考研408《计算机组成原理》复习笔记,第四章(3)——指令集、汇编语言
首先别乱学

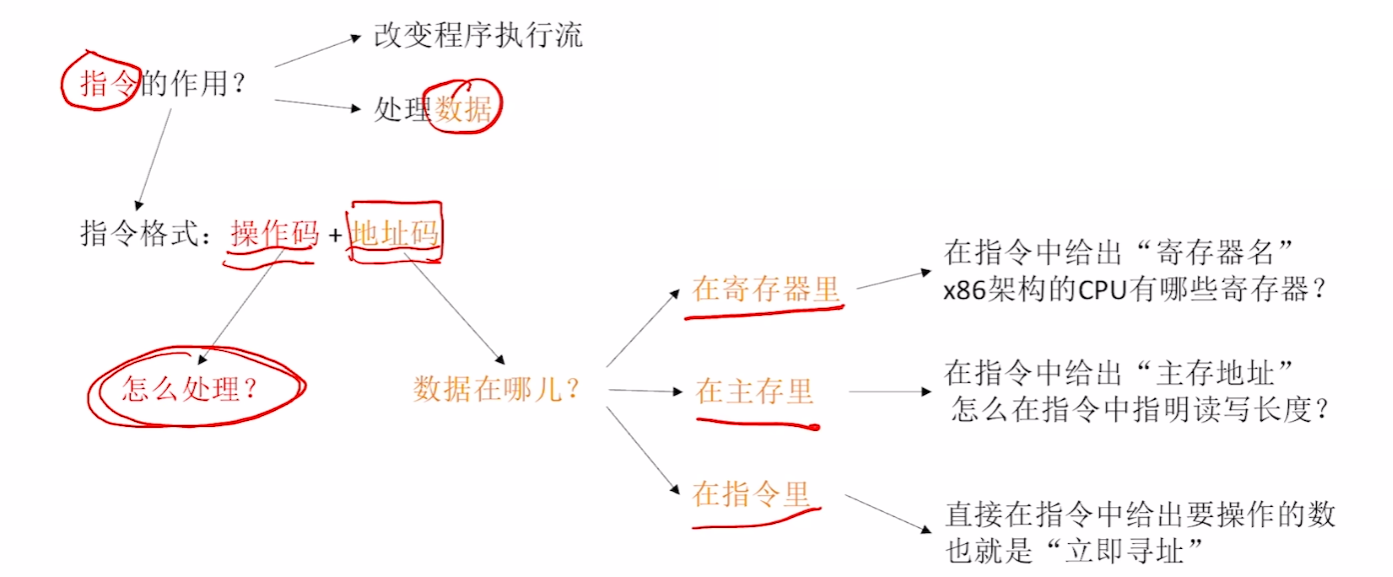
一、学习思路框架
这一章就先理解基本的汇编机器指令,能基本看懂题目
二、Intel x86格式指令集
首先,先按照最常用最正常的【Intel x86格式】的指令集学习,【AT&T格式】的很少用,最后对比一下即可。
1、数据在哪?
1)在【寄存器】里
首先我们直接粗暴记忆:
- 【E】开头的都是表示【寄存器】,都是【32bit】
- 然后前4种寄存器:【EAX】、【EBX】、【ECX】、【EDX】还可以再细分
- 它可以指定它的【后2字节(低16位)】位置作为一个更小的寄存器
- 分别是【AX】、【BX】、【CX】、【DX】,记住都是【16bit】就行
- 然后这4个寄存器各自还能再分2个寄存器,分别在最后面【各占1字节(8bit)】
- 【AX】对应的就是分别是【AH】、【AL】
- 【BX】对应的就是分别是【BH】、【BL】
- 【CX】对应的就是分别是【CH】、【CL】
- 【DX】对应的就是分别是【DH】、【DL】
- 反正记住都是【8bit】就行
;
回忆知识点:对应的寻址方式是那种?
- 【寄存器寻址】
- 【寄存器间接寻址】
- 【基址寻址】
- 【变址寻址】
- 【堆栈寻址里的 “硬堆栈”】
- 【还有别的 “复合寻址方式”】(反正凡是涉及【寄存器】的.......)



2)在【主存】里
- 有【中括号 “ [...] ” 】的就是主存!!!!
- 例子(先别管别的文字,只用看红色标记)
- 留意:
- [ 直接是数字 ]:表示主存的地址,【直接寻址】
- [ 寄存器的名字 ]:表示寄存器里是主存地址,【间接寻址】
- [ 一堆加减乘除 ]:表示【偏移寻址(相对寻址)】或【复合寻址】,具体还要后面细学分析
;
回忆知识点:对应的寻址方式是那种?
- 【直接寻址】
- 【间接寻址】
- 【隐含寻址】
- 【相对寻址】
- 【堆栈寻址里的 “软堆栈”】
- 【还有别的 “复合寻址方式”】(反正凡是涉及【主存】的.......)

3、在【指令】里
- 就是我们学的【立即寻址】!!!
- 数据以 “立即数” 形式直接给出在指令中,执行时无需访问主存、寄存器,直接从指令里提取数据。
- 所以都是【已知常数(二进制、十进制...)】,而不是【未知变量】
- 例子(先别管别的文字,只用看红色标记)
;
回忆知识点:对应的寻址方式是那种?
- 只有【直接寻址】!!!!!!!!!!

4)结合指令例子
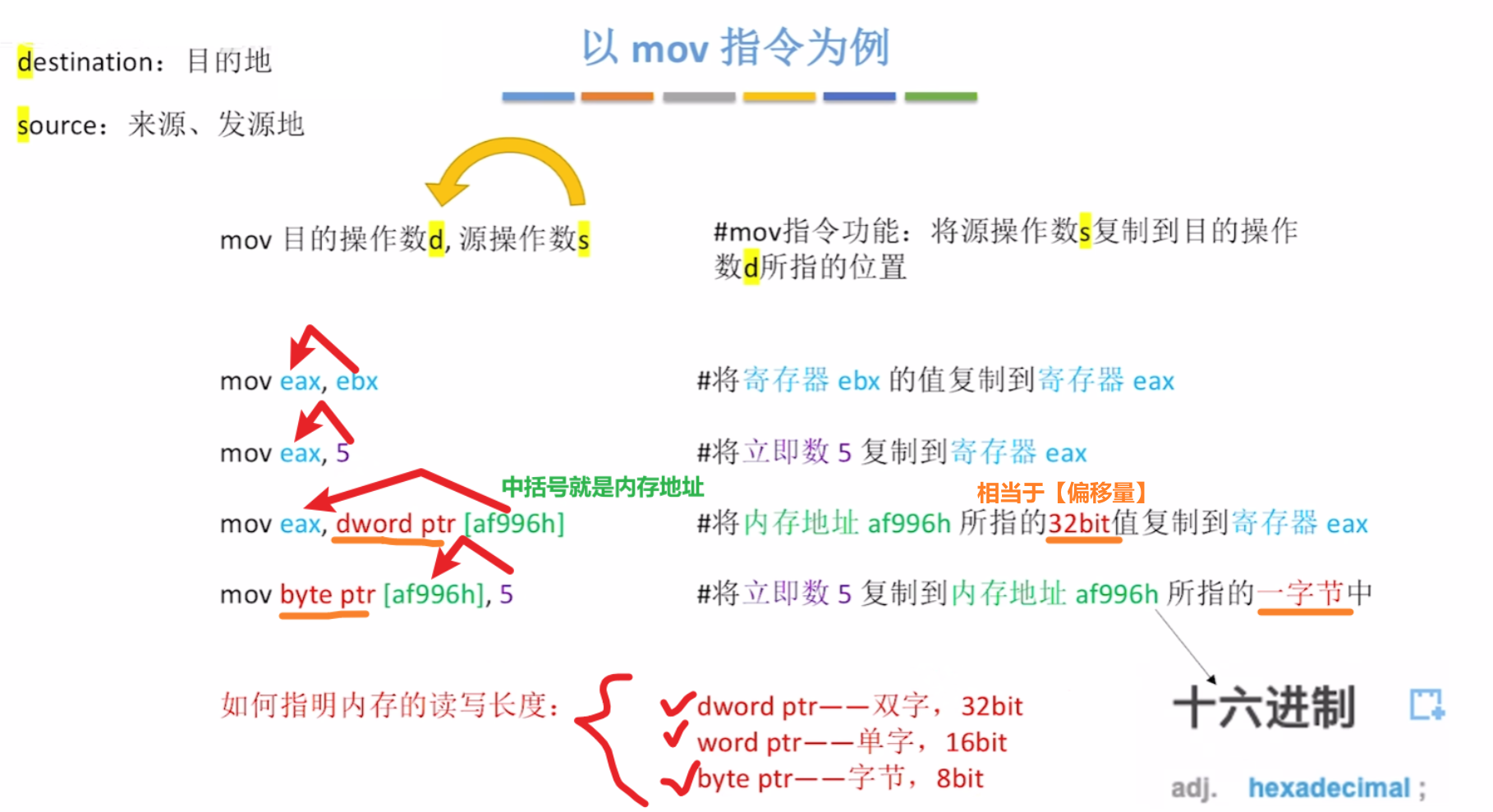
先记住数据转移的格式
【Intel x86格式里】:
- 【,】逗号左边是【d:目的操作数】、逗号右边是【s:来源操作数】
- 其中【d:目的操作数】还往往是【最终结果要存回去的地方】
- 比如:假设X存在EBX寄存器,X=X+1,就是(EBX)+1—>EBX,X+1的结果仍存回X
- 【d , s】意思就是把【右边的内容 复制到 左边】
;
而在【AT&T格式里】:
- 是完全反过来!!!
