RAG基本原理
1.RAG全称是Retrieval-Augmented Generation
Generation 的含义是 基于用户的输入,生成具有上下文含义的一段文字。
Query 比如说 太阳系中,哪个行星拥有的卫星数目最多?
回答Answer 木星,木星目前有79个卫星
这样的回答存在两个问题,1.无法追溯知识来源 2.可能会存在信息过时的问题(随着科学技术的进步,可能很多没有被发现的卫星被人类发现,或者说 另一个行星的卫星数目更多,这样以往的回答就失去了正确性)
但是实际答案发现这也是错误的信息,因为木星实际上是用有卫星最多的行星,截止到目前为止
参考链接:美国航天局
Deepseek尝试,发现Deepseek也同样给出了错误的回答,因此我认为RAG是一项非常重要的技术。
2.RAG实现流程
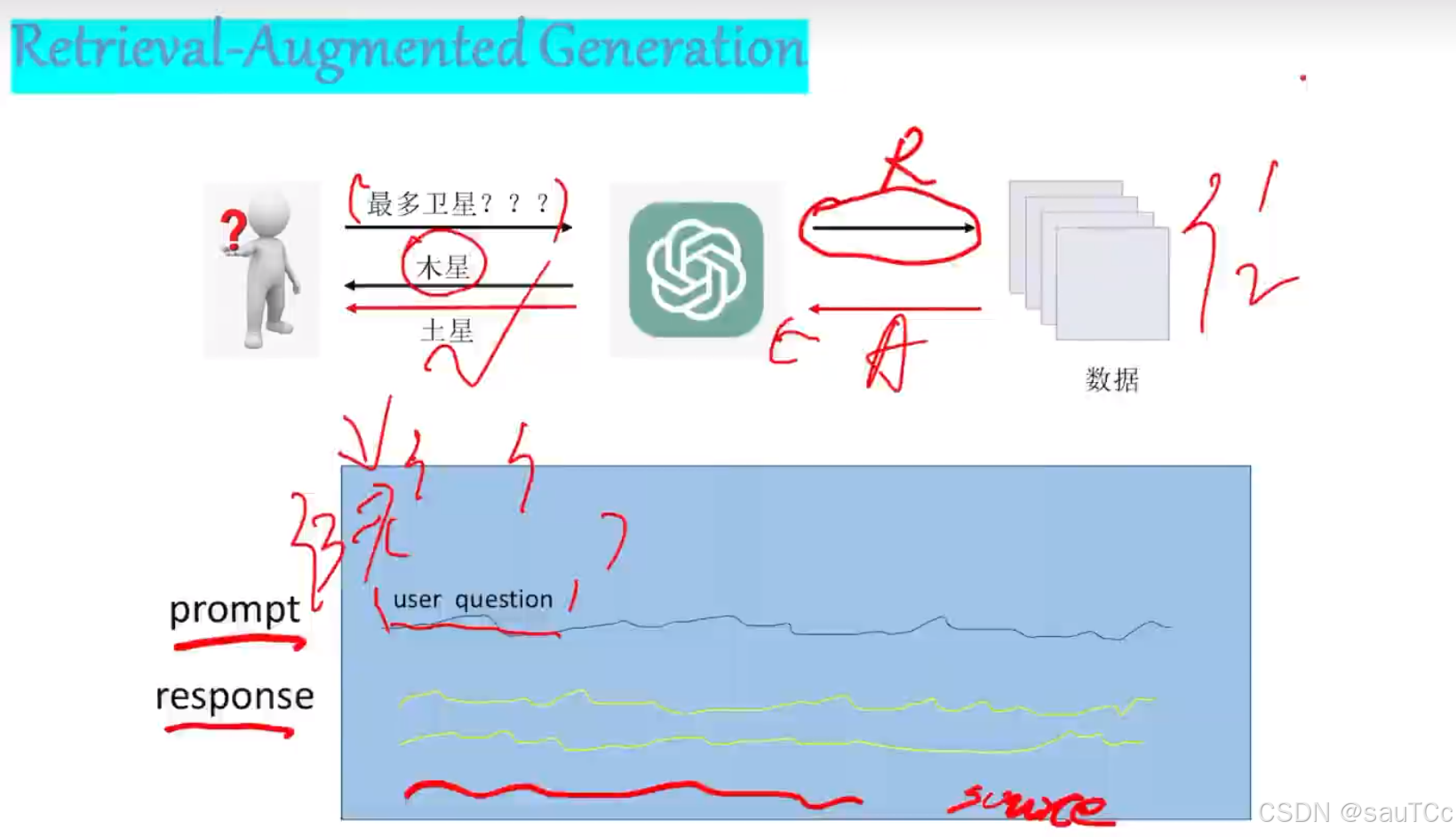
如上图所示,原本我们输入Prompt给大模型,然后大模型返回输出的response给我们,但是大模型中如果没有相关知识,或者相关知识存在歧义,那我们就很容易得到错误的回答。