数据科学与计算实例应用
中国大学排名爬取
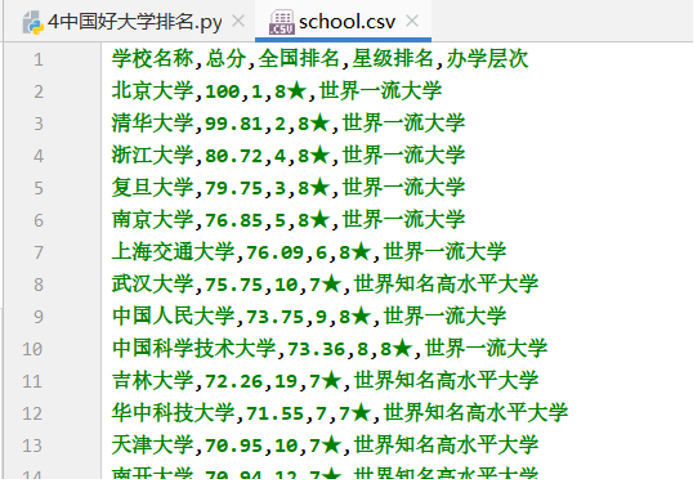
爬取高三网中国大学排名一览表,爬取数据包括学校名称、总分、全国排名、星级排名、办学层级。爬取后的数据保存在CSV文件中。
网址为 http://www.bspider.top/gaosan/
import requests
import csv
from bs4 import BeautifulSoupdef get_html(url, time=10):"""获取网页HTML内容"""try:r = requests.get(url, timeout=time)r.encoding = r.apparent_encodingr.raise_for_status()return r.textexcept Exception as error:print("网页获取失败:", error)return Nonedef parser(html):"""解析大学排名表格数据"""soup = BeautifulSoup(html, "lxml")out_list = []# 遍历表格行(跳过表头)for row in soup.select("table>tbody>tr"):tds = row.select("td")# 提取关键数据:学校名称、总分、全国排名、星级、办学层次row_data = [tds[1].text.strip(), # 学校名称tds[2].text.strip(), # 总分tds[3].text.strip(), # 全国排名tds[4].text.strip(), # 星级tds[5].text.strip() # 办学层次]out_list.append(row_data)return out_listdef save_csv(data, file_path):"""将数据保存为CSV文件"""with open(file_path, "w+", newline='', encoding="utf-8") as f:writer = csv.writer(f)writer.writerows(data)print(f"数据已成功保存至 {file_path}")if __name__ == "__main__":# 目标网址(大学排名页面)url = "http://www.bspider.top/gaosan/"# 完整爬取流程html_content = get_html(url)if html_content:parsed_data = parser(html_content)save_csv(parsed_data, "school.csv")发现school.csv中的“总分”那一列有一些空数据
数据预处理
删除包含空字段的行
import pandas as pd
df = pd.read_csv("school.csv")
new_df = df.dropna()
print(new_df.to_string())处理丢失数据之用指定内容来替换一些空字段
import pandas as pd
df = pd.read_csv("school.csv")
df.fillna("暂无分数信息", inplace = True)
print(df.to_string())
均值替换空单元格
import pandas as pd
df = pd.read_csv("school.csv")
x = df["总分"].mean()
print("总分的均值为")
print(x)
df["总分"].fillna(x, inplace = True)
print(df.to_string())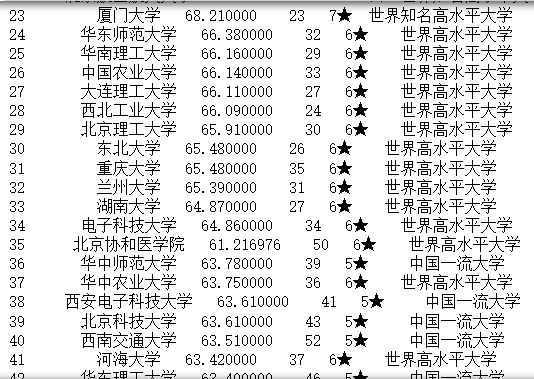
中位数替换空单元格
import pandas as pd
df = pd.read_csv("school.csv")
x = df["总分"].median()
print("总分的中位数为")
print(x)
df["总分"].fillna(x, inplace = True)
print(df.to_string())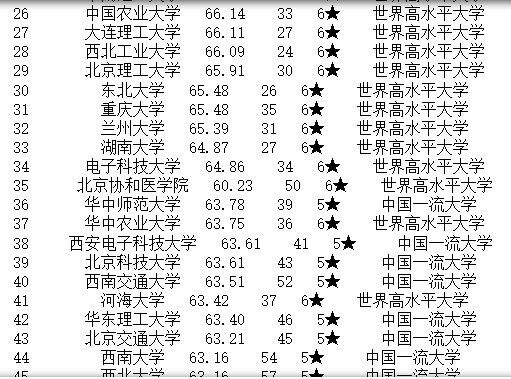
Matplotlib
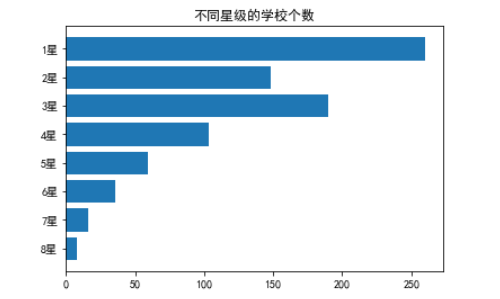
其中,按照星级排名分,8星学校有8所,7星学校有16所,6星学校有36所,5星学校有59所,4星学校有103所,3星学校有190所,2星学校有148所,1星学校有260所。
柱状图
import matplotlib.pyplot as plt
import numpy as npx = np.array(["8星","7星","6星","5星","4星","3星","2星","1星"])
y = np.array([8,16,36,59,103,190,148,260])
