Redis7学习--十大数据类型 bitmap、Hyperloglog、GEO、Stream、bitfield
目录
一、前言
二、Redis位图(bitmap)
基本命令
应用
三、Redis基数统计(Hyperloglog)
基数统计
HyperLogLog简介
基本命令
使用场景示例
注意事项
实际应用场景
四、Redis地理空间(GEO)
GEO
基本命令
使用场景示例
底层实现原理
实际应用场景
五、Redis流(Stream)
消息队列
Stream核心特性
基本命令
Stream应用场景
六、Redis位域(bitfield)
Bitfield核心特性
基本命令
注意事项
实际应用场景
一、前言
上篇文章中我们学习了Redis十大数据类型中的前五个,本篇文章我们再来学习后面的五个。
二、Redis位图(bitmap)
位图我们已经很熟悉了,C/C++中都有位图这个结构,且我们引入位图的目的都是差不多的,主要是为了提供一种极其节省内存且高效的方式来处理大规模的布尔型数据或进行位级别的操作。
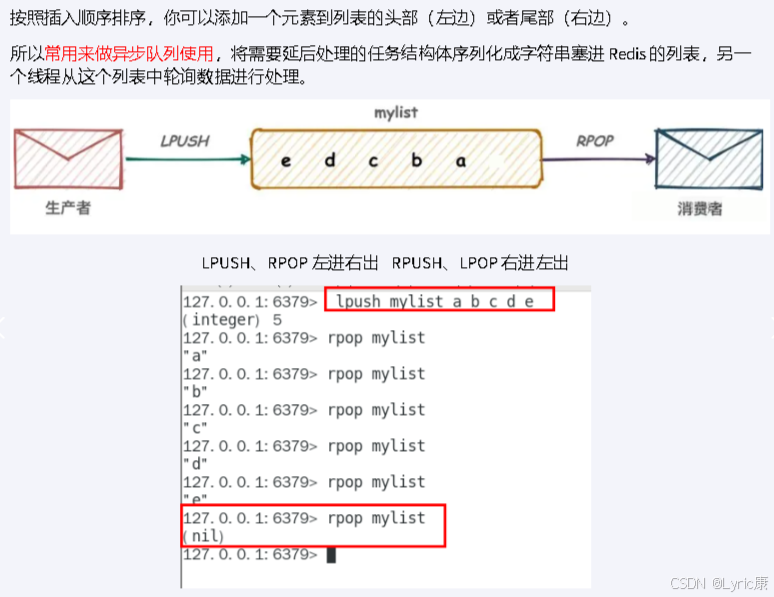
- 用String类型作为底层数据结构实现的一种统计二值状态的数据类型
- 位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,每个二进制位都对应一个偏移量(我们称之为一个索引)
- Bitmap支持的最大位数是2^32位,它可以极大的节约存储空间,使用512M内存就可以存储多达42.9亿的字节信息(2的32次方 = 4294967296)
基本命令
setbit key offset value // 将第offset的值设为value value只能是0或1 offset 从0开始
getbit key offset // 获得第offset位的值
strlen key // 得出占多少字节 超过8位后自己按照8位一组一byte再扩容
bitcount key // 得出该key里面含有几个1
bitop and destkey key1 key2 // 对一个或多个 key 求逻辑并,并将结果保存到 destkey
bitop or destkey key1 key2 // 对一个或多个 key 求逻辑或,并将结果保存到 destkey
