Java Map集合精讲:键值对高效操作指南
很多时候,我们会遇到成对出现的数据,例如,姓名和电话,身份证和人,IP和 域名等等,这种成对出现,并且一一对应的数据关系,叫做映射。
java.util.Map接口,就是专门处理这种映射关系数据的集合类型。
Map集合是一种用于存储键值对(key-value)映射关系的集合类。它提供了一种 快速查找和访问数据的方式,其中每个键都是唯一的,而值可以重复。
1. Map概述
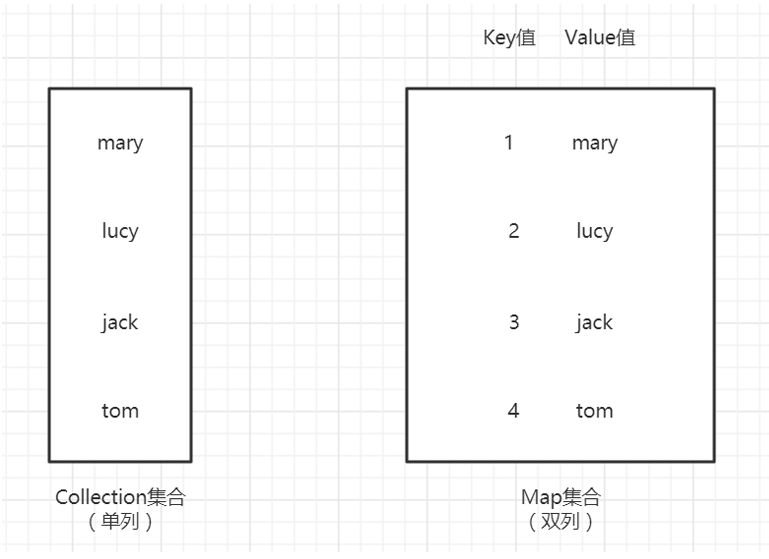
Collection接口为单列集合的根接口,Map接口为双列集合的根接口。
Map集合与Collection集合,存储数据的形式不同:
Map集合特点:
存储元素时,必须以key-value(键值对)的方式进行
键唯一性:Map集合中的键是唯一的,每个键只能对应一个值
可重复值:Map集合中的值可以重复,不同的键可以关联相同的值
高效的查找和访问:通过给定键key值(唯一),可以快速获取与之对应的 value值
Map集合内部使用哈希表或红黑树等数据结构来实现高效的查找和访问
Map接口常用方法(注意泛型K代表Key,范型V代表Value):
// 把key-value存到当前Map集合中
V put(K key, V value);// 把指定map中的所有key-value,存到当前Map集合中
void putAll(Map<? extends K, ? extends V> m);// 当前Map集合中是否包含指定的key值
boolean containsKey(Object key);// 当前Map集合中是否包含指定的value值
boolean containsValue(Object value);// 清空当前Map集合中的所有数据
void clear();// 在当前Map集合中,通过指定的key值,获取对应的value
V get(Object key);// 在当前Map集合中,移除指定key及其对应的value
V remove(Object key);// 返回当前Map集合中的元素个数(一对key-value,算一个元素数据)
int size();// 判断当前Map集合是否为空
boolean isEmpty();// 返回Map集合中所有的key值
Set<K> keySet();// 返回Map集合中所有的value值
Collection<V> values();// 把Map集合中的key-value封装成Entry类型对象,再存放到set集合中,并返回
Set<Map.Entry<K, V>> entrySet();Map集合实现类:
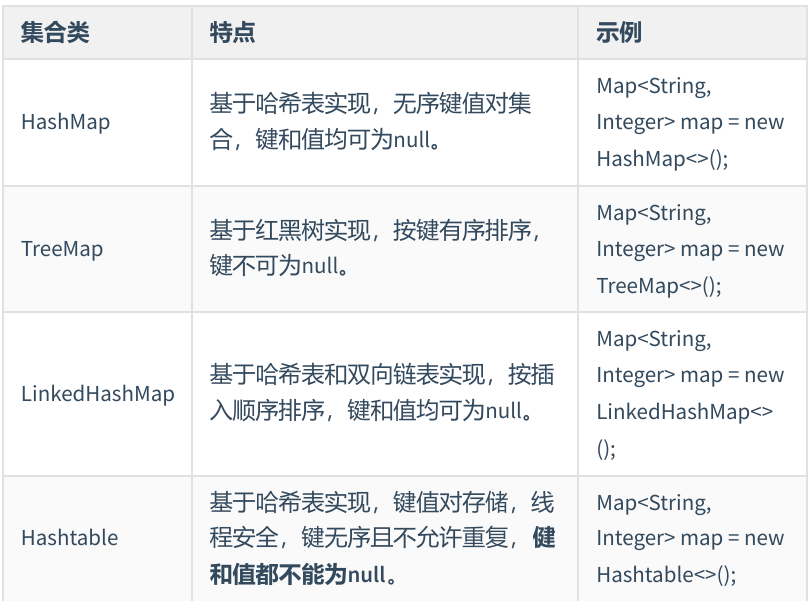
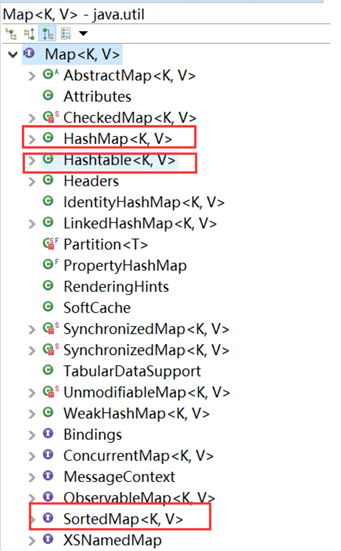
Java提供的Map集合实现类,常见的包括HashMap、TreeMap、LinkedHashMap 等。它们在内部实现和性能方面有所不同,可以根据具体需求选择适合的实现 类。

2. Map遍历
Map集合提供了2种遍历方式。
1)第一种遍历思路
借助Map中的keySet方法,获取一个Set集合对象,内部包含了Map集合中所有 的key,进而遍历Set集合获取每一个key值,再根据key获取对应的value。
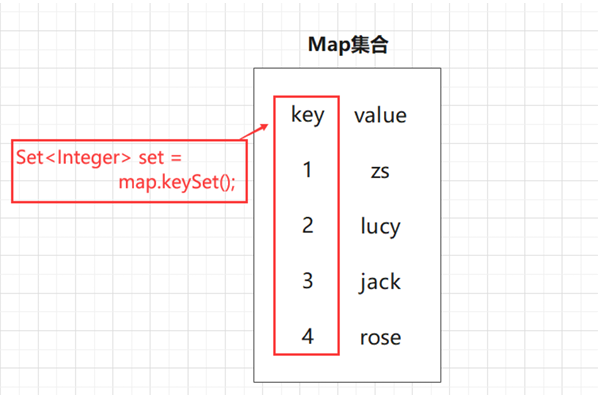
keySet遍历案例:
对前面案例中的map集合对象进行遍历。
import java.util.HashMap;
import java.util.Map;
import java.util.Set;public class Test082_Each {// 双列集合 存放 id-namepublic static void main(String[] args) {// 1. 创建HashMap集合对象,并添加元素Map<Integer, String> map = new HashMap<>();map.put(1, "zs");map.put(2, "ls");map.put(4, "rose");map.put(3, "jack");map.put(2, "lucy"); // lucy 会把 ls覆盖掉// 2. 第一种遍历方法// 先获取所有key, 再根据key获取valueSet<Integer> set = map.keySet();for (Integer k : set) {// 借助key获取对应的value值String v = map.get(k);System.out.println("id: " + k + " name: " + v);}}
}//运行结果:
id: 1 name: zsid: 2 name: lucyid: 3 name: jackid: 4 name: rose2)第二种遍历思路
借助Map中的entrySet方法,获取一个Set对象,内部包含了Map集合中所有的 键值对,然后对键值对进行拆分,得到key和value进行输出。
Map接口源码分析:
package java.util;public interface Map<K,V> {//省略...//获取map集合种所有的键值对Set<Map.Entry<K, V>> entrySet();//Map接口的内部接口,类似内部类interface Entry<K,V> {//Returns the key corresponding to this entry.K getKey();//Returns the value corresponding to this entry. V getValue();//省略...}//省略...}Map接口entrySet()方法解析:将Map集合中的每一组key-value(键值对) 都封装成一个Entry类型对象,并且把这些个Entry对象存放到Set集合中,并 返回。
