Table Foundation Models: on knowledge pre-training for tabular learning(每日一文)
本文我们介绍 TARTE,这是一个基础模型,它使用字符串来捕获语义,将表格转换为知识增强的向量表示。TARTE 已基于大型关系数据进行预训练,其生成的表示有助于后续学习,且几乎无需额外成本。这些表示可以进行微调或与其他学习器结合使用,从而形成能够提升最佳预测性能并改善预测/计算性能平衡的模型。 TARTE 专注于特定任务或领域,提供特定领域的表征,以促进进一步学习。我们的研究展示了一种有效的表格学习知识预训练方法。
研究现状及问题
与神经网络相比,基于树的模型在表格学习方面具有领先优势:它们的归纳偏差与表格数据的属性非常匹配。专用的神经网络架构以及足够大的数据集能够缩小这种差距。表格基础模型有望为中小型数据带来益处。
PFN(先验拟合网络):使用 Transformer 建模上下文。PFN基于众多数据集进行预训练,这些数据集与目标领域(此处指表格学习)相匹配。预测“在上下文中”进行:训练集作为 Transformer 的上下文,Transformer 使用它在前向传播中完成查询。由于预训练需要大量数据集,因此这些数据集必须是合成的,并通过复杂的随机过程计算得出。
对不同的模式和数据语义进行建模:表格基础模型的议程意味着跨表学习和模型复用,从而能够对具有不同“模式”、包含不同信息的列的表格进行建模。对于列数不同的表格,预先训练好的 Transformer 再次发挥作用(即使没有 PFN 的上下文学习),可以从不同数量的输入构建联合表示。更进一步说,模型理想情况下应该利用列的数据语义。例如,两列可能包含数字,但一列是年龄,另一列是体重。捕捉这些语义非常重要,即使只是为了跨表连接相关信息。列名很有帮助。各种基于 Transformer 的模型通过将列名添加到用作输入的数据中来解决跨具有不同列的表的学习问题。同样的,如果没有广泛的预训练,基于Transformer的模型通常不会超过基于树的模型。
大语言模型:通过广泛的预训练捕获大量信息(包括世界知识)的典型模型。它们处理自由流动的文本,不受模式约束,并理解相应的语义。它们可以适应表格,通过将行转换为句子。专门的微调将大语言模型转换为表格学习器。
预训练的文本和数字模型:表格学习不仅需要对字符串进行建模,还需要对数字进行建模,而不是依赖于 LLM 的标记化。CARTE 通过在关系数据上预训练一个带有注意力机制的图转换器,将列名与字符串编码或数字相结合,在小数据集上的表现可靠地优于基于树的模型。然而,这些模型依赖于微调,并且会产生巨大的计算成本。
重复使用表格基础模型:许多视觉语言模型最终被称为“基础模型”,因为它们易于重用,并且可以针对许多特定应用进行专门化。对于表格数据而言,重用和迁移也至关重要,跨具有不匹配列的表建模尤其有用,可以引入具有不同模式的数据。这种易于专业化和重用的特性尚未在表格数据中得到证实。为了充分利用表格基础模型的优势,设计能够轻松针对特定领域或任务进行专业化的模型是当务之急。