bitop xor destkey key1 key2 // 对一个或多个 key 求逻辑异或,并将结果保存到 destkey
bitop not destkey key // 对key 求逻辑非,并将结果保存到 destkey 假设我们有一个网站,需要记录用户每天的签到情况。我们可以用位图来实现一个高效的签到系统。
- key: 使用
user:sign:202310作为 2023 年 10 月的签到记录 key。 - offset: 用日期作为偏移量。10月1日的 offset 是 0,10月2日的 offset 是 1,以此类推,10月31日的 offset 是 30。
- value (bit): 1 表示已签到,0 表示未签到。
假设用户在 10 月 1 日、10 月 3 日和 10 月 5 日签到了。

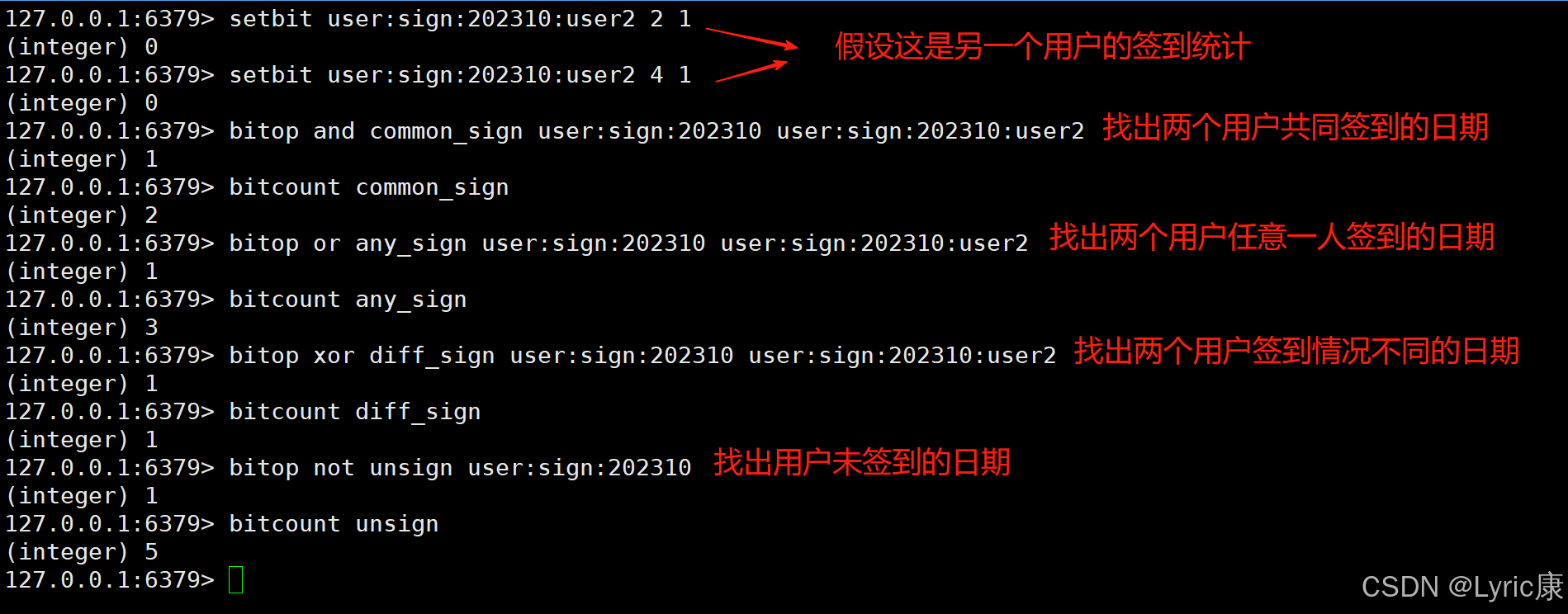
应用
如上面的例子,
- 做签到很适合位图
- 每天使用1个1亿位的Bitmap约占12MB的内存(10^8/8/1024/1024),10天的Bitmap的内存开销约为120MB,内存压力不算太高。
- 在实际使用时,最好对Bitmap设置过期时间,让Redis自动删除不再需要的签到记录以节省内存开销。
- 对于电影和广告是否被点击播放过也可以用位图。
三、Redis基数统计(Hyperloglog)
基数统计
基数统计是指统计一个集合中不重复元素的个数。例如:
- 集合 {1,2,3,4,5} 的基数是5
- 集合 {1,2,2,3,3,3} 的基数是3
在实际应用中,基数统计常用于:
- 统计网站的独立访客数(UV)
- 统计文章的阅读人数
- 统计搜索关键词的不同数量
HyperLogLog简介
HyperLogLog是Redis提供的一种用于基数统计的算法,它具有以下特点:
- 高效利用内存:只需要12KB内存就可以统计多达2^64个不同元素的基数
- 误差率低:标准误差仅为0.81%
- 合并功能:多个HyperLogLog可以合并计算总基数
基本命令
pfadd key element [element...] //向HyperLogLog中添加一个或多个元素。如果HyperLogLog不存在,会自动创建。pfcount key [key...]//获取基数的估计值
pfmerge destkey sourcekey [sourcekey ...] //合并多个HyperLogLog