- 【s , d】意思就是把【左边的内容 复制到 右边】
然后,关于上面三个【数据来源】的普通指令例子:
还要注意的细节:
- 如果前面还有【dword ptr】、【word ptr】、【byte ptr】这3字样,表示【偏移量】
- 在【s:源操作数】前面:表示这个【源操作数的 这个大小 的数据】复制走
- 在【d:目的操作数】前面:表示数据复制到【目的操作数的 这个大小 的位置】
- 【dword ptr】:是双字大小,32bit(ptr是必带的字符,不用管啥意思)
- 【word ptr】:是单字大小,16bit(ptr是必带的字符,不用管啥意思)
- 【byte ptr】:是字节大小,8bit(ptr是必带的字符,不用管啥意思)

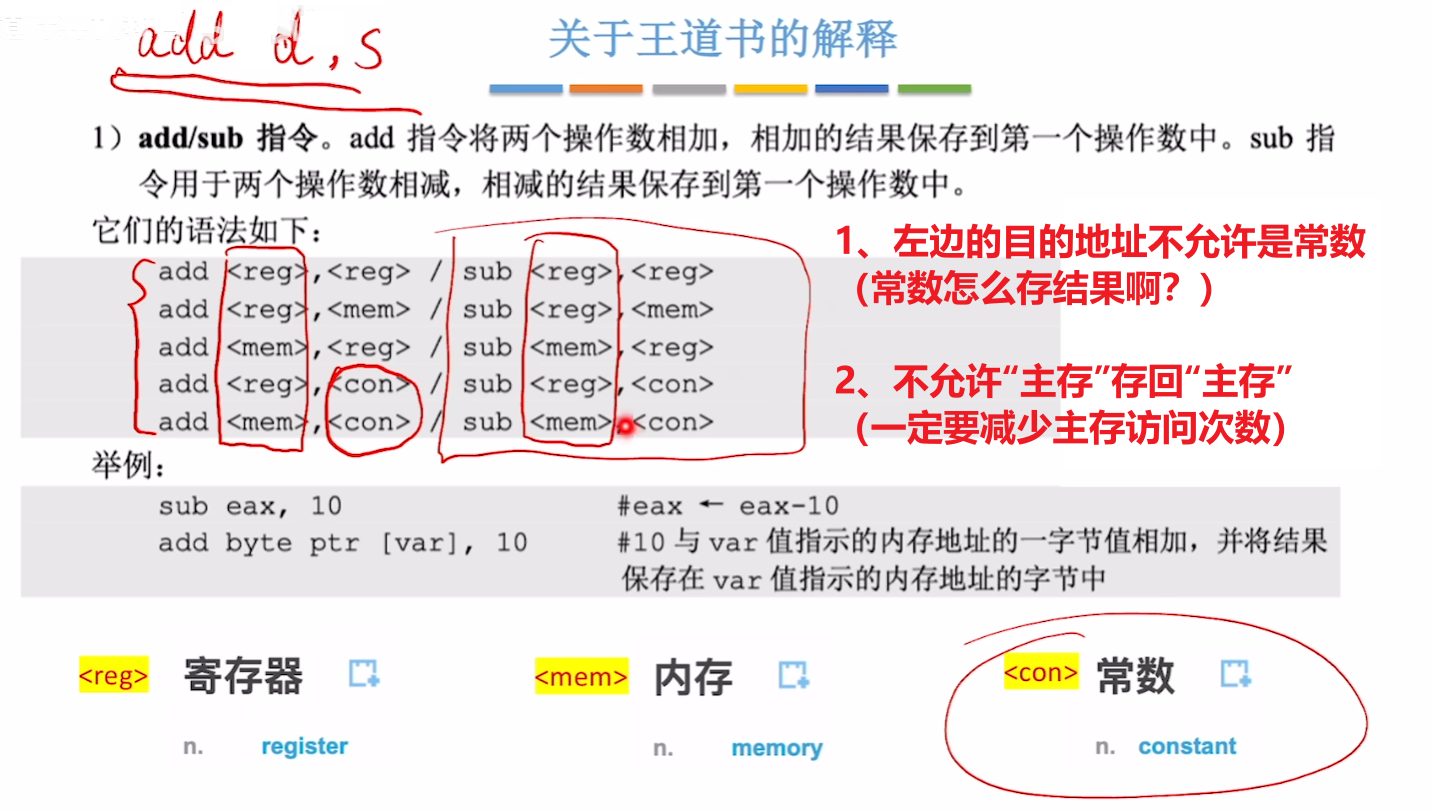
王道书和一些试卷上的另一种写法
还有一种指令写法,会用 < ... > 的写法表示【数据来自哪里】
- < reg >:寄存器(无需管是什么寄存器,具体多大,题目会给出数字)
- 当然,如果非要表明是什么寄存器,也可以把【具体寄存器名字】写进< ... >里
- 比如:< AH >、< CL >、< EBX >、< AX >、< EBP >......
- < mem >:内存(具体多大,题目会给出数字)
- < con >:常数(具体多大,题目会给出数字)
- 另外 / 的意思是【或】
还要注意两点,可以发现:
- 1、【目的地址】不可能是【常数】
- 因为【目的地址】是要用来存结果的,得是个容器
- 2、【逗号左右】绝对不可能都是【主存】
- 因为把【主存数据】存回【主存】要访问2次主存,要尽量减少访问主存的次数,尽量【寄存器 存到 主存】或者【主存 存到 寄存器】


5)总结
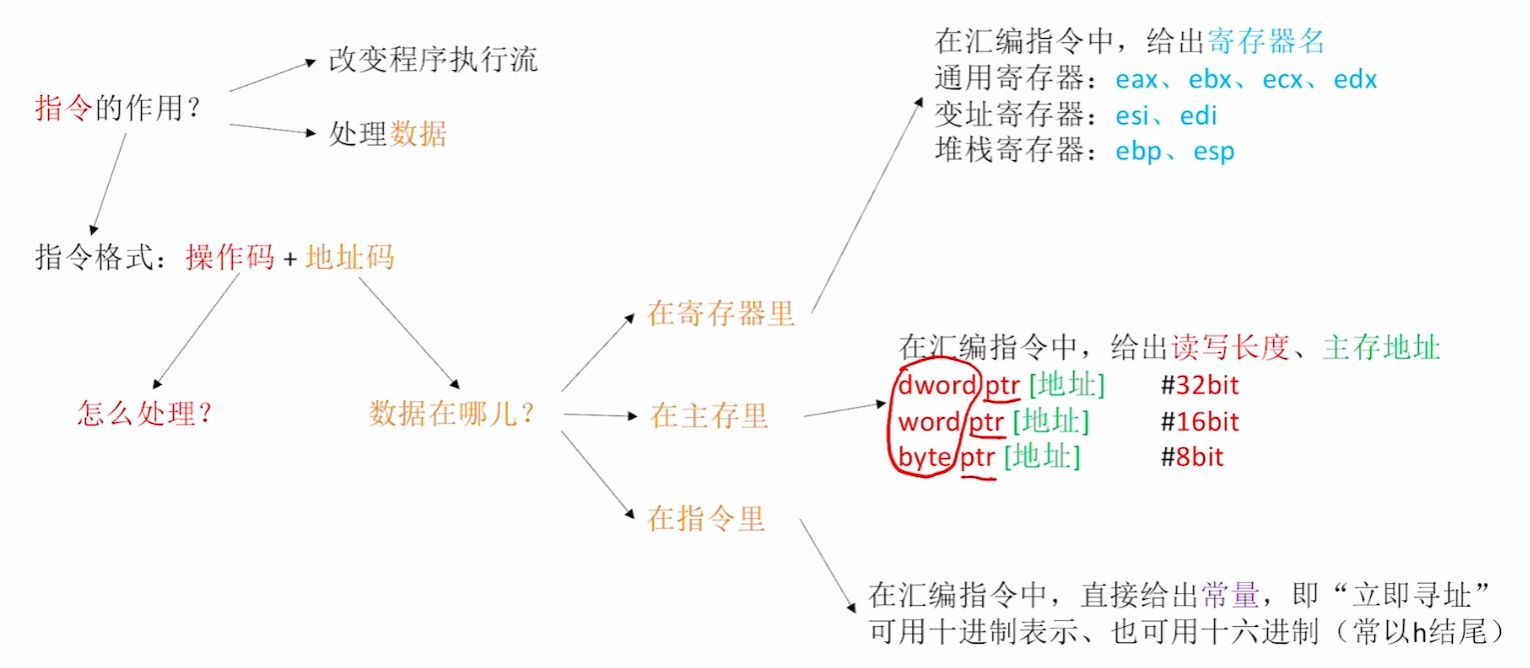
2、操作码怎么处理?
接下来看指令的前半部分【操作码】,要解决的问题是——“怎么处理数据?做什么操作?”
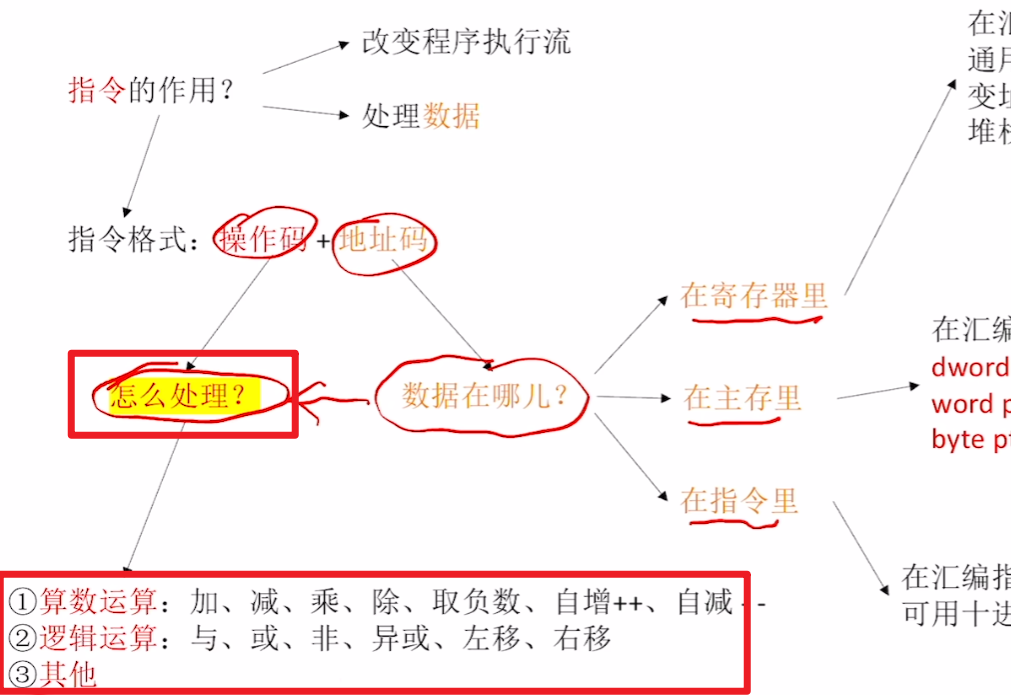
1)算数运算指令
就是背单词就完事了,英语6000单词背完的这些简单词汇肯定会,不会的就回家吧好吗
- 然后留意这几点:
- 乘法指令里的【有符号乘法】
