维文识别技术:将印刷体或手写体的维文文本转化为计算机可处理的数字信息
维文(维吾尔文)作为新疆地区及中亚数百万人口使用的文字,维文识别技术对于促进信息交流、文化传承和地区发展至关重要。其识别技术通过人工智能手段,将印刷体或手写体的维文文本转化为计算机可处理的数字信息,成为连接传统与现代的关键纽带。
核心工作原理:从图像到文本的智能转换
维文识别本质上是模式识别与机器学习的深度应用,其流程严谨而复杂:
1.图像预处理:
- 降噪与增强:去除扫描或拍摄产生的污点、折痕、阴影干扰,增强文字区域对比度。
- 版面分析:精准定位图像中的文本区域,区分正文、标题、图片、表格等。
- 行/词切分:由于维文从右向左横向书写,需高效切分文本行和单词(词间有空格)。
2.特征提取:
- 提取每个字符或单词的关键视觉特征,包括轮廓、笔划方向、点符位置、基线位置、连笔形状等。深度学习方法(如CNN)可自动学习复杂特征。
3.识别引擎:
主流方法(深度学习):
- 卷积神经网络:高效提取图像特征。
- 循环神经网络/ Transformer:处理序列信息(字符顺序),理解上下文关联。维文单词中字母的形态高度依赖位置(词首、词中、词尾、独立),RNN/LSTM/Transformer能有效建模这种强依赖关系。
- 解码:将神经网络输出的概率序列转换为最可能的字符序列(维文字符)。
4.后处理:
- 语言模型:利用维语语法、词频统计知识,纠正可能的识别错误(如混淆形近字母)。
- 词典匹配:进一步提高单词识别的准确性。
- 格式还原:尽可能保留原文档的排版、字体等信息。
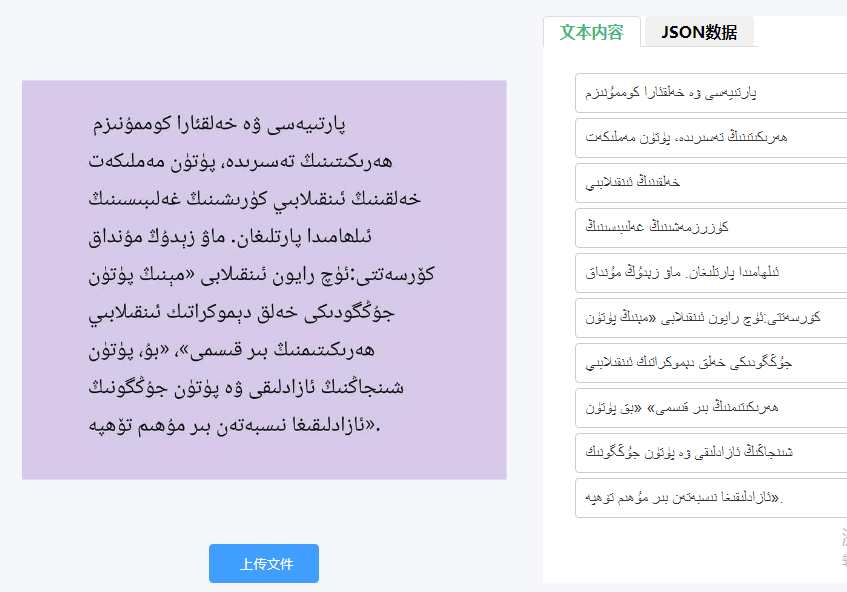
独特挑战与技术难点
维文识别面临比拉丁字母或汉字识别更复杂的挑战:
- 高度连写与形态变化:维文字母在词首、词中、词尾、独立形式下有显著不同的形态(有时多达4种),且字母间常紧密连笔,导致字符分割极其困难,常需整体识别单词。
- 点符的重要性与易混淆性:点符是区分不同字母的核心特征(如ب [b], ت [t], ث [th], ن [n]),但在扫描或书写不清时易丢失或粘连,造成识别错误。
- 双向文本环境:维文从右向左书写,但当嵌入数字、拉丁字母(如URL、专有名词)时,需处理混合双向文本,排版和识别逻辑复杂。
- 丰富的变音符号:哈姆扎、叠音符号等对发音和语义至关重要,但尺寸小、位置灵活,易被忽略。
- 手写体的巨大差异:个人书写习惯差异大,连笔程度、字母形态、倾斜度变化多端,对手写识别构成严峻挑战。
- 高质量数据稀缺:用于训练深度模型的、覆盖广泛字体和书写风格的大规模标注维文数据集相对匮乏。
- 复杂字体与印刷质量:传统书籍、报纸可能使用特殊或复杂装饰性字体,低质量印刷导致模糊、断笔。
关键功能特点
现代维文识别系统通常具备以下能力:
- 高精度识别:对清晰印刷体维文能达到商用级识别率(>95%)。
- 多字体适应:能处理常见印刷字体(如ALKATIP Tor、UKIJ Tuz Tom)。
- 手写识别支持:逐步提升对规整手写体的识别能力(仍是难点)。
- 版面保留:识别同时还原段落、表格、图片位置等基本版面信息。
- 混合文本处理:有效处理维文、中文、拉丁字母、数字混合的文档。
- 多格式输出:支持输出可编辑文本(如TXT)、保留格式文档(如DOCX, PDF)或结构化数据(如JSON)。
广阔应用场景
维文识别技术正深刻改变信息获取与处理方式:
文档数字化与档案管理:
- 将历史文献、政府公文、图书报刊转化为可检索的电子档案,保护文化遗产。
智能办公与教育:
- 扫描维文文件转可编辑文档,提升办公效率。
- 教学资料数字化,开发维汉/维英对照学习软件、点读工具。
多语言信息处理:
- 搜索引擎索引维文网页内容。
- 社交媒体内容分析、舆情监控。
- 机器翻译的前端输入(扫描文档直接翻译)。
金融服务:
- 自动识别身份证、银行卡、表单上的维文信息,加速开户、信贷等业务流程。
邮政物流与交通:
- 自动分拣维文地址的包裹,识别路牌、证件信息。
移动应用:
- 手机扫描翻译(菜单、说明书、路牌)。
- 手写输入法支持维文输入。
公共服务与司法:
- 政府窗口文件电子化录入,法庭证据材料处理。
维文识别技术正朝着更高精度(尤其手写体)、更强鲁棒性(适应低质量图像)、端到端深度学习模型优化、与LLM结合提升语义理解与纠错等方向发展。随着“数字丝绸之路”建设推进,维文识别将在促进跨语言交流、保障信息公平、服务区域经济社会发展中扮演愈发重要的角色,成为构建中华民族共同体意识、实现各民族共同繁荣的技术基石。维文识别技术的持续突破,将让古老的维文在数字时代焕发新的生机。