使用场景示例
假设我们要统计一个网站的UV,即独立访客数
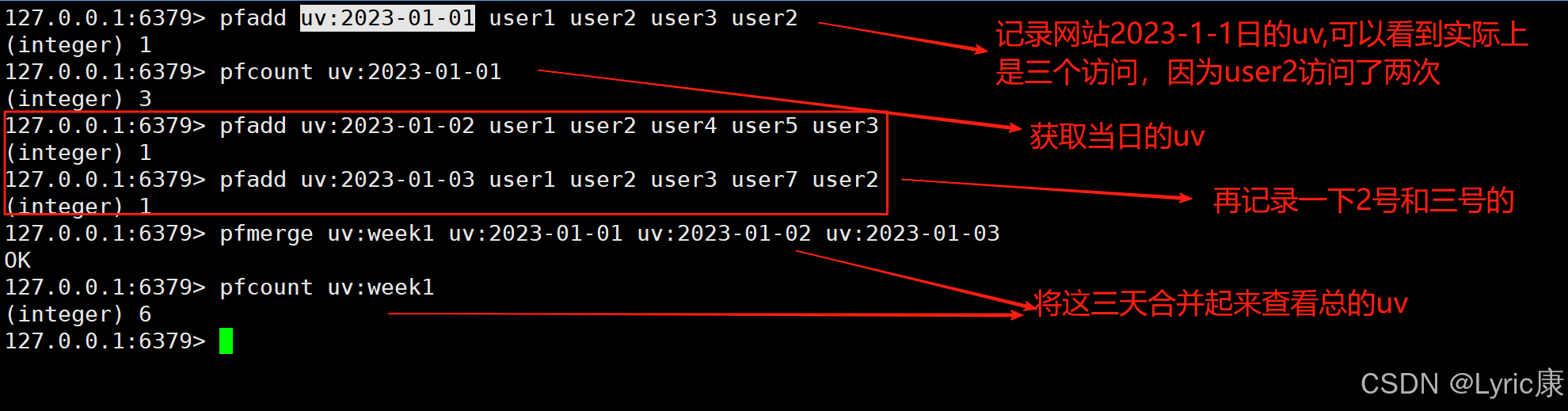
注意事项
- 不是精确计数:HyperLogLog提供的是近似值,有约0.81%的误差,HyperLogLog是一种概率算法,它通过哈希和概率统计来估计基数,而不是精确计数
- 内存固定:无论存储多少元素,每个HyperLogLog只占用12KB内存,HyperLogLog使用16384(2^14)个6位的寄存器(桶)来存储数据
- 稀疏表示:对于小基数,Redis会使用稀疏表示来节省内存,当元素数量很少时(Redis配置的默认阈值是3000),使用更紧凑的表示法,不是立即分配12KB,而是用更少的内存记录实际元素,当基数超过阈值时,自动转换为完整的12KB表示
- 不支持元素查询:无法判断某个元素是否在HyperLogLog中,设计初衷就是只回答"有多少个不同元素",而不是"某个元素是否存在",只存储基数信息,不存储原始元素。
- 适合大数据量:对于小数据量,使用SET更合适
实际应用场景
案例1:大型电商UV统计
- 使用HyperLogLog,因为:
- 每天可能有数百万UV
- 12KB/天的存储成本极低
- 0.81%误差在业务可接受范围内
案例2:小型论坛在线用户
- 使用SET,因为:
- 同时在线用户可能只有几百人
- 需要精确判断用户是否在线
- 内存消耗不大(几百用户只需几十KB)
四、Redis地理空间(GEO)
地球上的地理位置是使用二维的经纬度表示,经度范围 (-180, 180],纬度范围 (-90, 90],只要我们确定一个点的经纬度就可以名取得他在地球的位置。
例如滴滴打车,最直观的操作就是实时记录更新各个车的位置,当我们要找车时,在数据库中查找距离我们(坐标x0,y0)附近r公里范围内部的车辆
GEO
Redis GEO 是 Redis 提供的地理位置相关功能,基于有序集合(Sorted Set)实现,可以存储地理位置信息并进行相关计算。
其特点是
- 基于Sorted Set实现:底层使用有序集合存储,元素是地理位置名称,score是经过编码的地理位置信息
- 经纬度精度:使用WGS84坐标系,经度范围[-180,180],纬度范围[-85.05112878,85.05112878]
- 高效查询:支持半径查询、距离计算等操作
