SynAdapt:通过合成连续思维链实现大语言模型的自适应推理
摘要:尽管链式思维(CoT)推理能提升模型性能,却因离散 CoT 标记(DCoT)的生成而带来显著时间开销。连续 CoT(CCoT)是更高效的替代方案,但现有方法受限于间接微调、对齐不足或目标不一致。为此,我们提出创新高效的推理框架 SynAdapt:首先合成高质量 CCoT,作为大模型精确且有效的对齐目标,使其直接学会连续推理并给出正确答案;其次,仅凭 CCoT 难以解决难题,SynAdapt 引入难度分类器,结合问题上下文与 CCoT 在简短推理后识别困难样本,再自适应提示模型重新思考,以进一步提升表现。跨不同难度基准的大量实验充分验证了该方法的有效性,在准确率和效率之间实现了最佳平衡。
论文信息
论文标题: "SynAdapt: Learning Adaptive Reasoning in Large Language Models via Synthetic Continuous Chain-of-Thought"
作者: "Jianwei Wang, Ziming Wu, Fuming Lai, Shaobing Lian, Ziqian Zeng"
会议/期刊: "arXiv preprint arXiv:2508.00574v1"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2508.00574v1"
代码链接: ""
关键词: ["连续思维链", "自适应推理", "大语言模型", "效率优化", "难度分类"]
核心要点
