秋招笔记-8.9
这个是九号写的内容,当时急着面试就忘发了。
今天我们专注在项目上:
Recast Navigation优化
如何优化A星算法?
A星算法的优化老生常谈,哪怕是之前的笔记中我也说过一两次了,我们这里再系统性地梳理一下。
要优化A星算法首先要明白A星算法由哪些部分组成:
首先对输入参数进行校验和初始化,然后清空节点池和open list(优先队列),将起点节点加入open list,并初始化总代价(cost+heuristic)。在主循环中,每次从open list中取出总代价最小的节点(即当前最有希望到达终点的节点),如果该节点就是终点,则寻路结束;否则遍历所有与当前节点相邻的多边形(即可达的下一个区域),对每个邻居节点,先进行有效性和可通行性检查,再计算从起点到该邻居的实际代价(cost)和到终点的启发式距离(heuristic),两者相加得到总代价。如果该邻居节点已经有更优的路径,则跳过,否则更新其父节点、总代价等信息,并将其加入open list。整个过程中,算法会不断记录距离终点最近的节点,以便在找不到完全路径时返回最优近似路径。最终,算法通过回溯父节点链表,输出一条从起点到终点的最优路径。
首先,针对较大的场景,我们可以采取分层A星寻路,具体来说就是我们先实现基于Tile的A星寻路确认可能经过的Tile,然后再在这些Tile中去做细致的A星寻路;然后我们还可以采取双向A星寻路,也就是同时维护两个开放队列,从起点和终点都发起寻路,当两边的路径发生重合就可以算作寻路成功;针对开放队列,默认的数据结构是二叉最小堆,我们在特定的情况可以使用斐波那契堆或者桶队列这样的数据结构来优化时间复杂度;我们还可以去优化搜索邻居的算法,比如一般搜索邻居都是有一个默认的顺序(上下左右),这天然地赋予了一些方向额外的权重,我们可以去给每个方向一个随机数,每一次搜索邻居时都随机从某个方向开始,又或者我们针对可以走斜线的网格使用跳点搜索,可以减小需要搜索的邻居的数量;我们当然还可以去优化启发式函数,比如我们希望少走一些拐点,那么我们就可以在启发函数相关的计算中额外写一个判断判断是否有拐点,有的话我们就提高代价的值即可。
