【模型剪枝2】不同剪枝方法实现对 yolov5n 剪枝测试及对比
目录
一、背景
二、剪枝
1. Network Slimming
1.0 代码准备
1.1 稀疏化训练
1.2 剪枝
1.3 微调
1.4 测试总结
2. Torch Pruning(TP)
2.1 MagnitudePruner
2.1.1 剪枝
2.1.2 retrain
2.1.3 测试总结
2.2 SlimmingPruner
2.2.1 定义重要性评估
2.2.2 定义剪枝器
2.2.3 初始化
2.2.4 稀疏化训练
2.2.5 剪枝
2.2.6 微调
2.2.7 测试总结
三、总结
参考资料
一、背景
书接上回,本文记录一下上文中介绍的三种剪枝方法的使用,以剪枝 yolov5n6 为例,对比一下剪枝前后模型体积和准确率变化,以及不同剪枝方法之间的对比。
二、剪枝
[1] 官方没有提供代码,放到后面使用 Torch Pruning 工具实现,[2] 的官方代码是对 VGG 和 ResNet 进行的剪枝,有需要的朋友可以参考,这里使用的是 midasklr 大佬提供的 yolov5 实现[5],也是使用比较多的。
1. Network Slimming
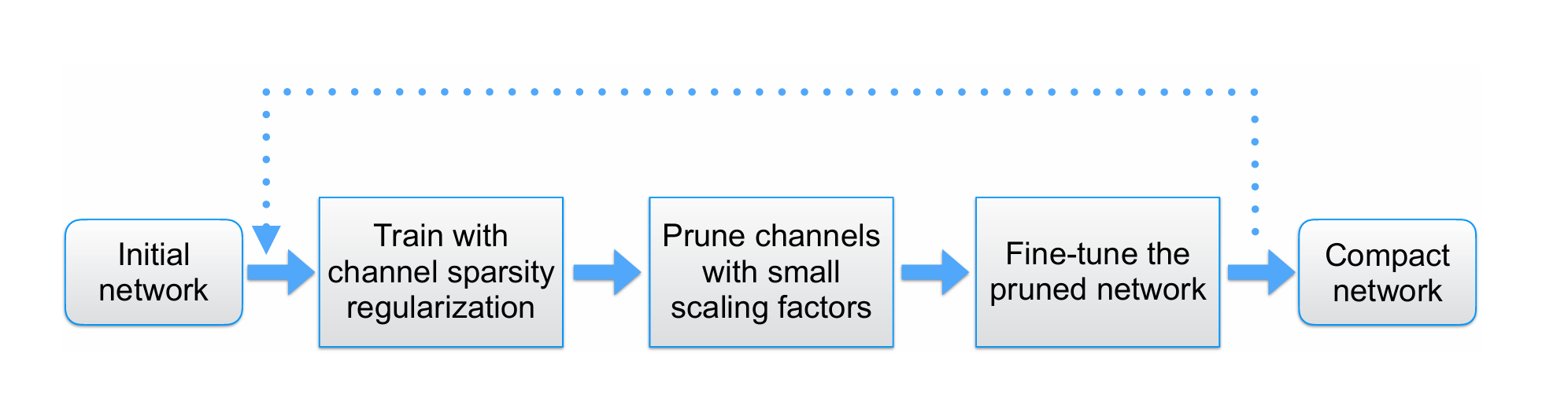
主要剪枝流程如下,作为比较,可以先训练一个原始 yolo 模型作为 baseline,之后再进行稀疏化训练。
原始 yolov5n6 模型精度测试结果

1.0 代码准备
首先本文测试的模型是有 4 个检测尺度分支的 yolov5n6,所以需要先对源码进行修改已适配模型结构。
(1)在 models/yolo.py 的 Line538 后添加一行
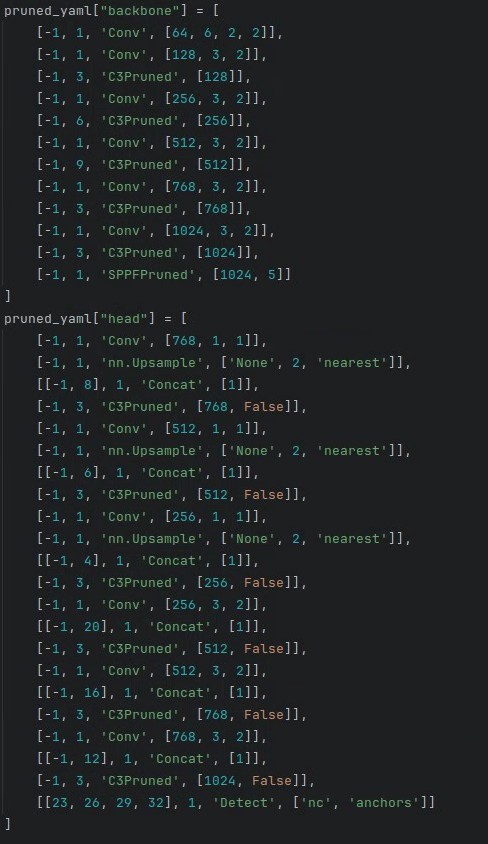
from_to_map[named_m_base + ".m.3"] = fromlayer[f[3]](2)prune.py 从 Line432 开始的 pruned_yaml["backbone"] 和 pruned_yaml["head"] 改成 yolov5n6 的 backbone 和 head
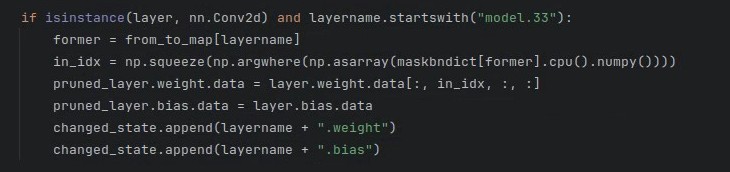
(3)Line554 的 "model.24" 改成 “model.33”
1.1 稀疏化训练
train_sparity.py 提供了稀疏化训练代码,这里的稀疏率 没有像官方一样使用定值,而是根据训练轮次增加逐渐减小,通常
越大稀疏化程度越高。
python train_sparity.py --st --sr 0.0005训练完成后可以进入 http://localhost:6006/ 查看 BN 层权重分布直方图的变化情况
