Oracle自动采集AWR Gets TOP SQL脚本
一、背景
最近在做一个Oracle数据库优化专题,这是一个即将迁移到OceanBase的系统,其他营账核心库都迁移完成,该系统迁移评估中CPU使用率、系统负载有点高,需要将Oracle一个系统的负载降低到30-40左右。
其中有三个方案:
1)将3-3-3的OB集群扩展成4-4-4;
2)分库,将一部分业务迁移出去;
3)优化TOP SQL降低Oracle负载;
本问主要讲第三点:优化TOP SQL降低Oracle负载 中如何自动化、定时地采集高逻辑读的TOP SQL。
按top排序可以是最高耗时,最高cpu,逻辑读、物理读、执行次数,作为一个OLTP的数据库常为IO密集型,资源消耗往往消耗在IO上频繁的单块、多块读写,索引访问上,所以逻辑读次数较高的SQL很可能是性能瓶颈的根源,尤其是在负载较高的系统环境下,定位并优化这些SQL可以有效降低系统资源消耗,提升整体性能。
二、需求分析
- 自动定时采集最近15天内的高逻辑读SQL(Buffer Gets TOP SQL)(根据AWR保留周期);
- 按数据库每天的事务数、会话连接数、数据库负载、CPU使用率等指标选取系统最忙的时间段采集,比如白天(08:00-18:00)与夜间(20:00-06:00)时间段,分别采集不同时间段数据,确保覆盖全天负载;
- 支持多实例环境,自动遍历所有实例进行采集;
- 过滤低影响SQL,聚焦占比超过1%的高逻辑读SQL;
- 避免重复采集,保证数据唯一性和完整性;
- 结果存储至自定义历史表,方便后续分析和趋势对比。
三、核心实现脚本设计
脚本通过PL/SQL块实现,核心流程如下:
- 时间段计算与FLAG标记
根据当前日期,循环最近15天。
对于每一天,判断应采集白天段(08:00-18:00,FLAG=1)还是夜间段(20:00-06:00,FLAG=0)。 - 数据存在性检查
先检测该时间段数据是否已经存在,避免重复插入。 - 多实例循环采集
遍历gv$instance,针对每个实例独立采集数据。 - 高效聚合计算
利用AWR视图如dba_hist_snapshot、dba_hist_sqlstat和dba_hist_sqltext,计算逻辑读总量及各SQL的逻辑读占比。 - 筛选与排序
初始优化只插入逻辑读占比超过1%的SQL结果排序存入历史表。
关键代码片段示例
------------- 建表
CREATE TABLE DBMT.GETS_STAT_HIST (INSTANCE_NUMBER NUMBER,INSTANCE_NAME VARCHAR2(100),HOST_NAME VARCHAR2(100),snap_time DATE, -- 对应 t.timeBUFFER_GETS NUMBER,EXECUTIONS NUMBER,GETS_PER_EXEC NUMBER,PCT_TOTAL NUMBER(10,2),CPU_TIME_S NUMBER,ELAPSED_TIME_S NUMBER,SQL_ID VARCHAR2(13),SQL_MODULE VARCHAR2(1000),SQL_TEXT CLOB,FLAG NUMBER -- 日/夜标识等
);-- 解决重复插入问题
ALTER TABLE DBMT.GETS_STAT_HIST ADD CONSTRAINT uq_gets_stat UNIQUE (INSTANCE_NUMBER, SNAP_TIME, SQL_ID, FLAG);set serveroutput onDECLAREv_flag NUMBER;v_begin_time DATE;v_end_time DATE;v_now DATE := SYSDATE;v_day_offset NUMBER;v_exists NUMBER;v_dbid NUMBER;v_target_date DATE; -- 新增目标日期变量