entrySet遍历案例:
对前面案例中的map集合对象进行遍历。
package com.briup.chap08.test;import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.Map.Entry;public class Test082_Each {// 双列集合 存放 id-namepublic static void main(String[] args) {// 1. 创建HashMap集合对象,并添加元素Map<Integer, String> map = new HashMap<>();map.put(1, "zs");map.put(2, "ls");map.put(4, "rose");map.put(3, "jack");map.put(2, "lucy"); // lucy 会把 ls覆盖掉// 2. 第二种遍历// 获取所有的key-value键值对,得到一个Set集合Set<Entry<Integer, String>> entrySet = map.entrySet();// 遍历Set集合for (Entry<Integer, String> entry : entrySet) {// 拆分键值对中的key和valueInteger key = entry.getKey();String value = entry.getValue();System.out.println("id: " + key + " name: " + value);}}
}//运行结果:id: 1 name: zsid: 2 name: lucyid: 3 name: jackid: 4 name: rose3. HashMap
HashMap底层借助哈希表实现,元素的存取顺序不能保证一致。
HashMap存储的键值对时,如果键类型为自定义类,那么一般需要重写键所属类 的hashCode()和equals()方法(重要,最常用)。
HashMap特点:
键唯一
值可重复
无序性
线程不安全
键和值允许使用null【重点记忆】
案例:
public class Test083_HashMap {public static void main(String[] args) {// 1. 实例化HashMap对象,其中key类型为自定义StudentMap<Student, String> map = new HashMap<>();// 2. 往集合中添加元素// map中插入键值对,调用key所属类的hashCode和equals方法进行判断是否重复map.put(new Student("zs", 78), "010");map.put(new Student("rose", 82), "005");map.put(new Student("lucy", 70), "009");map.put(new Student("lucy", 70), "019"); // 相同key,只能保留一项,"019"会覆盖"009"map.put(new Student("ww", 67), "002");// 注意:HashMap中key和value都可以为nullmap.put(new Student("tom", 86), null);map.put(null, "002");// 3. 基本方法测试// 获取长度System.out.println("size: " + map.size());// 判断key是否存在// 借助 key所属类的hashCode和equals方法完成System.out.println("Student(ww,67)是否存在: " +map.containsKey(new Student("ww", 67)));// 判断value是否存在// 借助value所属类型的 equals方法System.out.println("是否存在 009: " +map.containsValue("009"));// 根据key删除,返回键对应的值String value = map.remove(new Student("lucy", 70));System.out.println("remove(Student(lucy, 70)): " +value);System.out.println("---------------");// 4. 第一种遍历方法Set<Student> keySet = map.keySet();for (Student key : keySet) {System.out.println(key + ": " + map.get(key));}System.out.println("---------------");// 第二种方式遍历Set<Entry<Student, String>> entrySet = map.entrySet();for (Entry<Student, String> entry : entrySet) {System.out.println(entry.getKey() + ": " +entry.getValue());}}
}//运行结果:
size: 6Student(ww,67)是否存在: true
是否存在 009: falseremove(Student(lucy, 70)): 019--------------