tensorboard --logdir=./runs/train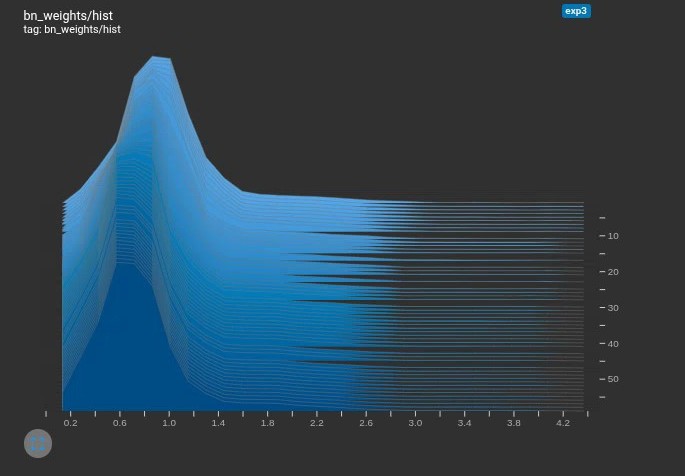
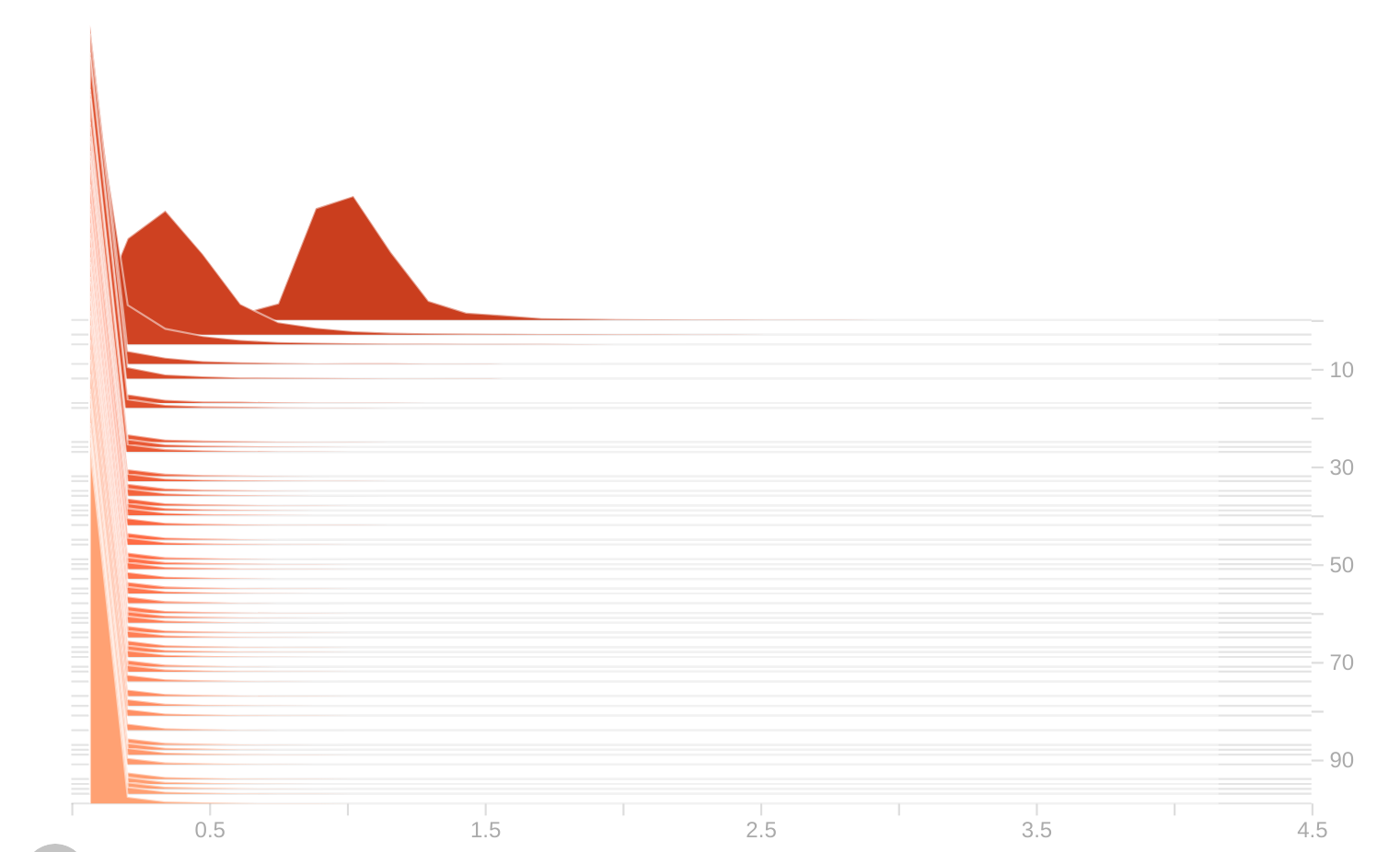
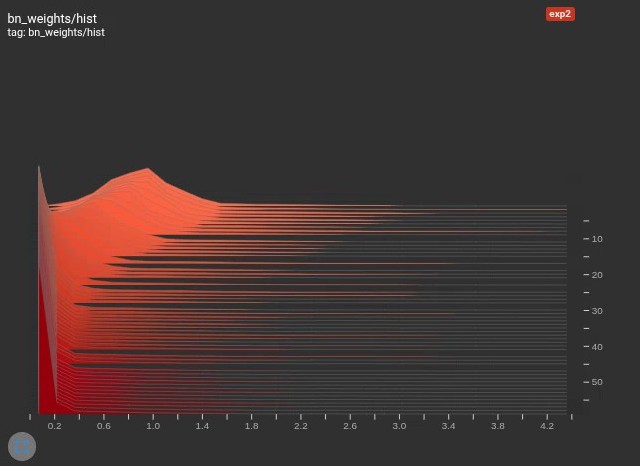
如果设置过小,BN 层很难稀疏化,可剪枝空间很小;如果设置过大,BN 层会过于稀疏化,难以学习到有效权重,造成精度损失和过度剪枝。所以需要根据具体任务和训练结果不断调整
,直到 BN 层的权重在训练过程中平稳变化至 0 点。
除了监控 BN 层,还可以通过 mAP 的变化情况判断模型的训练效果。
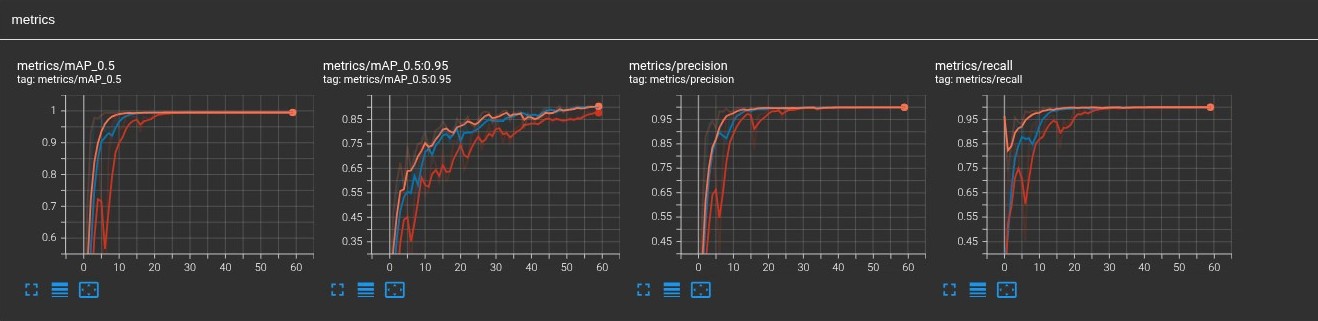
稀疏模型的精度测试

1.2 剪枝
稀疏训练完成后对得到的稀疏模型进行剪枝
python prune.py --percent 0.5 --weights /path/to/your/sparse_model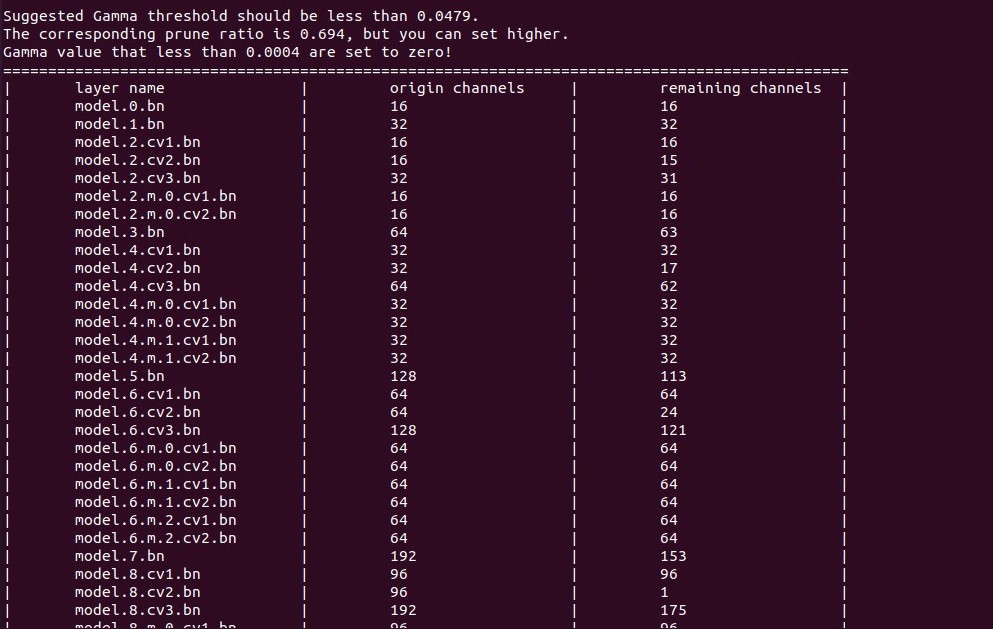
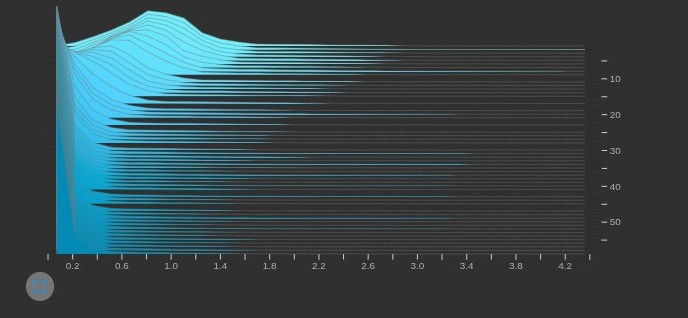
可以看到根据计算得到的 阈值对各层进行了剪枝。
当剪枝之后剩余通道数为 1 时,剪枝过程可能会报错。上图中 model.8.cv3.bn 剪枝后剩余 1 个通道,然后就会报错。

这表明对该层来说 阈值偏大了,所以需要针对该层调整
,确保剪枝后剩余通道数>1,具体需要修改 utils/prune_utils.py 的 obtain_bn_mask(),每次剪完之后判断剩余通道数,如果余 1,则按1% 的步长降低
,这样能保证剪枝通道尽可能多,循环剪枝判断,直至剩余通道数>1。
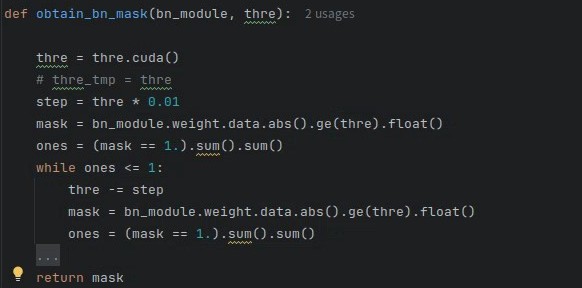
此时再剪枝就没有问题了,可以看到 model.8.cv3.bn 层剩余通道数变2了。
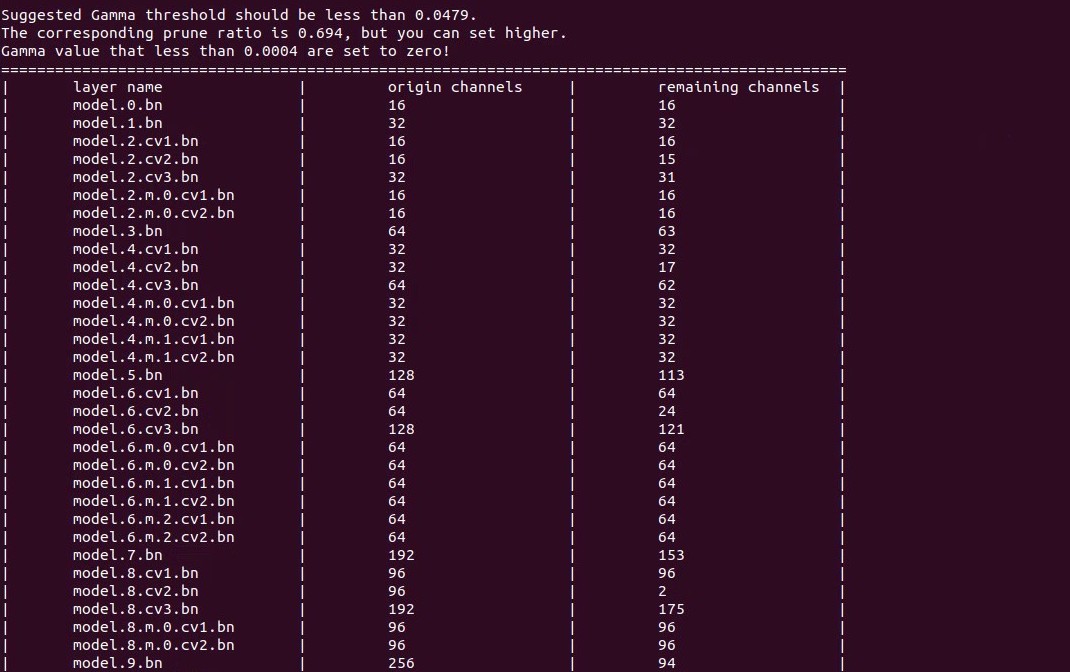
剪枝 50% 后的精度测试

可以看到跟剪枝前的稀疏模型相比没有精度损失,说明还有剪枝空间,剪枝率可以再调大一些。
剪枝 70% 后的模型和精度测试:
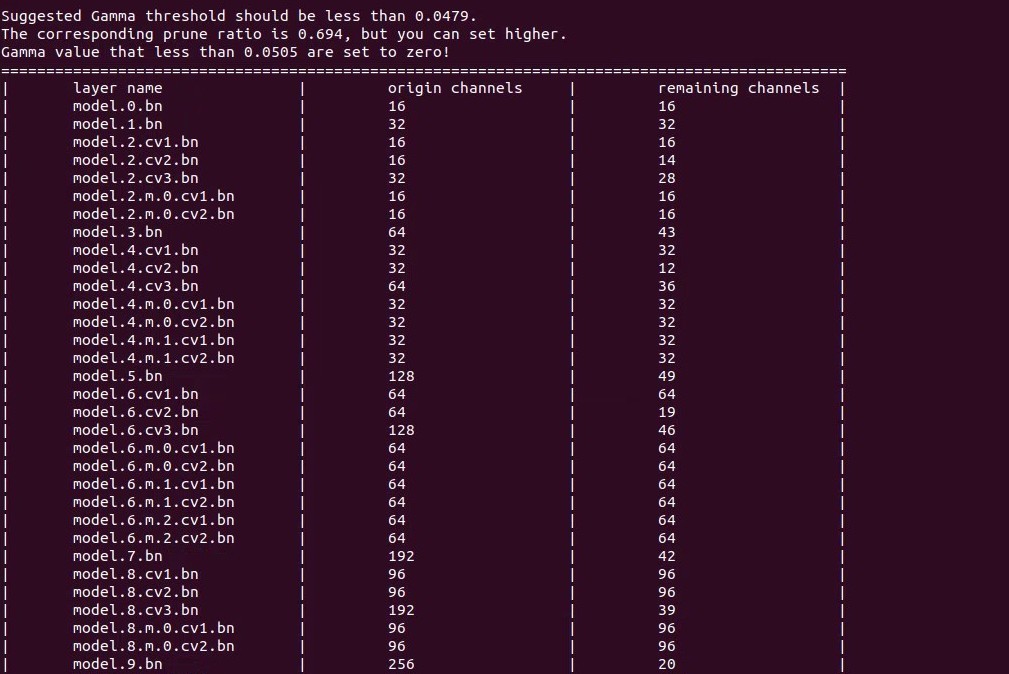

可以看到准确率明显下降,需要微调来恢复精度。
1.3 微调
python finetune.py --weights pruned_model.pt微调 60 个 epochs 之后准确率恢复到可接受程度,相比剪枝前会有轻微下降。