如何改进路径平滑算法和避障算法?
关于路径平滑,我们首先要明确一点的是,Recast Navigation是有相关的算法的,叫做漏斗算法。这个算法会将多个点转换成一条折线,但是显然折线看起来没有那么“聪明”,所以可以尝试去把这个折线修改为一条曲线——怎么做呢?很简单,我们学习过的贝塞尔曲线可以帮助我们实现这个功能。
这里大致介绍一下漏斗算法和贝塞尔曲线的底层原理:
关于漏斗算法:
给定一条多边形路径(即A算法输出的多边形序列),我们把每两个相邻多边形的公共边(交界线)提取出来,得到一系列线段,每个线段有两个端点,分别称为左点和右点。算法从起点出发,维护当前路径的apex点(即当前路径的拐点),并动态维护可行走区域的最左点和最右点。遍历所有交界线时,判断新的左点是否收紧了可行走区域的左边界(这个判断通常用三角形面积符号(叉积)来实现),若是则更新左点;判断新的右点是否收紧了右边界,若是则更新右点。如果发现新的左点已经跨过了当前右点,说明可行走区域被夹到极限,此时将apex点更新为当前右点,并把这个点作为拐点加入路径,然后重置apex、左点和右点,继续处理后续交界线。反之亦然,如果新的右点跨过了当前左点,也做类似处理。最后将终点加入路径。这样处理后,最终得到的路径是由起点、若干个拐点和终点组成的折线,每一段都保证在NavMesh的可行走区域内,且路径最短、不会穿越障碍。
关于贝塞尔曲线:
首先来介绍de Casteljau算法:如图所示,三个点生成的贝塞尔曲线就叫做二次贝塞尔曲线,我们要画出一条贝塞尔曲线,只需要知道任何在一个范围在(0,1)的t对应的点,这样的点全部组合起来就可以得到我们的贝塞尔曲线。
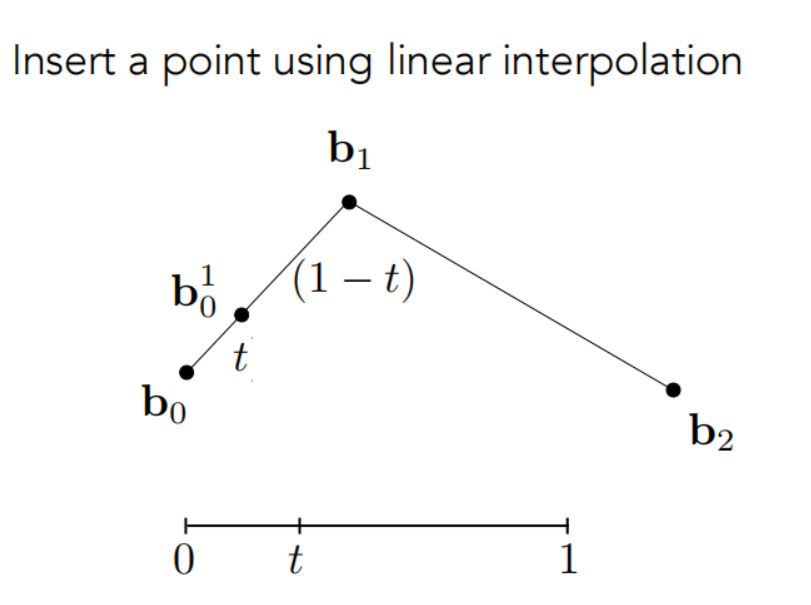
然后我们根据这个t来取两条线段的相对应位置:
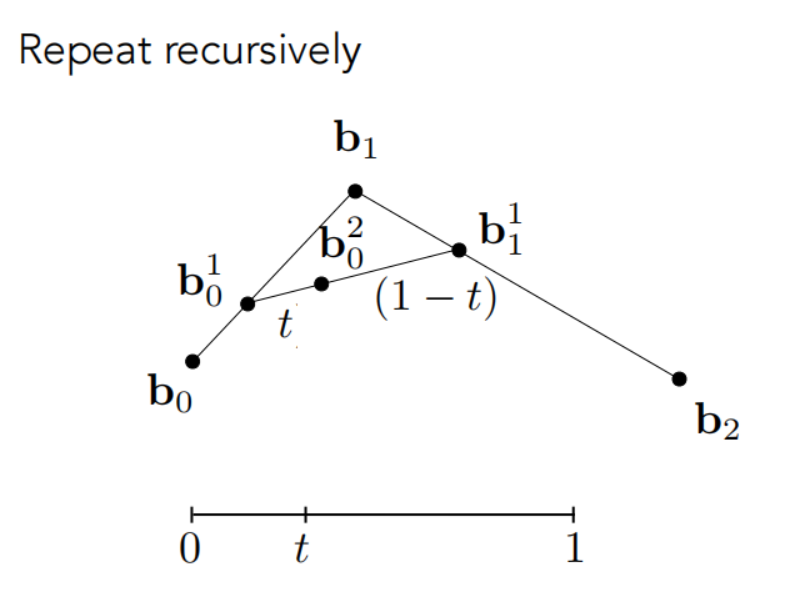
我们在新取的两个点连成的线段上再取这个比例为t的点...