- 距离单位:支持米(m)、千米(km)、英里(mi)、英尺(ft)
基本命令
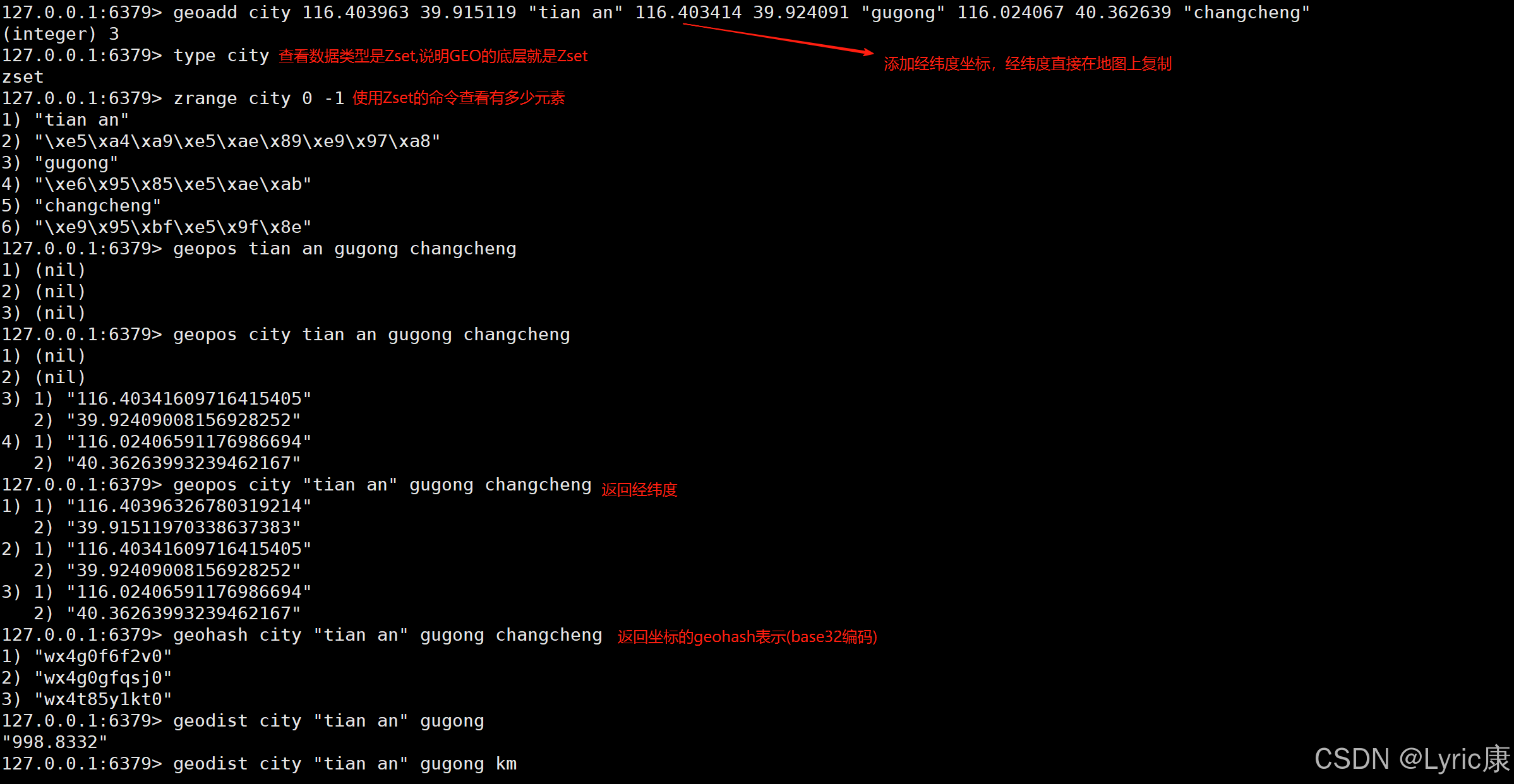
//向指定key中添加一个或多个地理位置。key:存储地理位置的键 longitude:经度
//latitude:纬度 member:位置名称/标识
geoadd key longitude latitude member [longitude latitude member ...] //获取一个或多个位置成员的经纬度坐标
geopos key member [member ...]//计算两个位置之间的距离unit:距离单位,可选:m:米(默认) km:千米 mi:英里 ft:英尺
geodist key member1 member2 [unit]//查询指定圆心和半径内的位置成员(Redis 6.2+已废弃)
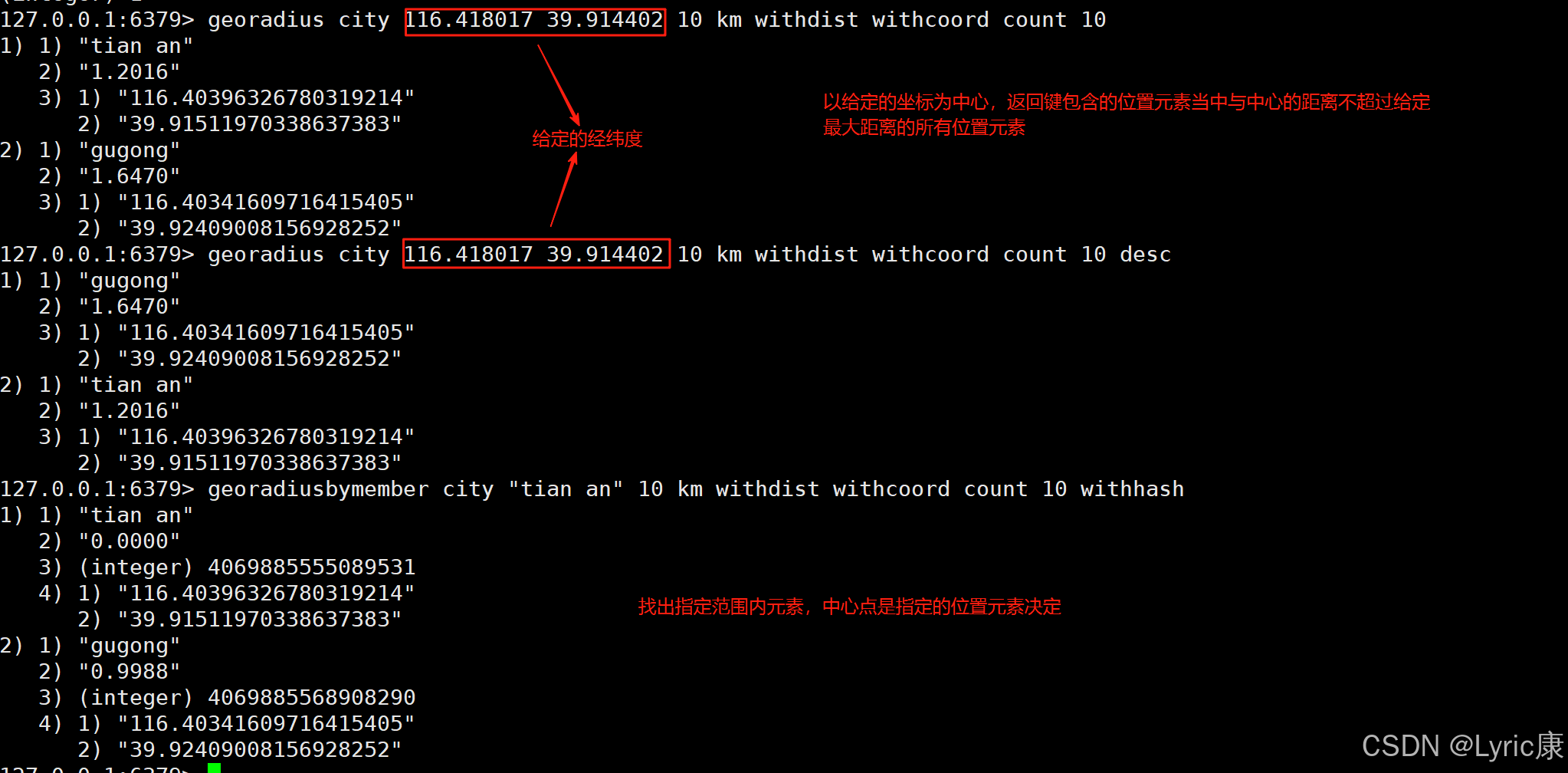
georadius key longitude latitude radius unit [WITHDIST] [WITHCOORD] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]//更强大的地理位置查询命令,支持半径和矩形区域查询
//FROMMEMBER:从指定成员位置开始 FROMLONLAT:从指定经纬度开始 BYRADIUS:按半径搜索
//BYBOX:按矩形区域搜索 WITHCOORD:返回坐标 WITHDIST:返回距离 WITHHASH:返回Geohash值
//COUNT:限制返回数量 ASC/DESC:排序方式
geosearch key [FROMMEMBER member] [FROMLONLAT longitude latitude] [BYRADIUS radius unit] [BYBOX width height unit] [ASC|DESC] [COUNT count] [WITHCOORD] [WITHDIST] [WITHHASH]使用场景示例

底层实现原理
Redis GEO功能基于:
- Geohash算法:将二维经纬度编码为一维字符串,附近的位置有相似的前缀
- Sorted Set:使用64位score存储Geohash的52位整数表示
- ZSET操作:所有GEO命令实际上都是对ZSET的操作