- 如果出现3个数,说明只有【后面两个数】参与计算
- 【第一个数】永远是存结果的寄存器而已
- 除法指令里【有符号、无符号都是】
- 【被除数】不用给出,只会隐含在【eax】和【edx】里
- 【商】放【eax】、【余数】放【edx】
- 所以仅按人类理解的完整写法应该是【eax:edx / s】(“:”表示“和”,这不是标准汇编指令,只是方便大家理解)



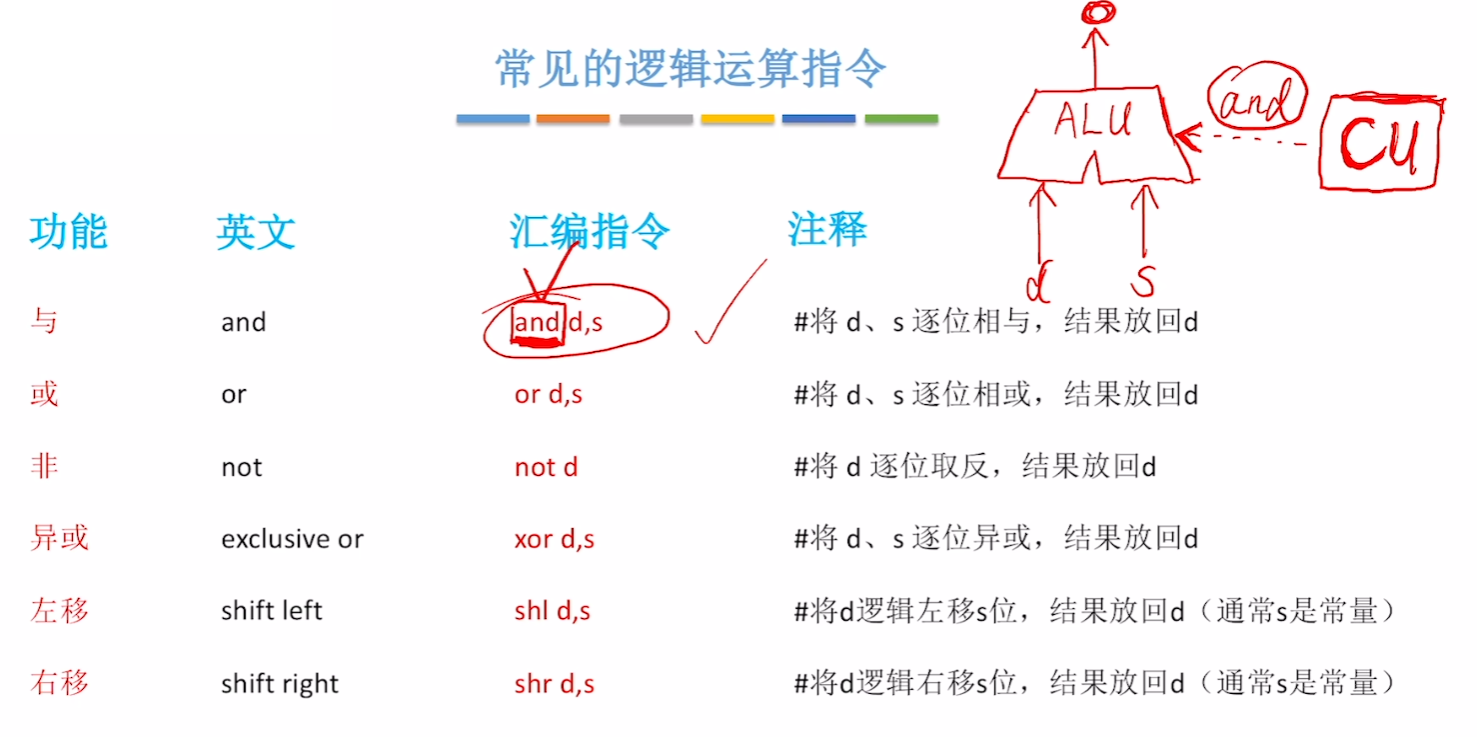
2)逻辑运算指令
依旧小学英语单词,不会的就回家吧
- 另外补充一个

3)其他指令
大体分类如下:

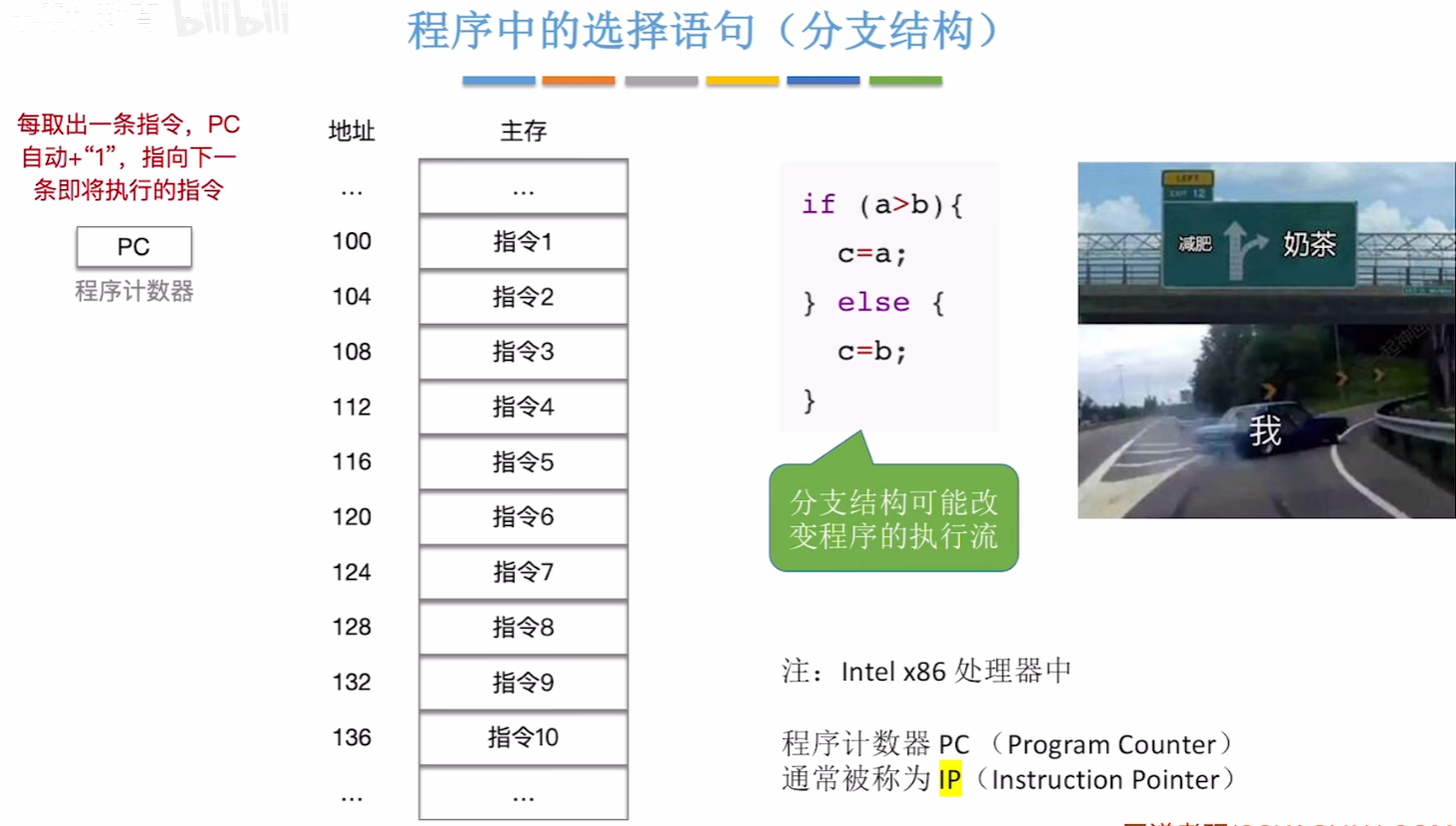
【实现选择分支结构】——【jmp指令(以及搭配指令)】
【选择分支结构】:就是【if-else】语句
(跨考专业不会代码的,自己去学数据结构会学到)
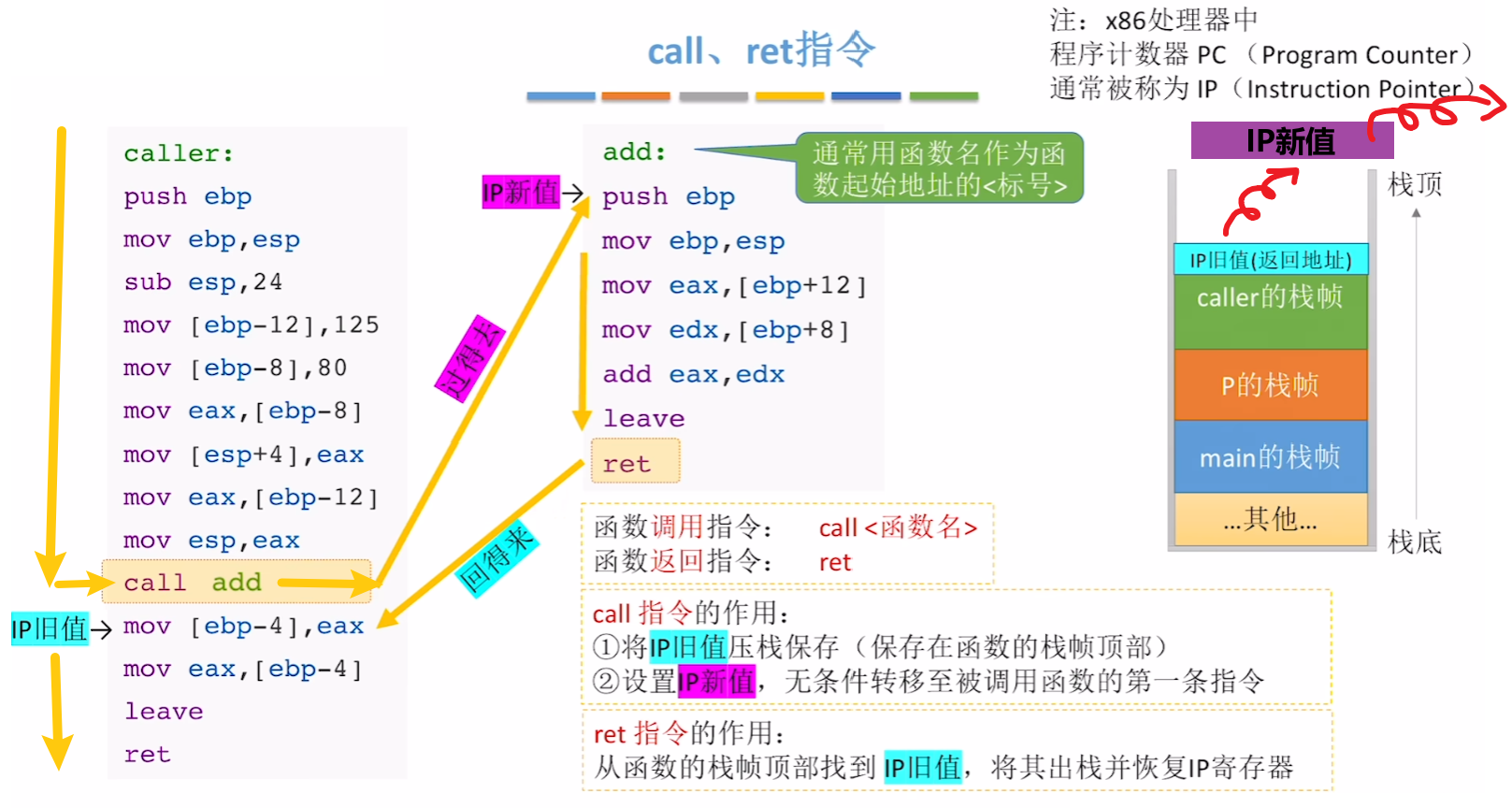
注意!!!:Intel x86计算机里,【PC】通常也被叫做【IP】,【PC】就等于【IP】!
;
;
那么对应最典型的指令就是:【jmp】指令
- 他会改变正常的【PC = PC + “1”】的指令默认步数,而跳到任意一个指定的【指令的位置】
- 写法是:【jmp 地址】
- 可以写指令的常数地址(指令在主存的位置)、寄存器名字(寄存器里是指令在主存的位置)、主存地址(主存里存着指令在主存的位置,套娃)
- 另外如果标记【NEXT】,则一定能指定跳到【你想要执行的那条指令】,不管这条指令的具体位置变到哪里(类似C语言的【goto】语句)
- (当然起始也不局限于【NEXT】这个单词,它只是一个【自定义标记符】,你也可以写【jmp fuck】、【jmp ass】、【jmp stupid】......随便你怎么想,只要能找到对应这个【标记】的指令位置就行)
- 【jxxx】指令
- 还没结束!!!那不管是【jmp 地址】还是【jmp NEXT】,都是指定跳到某个【指令】,这不就没法实现【if-else判断语句】了?
- 所以还有这么一堆恶心的指令,用来具体进行【条件判断】的,理解一下就行,有能力的最强大脑可以背熟
记忆方法
- 还有!!!!