SynAdapt创新性地通过生成合成连续思维链(Synthetic CCoT) 作为精准对齐目标,并结合难度分类器动态调整推理策略,在保持高精度的同时显著提升推理效率,实现了准确性与效率的最优平衡。
研究背景:思维链推理的效率困境
近年来,思维链(Chain-of-Thought, CoT) 推理已成为提升大语言模型(LLM)复杂任务解决能力的关键技术。然而,传统离散思维链(DCoT)生成大量自然语言 tokens,导致推理速度慢、计算成本高的问题。为解决这一痛点,连续思维链(Continuous CoT, CCoT) 应运而生,它通过LLM的隐藏状态进行推理,跳过冗余的token生成,理论上能在保持推理能力的同时提升效率。
现有CCoT方法却面临三大挑战:
- 间接微调(Indirect Training):如Coconut通过课程学习逐步替换DCoT,但缺乏显式对齐,导致推理能力损失
- 对齐不充分(Partial Alignment):如CODI仅对齐DCoT和CCoT的最后一个token状态,忽略中间推理过程
- 目标不一致(Incoherent Target):如CompressCoT仅对齐部分"重要token",破坏了推理链的连贯性
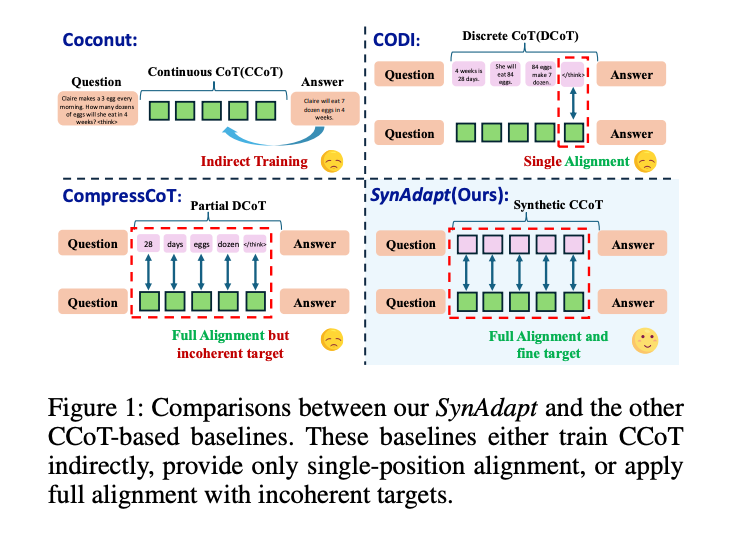
图1:SynAdapt与其他CCoT方法的对比。SynAdapt通过合成CCoT实现完全对齐且目标一致,而其他方法存在间接训练、单一对齐或目标不一致等问题
方法总览:SynAdapt的双阶段自适应推理框架