实际应用场景
- 美团附近的饭店、酒店
- 高德地图附近的店
五、Redis流(Stream)
Redis Stream是Redis 5.0引入的一种新的数据结构,专门为消息流式处理设计,它结合了日志数据结构的持久化和消息队列的消费组模式。
消息队列
实现消息队列的三个方式
List:
- List实现消息队列
- Pub/Sub 发布订阅
- Stream流 (Redis版的MQ消息中间件+阻塞队列)
发布订阅:
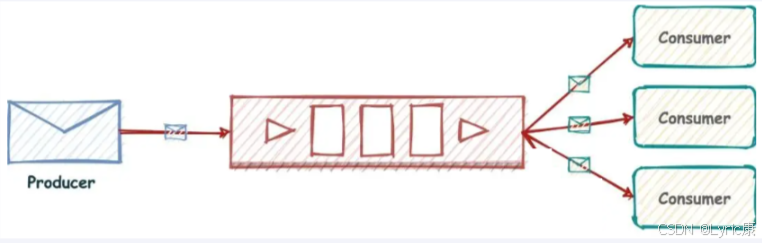
Redis 发布订阅 (pub/sub) 有个缺点就是消息无法持久化,如果出现网络断开、Redis 崩溃等,消息就会被丢弃。而且也没有 Ack 机制来保证数据的可靠性,假设一个消费者都没有,那消息就直接被丢弃了。Stream流实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持ack确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
Stream结构:
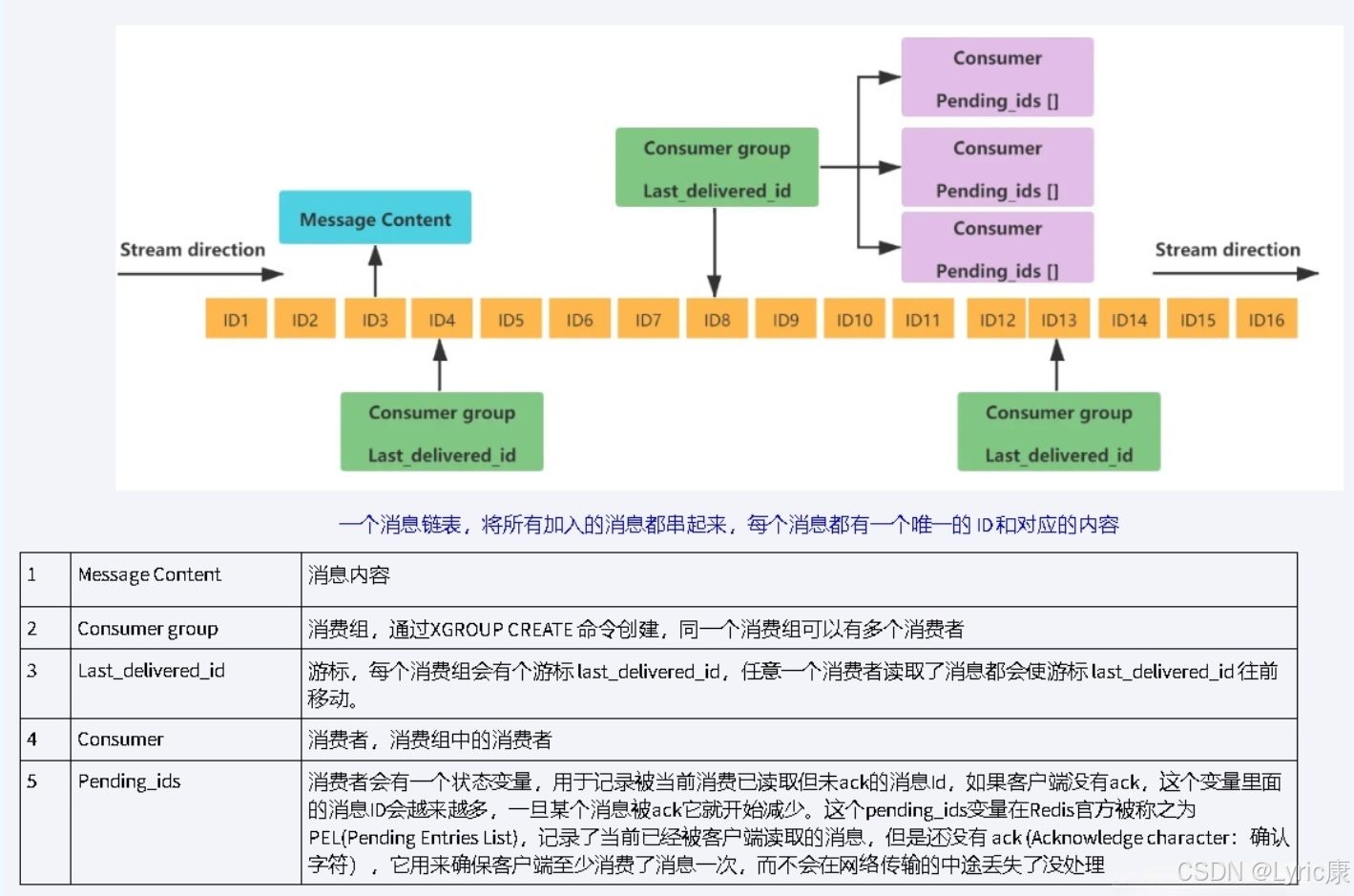
Stream核心特性
- 持久化消息日志:所有消息都会被持久化存储
- 消息ID序列:基于时间戳和序列号的唯一ID
- 消费者组支持:多个消费者组可以独立消费同一条消息流
- 阻塞和非阻塞读取:支持等待新消息到达的模式
- 历史消息追溯:可以访问任意历史消息
基本命令
| 指令名称 | 指令作用 |
|---|---|
| XADD | 添加消息到队列末尾 |
| XTRIM | 限制 Stream 的长度,如果已经超长会进行截取 |
| XDEL | 删除消息 |
| XLEN | 获取 Stream 中的消息长度 |
| XRANGE | 获取消息列表(可以指定范围),忽略删除的消息 |
| XREVRANGE | 和 XRANGE 相比区别在于反向获取,ID 从大到小 |
| XREAD | 获取消息(阻塞 / 非阻塞),返回大于指定 ID 的消息 |
| 指令名称 | 指令作用 |
|---|---|
| XGROUP CREATE | 创建消费者组 |
| XREADGROUP GROUP | 读取消费者组中的消息 |
| XACK | ack 消息,消息被标记为 “已处理” |