1.4 测试总结
上述剪枝流程还是比较清晰的,实际使用时很难说一次剪枝成功,根据效果多调参数,设置合适的剪枝比例基本不会有太大问题。下面对比总结一下剪枝前后模型准确率、体积、推理速度等方面的差异。
| model | mAP @.5 | mAP @.5:.95 | Speed / CPU (ms/image) | Speed / GPU (ms/image) | Params (M) | FLOPs (G) | Size (MB) |
| baseline | 0.995 | 0.921 | 36.3 | 11.7 | 3.09 | 4.3 | 13.2@32FP |
| sparse training | 0.995 | 0.897 | 37.6 | 12.0 | 3.09 | 4.3 | 13.2 |
| pruned 50% | 0.995 | 0.897 | 28.3 | 11.6 | 1.28 | 3.0 | 5.5 |
| pruned 70% | 0.694 | 0.55 | 25.6 (↑29.4%) | 10.4 (↑11.1%) | 0.67 | 2.2 | 3.0 |
| finetune | 0.994 | 0.877 | 24.9 (↑31.4%) | 11.0 (↑6.0%) | 0.67 | 2.2 | 3.0 |
从推理速度上看,剪枝后的模型在 GPU 上的加速效果不明显,在 CPU 上能加速 30% 左右,模型体积有明显降低。对于 GPU 加速不明显的问题,有人说是因为剪枝后的通道数不满足 ,不利于 GPU 的并行计算。

有小伙伴提出控制剪枝时的通道数为 ,实测下来提升效果不明显。
2. Torch Pruning(TP)
下面介绍使用剪枝库 TP 实现两种 [1-2] 不同的剪枝器。建议安装最新版本,新旧版本的代码结构差别比较大。TP 的基本使用可以参考官方文档,里面说的很清楚。
2.1 MagnitudePruner
MagnitudePruner 不需要稀疏化训练,直接对训练后的模型剪枝即可。
2.1.1 剪枝
TP 内部实现了基于权值重要性的剪枝算法,我们只需要调用相关接口生成一个自己的剪枝器就可以使用了。
def l1norm_filter_pruner(model, fake_input, iterative_steps, ratio, device='cuda:0'):for p in model.parameters():p.requires_grad_(True)# 定义重要性标准,p=2表示使用L2范数计算重要性分数imp = tp.importance.MagnitudeImportance(p=2)ignored_layer_outputs = [] # 忽略剪枝的输出通道ignored_layer_inputs = [] # 忽略剪枝的输入通道ignored_module = []# 自定义忽略剪枝的层,如果某些层对精度影响较大可以不剪,如果全剪则跳过本部分for k, m in model.named_modules():k_sp = k.split('.')if len(k_sp) <= 1: continuemodule_idx = int(k_sp[1])# 忽略对backbone的剪枝if module_idx < 12 and f"model.{module_idx}" not in ignored_module:ignored_module.append(f"model.{module_idx}")ignored_layer_outputs.append(m)# 忽略对Detect输出层的剪枝if isinstance(m, (Detect, )):ignored_layer_outputs.append(m)# 忽略对Detect输入层的剪枝if k in ['model.23.cv3', 'model.26.cv3', 'model.29.cv3', 'model.32.cv3']:ignored_layer_inputs.append(m)ignored_layers = ignored_layer_inputs + ignored_layer_outputs# 定义剪枝器pruner = tp.pruner.MagnitudePruner(model,fake_input, # 样例输入,用于自动生成依赖图,shape: [bs, ch, h, w]importance=imp, # 重要性标准iterative_steps=iterative_steps, # 剪枝迭代次数(=1:一次剪枝;>1:迭代剪枝,每次剪枝比例=ratio/iterative_steps)pruning_ratio=ratio, # 剪枝比例ignored_layers=ignored_layer_outputs, #忽略层)return model, pruner 注意剪枝比例是对于所有需要剪枝的层来说的,比如模型一共 20 层,需要剪枝 15 层,剪枝比例 70%,则实际剪枝 层。
有了剪枝器之后就可以剪枝了,这里使用了两种方式剪枝,一种是直接对训练完成的权重文件进行剪枝,另一种是 prune-retrain 迭代式剪枝。
一次剪枝
