【算法岗面试】手撕Self-Attention、Multi-head Attention
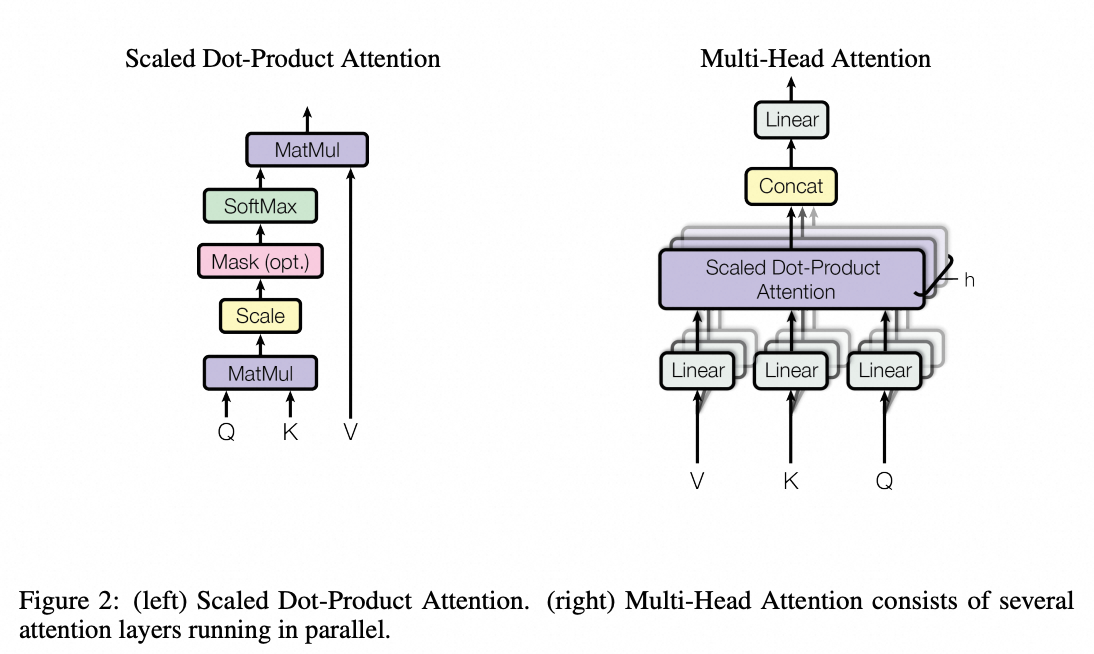
输入 X: [B, L,
d_model]Q/K/V 权重: [d_model, d_model] (合头写法,拆开后每头是 [d_model, d_k])
多头时:先全量 linear 得 [B, L, d_model],再 view/reshape 成 [B, L, num_heads, d_k],再 permute 成 [B, num_heads, L, d_k]
先用简单的Self-Attention捋一遍数据流动的过程:
import torch
import torch.nn as nn
import torch.nn.functional as F
import mathclass SelfAttention(nn.Module):def __init__(self, embed_dim,d_k):super().__init__()self.embed_dim = embed_dimself.W_Q = nn.Linear(embed_dim, d_k)self.W_K = nn.Linear(embed_dim, d_k)self.W_V = nn.Linear(embed_dim, d_k)def forward(self, x):# x: [batch_size, seq_len, embed_dim]Q = self.W_Q(x) # [B, L, D]K = self.W_K(x) # [B, L, D]V = self.W_V(x) # [B, L, D]# Attention scores: [B, L, L]score = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)attn_weights = F.softmax(score, dim=-1) # [B, L, L]att_output = torch.matmul(attn_weights, V) # [B, L, D]return att_output
然后再拓展到多头:
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):#定义参数def __init__(self,embed_dim,head_num):super().__init__()self.embed_dim=embed_dimself.head_num=head_numself.head_dim=embed_dim//head_num #每个头的维度#定义好Q,K,V矩阵和最后的输出变换矩阵self.W_Q=nn.Linear(embed_dim, embed_dim)self.W_K=nn.Linear(embed_dim, embed_dim)self.W_V=nn.Linear(embed_dim, embed_dim)self.W_O=nn.Linear(embed_dim, embed_dim)# 注意力输出后再投回原维度#前向传播def forward(self,x):# x维度是BLD,batch_size seq_len embed_dimbatch_size,seq_len,embed_dim=x.size()# 先全量投影得到了QKV矩阵再拆头Q = self.W_Q(x) # [B, L, embed_dim]K = self.W_K(x) # [B, L, embed_dim]V = self.W_V(x) # [B, L, embed_dim]#拆分多头# 方法:先view,再transpose# 拆分成[B, L, num_heads, head_dim],再变成[B, num_heads, L, head_dim]Q=Q.view(batch_size, seq_len, self.head_num, self.head_dim).transpose(1, 2)K=K.view(batch_size, seq_len, self.head_num, self.head_dim).transpose(1, 2)V=V.view(batch_size, seq_len, self.head_num, self.head_dim).transpose(1, 2)# 此时shape均为[B, num_heads, L, head_dim]# Q @ K^T:最后两维做乘法# K.transpose(-2, -1): [B, num_heads, head_dim, L]score = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.head_dim) # [B, num_heads, L, L]attn_weights = F.softmax(score, dim=-1) # [B, num_heads, L, L]# 得到每个头的注意力输出att_output = torch.matmul(attn_weights, V) # [B, num_heads, L, head_dim]# 变回 [B, L, embed_dim]# 先transpose(1,2): [B, L, num_heads, head_dim]# 然后view为 [B, L, num_heads*head_dim] = [B, L, embed_dim]att_output = att_output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.embed_dim)output = self.W_O(att_output) # [B, L, embed_dim]return output为什么要拆分成 (num_heads, head_dim)?
- 背景:你的输入每个 token 有
embed_dim维(比如 768)。多头注意力机制本质上是把输入特征维度切成 num_heads 块,每块 head_dim 维,分别做自注意力,然后拼回去。 - 本质:每个头都是一个“小的单头 self-attention”,但只用一部分特征(
head_dim=embed_dim//num_heads)。 - 举例:如果 embed_dim=768, num_heads=12, 每头 head_dim=64。768=12*64。
原始Q的shape
- Q = [B, L, embed_dim] (batch, sequence, feature维)
目标:希望得到一个 shape = [B, num_heads, L, head_dim]
这样后续每个head可以独立做 Attention(矩阵乘法/softmax/加权 …)。
为什么用 view(B, L, num_heads, head_dim).transpose(1, 2)?
Step 1: view(B, L, num_heads, head_dim)
- 把最后一维
embed_dim拆成num_heads * head_dim - 假设
embed_dim=768,num_heads=12,head_dim=64,则拆分成 [B, L, 12, 64]
Step 2: transpose(1, 2)
- 把 head 数移到序列长度前面
[B, L, num_heads, head_dim]-->[B, num_heads, L, head_dim]- 这样每个 batch 下,对每个头进行独立计算(更方便并行处理多头)
过程可视化
比如有 Q: [2, 10, 768](batch=2, seq=10, 768维)
- view(2, 10, 12, 64) -- 12个头,每头64维
- transpose(1, 2) 得到 (2, 12, 10, 64)
为什么顺序不能交换?
如果你写成 view(B, num_heads, L, head_dim),就完全不对了!因为:
- 原始数据是按
[B, L, embed_dim]顺序排列的。 view顺序必须是先序列后特征,特征维度用于拆分。- 而且在 PyTorch、Tensorflow 中,
view后的数据不会自动乱序分配,只是“重新组织 shape”,不会帮助你把循环顺序换掉。 transpose(1, 2)是在[B, L, num_heads, head_dim]基础上,把 head 放到序列之前。
如果互换 num_heads、L 顺序,会把 batch 里的时间步和头搞混,后续 Attention 计算也会错。
为什么最终要 [B, num_heads, L, head_dim]?
- 这样每个头彼此独立,并且都遍历了全部 batch 的序列。
- 方便后续在每个头上分别做 Attention 计算。
总结口诀
view 拆头之前,总是最后一维(embed_dim)先拆成 (num_heads, head_dim),再用 transpose 把 head 移到 L 之前,得到 [B, num_heads, L, head_dim]。不能交换顺序,因为原始数据排列是 batch, seq, feat,再拆 feat。