| XGROUP SETID | 设置消费者组最后递送消息的 ID |
| XGROUP DELCONSUMER | 删除消费者组 |
| XPENDING | 打印待处理消息的详细信息 |
| XCLAIM | 转移消息的归属权(长期未被处理 / 无法处理的消息,转交给其他消费者组进行处理) |
| XINFO | 打印 Stream\Consumer\Group 的详细信息 |
| XINFO GROUPS | 打印消费者组的详细信息 |
| XINFO STREAM | 打印 Stream 的详细信息 |

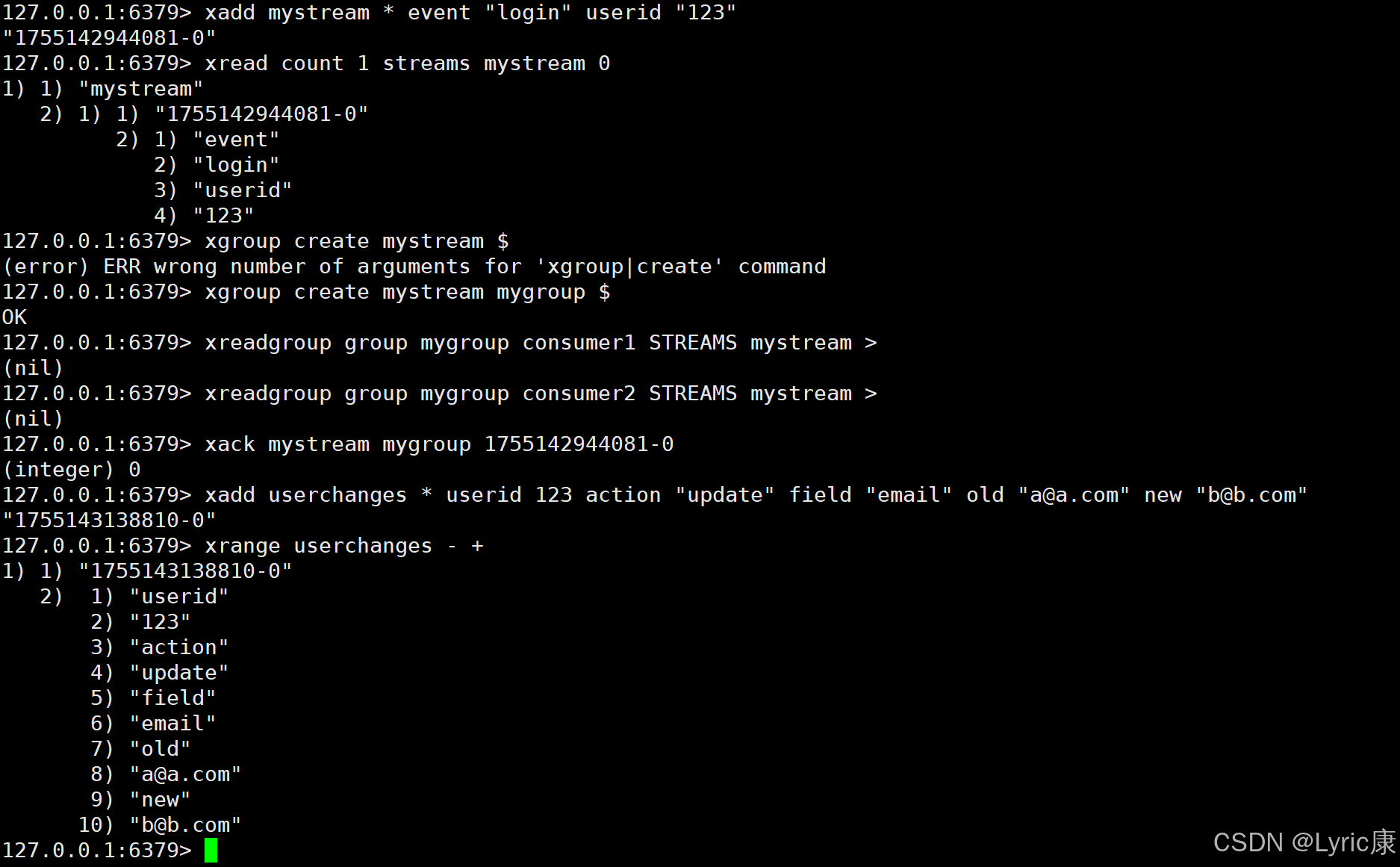
XADD mystream * event "login" userid "123"
命令解析:
XADD:向一个 Stream 添加一个新的条目(entry)。mystream:Stream 的名称,即数据将被添加到这个 Stream 中。*:自动生成的 ID。Redis 会自动生成一个唯一的 ID 来标识这个条目。event "login"和userid "123":键值对形式的数据,表示事件类型为 "login",用户 ID 为 "123"。返回值:
"1755142944081-0":新添加条目的唯一 ID,由时间戳和序列号组成。
XREAD COUNT 1 STREAMS mystream 0
命令解析:
XREAD:从一个或多个 Stream 中读取消息。COUNT 1:限制返回的消息数量为 1。STREAMS mystream 0:指定要读取的 Stream 名称及起始 ID。这里0表示从 Stream 的最开始位置开始读取。返回值:
- 结果是一个嵌套数组,包含 Stream 名称、条目 ID 及其字段和值。
XGROUP CREATE mystream mygroup $
命令解析:
XGROUP CREATE:创建一个新的消费者组。mystream:指定 Stream 名称。mygroup:消费者组的名称。$:指定消费者组开始消费的位置。$表示从当前最新条目之后开始消费。返回值:
OK:表示命令执行成功。
XREADGROUP GROUP mygroup consumer1 STREAMS mystream >
命令解析:
