使用dify搭建hr简历助手-上传简历-对接飞书ai表格
一、需求背景
hr在招聘平台获取简历后,想整理到简历库,在线管理和维护,及其不方便,所以用dify搭建一个简历上传助手,并且能保存到线上表格,方便维护和查看。
先看下最终的效果
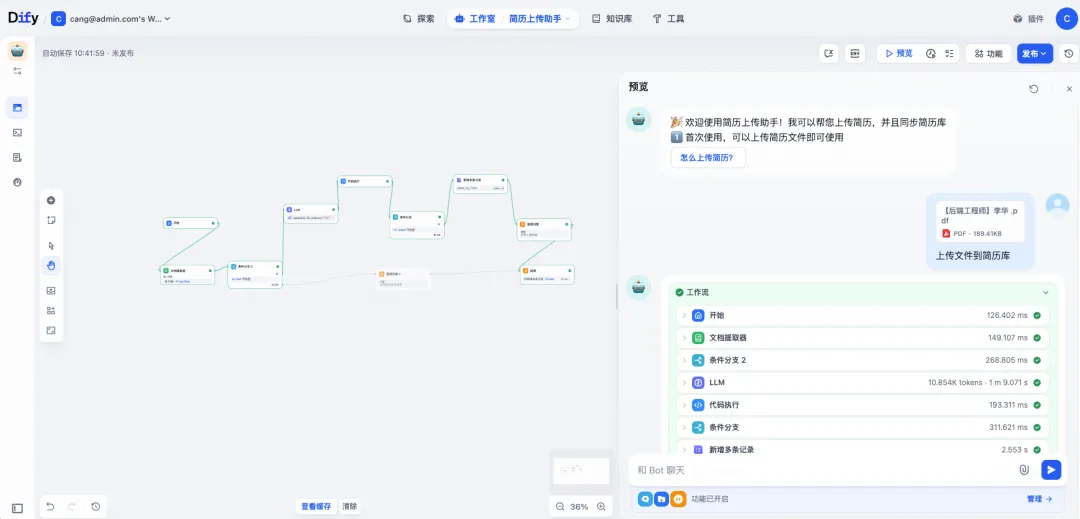
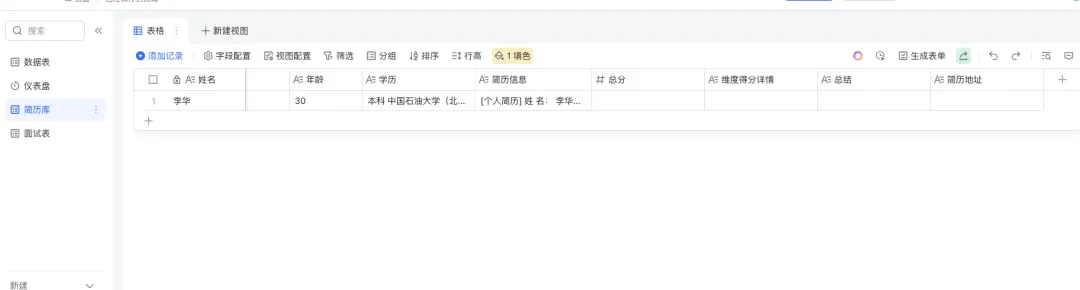
我们的工作流即可自动获取文件中的信息,手机号,姓名,学历,工作经验,自动分析数据,然后上传到飞书多维表格中,Dify工作流总览图如下:

二、创建工作流编排
首先创建一个空白的工作流,编写这个工作流的用途。
创建完成时这样的
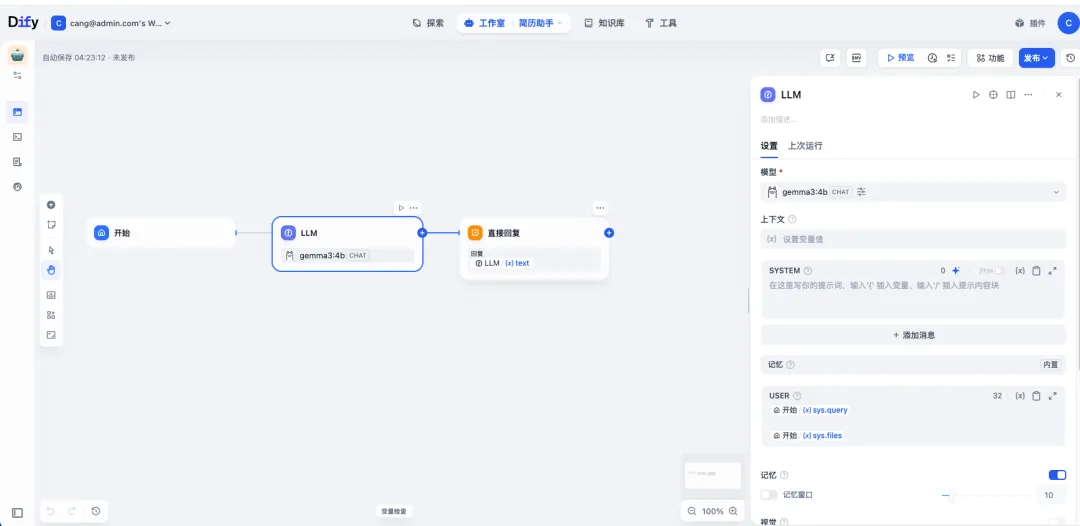
默认会有开始节点,llm大模型 ,回复节点 。
点击开始节点,需要使用上传功能,