BEGINSELECT dbid INTO v_dbid FROM v$database;FOR v_day_offset IN 1 .. 15 LOOP-- 计算目标日期(过去第N天的00:00)v_target_date := TRUNC(v_now) - v_day_offset;-- 根据目标日期的时段设置时间段(非当前时间)IF TO_CHAR(v_target_date + 12/24, 'HH24') BETWEEN '06' AND '18' THEN -- 目标日中午12点代表白天v_flag := 1; -- 白天段v_begin_time := v_target_date + 8/24; -- 目标日08:00v_end_time := v_target_date + 18/24; -- 目标日18:00ELSEv_flag := 0; -- 夜间段v_begin_time := v_target_date - 1 + 20/24; -- 目标日前一天20:00v_end_time := v_target_date + 6/24; -- 目标日06:00END IF;-- 高效检查记录是否存在BEGINSELECT 1 INTO v_existsFROM DBMT.GETS_STAT_HISTWHERE FLAG = v_flagAND snap_time = TRUNC(v_begin_time)AND ROWNUM = 1;EXCEPTIONWHEN NO_DATA_FOUND THEN v_exists := 0;END;IF v_exists > 0 THENDBMS_OUTPUT.PUT_LINE('已存在记录: ' || TO_CHAR(v_begin_time,'YYYY-MM-DD') || ' FLAG=' || v_flag);CONTINUE;END IF;DBMS_OUTPUT.PUT_LINE('收集时间段: ' ||TO_CHAR(v_begin_time,'YYYY-MM-DD HH24:MI') || ' - ' ||TO_CHAR(v_end_time,'YYYY-MM-DD HH24:MI') || ', FLAG=' || v_flag);-- 遍历每个实例FOR r_inst IN (SELECT instance_number, instance_name, host_name FROM gv$instance) LOOP-- 修复:删除重复的 INSERT 语句INSERT INTO DBMT.GETS_STAT_HIST (INSTANCE_NUMBER, INSTANCE_NAME, HOST_NAME,snap_time, BUFFER_GETS, EXECUTIONS, GETS_PER_EXEC, PCT_TOTAL,CPU_TIME_S, ELAPSED_TIME_S, SQL_ID, SQL_MODULE, SQL_TEXT, FLAG)WITH t AS (SELECT instance_number,MIN(snap_id) beg_snap,MAX(snap_id) end_snap,TRUNC(MIN(begin_interval_time)) AS snap_timeFROM dba_hist_snapshotWHERE end_interval_time >= v_begin_timeAND begin_interval_time <= v_end_timeAND instance_number = r_inst.instance_numberGROUP BY instance_number),total_gets AS ( -- 新增:预先计算总逻辑读避免重复查询SELECT t.instance_number,SUM(e.value - b.value) AS total_logical_readsFROM dba_hist_sysstat b,dba_hist_sysstat e,tWHERE