def prune_model(pruner, model, inputs, iters):# 原始模型的计算量和参数量base_macs, base_params = tp.utils.count_ops_and_params(model, example_inputs=inputs)# 开始剪枝for _ in range(iters):pruner.step()# 剪枝后的计算量和参数量macs, params = tp.utils.count_ops_and_params(model, example_inputs=inputs)print(model)print("Before Pruning: MACs=%.2f G, #Params=%.2f M" % (base_macs/1e9, base_params/1e6))print("After Pruning: MACs=%.2f G, #Params=%.2f M" % (macs/1e9, params/1e6))return modelif __name__ == '__main__':weights = 'runs/train/exp/weights/last.pt'model = attempt_load(weights, map_location='cuda:0')fake_input = torch.randn((1, 3, 640, 640), device='cuda:0')model, pruner = l1norm_filter_pruner(model, fake_input,1, 0.5, 'cuda:0')pruned_model = prune_model(pruner, model, fake_input, 1)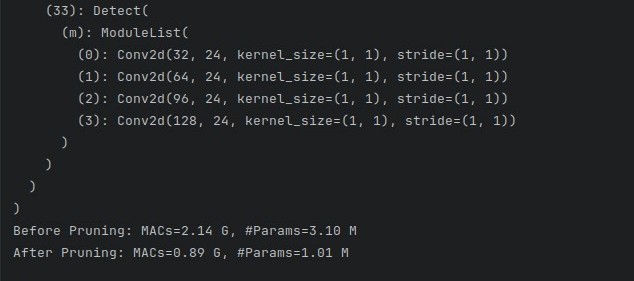
测试剪枝后准确率,直接归零

实测不同剪枝比例,仅剪枝 20% 准确率依然是 0,剪枝 1% 时 mAP 也有明显下降,感觉这种剪枝方式不好用。

2.1.2 retrain
[1]中提供了两种 retrain 策略恢复精度,一次剪枝+retrain 和 剪枝+retrain 交替。

(1)One Shot
对于一次剪枝+retrain,重新加载剪枝模型后从头开始训练,实测训练 120 个 epochs 模型基本收敛,精度不再有明显提升,最终恢复结果如下:


(2)迭代剪枝(Iter)
逐层剪枝和 retrain 交替进行,进行下一次剪枝之前先 retrain。之前 TP 作者有说过还不支持该方式,我也看了一下自该回答之后更新过的版本,也没有看到支持该方式的提示,所以目前来说应该还不支持。(如果说的不对请大佬指正)
2.1.3 测试总结