SynAdapt提出了一个两阶段框架,通过合成CCoT生成和自适应推理策略,同时解决准确性和效率问题。
核心创新点
- 合成连续思维链(Synthetic CCoT):生成高质量连续思维链作为对齐目标,替代传统DCoT
- 动态难度感知:训练难度分类器,根据问题复杂度动态选择推理策略
- 全对齐微调:通过多损失函数优化,实现思维链的完整对齐
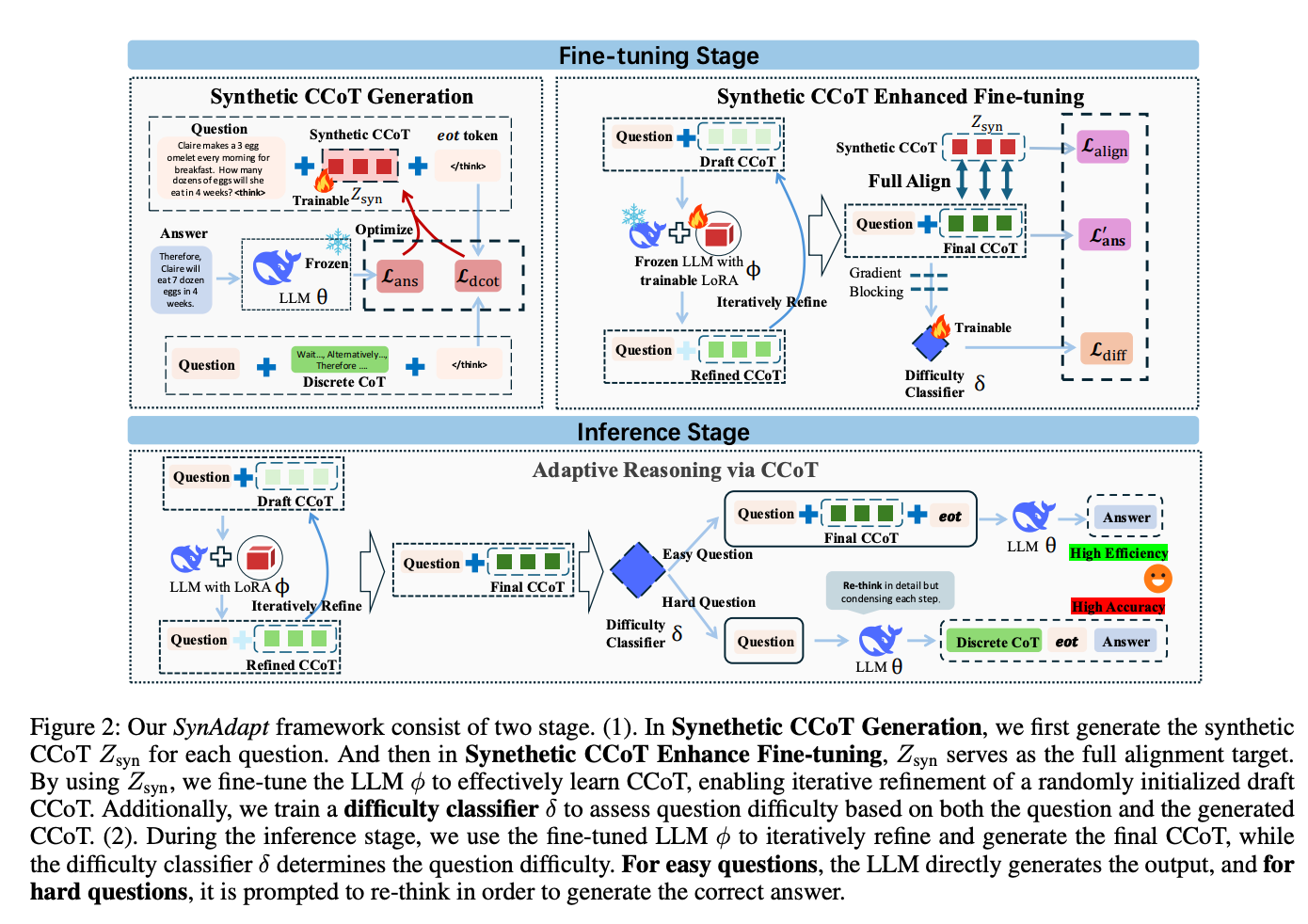
图2:SynAdapt框架分为微调阶段(上)和推理阶段(下)。微调阶段生成合成CCoT并训练难度分类器;推理阶段根据问题难度动态调整推理策略
关键技术解析
1. 合成CCoT生成:精准对齐的基础
SynAdapt首先为每个问题生成合成连续思维链(Z_syn),作为后续微调的"黄金标准"。具体步骤:
- 随机初始化一个长度为m的连续向量Z_syn
- 固定LLM参数,仅优化Z_syn,使LLM能基于问题和Z_syn生成正确答案
- 通过两个损失函数优化:
- 答案损失(L_ans):确保Z_syn引导LLM生成正确答案
- DCoT对齐损失(L_dcot):使Z_syn的隐藏状态与真实DCoT的隐藏状态对齐
这一过程类似为LLM定制"思维导航图",确保模型学习到高效且准确的推理路径。
2. 增强微调:迭代优化思维链
微调阶段采用迭代优化策略,训练LLM将随机初始化的"草稿思维链"(Draft CCoT)逐步优化为与合成CCoT对齐的最终思维链:
- 从无意义的重复token序列初始化草稿思维链
- 通过LoRA模块微调LLM,迭代精炼草稿思维链(默认4轮迭代)
- 多损失函数联合优化:
- 对齐损失(L_align):使最终思维链与合成CCoT对齐
- 答案损失(L’_ans):确保最终思维链能引导LLM生成正确答案
3. 难度分类器:智能任务分诊
为解决简单问题过度推理和复杂问题推理不足的矛盾,SynAdapt训练了一个难度分类器(δ):
- 输入:问题本身和对应的CCoT
- 输出:0-1之间的难度分数
- 训练策略:构造难易问题对,通过对比损失(L_diff)训练分类器
推理时,根据难度分数动态调整策略:
- 简单问题(分数<τ):直接基于CCoT生成答案,追求效率
- 困难问题(分数≥τ):丢弃CCoT,提示LLM重新进行详细推理,确保准确性
实验结果:全面超越现有基线
1. 准确性-效率权衡优势
在五大数学推理基准测试(AIME25、AIME24、AMC23、MATH500、GSM8K)上,SynAdapt展现出显著优势:
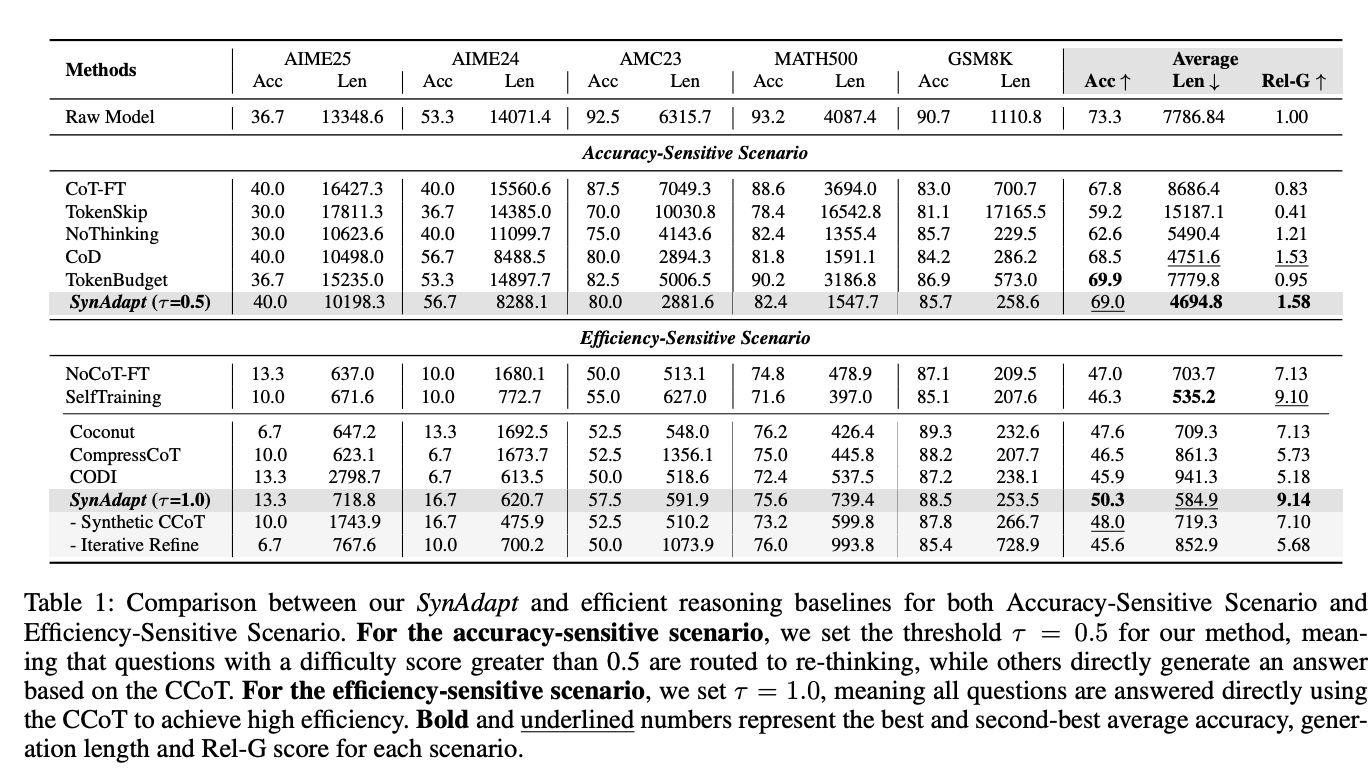
表1:SynAdapt与各基线方法在准确性敏感场景和效率敏感场景的对比
-
准确性敏感场景(τ=0.5):
- 平均准确率达69.0%,与原始模型相当
- 平均生成长度缩短39.7%(从7786.8→4694.8 tokens)
- Rel-G指标达1.58,显著优于CoD(1.53)和NoThinking(1.21)
-
效率敏感场景(τ=1.0):
- 平均长度仅584.9 tokens,比原始模型缩短92.5%
- 准确率保持50.3%,远超Coconut(47.6%)和CODI(45.9%)
- Rel-G指标达9.14,为所有方法最高
