子系统的数据结构。
第二步,mount cgroup 文件系统,创建文件系统的树形结构,以及操作函数。
第三步,写入 cgroup 文件,设置 cpu 或者 memory 的相关参数,这个时候文件系统的操作函数会调用到 cgroup 子系统的操作函数,从而将参数设置到 cgroup 子系统的数据结构中。
第四步,写入 tasks 文件,将进程交给某个 cgroup 进行管理,因为 tasks 文件也是一个 cgroup 文件,统一会调用文件系统的操作函数进而调用 cgroup 子系统的操作函数,将 cgroup 子系统的数据结构和进程关联起来。
第五步,对于 CPU 来讲,会修改 scheduled entity,放入相应的队列里面去,从而下次调度的时候就起作用了。对于内存的 cgroup 设定,只有在申请内存的时候才起作用。
【举例】
假设我们要做一个叫 toy 的自定义 cgroup 子系统
目标:限制进程每秒能执行的 CPU 时间片数,超过就记一次“违规”。
第一步:系统初始化时注册子系统
内核启动时,会调用 cgroup_register_subsys() 把 toy 子系统注册到全局的 cgroup_subsys 列表里。
这里我们分配了 toy_cgroup 数据结构,里面有一个 max_ticks 字段,表示允许的最大 CPU 时间片数。
同时注册一组操作函数,比如:
创建新 cgroup 时的 css_alloc()(分配结构)
销毁时的 css_free()(释放结构)
写配置参数时的回调函数。
第二步:挂载 cgroup 文件系统
mount -t cgroup -o toy none /sys/fs/cgroup/toy
内核的 cgroup 文件系统代码会为 toy 创建一棵树形目录结构,默认有一个根节点(root cgroup)。
每个 cgroup 节点都会有一些文件,比如 toy.max_ticks,这些文件的操作函数就是我们注册时提供的回调。
第三步:写入参数文件
echo 100 > /sys/fs/cgroup/toy/mygroup/toy.max_ticks
文件系统的写操作会调用到 cgroup 核心层,进而调用我们子系统注册的 toy_max_write() 回调。
这个回调会把 100 存进 toy_cgroup 结构里的 max_ticks 字段。
从源码角度,这就是通过 cgroup 文件系统把用户空间参数下发到内核子系统数据结构。
第四步:写 tasks 文件把进程加入 cgroup
echo 1234 > /sys/fs/cgroup/toy/mygroup/tasks
内核会调用 toy_attach() 回调,把 PID=1234 对应的 task_struct 和 toy_cgroup 结构关联起来。
从此,这个进程的 task_struct 里会有一个指针指向它所属的 toy cgroup 状态。
第五步:在内核路径中生效
CPU 调度代码在每次给进程分配时间片时,会检查这个进程属于哪个 cgroup。
如果是 toy 子系统管理的 cgroup,就去读取它的 max_ticks 配置。
如果这个进程在 1 秒内使用的时间片超过了 max_ticks,就触发限制(比如降低优先级、记违规次数等)。
对 CPU 控制器来说,就是在调度路径(scheduler_tick())里生效;
对内存控制器来说,就是在 alloc_pages() 或 do_page_fault() 时检查限制。
推荐阅读:
文件系统(dcoker联合文件系统&linux文件系统)
GO的启动流程(GMP模型/内存)