b.snap_id = t.beg_snapAND e.snap_id = t.end_snapAND b.dbid = v_dbidAND e.dbid = v_dbidAND b.instance_number = t.instance_numberAND e.instance_number = t.instance_numberAND b.stat_name = 'session logical reads'AND e.stat_name = 'session logical reads'GROUP BY t.instance_number),gets_stat AS (SELECT sqt.instance_number,sqt.buffer_gets,sqt.executions,ROUND(DECODE(sqt.executions, 0, NULL, sqt.buffer_gets / sqt.executions), 2) AS gets_per_exec,-- 处理除零错误:总逻辑读为0时返回NULLROUND(DECODE(tg.total_logical_reads, 0, NULL, (100 * sqt.buffer_gets) / tg.total_logical_reads), 2) AS pct_total,ROUND(NVL(sqt.cpu_time / 1000000, 0), 2) AS cpu_time_s,ROUND(NVL(sqt.elapsed_time / 1000000, 0), 2) AS elapsed_time_s, sqt.sql_id,TO_CLOB('Module: ' || NVL(sqt.module, 'N/A')) AS sql_module,NVL(st.sql_text, TO_CLOB('** SQL Text Not Available **')) AS sql_text,t.snap_time,-- 新增排序字段ROW_NUMBER() OVER (ORDER BY (100 * sqt.buffer_gets) / tg.total_logical_reads DESC NULLS LAST) AS rnFROM (SELECT sql_id,module,instance_number,SUM(buffer_gets_delta) AS buffer_gets,SUM(executions_delta) AS executions,SUM(cpu_time_delta) AS cpu_time,SUM(elapsed_time_delta) AS elapsed_timeFROM dba_hist_sqlstatWHERE dbid = v_dbidAND instance_number = r_inst.instance_numberAND snap_id BETWEEN (SELECT beg_snap FROM t) + 1 AND (SELECT end_snap FROM t)GROUP BY sql_id, module, instance_number) sqtJOIN t ON t.instance_number = sqt.instance_numberLEFT JOIN dba_hist_sqltext st ON st.sql_id = sqt.sql_id AND st.dbid = v_dbidJOIN total_gets tg ON tg.instance_number = t.instance_number -- 关联总逻辑读WHERE tg.total_logical_reads > 0 -- 忽略无逻辑读的时段)SELECT r_inst.instance_number,r_inst.instance_name,r_inst.host_name,gs.snap_time, -- 直接插入日期类型(非字符串)gs.buffer_gets,gs.executions,gs.gets_per_exec,gs.pct_total,gs.cpu_time_s,gs.elapsed_time_s,gs.sql_id,gs.sql_module,gs.sql_text,v_flagFROM gets_stat gsWHERE gs.rn <= 65 -- 取逻辑读占比最高的65条AND gs.pct_total > 1; -- 过滤低占比SQLEND LOOP;COMMIT;END LOOP;