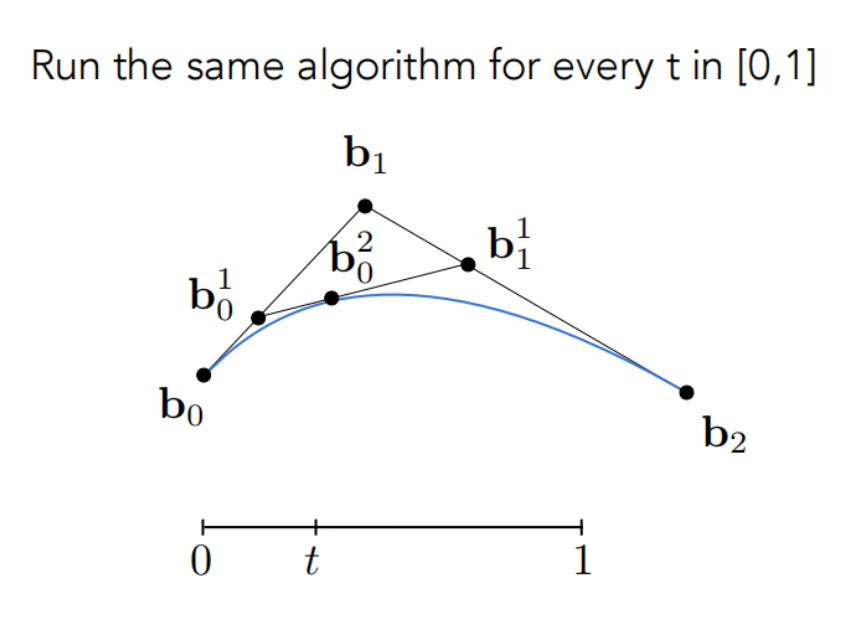
对于三个点,我们只需要取两次点,然后把最后得到的这三个点进行一个曲线的连接即可。
关于避障算法:
项目默认的局部避障算法是:
VO 机制(本项目的 sampleVelocityAdaptive/Grid): 在二维速度空间(vx,vz)内,以预测时间窗T把“会发生碰撞的速度”构成禁区(Velocity Obstacle);对速度圆盘做采样(自适应/网格),丢弃落入禁区的候选,用代价函数(接近期望速度、与障碍距离、安全时间等)选最优速度。实现简单、常数小,但非互惠,密集场景易出现相互“让步”引发振荡。
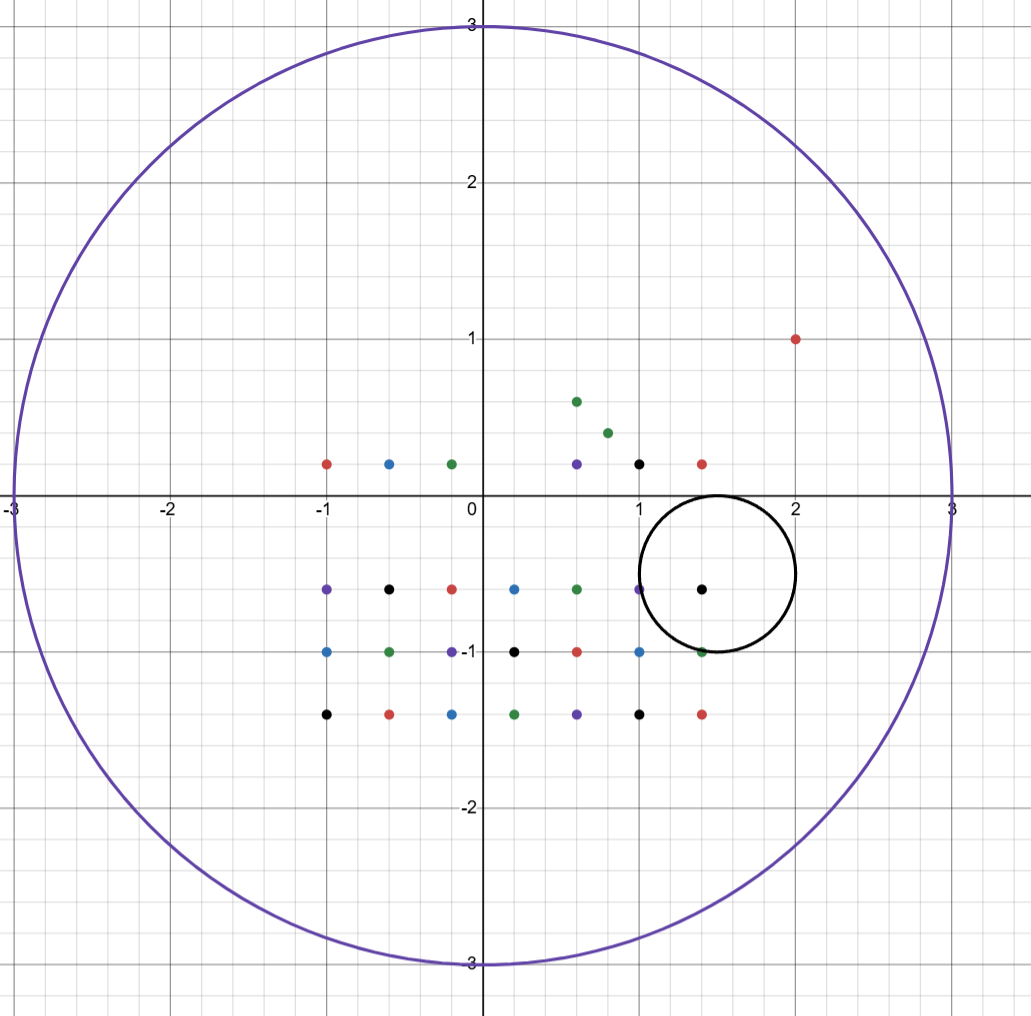
大致的速度空间采样示意图,可以看见有一个大的速度圆盘,这个圆盘的半径是每个agent最大的速度限制,然后内部有一个小圆,这个小圆是可能与检测范围中其他的agent产生碰撞的agent的速度禁区,我们在这个禁区之外去采样一个代价函数相对来说最小的速度即可(离散采样)。
我们对其进行修改后:
ORCA 机制(本项目的 sampleVelocityORCA): 为每个邻居在速度空间构造一条“分离直线”,形成一个半平面,含义是“双方各分担将相对速度移出危险域的一半修正”;把所有半平面取交集得到可行域,然后解一个“距期望速度最近”的2D线性规划(不可行时沿约束边界退化)得到输出速度。互惠对称、收敛更稳,群体表现更自然。
这是ORCA算法的速度空间采样的结果示意图,可以看到速度禁区不再以圆的形式而是以直线的形式出现。