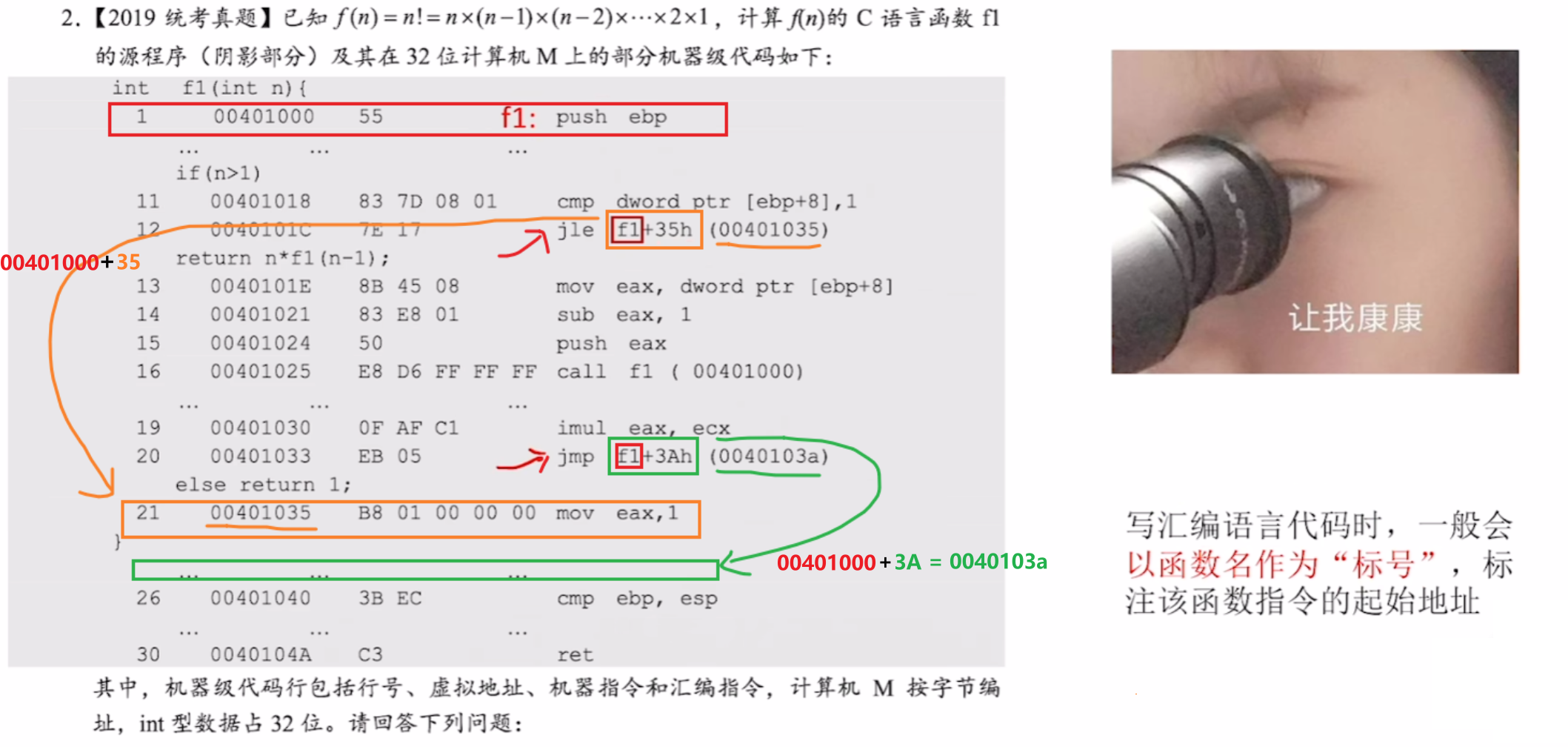
- 有的时候jmp跳转指令还会以【函数名】作为【指令跳转的偏移计算】的【起始位置】
- 比如下面例子:函数名叫做【f1】,它里面的【第一个指令】就是这个函数的起始位置;然后后面【jmp指令的地址】就可以写成【f1 + 地址】
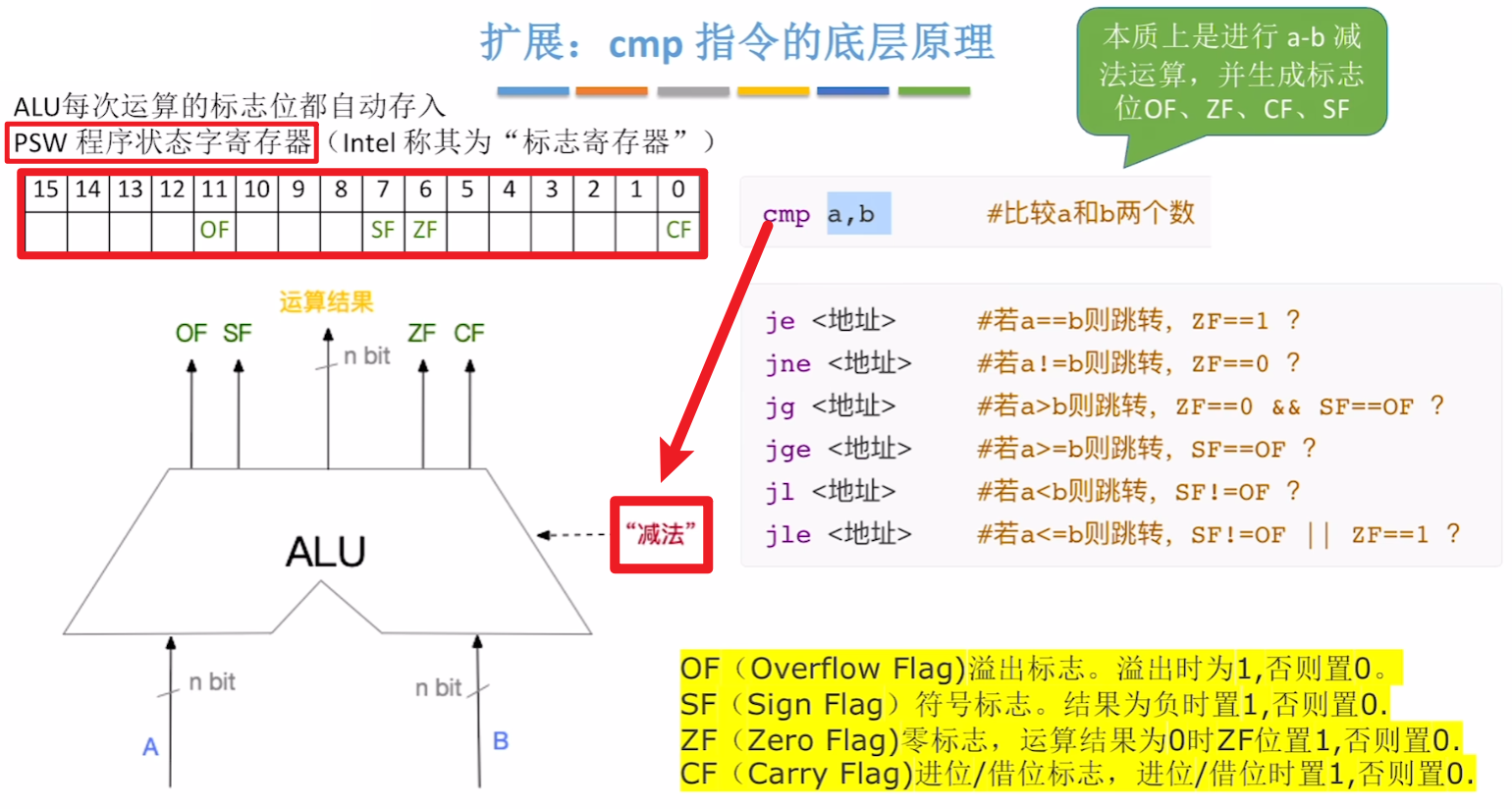
- 还他妈有【cmp】指令!!!(作为扩展吧,爱学学,不爱学跳过)
- 【cmp】对比指令的底层原理是【ALU】对两个数作【减法】



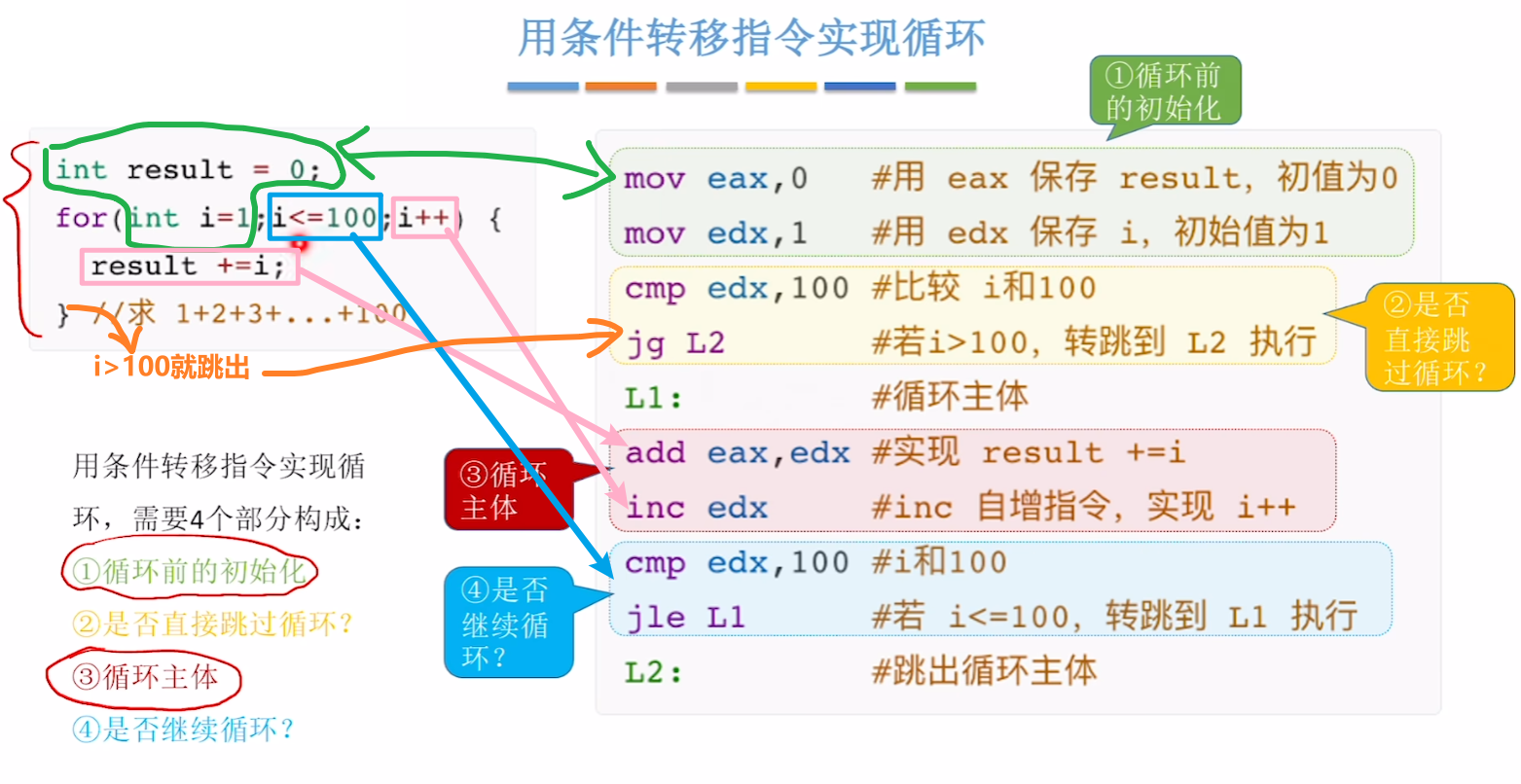
【实现循环结构】
第一种是:【条件转移指令】
- 通过纯粹的【jxxx 跳转指令】来实现循环
- 快速理解方法就是记住3点:
- 1、先判断是否【不满足循环条件】,若不满足,则【跳到最下面(循环体之外)】
- (满足的话,PC寄存器正常往下一步一步走)
- 2、然后进入循环体,执行各个指令
- 3、执行完循环体内容,再判断是否【满足循环条件】,若满足,则【跳回上面(循环体开始)】
- (不满足的话,PC寄存器正常往下一步一步走)
第二种是:【loop循环指令】
- 快速理解方法就是记住3点:
- 1、循环体开头自定义一个【标记】,比如 “Looptop”
- 2、中间循环指令
- 3、结尾的【loop 标记】隐含意思就是【ecx寄存器--、jxxx指令判断是否满足跳转条件】
- 满足则跳回【标记】处;不满足则【IP】正常往下走
- 那么注意一个重点,【loop】只会自动减【ecx寄存器】的值
- 【ecx寄存器】是一个循环计数器,只有它有资格搭配【loop】!!!!