XREADGROUP:从一个或多个 Stream 中读取消费者组未确认的消息。GROUP mygroup consumer1:指定消费者组名称和消费者名称。STREAMS mystream >:指定要读取的 Stream 名称及起始 ID。>表示只读取新的消息。返回值:
(nil):表示没有新的消息可以读取。
XACK mystream mygroup 1755142944081-0
命令解析:
XACK:确认消息已被处理。mystream:Stream 的名称。mygroup:消费者组的名称。1755142944081-0:要确认的消息 ID。返回值:
(integer) 0:表示没有消息被确认(可能是因为该消息已经被确认过或者不存在)。
XADD userchanges * userid 123 action "update" field "email" old "a@a.com" new "b@b.com"
命令解析:
XADD:向一个 Stream 添加一个新的条目。userchanges:Stream 的名称。*:自动生成的 ID。userid 123、action "update"、field "email"、old "a@a.com"、new "b@b.com":键值对形式的数据,表示用户 ID 为 123 的邮箱更新记录。返回值:
"1755143138810-0":新添加条目的唯一 ID。
XRANGE userchanges - +
命令解析:
XRANGE:按时间顺序返回 Stream 中的一个范围内的条目。userchanges:Stream 的名称。-和+:分别表示最早的 ID 和最新的 ID,即返回所有条目。返回值:
- 结果是一个嵌套数组,包含条目 ID 及其字段和值。
Stream应用场景
- 消息队列系统:替代传统的Redis列表实现的消息队列
- 事件溯源:记录所有状态变化事件
- 实时数据处理:处理传感器数据、日志等实时流
- 通知系统:实现用户通知的存储和分发
- 审计日志:记录所有操作的完整审计日志
六、Redis位域(bitfield)
Redis Bitfield(位域)是Redis 3.2引入的一种高级数据结构,允许对字符串中的任意位进行读写操作,并支持多种位宽的整数(有符号/无符号)。它将字符串视为一个由二进制位组成的数组,提供了灵活的位级操作能力。
Bitfield核心特性
- 多类型位操作:支持8/16/32/64位有符号/无符号整数
- 位宽自定义:可操作1~64位任意宽度的整数
