大模型-QAT介绍
一、量化技术简介
近年来,随着Transformer、MOE架构的提出,使得大模型轻松突破上万亿规模参数,从而导致模型变得越来越大,因此,需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。 目前的模型压缩技术主要分为如下几类:
模型剪枝(Pruning)
知识蒸馏(Knowledge Distillation)
模型量化
模型量化是一种用于减少神经网络模型大小和计算量的技术,将模型参数(如:权重)从高精度数据类型(如:float32)转换为低精度数据类型(如:int8 或 fp4)。模型量化通过以更少的位数表示数据,可以减少模型尺寸,进而减少在推理时的内存消耗,并且在一些低精度运算较快的处理器上可以增加推理速度,同时仍然可以保持模型的性能。目前量化技术从大的角度上可以分成 量化感知训练QAT(Quantization-Aware Training)和训练后量化PTQ(Post Training Quantization)。
PTQ:
PTQ 的主要优势在于其简单和高效,无需对 LLM 架构进行修改或重新训练,仅使用有限的校准数据进行校准即可。然而,值得注意的是,PTQ可能会在量化过程中引入一定程度的精度损失。PTQ特别适合需要大幅度压缩模型的场景。对于通常包含数十亿参数的 LLMs 来说,量化感知训练(QAT)的训练成本过高,PTQ 因此成为一种更实际的替代方案。缺点是精度的损失会比较的大。目前量化在大模型领域的实践中,我们发现 PTQ 在 4bit或8bit 以及以上还行,但是再往下量化效果就不太行了,精度损失比较大。
QAT:
在量化感知训练(QAT)中,量化过程被无缝地集成到大型语言模型(LLMs)的训练中,使这些模型能够适应低精度表示,在量化处理时保持其原始的输出分布,确保性能损失最小化,从而减轻了精度损失。因为通常涉及整个模型的重新训练,通常需要大量的训练数据和计算资源,这对QAT的实施构成了潜在的瓶颈。不幸的是,当前最好的低于8比特的PTQ方法也会导致模型质量急剧下降。因此,对于更高的量化水平,人们发现有必要使用量化感知训练(QAT)。在本文我们介绍下量化技术中的量化感知训练QAT(Quantization-Aware Training) 。
二、Quantization-Aware Training (QAT)
2.1 QAT的原理
当前针对LLM的QAT方法分为两类:全参数重新训练和参数-高效再训练。
-
全参数重新训练是一种在量化LLM时对LLM进行完整的参数重新训练的方法,通过使用数据生成方法以及QAT和蒸馏技术,这样可以保留原始模型的涌现能力,同时减少内存使用和计算量。
-
参数-高效再训练是指采用参数高效的方法重新训练LLM。其中,QLoRA和QA-LoRA[4]提出了将组量化集成到QLoRA中,缓解量化与低秩适应之间的不平衡问题。此外,还有如冻结量化指数并仅微调量化参数、使用二进制量化等。这些方法在具有相对可接受的计算预算下,采用低秩适应来重新训练量化LLM。
PTQ中模型训练和量化是分开的,而QAT则是在模型训练时加入了伪量化节点, 通过在模型训练过程中模拟低精度计算(如 8 位整数计算)来减少推理阶段的精度损失。QAT 的核心思想是让模型在训练过程中意识到量化带来的误差,以便更好地适应量化后的环境。
在量化感知训练过程中,模型的权重和激活在前向传播时会被模拟量化,而反向传播时则继续使用高精度的浮点数进行梯度更新。这种方法既能保持训练的精度,又能让模型意识到推理阶段量化带来的误差,从而在反向传播中对权重的优化过程中进行误差补偿。
QAT 往往比 PTQ 更精确,因为在训练过程中已经考虑了量化。在训练过程中,引入了所谓的“伪”量化(fake quants)。这是指首先将 weights 量化为例如 INT4,然后再反量化回 FP32 的过程, 此过程允许模型在训练期间考虑量化过程、损失计算和weights更新。