2. 准确率-效率权衡曲线
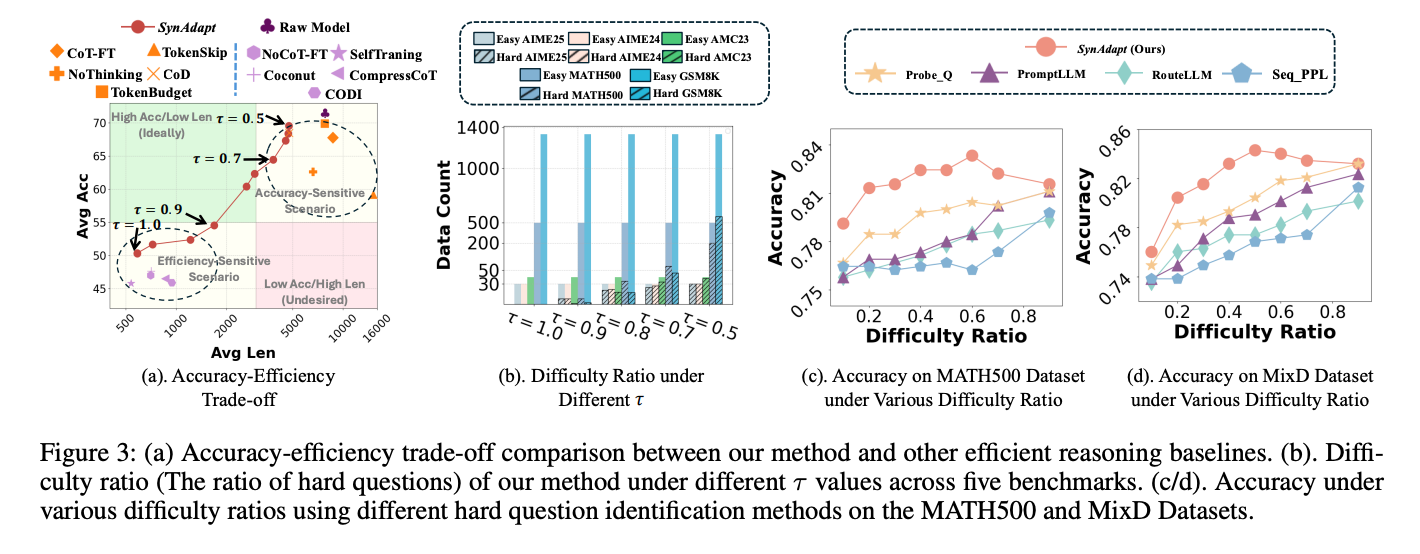
图2:不同方法的准确率-效率权衡曲线。SynAdapt(红点)位于"高准确率-低长度"的理想区域
通过调整阈值τ,SynAdapt可灵活适应不同场景需求:
- τ=0.5时优先保证准确率(适合科研、医疗等高风险场景)
- τ=1.0时最大化效率(适合实时交互、边缘设备等资源受限场景)
3. 难题识别能力
SynAdapt的难度分类器在MATH500和MixD数据集上表现优异:
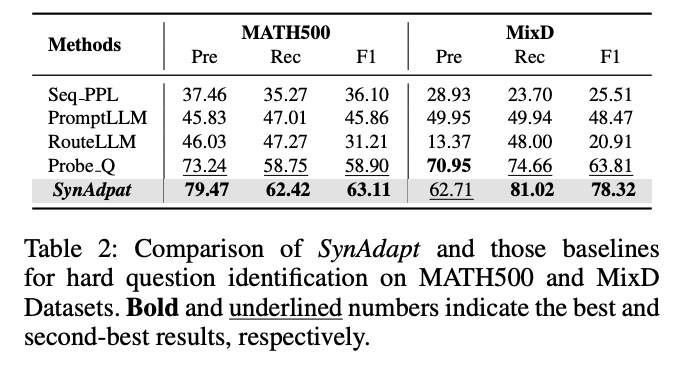
表2:SynAdapt与基线方法在难题识别任务上的对比(F1值)
- 在MATH500数据集上,F1值达63.11,远超PromptLLM(45.86)和RouteLLM(31.21)
- 在MixD数据集上,F1值达78.32,显著优于Probe.Q(63.81)
4. 训练效率分析
尽管增加了合成CCoT生成步骤,SynAdapt的整体训练成本仍具竞争力:
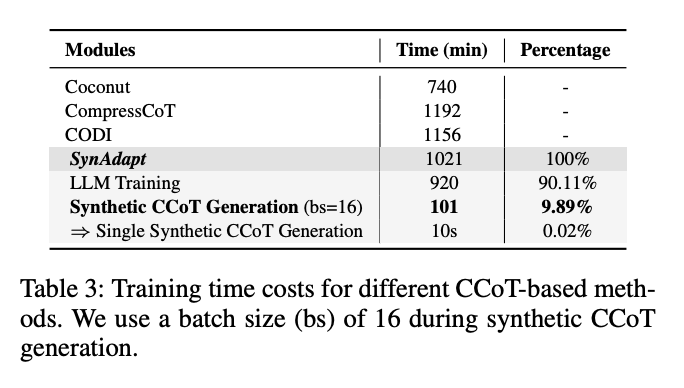
表3:不同CCoT方法的训练时间对比
- 总训练时间1021分钟,仅比CODI(1156分钟)少11.6%
- 合成CCoT生成仅占总时间的9.89%,单条合成CCoT生成仅需10秒
5. 跨模型泛化能力
在不同规模的LLM骨干模型上,SynAdapt均保持稳定优势:
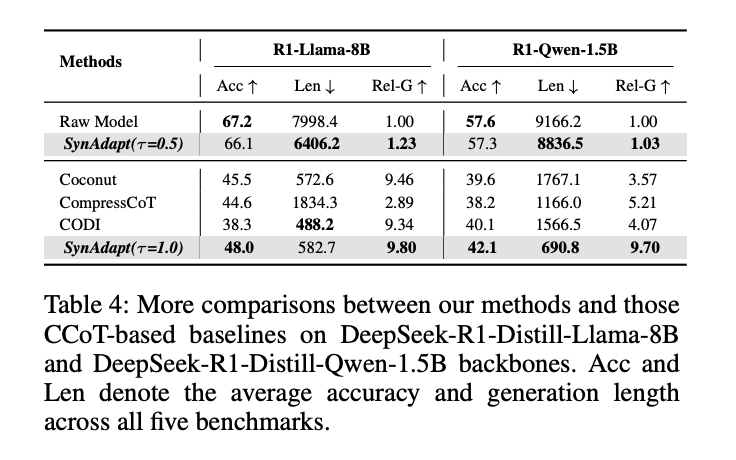