END;
/收集时间段: 2025-08-10 08:00 - 2025-08-10 18:00, FLAG=1
收集时间段: 2025-08-09 08:00 - 2025-08-09 18:00, FLAG=1
收集时间段: 2025-08-08 08:00 - 2025-08-08 18:00, FLAG=1
收集时间段: 2025-08-07 08:00 - 2025-08-07 18:00, FLAG=1
收集时间段: 2025-08-06 08:00 - 2025-08-06 18:00, FLAG=1
收集时间段: 2025-08-05 08:00 - 2025-08-05 18:00, FLAG=1
收集时间段: 2025-08-04 08:00 - 2025-08-04 18:00, FLAG=1
收集时间段: 2025-08-03 08:00 - 2025-08-03 18:00, FLAG=1
收集时间段: 2025-08-02 08:00 - 2025-08-02 18:00, FLAG=1
收集时间段: 2025-08-01 08:00 - 2025-08-01 18:00, FLAG=1
收集时间段: 2025-07-31 08:00 - 2025-07-31 18:00, FLAG=1
收集时间段: 2025-07-30 08:00 - 2025-07-30 18:00, FLAG=1
收集时间段: 2025-07-29 08:00 - 2025-07-29 18:00, FLAG=1
收集时间段: 2025-07-28 08:00 - 2025-07-28 18:00, FLAG=1
收集时间段: 2025-07-27 08:00 - 2025-07-27 18:00, FLAG=1PL/SQL procedure successfully completed. 后续有权限也可接到定时任务里
-- 06:10 执行:收集前夜间段(FLAG=0)
-- 18:10 执行:收集白天段(FLAG=1)
10 6,18 * * * /path/to/collect_gets_stat.sh >> /path/to/log/gets_stat.log 2>&1四、分析SQL
该脚本取得SQL的逻辑读和AWR报告一致,取20250810早8:00-20250810 18:00的AWR报告,对比查询结果和AWR结果一致。
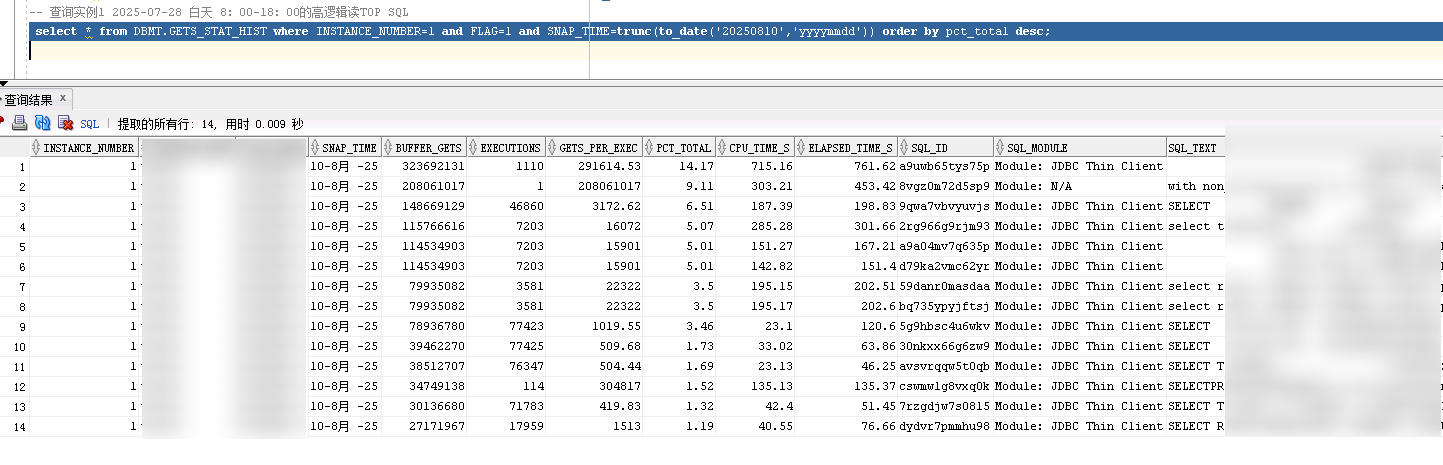
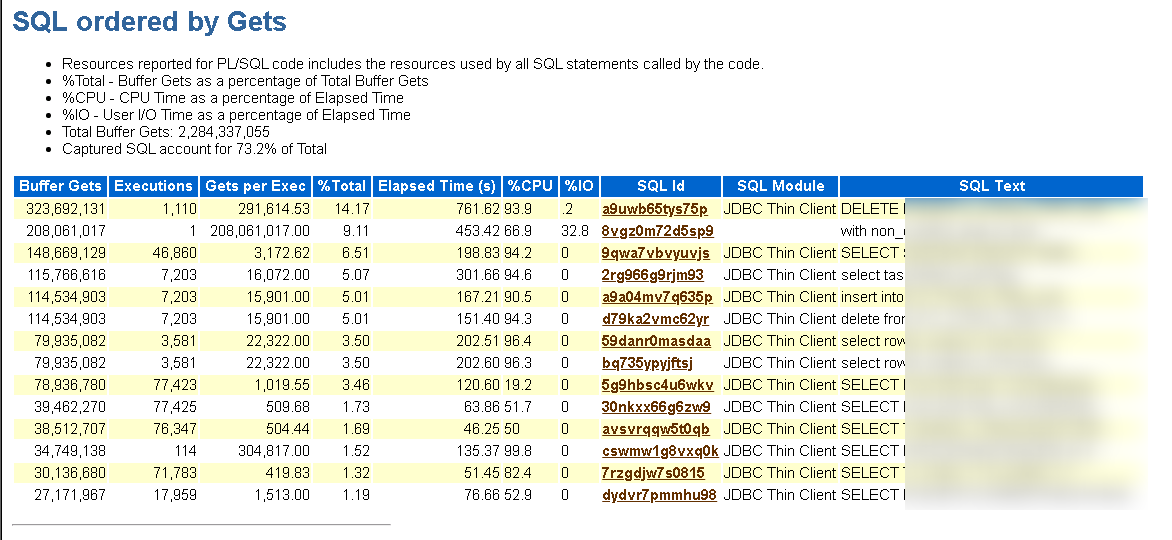
附上SQL分析
-- 根据 sql_id 估算一天产生的逻辑读
SELECT AVG(BUFFER_GETS) * 24 / 10 ,ROUND((AVG(BUFFER_GETS) * 24 / 10 * 8192)/ POWER(1024, 4), 2 ) AS LOGICAL_READ_TB_24H