目前测试来看基于权值重要性的剪枝方式效果不如基于 BN 层的剪枝,前者剪枝比例稍大一些对于精度损失就很明显,而且 retrain 基本恢复不到原始精度,但是模型压缩比和 CPU 加速比更明显,具体对比测试结果如下:
| Model (prune method) | mAP @.5 | mAP @.5:.95 | Speed / CPU (ms/image) | Speed / GPU (ms/image) | Params (M) | FLOPs (G) | Size (MB) |
| baseline | 0.995 | 0.921 | 36.3 | 11.7 | 3.09 | 4.3 | 13.2@32FP |
| MagPru+50% | 0 | 0 | / | / | 0.78 | 1.2 | 3.4 |
| SlimPru+50% | 0.995 | 0.897 | 28.3 | 11.6 | 1.28 | 3.0 | 5.5 |
| SlimPru+70% | 0.694 | 0.55 | 25.6 (↑29.4%) | 10.4 (↑11.1%) | 0.67 | 2.2 | 3.0 |
| MagPru+50%+retrain (OneShot/120epochs) | 0.995 | 0.86 | 20.6 (↑43.2%) | 10.9 (↑6.8%) | 0.78 | 1.2 | 3.4 |
| SlimPru+70%+finetune (60 epochs) | 0.994 | 0.877 | 24.9 (↑31.4%) | 11.0 (↑6.0%) | 0.67 | 2.2 | 3.0 |
2.2 SlimmingPruner
基于 TP 实现 Slimming 剪枝比较简单,[6] 中原作者也给了比较清晰的例子,定义好重要性评估和剪枝器,将 [5] 中的稀疏化训练代码替换一下就可以,后面的剪枝和微调操作不变。
2.2.1 定义重要性评估
class MySlimmingImportance(tp.importance.Importance):def __call__(self, group, **kwargs):group_imp = []for dep, idxs in group:layer = dep.target.moduleif isinstance(layer, nn.BatchNorm2d):local_imp = torch.abs(layer.weight.data)group_imp.append(local_imp)if not len(group_imp):return Nonegroup_imp = torch.stack(group_imp, dim=0).mean(dim=0)return group_imp2.2.2 定义剪枝器