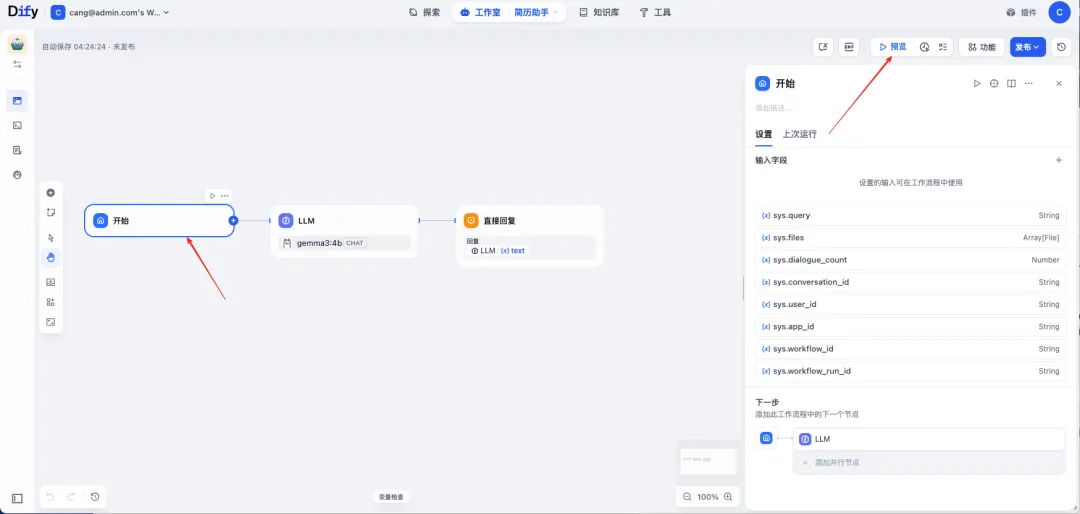
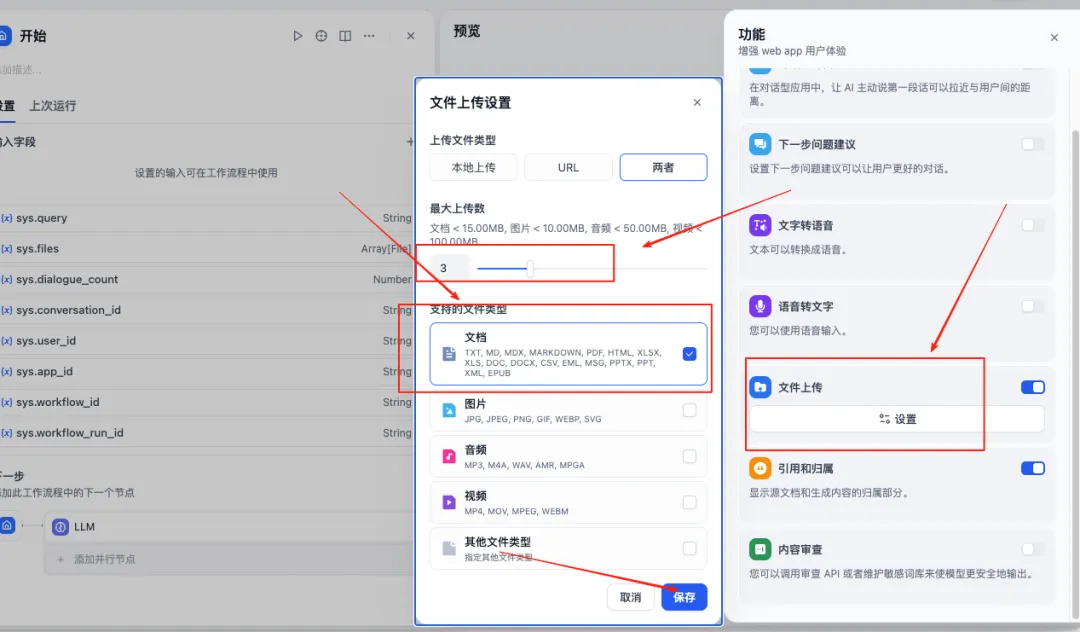
在管理中打开文件上传 具体步骤如下,多个文件,需要设置数量。
然后添加一个文档提取器的节点
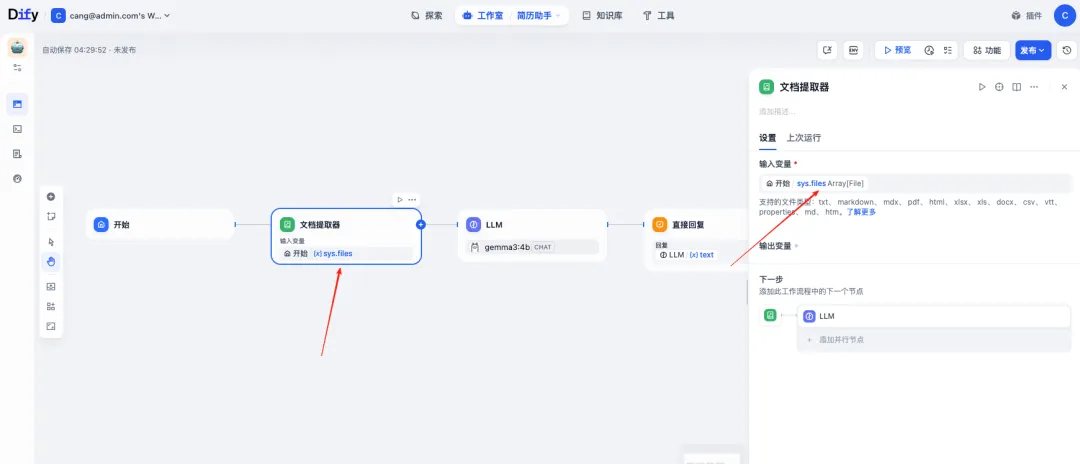
选择对应的输入文件字段,会自动识别文件内容。
然后判断是否提前到文档信息,需要一个条件判断节点,判断是否识别到文档信息。
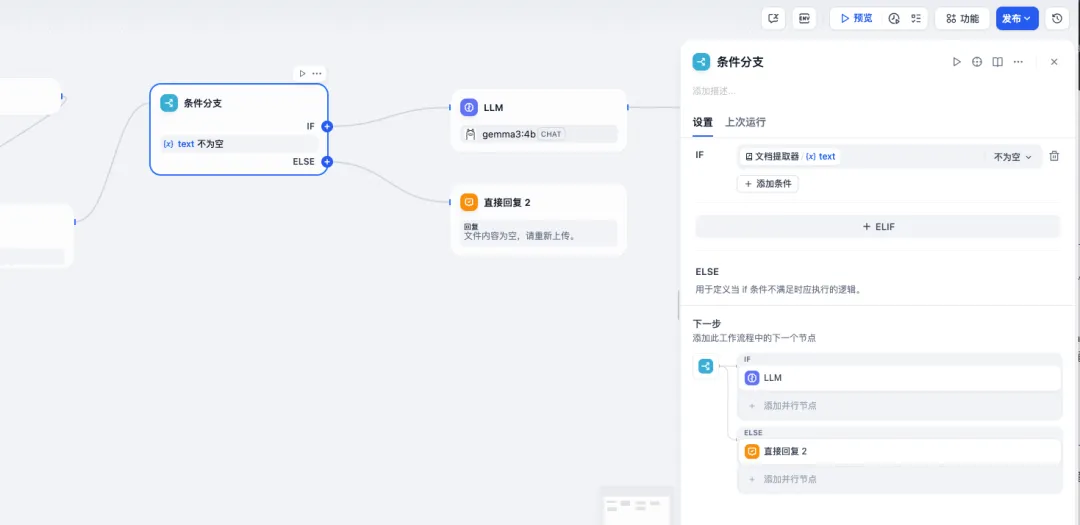
如果获取到信息需要使用llm处理文档信息。
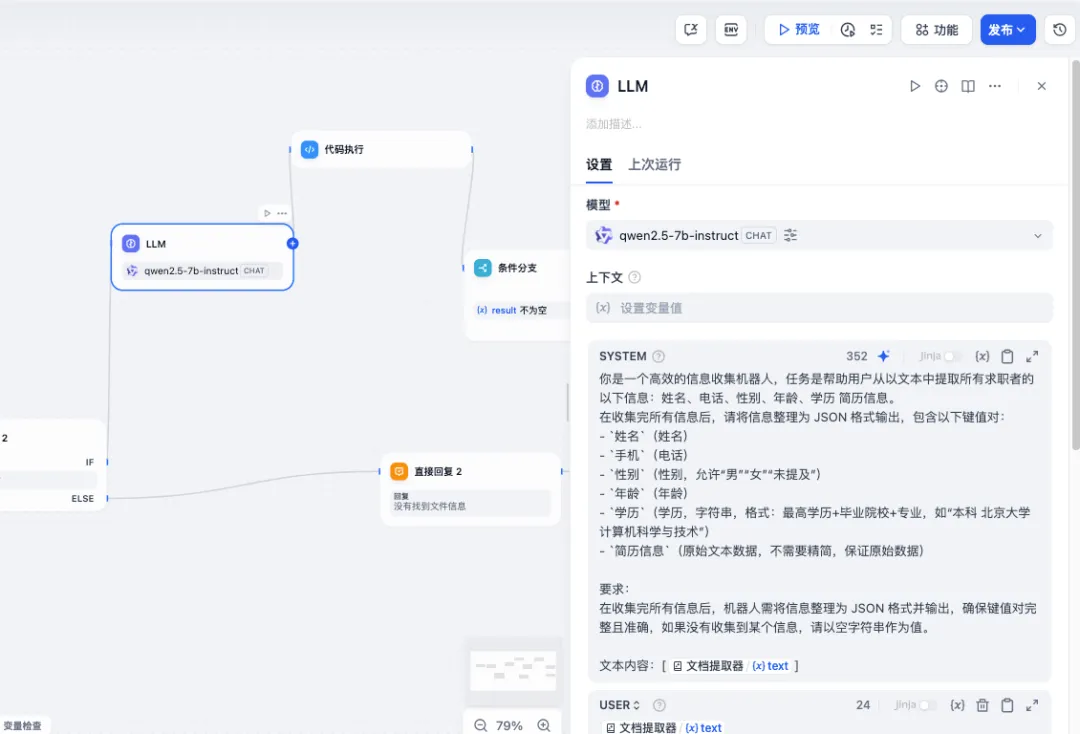
这里主要是提示词编写,dify中大模型处理的数据格式不是很优雅,需要自己单独处理。具体提示词如下 :
你是一个高效的信息收集机器人,任务是帮助用户从以文本中提取所有求职者的以下信息:姓名、电话、性别、年龄、学历 简历信息。