QAT的流程归总如下:
-
首先在数据集上以FP32精度进行模型训练,得到训练好的baseline模型;
-
在baseline模型中插入伪量化节点,得到QAT模型,并且在数据集上对QAT模型进行finetune;
-
伪量化节点会模拟推理时的量化过程并且保存finetune过程中计算得到的量化参数;
-
finetune完成后,使用3步骤 中得到的量化参数对QAT模型进行量化得到INT4模型,并部署至推理框架中进行推理。
-
QAT方式需要重新对插入节点之后的模型进行finetune,通过伪量化操作,可以使得网络各层的weights和activation输出分布更加均匀,相对于PTQ可以获得更高的精度。
伪量化节点
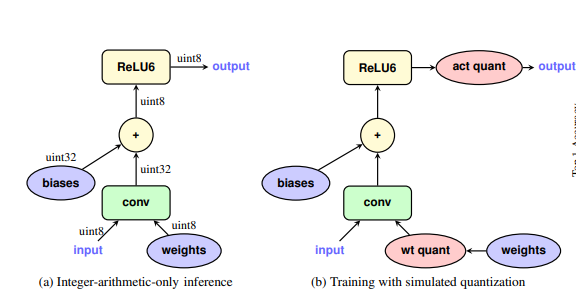
那么什么是伪量化呢?伪量化实际上是quantization+dequantization的结合,实际上就是模拟量化round引起的误差,上图中的fake quants 的这个过程。
伪量化的操作看起来输入输出没变,但是实际上在其中模拟了量化round操作,将这种误差当做一种训练的噪声,在QAT finetune的同时,模型会去适应这种噪声,从而在最后量化为INT8时,减少精度的损失。
伪量化节点插入位置就是需要进行量化操作的位置,在weights输入conv之前(weight quantization)以及activation之后(activation quantizaion)插入了伪量化节点,QAT训练时所有计算都使用FP32单精度。如下图所示:
下面的公式是一个量化的举例说明示例:
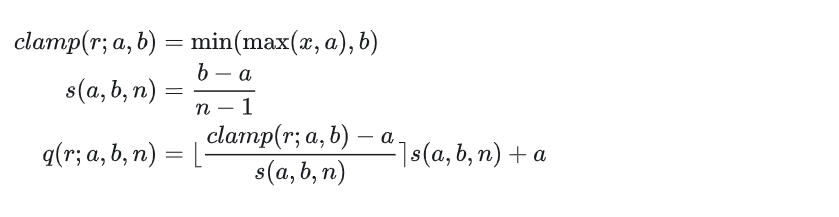
伪量化节点会保存finetune过程中的量化参数,伪量化节点的计算公式中[a, b]即为FP32浮点数值的范围,这个值将会在finetune过程中进行估计与更新,下面介绍伪量化节点weight quantization以及activation quantizaion:
-
对于weight quantization的量化节点,直接将a, b 设置为weights的最小值与最大值即可,即 a=min_w , b=max_w ;
-
对于activation quantizaion,处理方式类似于batch norm,使用了指数移动平均,在finetune的每个batch动态地更新 [a, b];
这个是指数移动平均的一般实现:

最后量化模型的时候,得到了缩放系数和量化零点值。
为什么伪量化能减少误差
假设模型损失函数是 L(θ,x),其中 θ 是模型的权重,x 是输入。在量化感知训练中,前向传播会引入量化误差 ϵ,因此损失函数变为:
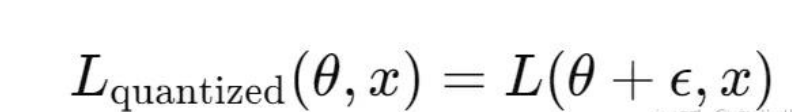
这个损失函数不仅仅依赖于模型参数 θ 本身,还依赖于由量化误差 ϵ 引入的偏差。
反向传播阶段,模型通过高精度的浮点数权重 θ 来计算梯度并更新weights。此时,损失函数的梯度计算会涉及量化误差。
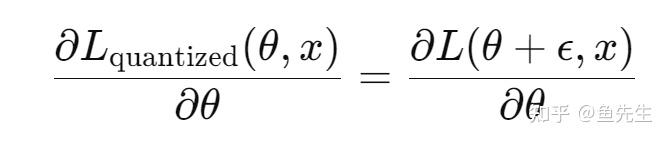
由上式可知,通过调整权重,模型使其在量化误差 ϵ 存在的情况下对输出影响最小。换句话说,即 QAT 让模型在优化过程中学习,如何在这些误差存在的情况下进行自我调整,使模型最终能够适应量化误差,从而在推理阶段的低精度环境下表现更好。
QAT量化的挑战和优化思路
使用QAT量化LLM在几个主要方面面临挑战:
-
对数据要求高。如果训练数据域太窄或者与原始预训练数据分布存在显著不同,则可能会损害模型的性能。
-
对算力要求高。大模型的训练对于算力资源要求比较集中,通常需要大量的训练数据和计算资源。
-
由于LLM训练及其复杂,因此,很难准确地复现原始的训练设置。
因此针对目前的QAT的量化方法,优化点或者说突破点主要就是如下两点:
减少数据需求