class MySlimmingPruner(tp.pruner.BasePruner):def regularize(self, model, sr):for m in model.modules():if isinstance(m, nn.BatchNorm2d):m.weight.grad.data.add_(sr * torch.sign(m.weight.data)) # L1正则2.2.3 初始化
初始化重要性评估和剪枝器
imp = MySlimmingImportance()ignored_layer_outputs = []
ignored_layer_inputs = []
for k, m in model.named_modules():if isinstance(m, Detect):ignored_layer_outputs.append(m)if k in ['model.23.cv3', 'model.26.cv3', 'model.29.cv3', 'model.32.cv3']:ignored_layer_inputs.append(m)
ignored_layers = ignored_layer_inputs + ignored_layer_outputsiterative_steps = 1
pruner = MySlimmingPruner(model,fake_input,global_pruning=False,importance=imp,iterative_steps=iterative_steps,pruning_ratio=0.7,ignored_layers=ignored_layers, # 忽略对Detect层的剪枝
)2.2.4 稀疏化训练
在反向传播和梯度更新之间插入一行代码即可。tp.Pruner.MetaPruner 提供了一个 regularize 接口,用于稀疏训练。
loss.backward()
srtmp = opt.sr*(1 - 0.9*epoch/epochs)
slpruner.regularize(model, srtmp) # 稀疏化训练
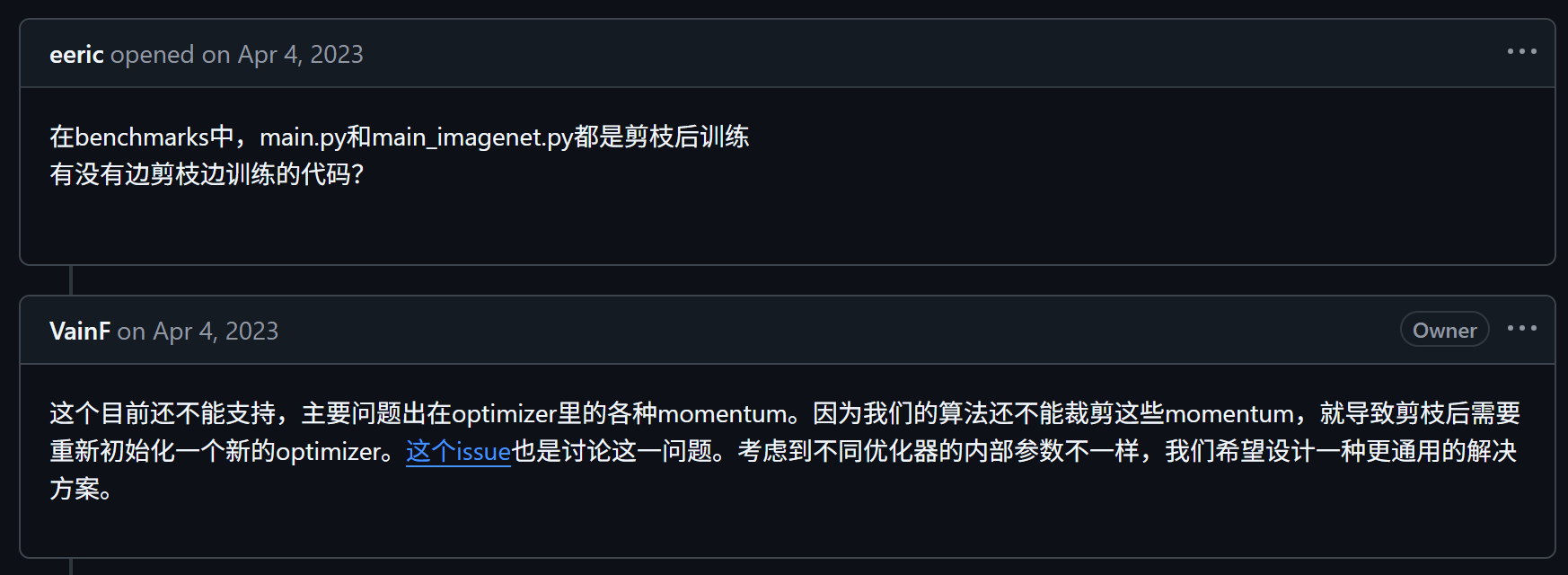
optimizer.step()训练过程没有区别,训练完之后使用 TensorBoard 查看 BN 层权重变化,可以看到权重随着训练慢慢变得稀疏

2.2.5 剪枝

2.2.6 微调
微调 60 个 epochs 后基本恢复,测试精度上与直接使用 Network Slimming 没啥区别。

2.2.7 测试总结