null: 002Student [name=rose, age=82]: 005Student [name=zs, age=78]: 010Student [name=tom, age=86]: nullStudent [name=ww, age=67]: 002--------------
省略...结论:key类型如果为自定义类型,重写其hashCode和equals方法!
HashMap中add(key,value)时,需要判断key是否存在(先hashCode再 equals)
HashMap中containsKey(key)时,同样要借助hashCode和equals方法
HashMap中remove(key)时,同样要借助hashCode和equals方法
4. Hashtable
Hashtable是Java中早期的哈希表实现,它实现了Map接口,并提供了键值对的存 储和访问功能。

Hashtable特点:
JDK1.0提供,接口方法较为复杂,后期实现了Map接口
线程安全:Hashtable是线程安全的,相对于HashMap性能稍低
键和值都不能为null:如果尝试使用null作为键或值,将会抛出 NullPointerException
哈希表实现:和HashMap一样,内部使用哈希表数据结构来存储键值对
案例:
import java.util.Enumeration;
import java.util.Hashtable;
import com.briup.chap08.bean.Student;public class Test084_Hashtable {public static void main(String[] args) {// 1. 实例化Hashtable对象,其中key类型为自定义StudentHashtable<Student, String> map = new Hashtable<>();// 2. 往集合中添加元素// map中插入键值对,调用key所属类的hashCode和equals方法进行判断是否重复map.put(new Student("zs", 78), "010");map.put(new Student("rose", 82), "005");map.put(new Student("lucy", 70), "009");map.put(new Student("lucy", 70), "019"); // 相同key,只能保留一项,"019"会覆盖"009"map.put(new Student("ww", 67), "002");// 注意:Hashtable中key和value不能为null,否则抛出NullPointerException// map.put(new Student("tom", 86), null);// map.put(null, "002");// 3. 遍历,Hashtable早期提供的方法较为繁琐Enumeration<Student> keys = map.keys();while (keys.hasMoreElements()) {Student key = keys.nextElement();String value = map.get(key);System.out.println(key + ": " + value);}}
}//运行输出:Student [name=lucy, age=70]: 019Student [name=zs, age=78]: 010Student [name=ww, age=67]: 002Student [name=rose, age=82]: 0055. TreeMap
TreeMap是有序映射实现类,它实现了SortedMap接口,基于红黑树数据结构来 存储键值对。
TreeMap特点:
键的排序:TreeMap中的键是按照自然顺序或自定义比较器进行排序的
红黑树实现:TreeMap内部使用红黑树这种自平衡二叉搜索树数据结构来存 储键值对
键唯一,值可重复
线程不安全,如果在多线程环境下使用TreeMap,应该使用Collections工具类 处理
初始容量:TreeMap没有初始容量的概念,它会根据插入的键值对动态地调 整红黑树的大小
TreeMap 自然排序案例:
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;public class Test085_TreeMap {public static void main(String[] args) {Map<Integer, String> map = new TreeMap<>();map.put(4, "mary");map.put(2, "jack");map.put(1, "tom");map.put(3, "lucy");Set<Integer> keys = map.keySet();for (Integer key : keys) {System.out.println(key + ": " + map.get(key));}}
}//运行结果:
1: tom2: jack3: lucy4: maryTreeMap 比较器排序案例:
创建TreeMap集合对象,额外指定比较器,要求按名字降序, 如果名字相同则按年龄升序。
// 注意导入自定义Student类
import com.briup.chap08.bean.Student;
import java.util.Comparator;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
import java.util.Map.Entry;// 比较器排序