为了减少数据需求,LLM-QAT引入了一种无数据的方法,利用原始FP16的大模型生成训练数据,然后利用预训练模型生成的结果来实现无数据蒸馏。具体来说,LLM-QAT使用词表中的每个token作为生成句子的起始token。基于生成的训练数据,LLM-QAT应用了基于蒸馏的工作流来训练量化的LLM,以匹配原始FP16大模型的输出分布。
减少计算量
为了减少计算量,许多方法采用高效参数微调(parameter-efficient tuning,PEFT)策略来加速QAT。
-
QLoRA[3]将大模型的权重量化为4位,随后在BF16中对每个4位权重矩阵使用LoRA来对量化模型进行微调。
-
LoftQ[5]指出,在QLoRA中用零初始化LoRA矩阵对于下游任务是低效的。作为一种替代方案,LoftQ建议使用原始FP16权重与量化权重之间差距的奇异值分解(Singular Value Decomposition,SVD)来初始化LoRA矩阵。LoftQ迭代地应用量化和奇异值分解来获得更精确的原始权重近似值。
-
PEQA是一种新的量化感知技术,可以促进模型压缩并加速推理。它采用了双阶段过程运行。在第一阶段,每个全连接层的参数矩阵被量化为低比特整数矩阵和标量向量。在第二阶段,对每个特定下游任务的标量向量进行微调。这种策略大大压缩了模型的大小,从而降低了部署时的推理延迟并减少了所需的总体内存。 同时,快速的微调和高效的任务切换成为可能。
后面我们看下经典的论文来对这些技术进行了解学习。
三、附录
[1 ]S.-y. Liu, Z. Liu, X. Huang, P. Dong, and K.-T. Cheng, “Llm-fp4: 4-bit floating-point quantized transformers,” in The 2023 Conference on Empirical Methods in Natural Language Processing, 2023.
[2] L. Li, Q. Li, B. Zhang, and X. Chu, “Norm tweaking: Highperformance low-bit quantization of large language models,” arXiv preprint arXiv:2309.02784, 2023.
[3] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,” Advances in Neural Information Processing Systems, vol. 36, 2024.
[4] Y. Xu, L. Xie, X. Gu, X. Chen, H. Chang, H. Zhang, Z. Chen,X. Zhang, and Q. Tian, “Qa-lora: Quantization-aware lowrank adaptation of large language models,” arXiv preprintarXiv:2309.14717, 2023.
[5] Y. Li, Y. Yu, C. Liang, P. He, N. Karampatziakis, W. Chen, and T. Zhao, “Loftq: Lora-fine-tuning-aware quantization for large language models,” arXiv preprint arXiv:2310.08659, 2023
[6] Quantization and training of neural networks for efficient integer-arithmetic-only inference
[7] BitNet: Scaling 1-bit Transformers for Large Language Models https://arxiv.org/pdf/2310.11453