Network Slimming 的两种实现方式在最终的剪枝效果上没有啥区别,主要还是使用方式上的不同。
| Model | mAP @.5 | mAP @.5:.95 | Speed / CPU (ms/image) | Speed / GPU (ms/image) | Params (M) | FLOPs (G) | Size (MB) |
| base | 0.995 | 0.921 | 36.3 | 11.7 | 3.09 | 4.3 | 13.2@32FP |
| Slimming (prune 70%) | 0.694 | 0.55 | 25.6 (↑29.4%) | 10.4 (↑11.1%) | 0.67 | 2.2 | 3.0 |
| Slimming+ft (60 epochs) | 0.994 | 0.877 | 24.9 (↑31.4%) | 11.0 (↑6.0%) | 0.67 | 2.2 | 3.0 |
| TP-Slimming (prune 70%) | 0 | 0 | / | / | / | / | 2.9 |
| TP-Slimming+ft (60 epochs) | 0.995 | 0.877 | 25.4 (↑30%) | 11.1 (↑5.1%) | 0.67 | 2.2 | 2.9 |
三、总结
本文是基于之前学习的几篇剪枝论文,参考网上代码做的本地实现,并对比测试了不同剪枝方法之间的效果差异。目前的工作只能算是对模型剪枝的入门,剪枝的模型也是使用比较多的yolov5,实现难度上相对小一些。后面有时间也会慢慢尝试对其他更多模型的剪枝,学习更多的剪枝方法。
现在使用的剪枝和量化操作都是独立进行的,而且剪枝对模型体积的压缩效果更明显,可以试着把两者结合起来,对剪枝后的模型做量化,进一步压缩模型体积的同时借助 NPU 加速模型推理。此外,除了模型剪枝和模型量化,模型蒸馏也是模型优化的一种方法,后面有时间也会去学习。
参考资料
[1] [1608.08710] Pruning Filters for Efficient ConvNets
[2] ICCV 2017 Open Access Repository
[3] yolov5s模型剪枝详细过程(v6.0)_yolov5剪枝-CSDN博客
[4] YOLOv5-6.1剪枝实战_yolov5通道剪枝-CSDN博客
[5] https://github.com/midasklr/yolov5prune/tree/v6.0
[6] https://github.com/YINYIPENG-EN/Pruning_for_YOLOV5_pytorch
[7] Torch-Pruning | 轻松实现结构化剪枝算法 - 知乎