为什么VO和ORCA的速度禁区形状不同?本质是因为两者解决避障问题的建模思路完全不同:VO算法直接从"几何碰撞条件"出发,问的是"哪些相对速度会在时间窗内导致两个圆形agent相撞",这个物理约束在速度空间中天然形成圆形禁区;而ORCA算法从"互惠责任分摊"出发,问的是"如何让双方各承担避让修正的一半",这种线性分摊关系在速度空间中表现为线性约束(直线),因此VO是几何碰撞→圆形禁区,ORCA是线性分摊→线性约束,形状差异直接反映了两种算法哲学的不同。
VO 是“采样+代价最小化”的启发式方法,靠剔除禁区并在剩余点中择优;ORCA 是“解析约束+最优解”,用半平面线性约束直接定义安全速度集合并求最近可行解。前者实现轻、性能常数低但稳定性依赖采样与权重;后者更稳定、抑制振荡,密集人群更优,但约束构建和求解的常数略高。VO算法我们是通过离散采样的但是我们的ORCA是作为一个连续的约束求解。
如何理解NavMesh的全局缓存?怎么实现?
全局路径缓存就是把“常走的多边形路径序列”按起终点与位置量化做成 Key 存起来;命中时直接复用,未命中再寻路并写回;用命中次数+最近访问时间+路径长度决定淘汰,支持落盘与NavMesh变更失效。
我们的全局路径缓存用“哈希表+顺序表”实现:以 `unordered_map<uint64_t, Entry*>` 做 O(1) 查找,`vector<Entry*>` 存放条目便于遍历与淘汰;键是“起点/终点多边形ID”与“起点/终点位置按 `spatialTolerance` 量化后的网格坐标(X、Z)”组合成的 64 位值,以容忍小范围位置抖动;值是路径条目类,包含起终位置、多边形路径序列及长度、命中次数、最近访问时间等;查询时先用键查表,命中则直接拷贝路径并更新统计,未命中则正常寻路后写回;容量超限按优先级(命中对数、时间衰减、路径长度轻权重)淘汰;并支持持久化与在 NavMesh 哈希或容忍度变化时整体失效。
MMORPG
关于TCP+ProtoBuf 网络通信框架,为什么要采用这个网络框架?这个网络框架相比起其他的网络框架来说优点是什么?具体怎么实现?