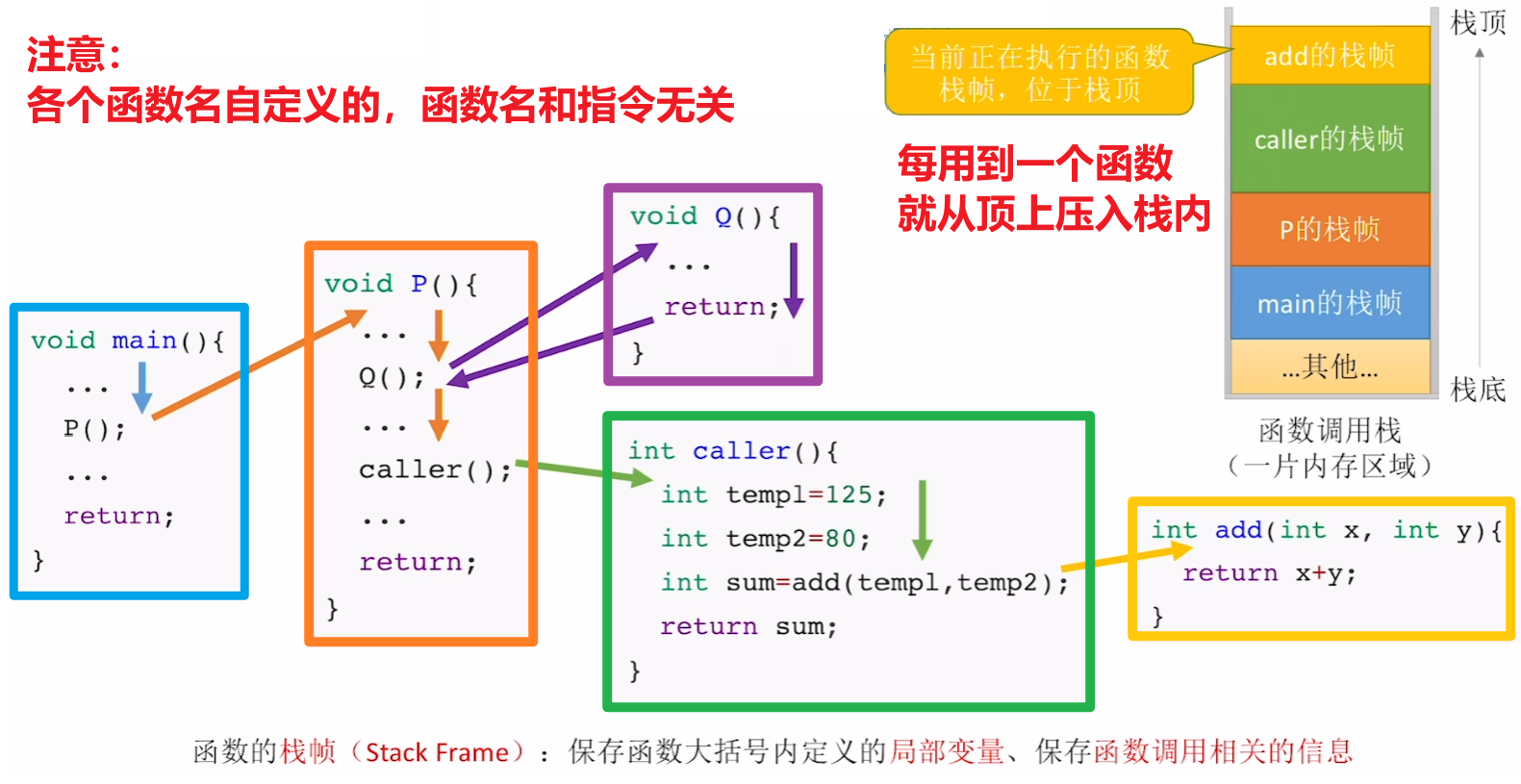
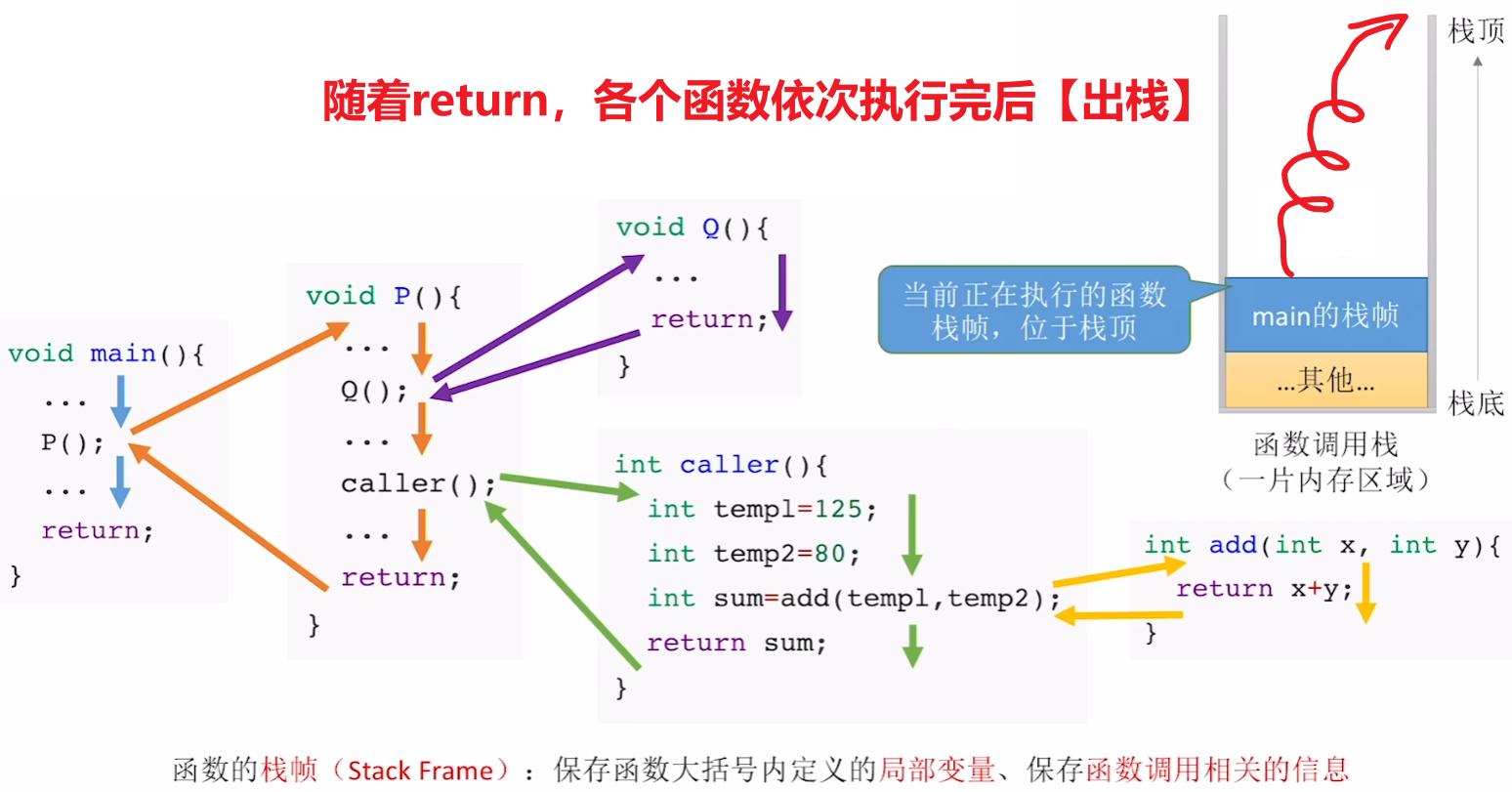
【实现函数调用】
首先理解【整个函数】视角的:调用、执行、执行完毕return的流程
- 就是数据结构的栈,我不想解释,没学过的自己学
;
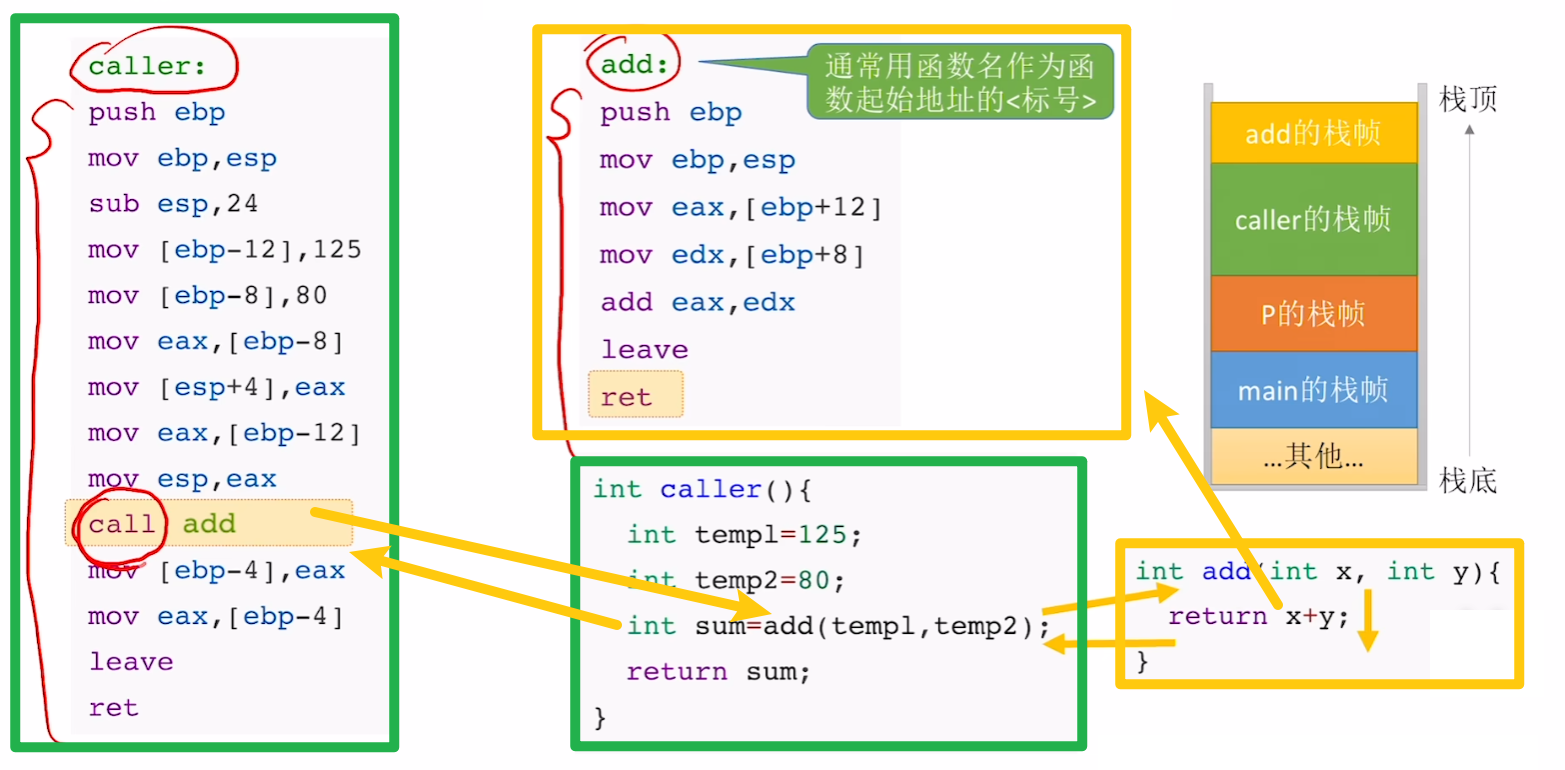
然后到函数调用的指令:【call】、【ret】
- 【call】是【函数调用】
- 【ret】是【函数结束返回】
- 然后按照【函数视角】来看这两个指令(注意,例子里的caller、add只是函数自定义的名字,跟任何指令本身没有任何一丁点没半毛钱关系)
- 所以得出重点:
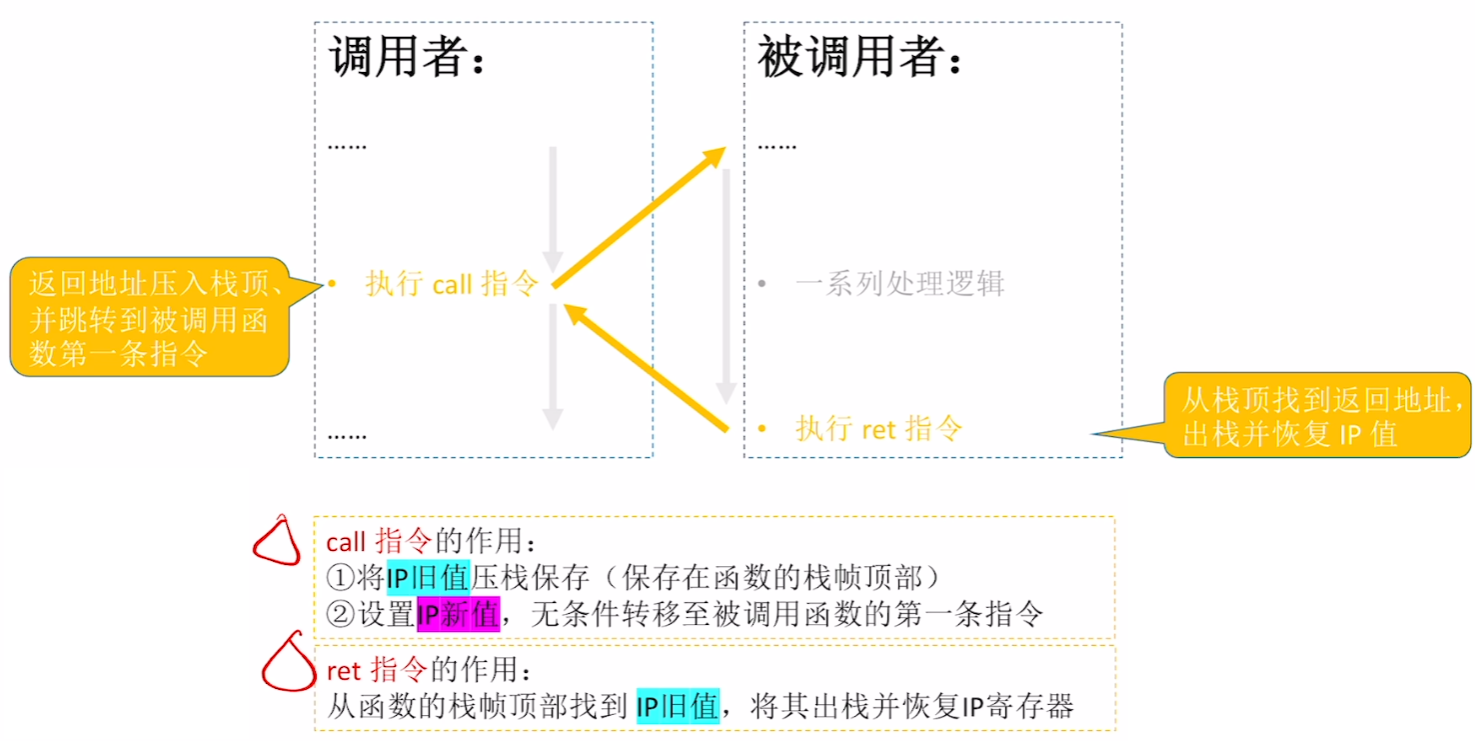
- 【call指令】作用:将【旧IP】压栈保存;将设置【新IP】,用【jmp无条件跳转】到被调用函数的开始
