数据分析—双十一
电商双11美妆数据分析报告
一、数据清洗与预处理
数据类型识别与统计量计算
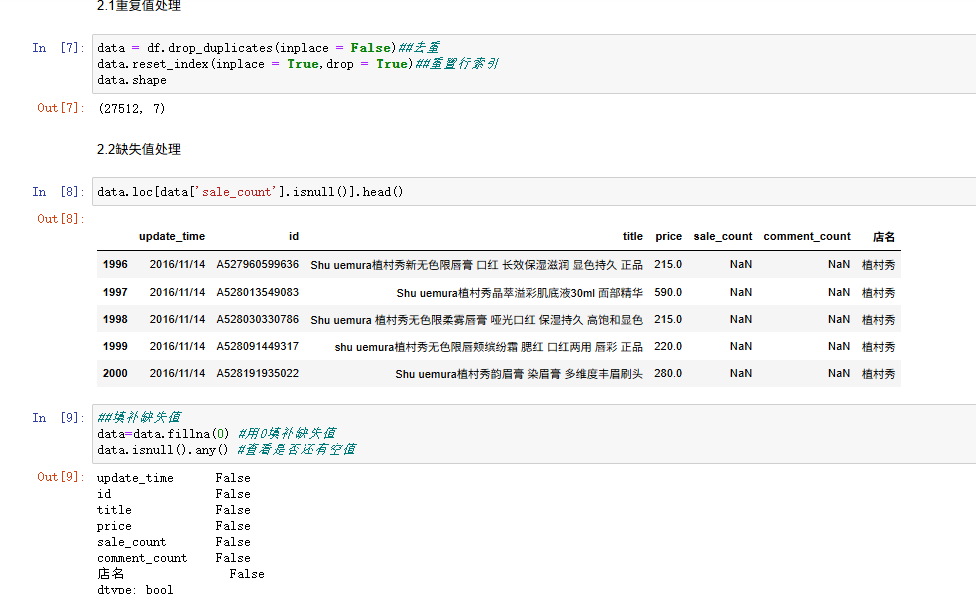
首先识别数据中各列的数据类型,并计算统计量,包括标准差、最小值、最大值、四分位数等,为后续分析提供基础数据支持。处理重复值
检测到数据中共有86条重复记录,将其删除后重置行索引,数据量从27598条减少至27512条,确保数据的唯一性。处理缺失值
发现“销售数量”和“评论数量”两列存在缺失值。经过分析后,决定用零填充这些空值,以保证数据的完整性。
二、数据特征扩充与分析
新增分析维度
销售额:通过“单价 × 销售数量”计算销售额,为分析商品的经济价值提供依据。
品牌分析:从商品标题中提取品牌名,分析不同品牌的销售表现,了解市场占有率和消费者偏好。
产品分类:将产品分为护肤品和化妆品两大类,并进一步细分小类,如护肤品中的眼部护理、面膜等,化妆品中的口红、底妆等,以便更精准地分析市场需求。
价格区间:分析平价产品(0-300元)与贵价产品(>300元)对销量的影响,探究价格与销售的关系。
适用人群:根据商品标题中的关键词,如“男”“女士”等,划分产品适用人群,了解不同性别的消费偏好。
强调通过数据挖掘扩充特征,而非无中生有,例如无法新增“浏览量”字段。
中文分词与文本处理
使用结巴库(jieba)对商品标题(title列)进行中文分词,采用“搜索引擎模式”切分长词语,提高分词的准确性。
创建分类字典,主类分为“护肤品”和“化妆品”,子类进一步细化。通过关键词匹配将分词结果映射到主类和子类,确保关键词覆盖全面,避免分类错误。后续处理逻辑
遍历分词结果,根据分类字典为每条数据标注主类和子类。例如,若标题包含“面膜”关键词,则主类为“护肤品”,子类为“面膜”。对未识别的关键词归类为“其他”,确保数据分析的完整性。新增“是否为男士专用”列,通过关键词筛选(如“男”“男士”且排除“女”“斩男”等)标记男性专用产品。计算销售额(单价×数量),观察到高销售额商品(如面霜)的数值表现突出。
三、数据分析与可视化
品牌分析
相宜本草销量和销售额均领先,但单价亲民(200元以内)。
雅诗兰黛单价最高(>500元),但销量低。
SK-II、玉兰油等品牌商品数量在500-1500件,但销量趋近于零。
价格区间影响
将商品按均价分为A(0-100元)、B(100-200元)、C(200-300元)、D(>300元)四类。分析发现,平价商品(A、B类)销售额占比最高,高价商品(D类)占比最低。品类分析
大类中护肤品占比最高(71.7%),化妆品次之(18.77%)。
小类中清洁类和补水类销量占比最高,修容、眼部护理等占比低。
性别分析
男士专用产品中清洁类(61.54%)和补水类(16.87%)为主。
非男士专用产品品类分布更均衡。
女性消费者贡献81.83%的销量,男性仅占18.16%。
四、结论与建议
平价商品优势
平价商品(尤其是清洁、补水类)更易获得高销售额,建议优先开发性价比高的产品,满足大众消费需求。品类开发建议
针对女性消费者需提供多样化品类,如彩妆、护肤全系列,以满足其广泛需求。
男性产品可聚焦清洁和补水功能,开发针对性强的产品。
可视化优化
可视化需结合分析结论,明确图表服务于业务决策,如定价策略、品类规划等。使用matplotlib绘制柱状图、饼图,通过排序和分组优化图表可读性,强调代码中自适应调整、中文显示等细节设置的重要性。例如,df.groupby('店名')['销售额'].sum().sort_values().plot.bar()用于品牌销售额排序展示。
五、后续方向
探索单价与销量的非线性关系
分析促销活动对单价与销量关系的影响,挖掘潜在的销售增长点。细分品类增长空间
深入分析细分品类(如“眼部护理”)的潜在增长空间,为品类拓展提供数据支持
import numpy as np
import pandas as pd
df = pd.read_csv('双十一淘宝美妆数据.csv')
df.head()
df.info()#数据特征
df.shape
df.describe()数据初步了解:数据集数据数量
示例代码 对数据进行处理,查看数据分布,使得数据更加直观。