FROM DBMT.GETS_STAT_HIST WHERESNAP_TIME >= TO_DATE('20250724', 'yyyymmdd')AND INSTANCE_NUMBER = 1AND sql_id = 'cyypmad5n2b1m';-- 查询实例1 2025-07-28 高逻辑读TOP SQLselect * from DBMT.GETS_STAT_HIST where INSTANCE_NUMBER=1 and SNAP_TIME=trunc(to_date('20250728','yyyymmdd'));-- 查询实例1 2025-07-28 白天/夜晚 8:00-18:00/20:00-6:00 的高逻辑读TOP SQLselect * from DBMT.GETS_STAT_HIST where INSTANCE_NUMBER=1 and FLAG=1 and SNAP_TIME=trunc(to_date('20250728','yyyymmdd'));select sum(BUFFER_GETS),sum(EXECUTIONS),sum(CPU_TIME_S),sum(ELAPSED_TIME_S),SQL_ID,COUNT(SQL_ID)from DBMT.GETS_STAT_HIST where SNAP_TIME>=(to_date('20250723','yyyymmdd')) and INSTANCE_NUMBER=1 and FLAG=0group by SQL_IDorder by sum(BUFFER_GETS) desc;-- 查询 20250723至今 实例一白天的TOP SQLselect INSTANCE_NUMBER,SNAP_TIME,BUFFER_GETS,EXECUTIONS,GETS_PER_EXEC,CPU_TIME_S,ELAPSED_TIME_S,SQL_ID,SQL_TEXT,COUNT(SQL_ID) OVER (PARTITION BY SQL_ID) AS SQL_COUNT,SUM(BUFFER_GETS) OVER (PARTITION BY SQL_ID ) AS BUFFER_GETS_TOTALfrom DBMT.GETS_STAT_HIST where SNAP_TIME>=(to_date('20250723','yyyymmdd')) and INSTANCE_NUMBER=1 and FLAG=1order by SQL_COUNT desc,BUFFER_GETS_TOTAL desc ;-- 查询 20250723至今 实例一白天的TOP SQL,每个sql按照BUFFER_GETS大小排序select INSTANCE_NUMBER,SNAP_TIME,BUFFER_GETS,EXECUTIONS,GETS_PER_EXEC,CPU_TIME_S,ELAPSED_TIME_S,SQL_ID,SQL_TEXT,COUNT(SQL_ID) OVER (PARTITION BY SQL_ID) AS SQL_COUNT,SUM(BUFFER_GETS) OVER (PARTITION BY SQL_ID) AS BUFFER_GETS_TOTAL,row_number() over(partition by sql_id order by BUFFER_GETS) rnfrom DBMT.GETS_STAT_HIST where SNAP_TIME>=(to_date('20250723','yyyymmdd')) and INSTANCE_NUMBER=1 and FLAG=0order by SQL_COUNT desc,rn desc在每次分析完sql可以查看sql是否还在TOP里,根据sql分析清单(excel等)插入分析进度
比如:新增status列和dbmt.sqltune_list优化列表
-- status : 0:待优化 1:已建议 2:已分析、无优化空间 9:已优化alter table DBMT.GETS_STAT_HIST add status int default 0; COMMENT ON COLUMN DBMT.GETS_STAT_HIST.FLAG IS 'FLAG=1 :早 08:00 - 晚 18:00 FLAG=0 :晚 20:00 - 早 06:00';