- 【ret指令】作用:被调用函数执行完【新IP】出栈,然后找到【旧IP】,恢复【IP寄存器】值
【数据传送指令】(访问栈帧内数据的指令)
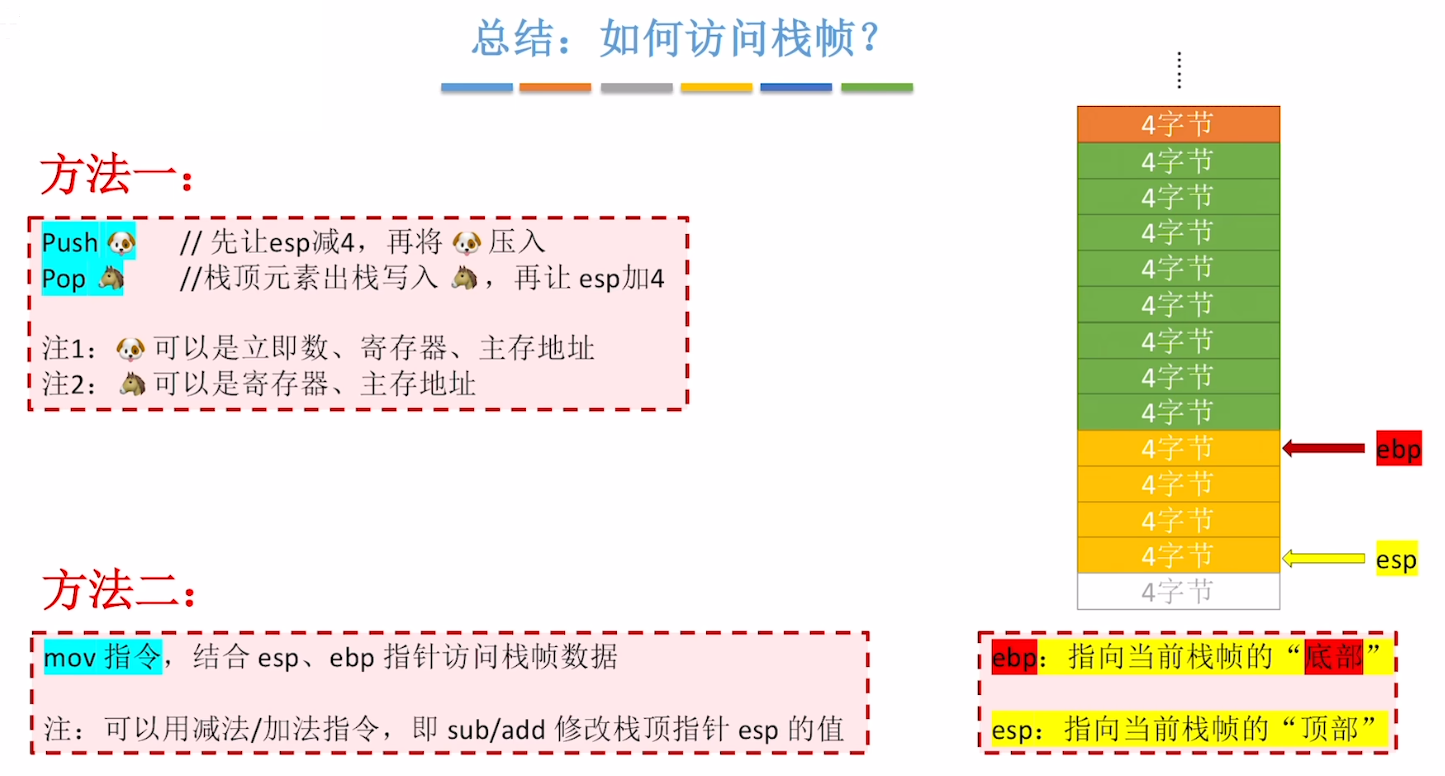
【push、pop指令】
前面我们知道了函数调用的本质就是【函数堆栈】的【IP栈帧的入栈】、【IP栈帧出栈】
可是【call】、【ret】指令只负责设置【新IP值】、找回【旧IP值】,具体是怎么访问数据的?
;
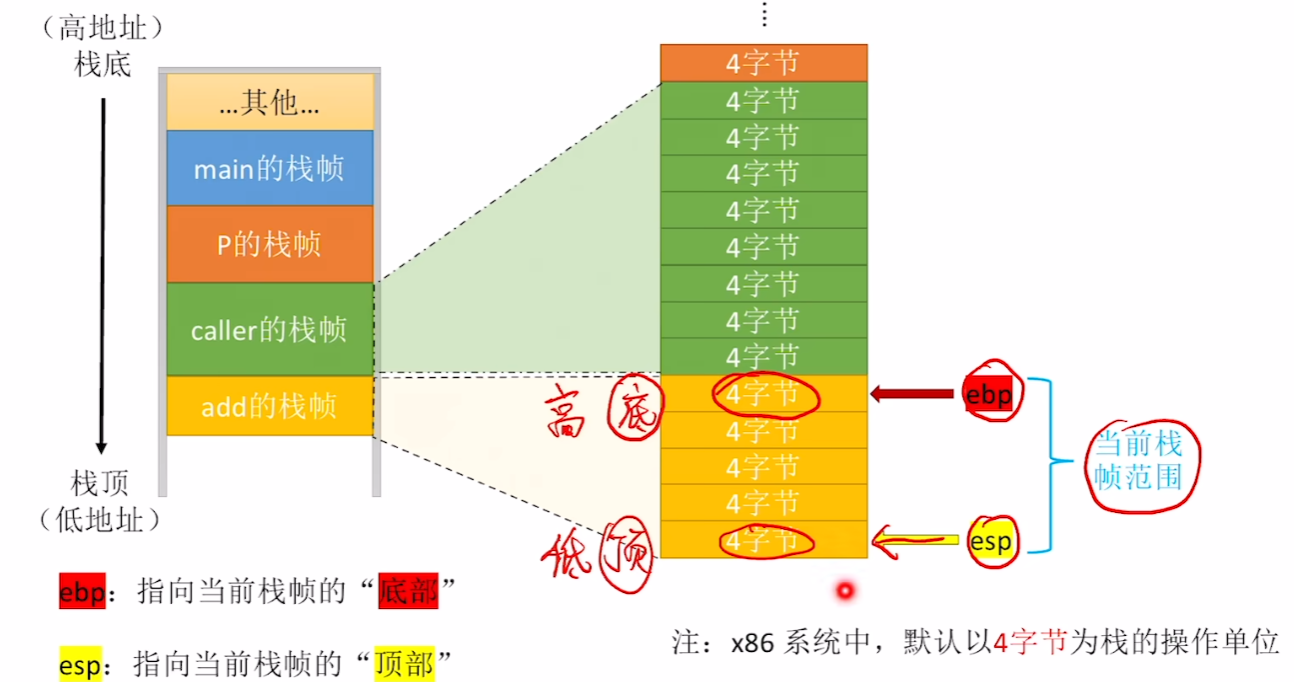
第一步:
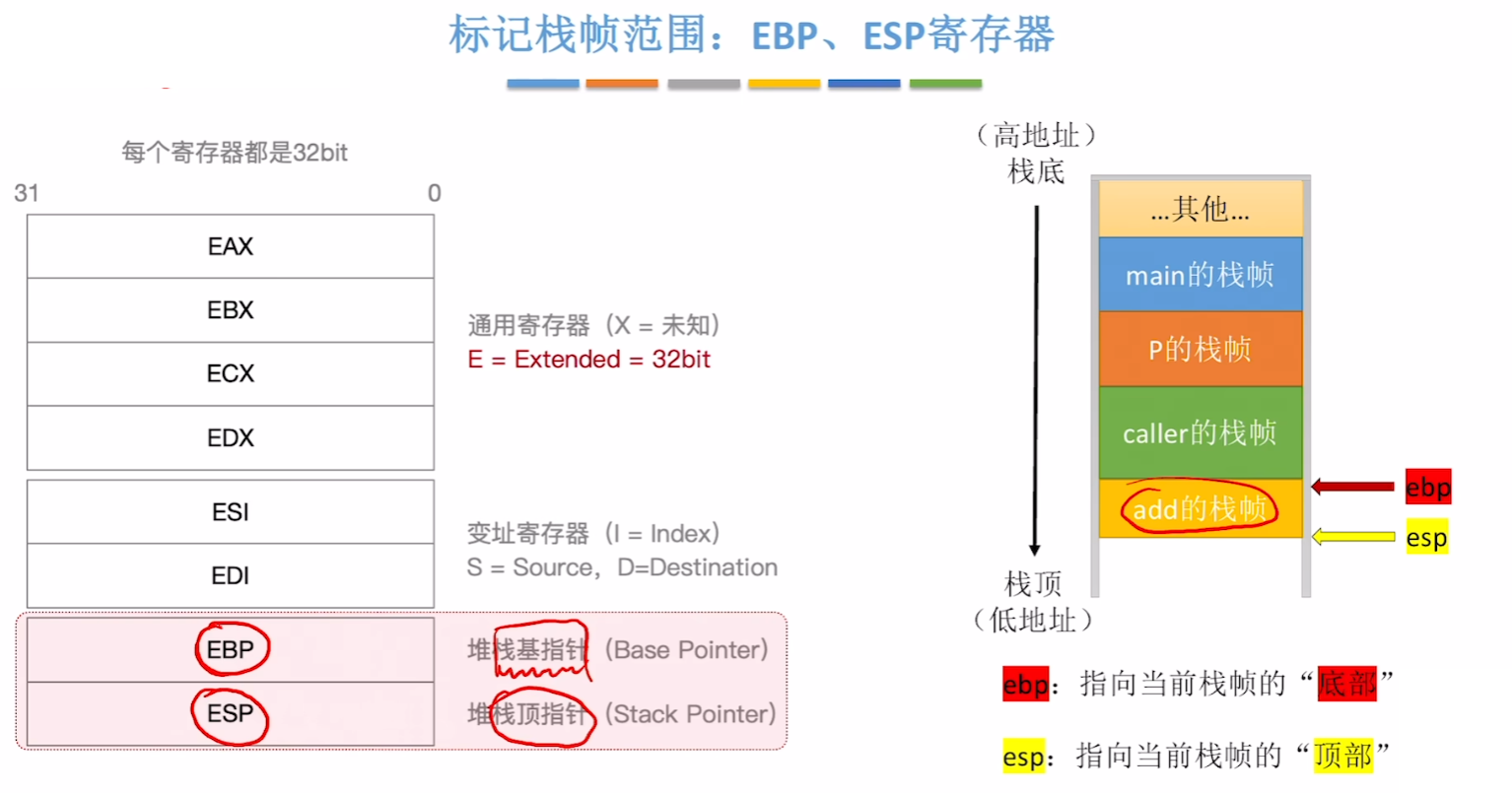
- 首先一个函数段代码需要【2个栈指针】来标记,本质就是【2个寄存器】
- 【EBP】专用于作为【堆栈基指针】,指向一个函数【栈底】
- 谐音记忆:BP就是扁平,栈底被压扁平了
- 【ESP】专用于作为【堆栈顶指针】,指向一个函数【栈顶】
- 谐音记忆:SP就是上坡,栈顶就像上坡一样