- 原子操作:多个位操作可以打包成事务执行
- 溢出控制:提供三种溢出处理策略
- 位偏移访问:可以从字符串的任意位偏移位置读写数据
基本命令
核心命令如下
BITFIELD key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL]类型(type)表示法
格式:[u|i]<bits>,其中:
u:无符号整数i:有符号整数(使用补码表示)<bits>:位宽(1~64),如u8表示8位无符号整数,i16表示16位有符号整数
bitfield key get type offset //读取位域值
bitfield key set type offset value //读取位域值
bitfield key incrby type increment //位域值自增/自减
bitfield key overflow sat incrby u8 0 100 //设置溢出策略为饱和模式
//三种溢出处理策略:WRAP:环绕(默认,如u8最大值255+1=0) SAT:饱和(达到最大值后不再增长) FAIL:失败(不执行操作,返回空值)bitfield mykey GET u8 0 SET u8 0 255 INCRBY u8 0 1 OVERFLOW FAIL INCRBY u8 0 1//多个操作可以在一个命令中执行,按顺序返回结果溢出测试
WRAP: 使用回绕 (Wrap around) 方法处理有符号和无符号整数溢出

Set: 使用饱和计算(saturation arithmetic) 方法处理溢出, 下溢计算的结果为最小的整数值,而上溢计算的结果为最大的整数值

FAIL :命令将拒绝执行那些会导致上溢或者下溢情况出现的计算,并向用户返回空值表示计算未被执行

注意事项
实际应用场景
用户签到系统:用1位表示1天的签到状态,1个字节(8位)可表示8天,1个字符串可表示365天(46字节)
库存计数器:用16位无符号整数存储商品库存,一个字符串可存储多个商品库存
- 位宽限制:最大支持64位整数,超过会返回错误
- 偏移计算:偏移量是指"位"偏移,而非字节偏移
- 内存分配:设置高位偏移时会自动扩展字符串长度
- 溢出处理:不同场景需选择合适的溢出策略,默认WRAP可能导致意外结果
- 返回值:多个操作时按顺序返回结果数组,失败返回nil
感谢阅读!