COMMENT ON COLUMN DBMT.GETS_STAT_HIST.STATUS IS '0:待优化 1:已建议 2:已分析、无优化空间 9:已优化';-- 新增优化列表
create table dbmt.sqltune_list(db_name varchar2(20),sql_id varchar2(100),status varchar2(20));
alter table DBMT.GETS_STAT_HIST add status int default 0; insert into dbmt.sqltune_list values('orcl2','0sg6jv5u27cxb','已优化');
insert into dbmt.sqltune_list values('orcl2','7pku4wk5skhbu','已建议');
insert into dbmt.sqltune_list values('orcl1','3bmmahm7duj1m','已优化');
insert into dbmt.sqltune_list values('orcl1','1m0w8j99p8um0','已优化');
insert into dbmt.sqltune_list values('orcl1','07rsrdcyvxwkv','已优化');
insert into dbmt.sqltune_list values('orcl1','3txts3r0v2rrv','已分析、无优化空间');优化时先挑出现频率最高的TOP SQL
-- 查询出现次数最多的TOP SQLselect INSTANCE_NUMBER,SNAP_TIME,BUFFER_GETS,EXECUTIONS,GETS_PER_EXEC,CPU_TIME_S,ELAPSED_TIME_S,a.SQL_ID,SQL_TEXT,FLAG,a.status,b.status,COUNT(a.SQL_ID) OVER (PARTITION BY a.SQL_ID) AS SQL_COUNT,SUM(BUFFER_GETS) OVER (PARTITION BY a.SQL_ID ) AS BUFFER_GETS_TOTALfrom DBMT.GETS_STAT_HIST a left join dbmt.sqltune_list b on a.sql_id=b.sql_id where SNAP_TIME>=(to_date('20250728','yyyymmdd')) and INSTANCE_NUMBER=1 -- and status=0 and flag=1order by BUFFER_GETS_TOTAL desc, SQL_COUNT desc ;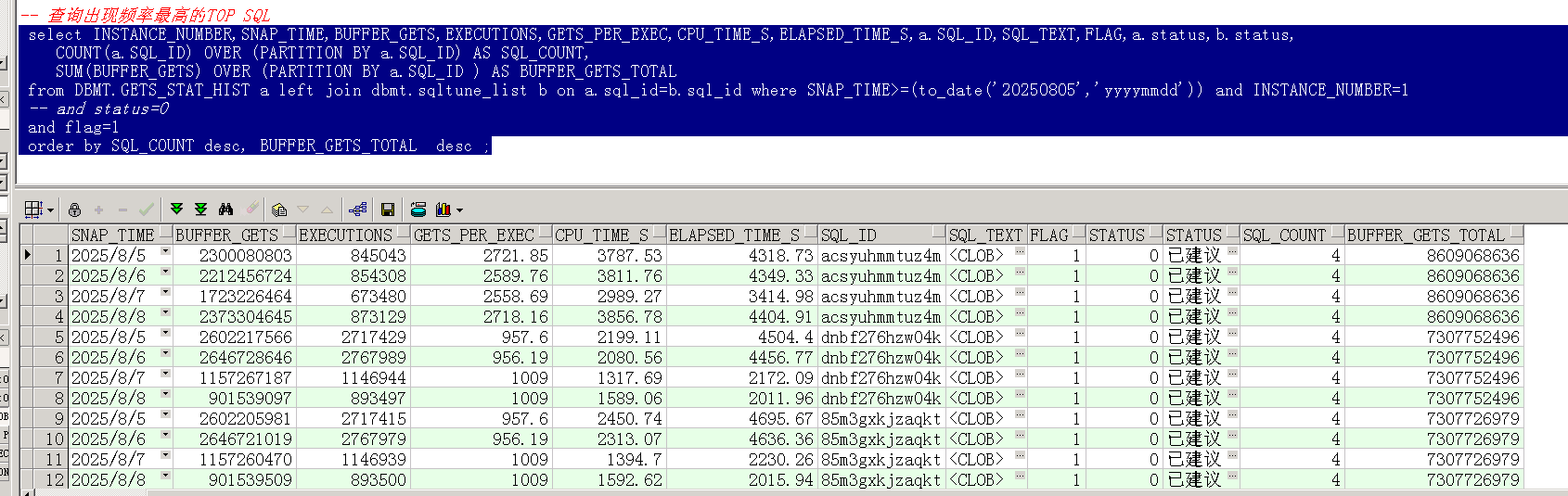
单次逻辑读最高的SQL
select INSTANCE_NAME,a.sql_id,max(BUFFER_GETS) BUFFER_GETS,max(EXECUTIONS),max(GETS_PER_EXEC) GETS_PER_EXEC ,FLAG,b.status
from DBMT.GETS_STAT_HIST a left join dbmt.sqltune_list b on a.sql_id=b.sql_id where SNAP_TIME>=(to_date('20250723','yyyymmdd')) and INSTANCE_NUMBER=2
group by INSTANCE_NAME,a.sql_id,FLAG,b.statusorder by BUFFER_GETS desc;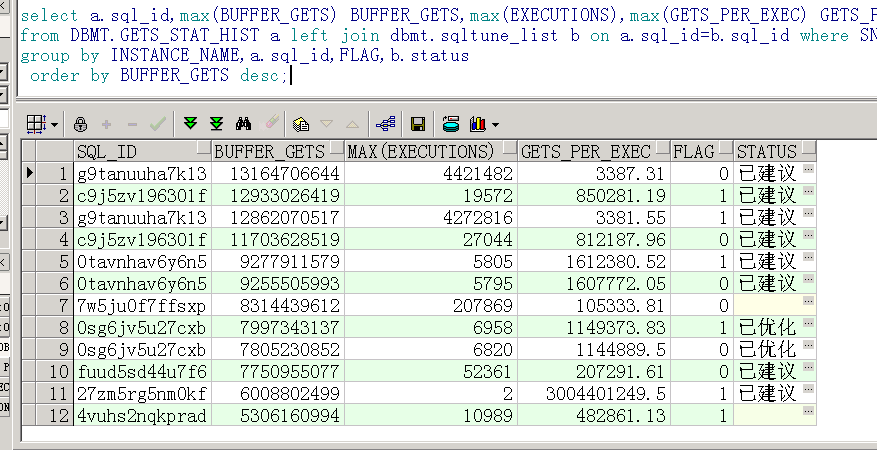
五、总结
自动化采集Gets TOP SQL,是Oracle数据库性能调优的基础环节。通过合理的时间分段、多实例支持和数据去重逻辑,DBA可以持续掌握系统内高负载SQL,结合后续分析工具,实现有效的性能定位与优化。