- (注意,数据结构的栈是自下往上的,但是实际栈的地址高位是从上往下的,所以下面的栈都画成倒过来的)
第二步:
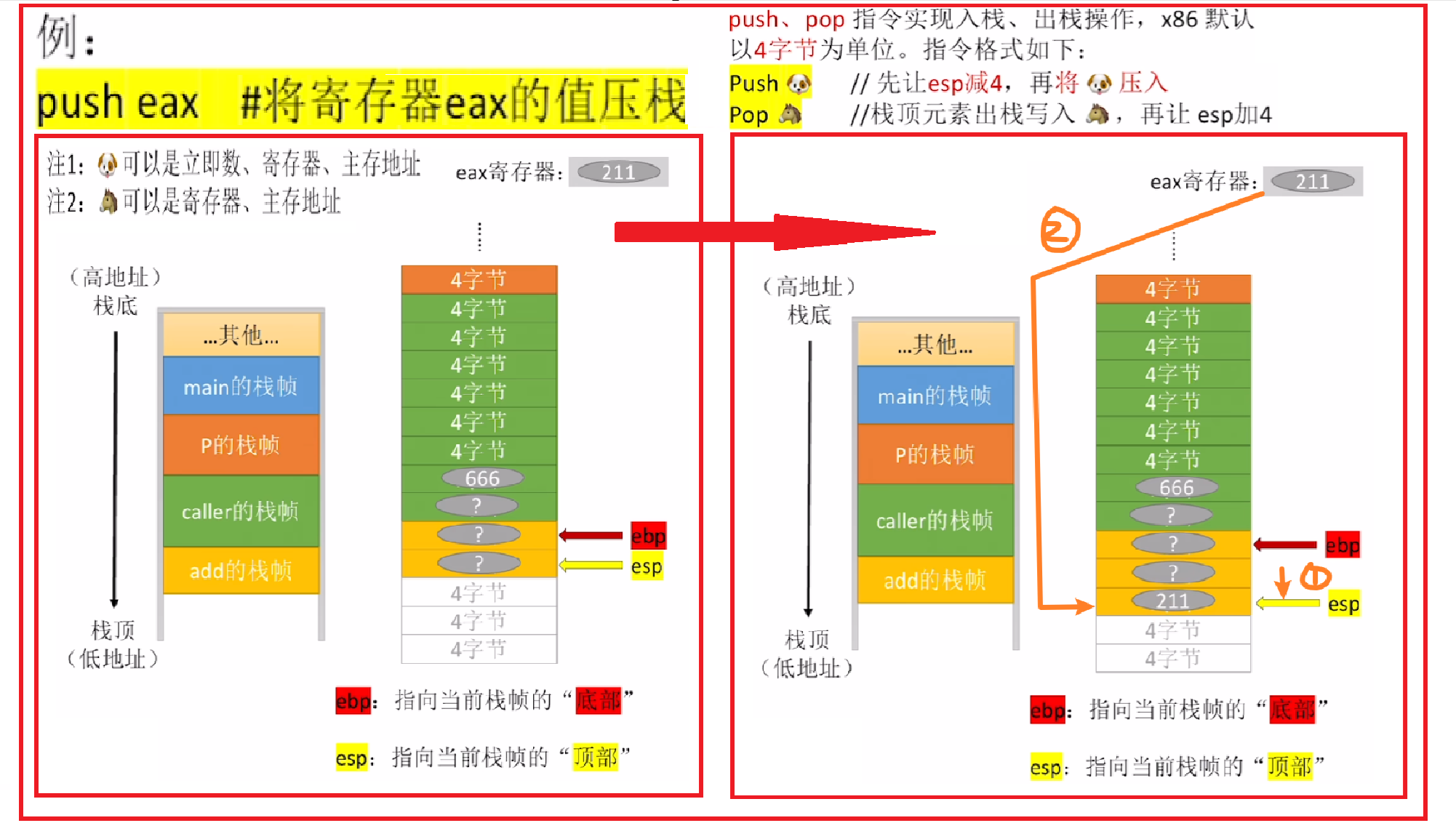
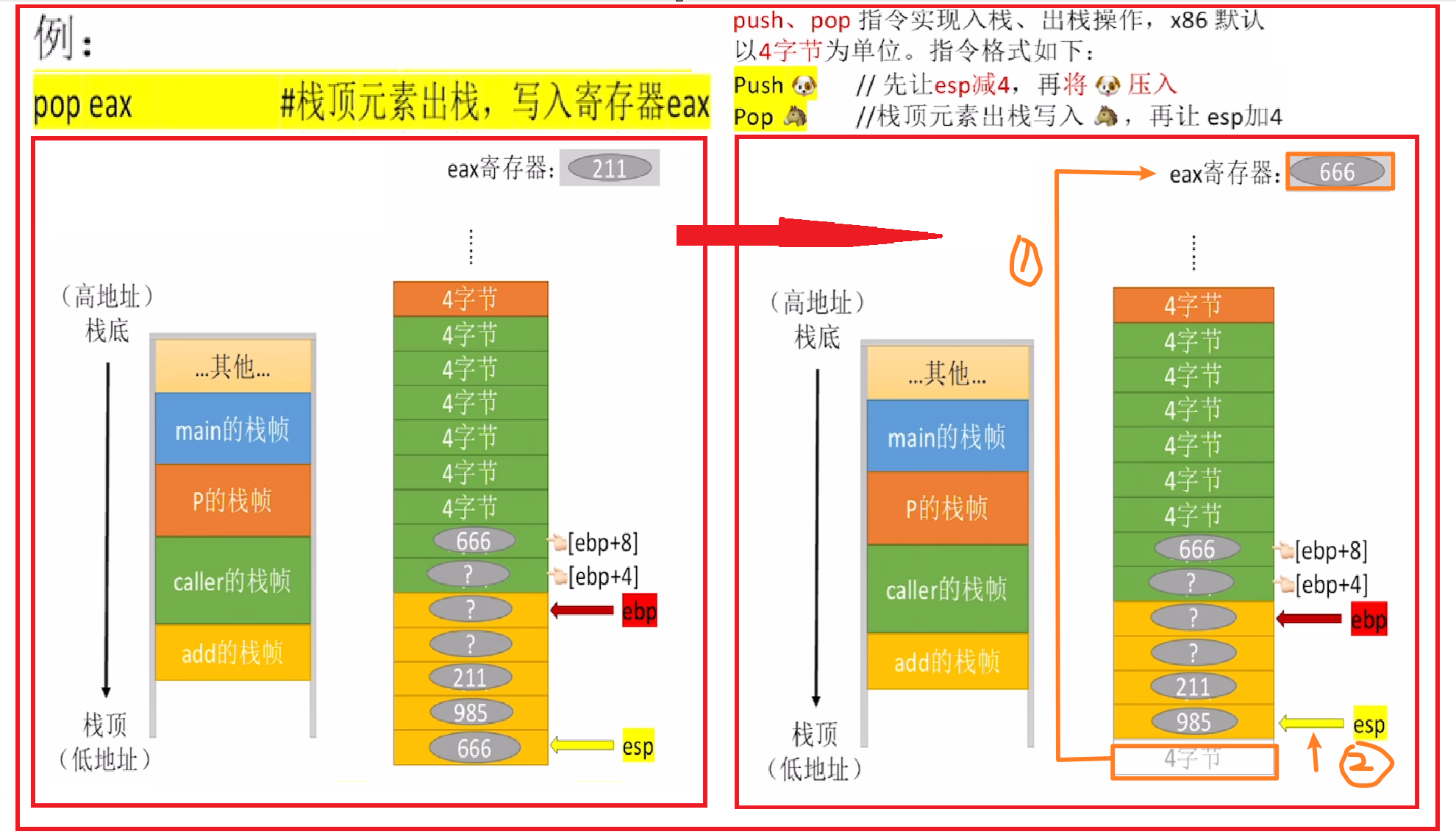
- 【push 数据】:顾名思义,把数据压入栈顶(数据可以是立即数、主存地址、寄存器)
- 【pop 数据】:顾名思义,把数据压入栈顶(数据可以是主存地址、寄存器)
- 然后重点流程就是:
- 不管【push】还是【pop】,都只能操作栈顶,而不是跳过栈顶操作栈内
- 也就是说只移动【ESP】(堆栈基指针)
- 【push】是先移动【ESP】指针,也就是【ESP】往栈顶移动,再进行入栈
- 对应【ESP地址 “减”】
- 【pop】则是先出栈,再移动【ESP】指针,也就是【ESP】往栈里面移动
- 对应【ESP地址 “加”】
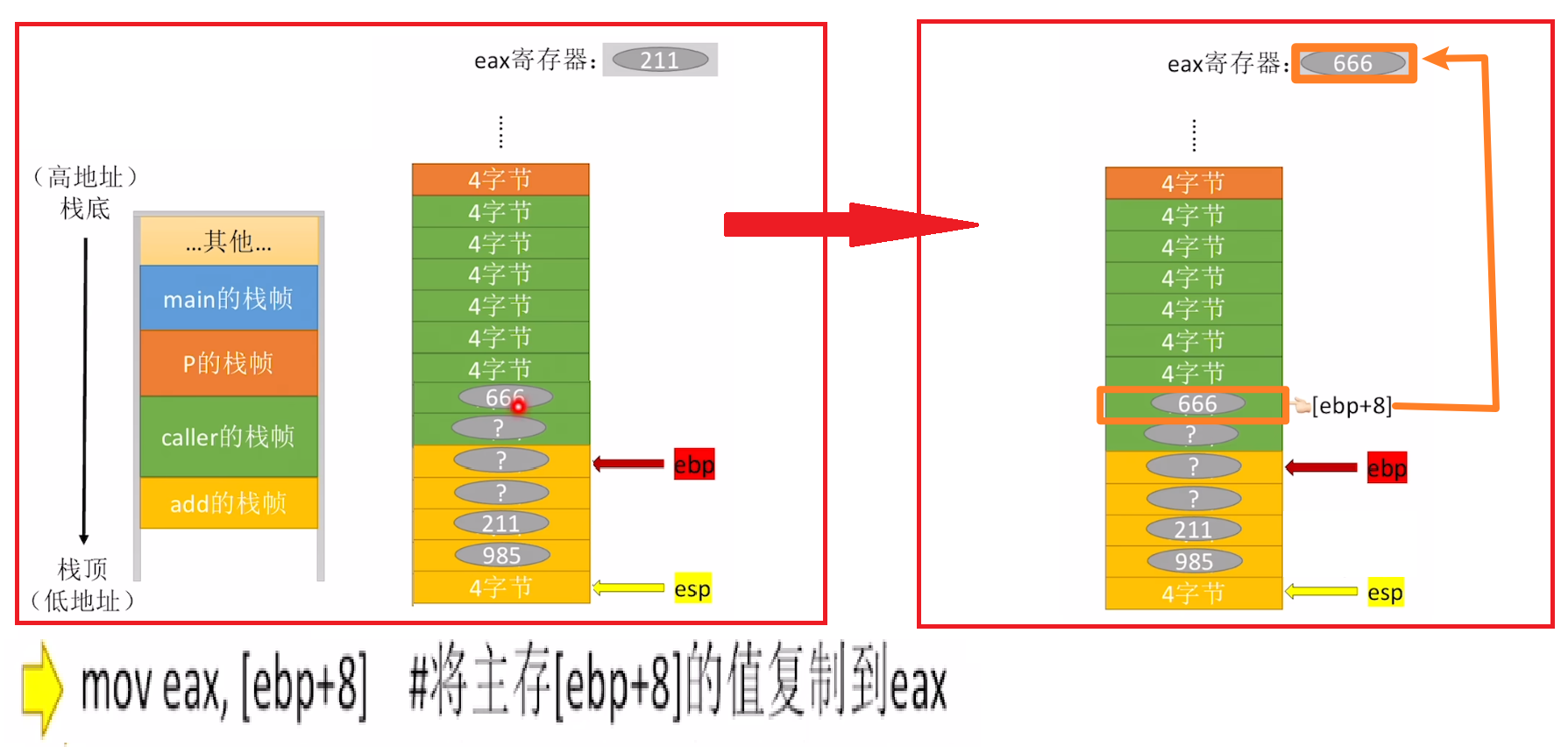
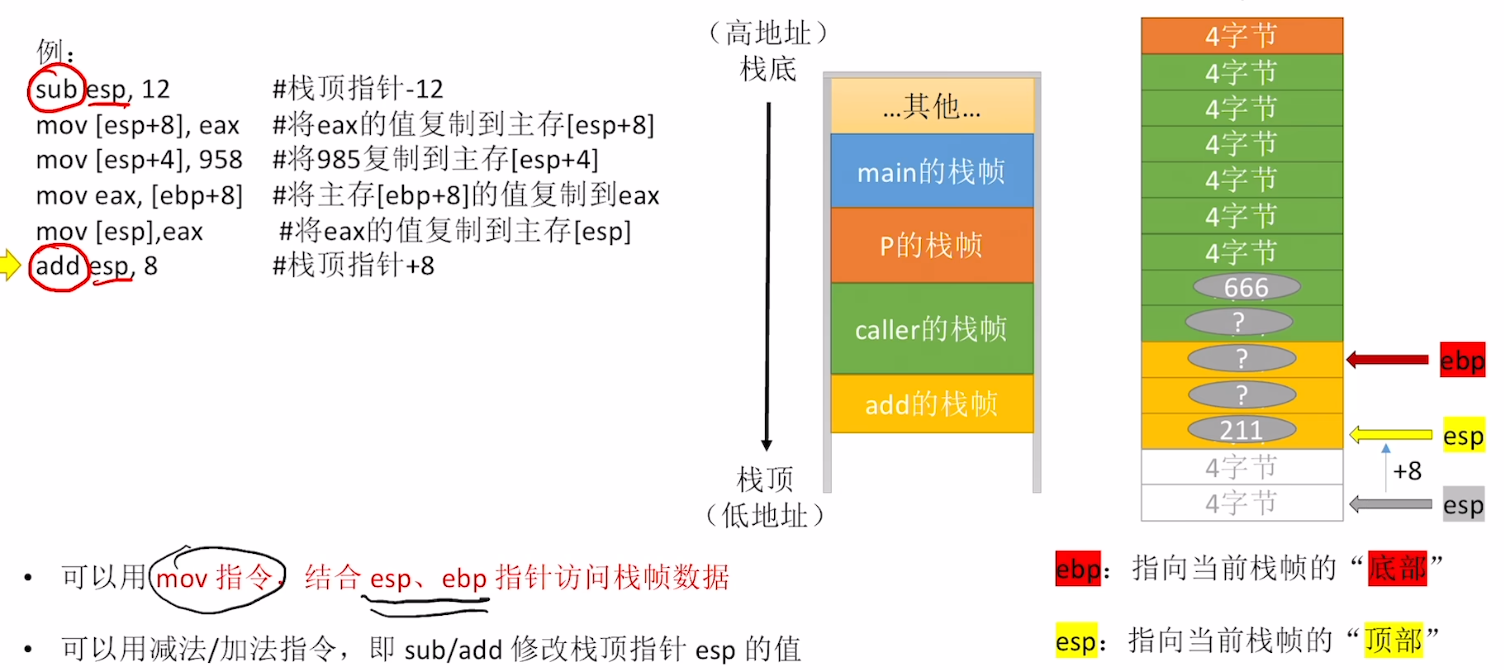