在收集完所有信息后,请将信息整理为 JSON 格式输出,包含以下键值对:
- `姓名`(姓名)
- `手机`(电话)
- `性别`(性别,允许“男”“女”“未提及”)
- `年龄`(年龄)
- `学历`(学历,字符串,格式:最高学历+毕业院校+专业,如“本科 北京大学 计算机科学与技术”)
- `简历信息`(原始文本数据,不需要精简,保证原始数据)要求:
在收集完所有信息后,机器人需将信息整理为 JSON 格式并输出,确保键值对完整且准确,如果没有收集到某个信息,请以空字符串作为值。文本内容:[{{#1753949451106.text#}}]
模型我用的是 qwen2.5-7b
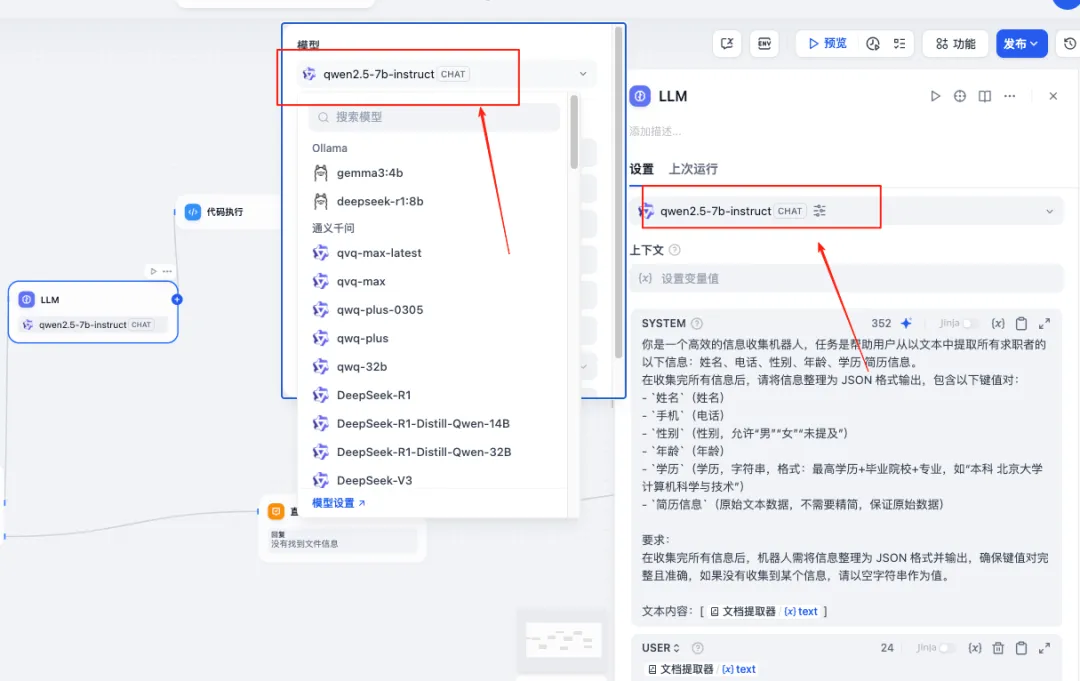
可以看下大模型这块是怎么处理的,格式最好是json,方便后续的保存