表4:SynAdapt在不同LLM骨干上的表现
- 在R1-Llama-8B上,τ=1.0时Rel-G达9.80,远超Coconut(9.46)
- 在R1-Qwen-1.5B(轻量级模型)上,τ=1.0时Rel-G达9.70,为所有方法最高
实际案例:推理质量对比
以"不同进制转换"问题为例,SynAdapt展现出简洁且准确的优势:
- Coconut:生成冗长推理过程,但答案错误
- CompressCoT:推理简洁但遗漏关键步骤,答案错误
- CODI:推理正确但包含大量冗余内容(768 tokens)
- SynAdapt:仅用47 tokens完成准确推理,实现"又快又好"
未来工作与思考
1. 方法改进方向
- 合成CCoT优化:探索动态长度CCoT,避免固定长度带来的信息浪费或不足
- 多粒度难度分类:当前二分类(难易)可扩展为多级别分类,实现更精细的推理资源分配
- 领域适应:目前主要验证数学推理任务,需扩展到代码生成、逻辑推理等更多领域
2. 实际应用挑战
- 阈值τ的选择:不同应用场景需要不同的τ值,如何自适应调整仍是开放问题
- 计算资源消耗:合成CCoT生成虽高效,但对显存要求较高(尤其长序列)
- 错误传递风险:合成CCoT的质量直接影响后续微调效果,需进一步提升鲁棒性
3. 更广泛的影响
SynAdapt的思想可启发更广泛的研究方向:
- 通用AI效率优化:不仅限于LLM推理,可扩展到多模态模型、强化学习等领域
- 人机协作新模式:难度感知机制可用于动态调整人机分工,提升协作效率
- 边缘设备部署:通过CCoT压缩推理过程,为LLM在边缘设备部署提供可能