public class Test085_TreeMap_Comparator {public static void main(String[] args) {// 1. 额外提供比较器对象Comparator<Student> comp = new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {// 先按照名字降序int r = o2.getName().compareTo(o1.getName());// 如果名字一样,再按照年龄升序if (r == 0)r = o1.getAge() - o2.getAge();return r;}};// 2. 实例化TreeMap对象Map<Student, String> map = new TreeMap<>(comp);// 3. 添加键值对map.put(new Student("zs", 78), "010");map.put(new Student("rose", 82), "005");map.put(new Student("lucy", 79), "009");map.put(new Student("lucy", 79), "009"); // 重复键,会被覆盖map.put(new Student("tom", 68), "019");map.put(new Student("tom", 86), "012");map.put(new Student("ww", 67), "002");// key不能为null, 否则出 NullPointerException// map.put(null,"002");// 4. 遍历Set<Entry<Student, String>> entrySet = map.entrySet();for (Entry<Student, String> entry : entrySet) {System.out.println(entry.getKey() + ": " + entry.getValue());}}
}//运行结果:
Student [name=zs, age=78]: 010Student [name=ww, age=67]: 002Student [name=tom, age=68]: 019Student [name=tom, age=86]: 012Student [name=rose, age=82]: 005Student [name=lucy, age=79]: 009思考,如果要求重复的元素也能够放入,如何实现?
修改比较器中返回值即可:当r==0,即元素属性一样时,返回非0值即可。
// 1. 额外提供比较器对象
Comparator<Student> comp = new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {// 先按照名字降序int r = o2.getName().compareTo(o1.getName());// 如果名字一样,再按照年龄升序if (r == 0) {r = o1.getAge() - o2.getAge();}// 当 r == 0,即两个学生名字和年龄都相同时,返回非0值(如1),避免被TreeMap视为重复键return (r == 0) ? 1 : r;}
};TreeMap小结:
TreeMap底层借助红黑树实现,它提供了高效的有序映射功能,可以用于范 围查找、排序和遍历等操作。但红黑树的平衡操作会带来额外的开销,相比 于HashMap等实现类,TreeMap在插入和删除操作上可能稍慢。
因此,在选择使用TreeMap时,需要根据具体需求权衡性能和有序性的需 求。
6. LinkedHashMap
LinkedHashMap是HashMap的一个子类,底层在哈希表的基础上,通过维护一个 双向链表来保持键值对的有序性,可以保证存取次序一致。
案例:
import java.util.LinkedHashMap;
import java.util.Map;
import com.briup.chap08.bean.Student;// LinkedHashMap可以保证 存取次序一致
public class Test086_LinkedHashMap {public static void main(String[] args) {// 1. 实例化LinkedHashMap类对象Map<String, Student> map = new LinkedHashMap<>();// 2. 添加元素map.put("010", new Student("zs", 78));map.put("005", new Student("rose", 82));map.put("009", new Student("lucy", 70));map.put("019", new Student("lucy", 70)); // 重复的value,但key不同,所以会添加map.put("002", null); // value可以为nullmap.put(null, new Student("ww", 67)); // key也可以为null// 3. 遍历for (String key : map.keySet()) {System.out.println(key + " " + map.get(key));}}
}//结果输出:
010 Student [name=zs, age=78]005 Student [name=rose, age=82]009 Student [name=lucy, age=70]019 Student [name=lucy, age=70]002 nullnull Student [name=ww, age=67]可以看出,数据存入Map中的顺序,就是存储的顺序,也是取出的顺序!
7. Map小结