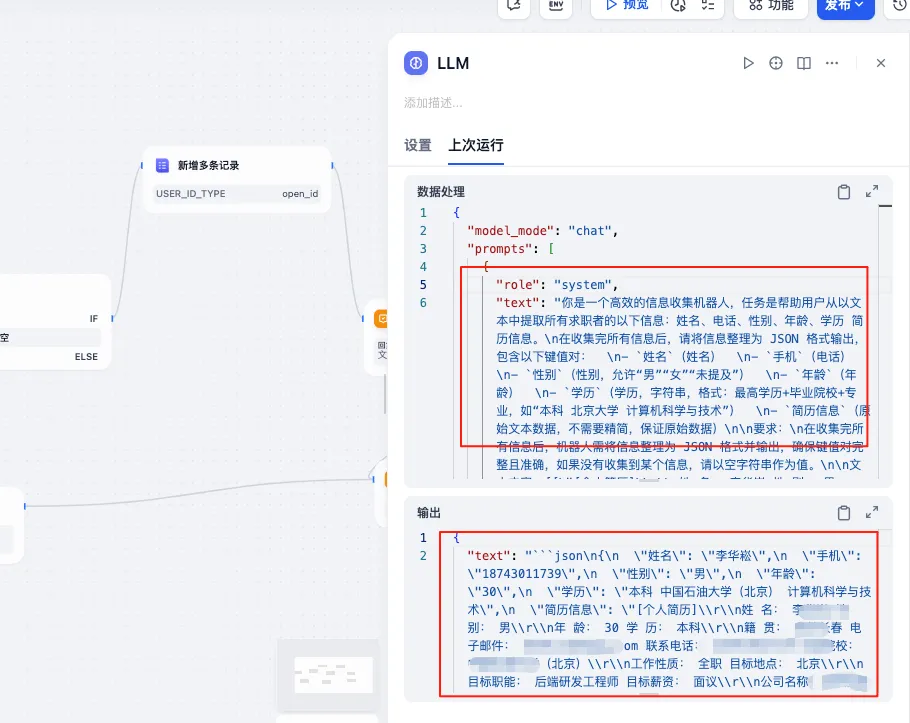
然后就是代码直接,梳理需要的数据,保存到飞书或钉钉等ai表格,
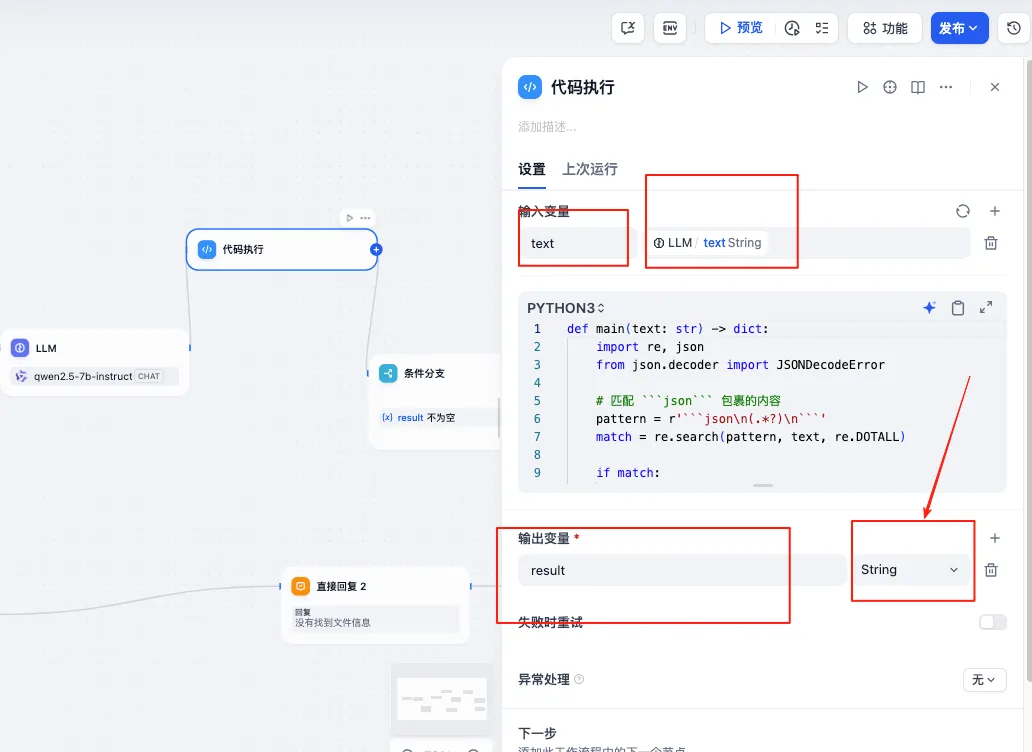
这个地方一定要注意,返回到格式,如果格式不是设置的,会报错 。这是我py处理数据格式的代码。
def main(text: str) -> dict:import re, jsonfrom json.decoder import JSONDecodeError# 匹配 ```json```包裹的内容pattern = r'```json\n(.*?)\n```'match = re.search(pattern, text, re.DOTALL)if match:json_str = match.group(1).strip()# 清理可能影响解析的特殊字符json_str = json_str.replace('\r', '')json_str = re.sub(r'[\x00-\x1F\x7F]', '', json_str)try:json_data = json.loads(json_str)# 确保数据是列表格式if not isinstance(json_data, list):json_data = [json_data]# 完整提取所有字段,完整保留原始内容formatted_data = []for item in json_data:if isinstance(item, dict):formatted_item = {"姓名": item.get("姓名", ""),"手机号": item.get("手机", ""),"性别": item.get("性别", ""),"年龄": item.get("年龄", ""),"学历": item.get("学历", ""),"简历信息": item.get("简历信息", "") # 完整保留原始简历信息}formatted_data.append(formatted_item)return {"result": json.dumps(formatted_data, ensure_ascii=False)}except JSONDecodeError as e:print(f"JSON解析错误: 行 {e.lineno}, 列 {e.colno} - {e.msg}")return {"result": ""}except Exception as e:print(f"处理错误: {str(e)}")return {"result": ""}else:print("未找到有效的JSON数据")return {"result": ""}后面就是对接飞书ai表格,飞书ai表格这个需要,创建飞书应用,找到对应的授权信息。
图片
这个添加的地方。有一些坑,我需要说下,这个记录列表是字符串类型,需要在py代码中提取转换好。不然会报错。
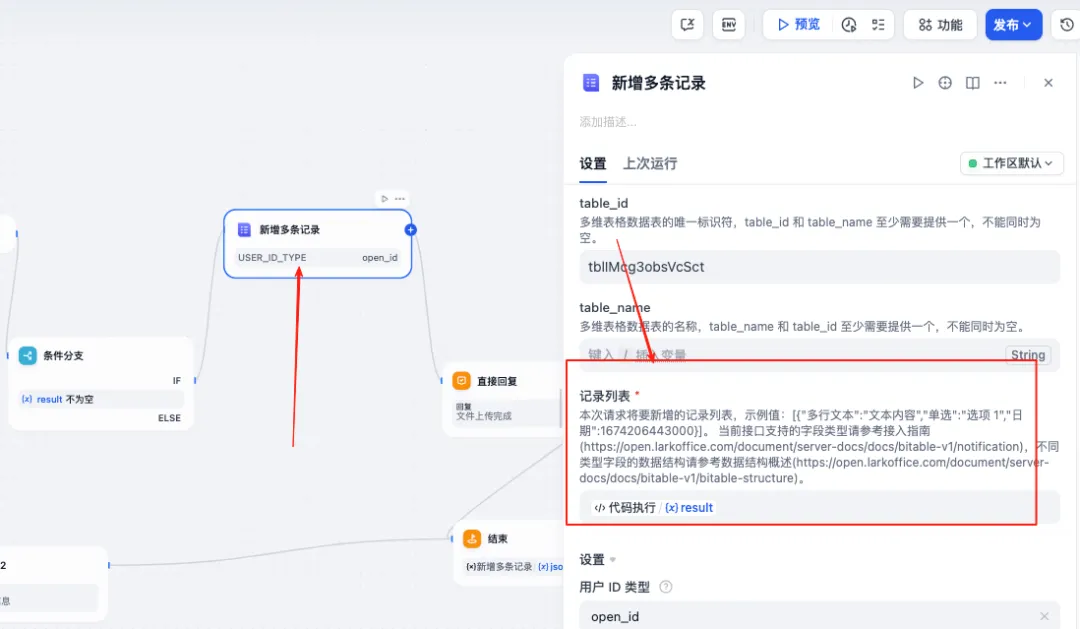
导入成功以后,添加条件判断是否成功,成功在把数据转换下,输出导入我数据信息,
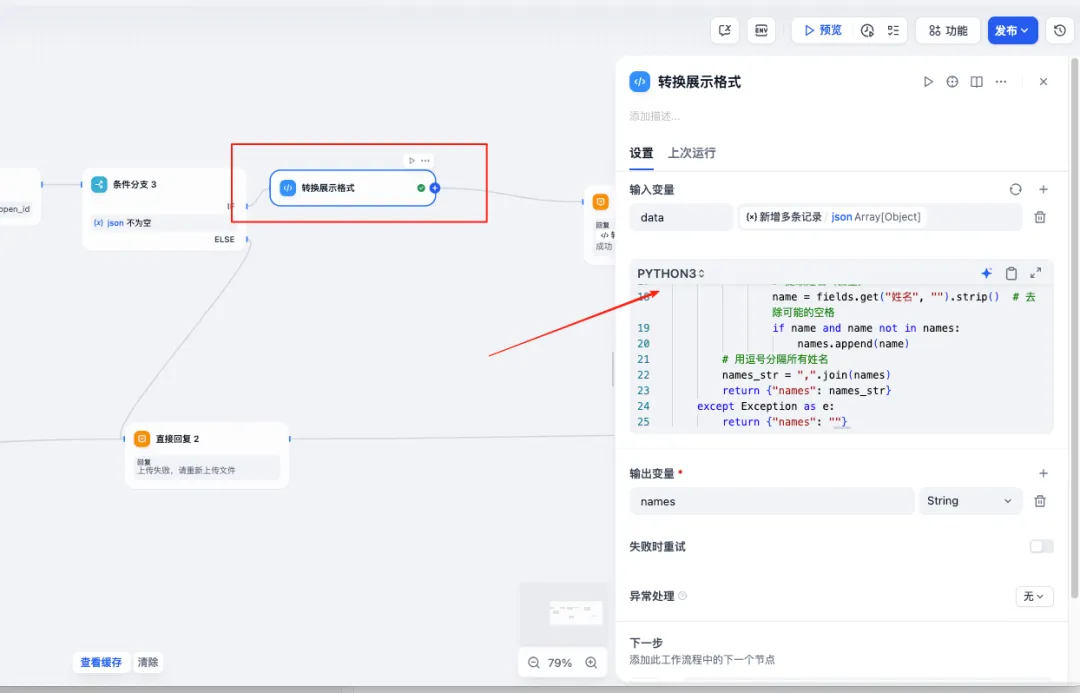
代码转换如下:
import json
def main(data: list) -> dict:try:names = []# 遍历外层数据for outer_item in data:# 获取records列表(处理可能的非列表情况)records = outer_item.get("records", [])if not isinstance(records, list):continue# 遍历每条记录for record in records:# 解析fields中的JSONfields_str = record.get("fields", "{}")fields = json.loads(fields_str)# 提取姓名(去重)name = fields.get("姓名", "").strip() # 去除可能的空格if name and name not in names:names.append(name)# 用逗号分隔所有姓名names_str = ",".join(names)return {"names": names_str}except Exception as e:return {"names": ""}
然后回复信息,结束工作流。
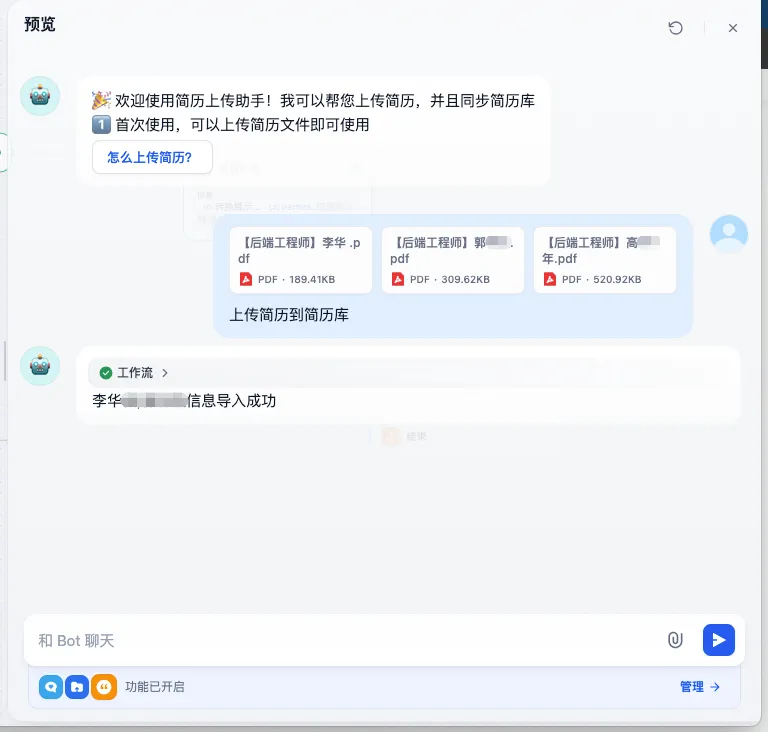
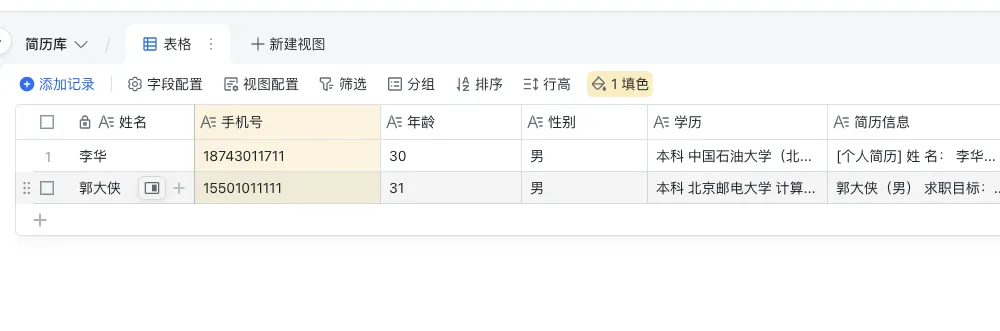
这样hr可以直接处理,记录数据,后续更新面试相关的工作流。
如果感觉不错,可以点赞收藏。