方法论
TARTE 是一个易于复用的预训练模型,它通过从大型知识库进行预训练,对异构表的数据语义进行编码。TARTE包含三个主要组件:(1) 基于 Transformer 的架构,通过列和单元格之间的依赖关系对表条目的数据语义进行建模;(2) 利用存储在大型知识库中的丰富背景信息进行知识预训练;(3) 高效的后训练,以便在各种下游表格任务中重用预训练的知识。
基于Transformer的架构
TARTE 基于变压器架构的变体构建将输入数据适当地转换为向量表示,例如 LLM 中的单词标记和位置编码,2)基于自注意力机制的神经架构来捕捉跨输入的复杂依赖关系。
要跨表学习,一个核心挑战是在异构数据集中找到一个通用的表表示形式。尽管行和列的布局结构合理,但表中存储的信息仍然多样且不协调。表格表示的信息具有不同的列数、数据类型(例如,数值型或离散型)和命名约定(例如, France 或 FR)。
TARTE 借鉴了 Kim et al. (2024) 的列–单元格 (E–X) 对建模方法,但放弃了图结构。图 1 展示了将表格条目转化为 Transformer 输入的过程。对于具有 k 列且包含多种数据类型的表格,第 i 行可表示为![]() ,并将所有组价映射到相同维度d(对于列名,以及不同的数据类型做不同的处理):
,并将所有组价映射到相同维度d(对于列名,以及不同的数据类型做不同的处理):

语言模型使 TARTE 能够处理开放词汇,无需对字符串条目进行人工处理,从而绕过复杂的列或实体匹配问题,并实现跨表的数据语义建模。
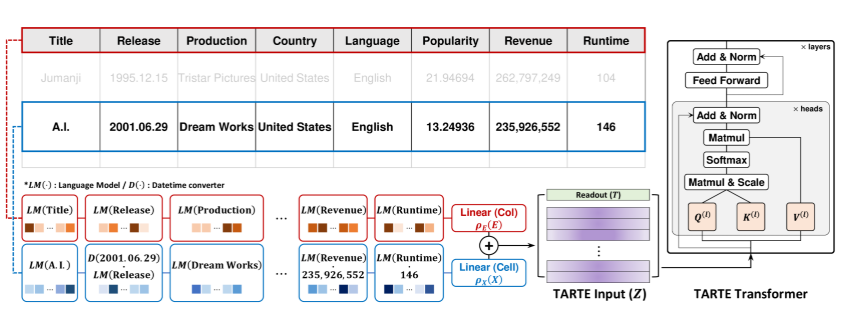
为了得到第 i 行的 Transformer 输入Zi,将线性映射的列信息ρ(E)与单元格信息ρ(X)相加,再在顶部添加一个可学习的读出向量T(d维):
![]()
其中ρ(⋅)=Linear(ReLU(LayerNorm(⋅))),T类似于BERT中的[CLS]token,处理后输入Z送入基于编码器的Transformer,采用多头自注意力和前馈网络模块。
来自大型数据库的知识预训练
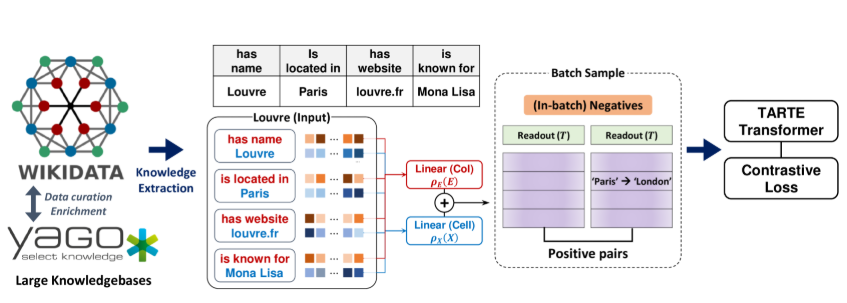
预训练数据
为了捕捉表格知识,需要多样化的表格数据进行预训练。TARTE 将两个大型知识库结合起来:YAGO4.5(Suchanek et al., 2024)和 Wikidata(Vrandečić 和 Krötzsch, 2014)。YAGO4.5 是 Wikidata 的清理版本,结构更简化、便于自动推理,但数值信息较少。为了弥补这一不足,研究从 Wikidata 补充了丰富的数值事实(数值和日期)。最终数据集包含 550 多万个实体、3000 万个事实、687 种不同关系。
数据预处理
知识库数据为三元组 (h, r, t),分别表示头实体、关系和尾实体,例如 “卢浮宫位于巴黎” 表示为 (“Louvre”, “is located in”, “Paris”)。对不同数据类型(字符串、数值、日期时间)分别处理:
字符串:用 FastText 构建查找表嵌入(表格中的文本通常很短,LLM 不适用);
数值和日期时间(转为分数年份):采用关系级的幂变换。
批采样与对比损失
每个批次先随机选取 Nb 个实体,提取其相关事实,并截断到统一列数。正样本通过替换部分事实(如“巴黎”替换为“伦敦”)生成。使用对比学习框架,批内其他实体作为负样本,采用高斯核相似度与 InfoNCE 损失。
模型规模
Transformer 使用 3 层自注意力、每层 24 个多头注意力、隐藏维度 768、前馈层 2048 维。对比学习投影层为两层线性,隐藏和输出维度分别为 2048 和 768,整体参数量 2500 万以上。
使用主干模型进行学习:微调或冻结,与另一个模型结合
任务微调
将对比学习的投影层替换为三层 ρ(⋅)结构,Transformer 层参数冻结,端到端训练。采用 Bagging*(什么是bagging策略:从原始训练集随机有放回地抽取多个子集(bootstrap samples),在这些不同的子集上分别训练多个模型,然后将它们的预测结果进行平均(回归)或投票(分类)。)策略,多模型在不同训练-验证划分上训练并平均预测结果。
冻结骨干作为表格特征提取器
类似于 Sentence-BERT,TARTE 可生成表格条目的嵌入向量。冻结骨干,将读出向量 T(前文提到的类似于CLS的token) 的嵌入作为特征输入任意机器学习模型进行预测。
提升补充模型
隐含的先验信息在与互补的表格模型适当结合时仍然有用。为了配合先验表格模型,制定了一个 boosting 策略:将包含原始表的基础表格模型与一个模型集成,该模型可以拟合包含 TARTE 嵌入特征的基础模型的(训练)残差。为了提高效率,我们将 TARTE 与岭回归结合使用。
领域转化
利用 TARTE 的特征提取器能力,可避免代价高昂的跨表联合学习。先从相关领域表格的微调模型中提取嵌入,再通过boosting策略融入领域专用预测,实现多步提升。
实验设计及结果
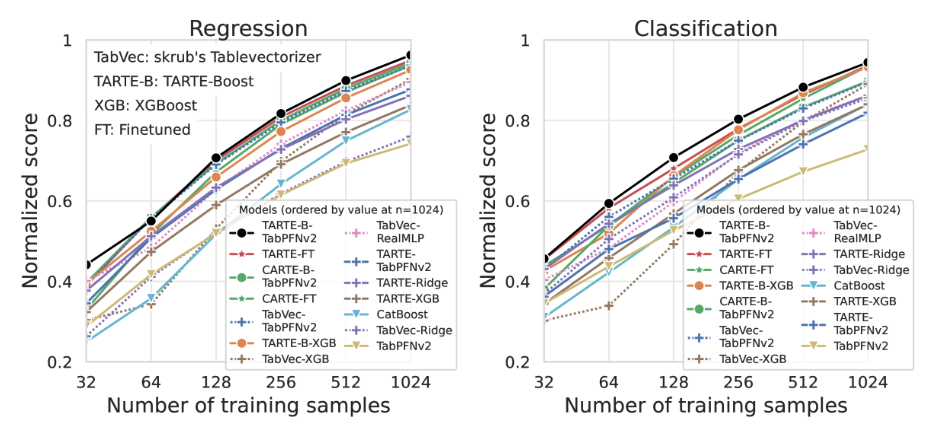
Normalized score 表示不同模型在多个数据集不同训练规模下的性能归一化指标。总体的性能都是随训练样本数增加而提升。TARTE 的知识预训练 + 合理后训练策略(Boosting / Fine-tuning) 在小样本场景下能显著提升性能,且在回归与分类两类任务中均成立。
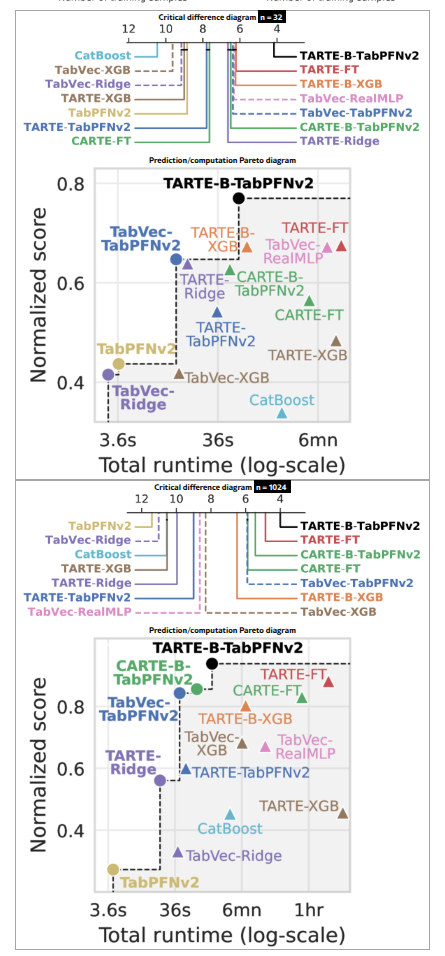
训练样本数在32和1024时,模型的平均排名差异,以及性能与耗时的关系。

消融架构、预训练和预处理组件。
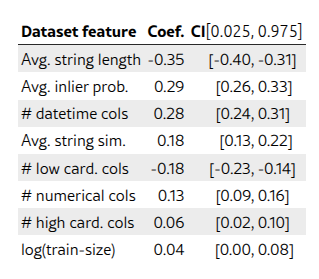
线性模型的系数及其置信区间解释了 TARTE-Ridge 在各个数据集上相对于 TabVec-Ridge 的改进(R 平方:0.22)。负值表示相应元特征的值越大,TARTE 的改进效果越小。长字符串的性能下降表明语言模型 FasText 存在局限性。内点概率的重要性表明需要进行预训练才能很好地覆盖下游术语。