【mov指令】
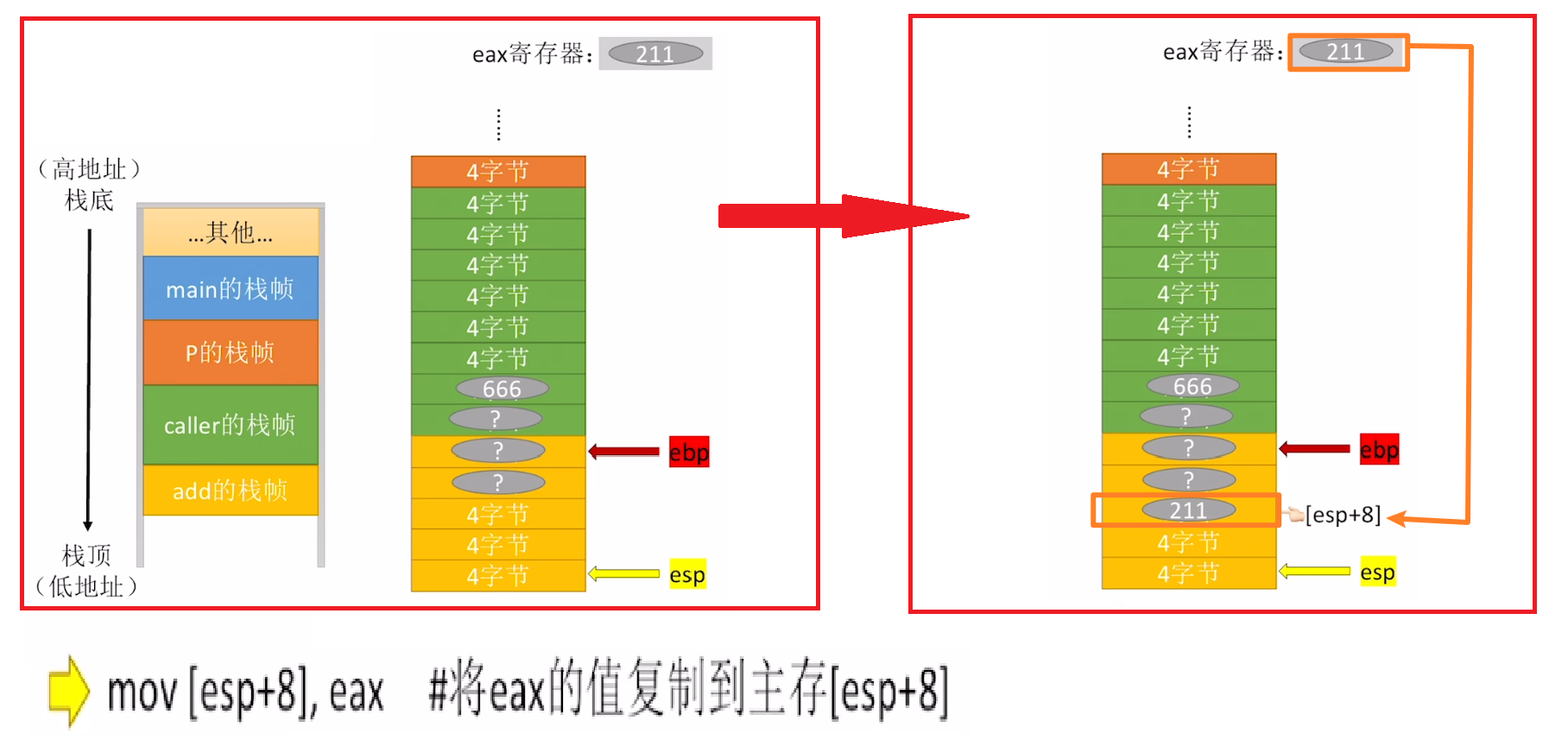
【mov指令】则是简单的【复制】了
- 【mov指令】可以结合【esp】、【ebp】两个指针来访问数据
重点就是:
- 不管是【“复制” 进来】还是【“复制” 出去】,2个指针【esp】、【ebp】都不动!!!
- 只是根据【它两的偏移量】来访问主存堆栈内的数据(“复制” 数据只可能更改,但不会消失、增加)
- 通常要 “复制” 的数据,往栈顶看,哪个指针离他近,就以哪个指针作为【偏移量导航基准】
- 比如下面这个主存地址,往栈顶看,就【esp】离得近,就写成【esp + 8】
- 比如下面这个主存地址,往栈顶看,就【ebp】离得近,就写成【ebp + 8】
拓展:
add/sub 指令也会改动【esp】【ebp】指针位置,知道即可

【总结】
3、【AT&T格式】和【Intel格式】对比
为了以防考到【AT&T格式】,还是简单看一下,其实也没差多少