选择TCP是因为其可靠有序、可全面自定义且更轻量,避免HTTP/WebSocket的握手与帧开销,便于我们按需实现长度前缀、心跳、超时与断线重连等机制以获得更低延迟与更强可控性;选择ProtoBuf是因为其二进制高效(体积小、序列化快)、跨语言强类型且协议可演进(通过.proto定义生成C#类,前后端一致);具体实现上,我们用C# Socket建立TCP连接,采用“4字节长度前缀 + ProtoBuf消息体”的帧格式解决粘/拆包,.proto中定义NetMessage及各业务消息后用protoc生成C#类型,发送侧序列化打包入发送队列,接收侧按长度解包后反序列化并投递到消息分发器分派至各Service处理,网络层用异步IO/线程池提高吞吐,配合定时心跳与超时检测触发自动重连,并以Manager‑Service分层解耦网络与业务逻辑。
如何实现异步消息处理和断线重连?
异步消息处理:客户端在Update()循环里用非阻塞Socket收发数据,收到字节流后交给PackageHandler按长度前缀拆包并反序列化,然后将消息投入MessageDistributer队列,最后分发到各Service处理;服务端用监听器接收连接,NetConnection异步收取数据并交给打包器,MessageDistributer在独立线程池中并发处理业务,从而解耦IO与逻辑避免阻塞。
断线重连:客户端所有异常路径统一走CloseConnection清理状态并触发断开事件,随后由Update()->KeepConnect()自动重试连接(含超时与最大重试次数),若业务在未连接时发消息也会先触发连接,形成自恢复链路。
如何采用模块化架构设计以实现逻辑解耦,构建扩展性强的事件驱动 Manager-Service 分层系统?意义是什么?
Manager层负责资源管理和对象生命周期(如EntityManager管理所有实体、MapManager管理地图实例、ItemManager管理物品池),采用单例模式避免重复创建;Service层负责具体业务逻辑(如UserService处理登录注册、ChatService处理聊天、BattleService处理战斗),通过MessageDistributer订阅网络消息并处理业务逻辑;事件驱动体现在网络消息通过分发器按类型分发到对应Service,Service处理完后通过NetClient发送响应,Manager和Service之间通过事件通知机制解耦。这种设计的意义是提高代码可维护性和扩展性,新增功能只需添加对应Service并订阅消息类型,修改某个模块不会影响其他模块,同时通过对象池和单例模式优化内存使用和性能。
更多详细内容可见以往的MMORPG项目总结。
UE ARPG
如何实现角色、存档、收集和战斗等核心系统?
Animation Budget Allocator、Actor Pooling、PSO 预缓存都是什么?有何作用?如何实现?
Animation Budget Allocator 是 UE 的“动画预算分配”机制,用于在同屏大量骨骼网格时按重要度动态分配 CPU(降低远处/次要角色的骨骼评估频率以避免卡顿);使用时启用插件并在 Project Settings-Animation 勾选 Enable Animation Budget Allocator,设置预算参数(预算毫秒、质量阈值等),让角色网格组件自动注册与重要度评估(Blueprint/C++ 调用 UAnimationBudgetBlueprintLibrary::EnableAnimationBudget、SetAutoRegisterWithBudgetAllocator、SetAutoCalculateSignificance,或配合 USignificanceManager 自定义重要度),即可全局按预算调度动画更新。
Actor Pooling(对象池)是复用高频创建/销毁的 Actor(如子弹、特效)的优化模式:预生成一定数量的对象放入池中,获取时出池,归还时重置并隐藏(SetActorHiddenInGame/SetActorTickEnabled/SetActorEnableCollision),通常用“类名→队列/栈”的映射管理 Acquire/Release,容量不足再懒生成,关卡切换统一回收,可做成 GameInstance/Subsystem 单例服务,显著减少 Spawn/GC 抖动。
PSO 预缓存(Pipeline State Object Pre-caching)是在 DX12/Vulkan 渲染管线中“预先编译并缓存着色器/管线状态组合”,避免运行中首次遇到材质/着色器组合时的卡顿;实现流程是开启管线缓存与记录(控制台变量 r.ShaderPipelineCache.Enabled=1、r.ShaderPipelineCache.SaveUserCache=1),在代表性关卡游玩生成用户缓存并合并为发布用默认缓存(.upipelinecache),启动时设 r.ShaderPipelineCache.StartupMode=3(Precompile)或做 Warmup 资源以热身关键 PSO,从而在运行期直接命中缓存,消除 shader hitch。