但是我们增加了检索增强的内容给大模型,大模型自身的逻辑推理能力,会输出source输入相关内容,有利于提高答案的准确性,提高生成内容的质量。简单的来说,RAG就是为了让大模型有更好的输出。
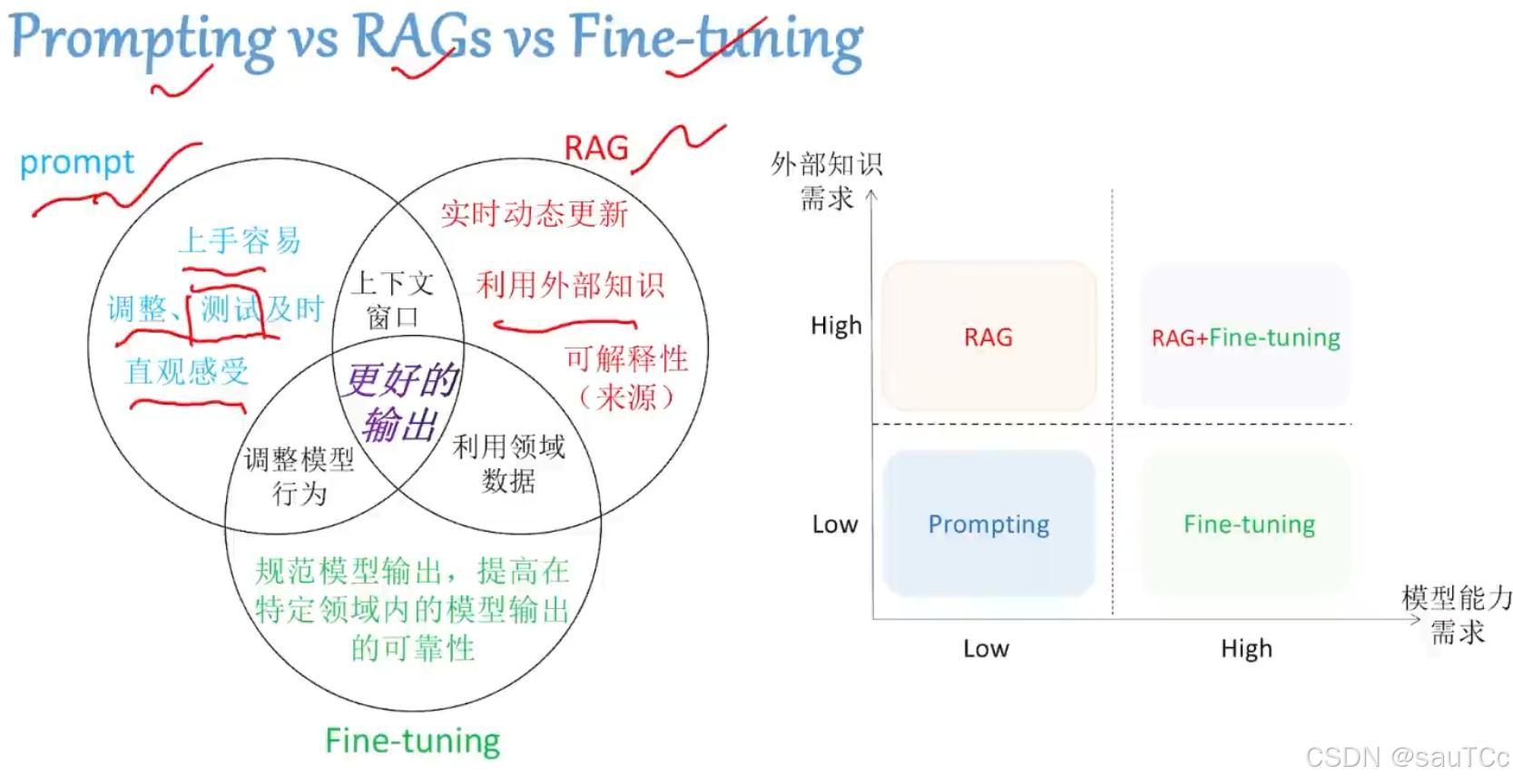
| Prompt工程 | RAG | Fine-tuning |
|---|---|---|
| 定义:提供给大模型的输入即为Prompt,基于此输入,LLM生成响应 | 定义:将Prompting工程与数据库查询结合起来,以获取上下文丰富的答案 | 定义:使用特定任务的数据调整LLM的参数,以使其在某个领域更加专业化 |
| 用途:通过提供精炼的输入来引导模型的输出,生成的输入也是基于大模型现有的知识 | 用途:生成的输出将会基于数据库中可用的知识,从而实现更具上下文的相应 | 用途:可以在特定领域上对语言模型进行Fine-tuning,使其更擅长大模型在该领域的应用 |
3.Prompting vs Fine-tuning vs RAGs
参考引用资料:链接