plt.title("不同星级的学校个数")
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.bar(x,y)
plt.show()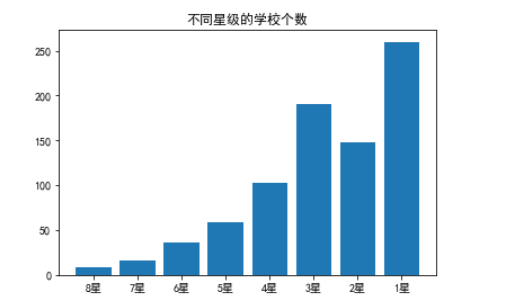
只需将plt.bar(x,y)换成plt.barh(x,y),就会变成横向的柱状图
饼图
import matplotlib.pyplot as plt
import numpy as npy = np.array([1,2,4.5,7.2,12.5,23.1,18,31.7])
plt.pie(y,labels=["8星","7星","6星","5星","4星","3星","2星","1星"])
plt.title("不同星级的学校个数")
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.show()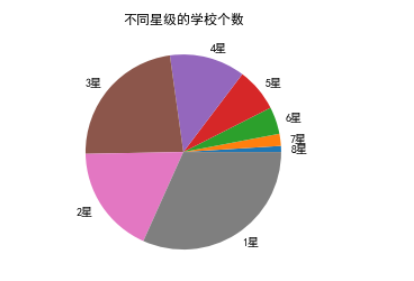
练习
中文网
https://www.ryjiaoyu.com/tag/details/
爬取信息
import requests
import csv
from lxml import etree
import pymysql
from pymysql.constants import CLIENT # 解决加密认证问题# 数据保存到MySQL的函数
def save_mysql(sql, val, **dbinfo):connect = Nonecursor = Nonetry:# 添加重连和认证插件参数dbinfo.update({"client_flag": CLIENT.MULTI_STATEMENTS})connect = pymysql.connect(**dbinfo)cursor = connect.cursor()cursor.executemany(sql, val) # 批量执行SQLconnect.commit()print(f"成功保存 {len(val)} 条数据到数据库")except Exception as err:if connect: connect.rollback()print("数据库保存错误:", err)finally:if cursor: cursor.close()if connect: connect.close()def get_html(url):try:headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}r = requests.get(url, headers=headers, timeout=10)r.encoding = r.apparent_encodingr.raise_for_status()return r.textexcept Exception as error:print(f"请求失败: {error}")return Nonedef safe_xpath(row, xpath, default=""):"""安全提取XPath数据"""elements = row.xpath(xpath)return elements[0].strip() if elements else defaultresult_list = [] # 存放爬取内容def parse(html):try:doc = etree.HTML(html)# 使用更健壮的XPath选择器for row in doc.xpath('//*[@id="tag-book"]/div/ul/li/div[2]'):name = safe_xpath(row, 'h4/a/text()', "未知书名")url = safe_xpath(row, 'h4/a/@href', "")author = safe_xpath(row, 'div/span/text()', "未知作者").strip()price = safe_xpath(row, 'span/span/text()', "未知价格")item = [name, url, author, price]result_list.append(item)except Exception as e:print(f"解析异常: {e}")return result_listdef save_csv(data, path):with open(path, "w", newline='', encoding='utf-8-sig') as f:writer = csv.writer(f)writer.writerow(["书名", "链接", "作者", "价格"])writer.writerows(data)print(f"CSV保存成功: {len(data)}条数据")if __name__ == "__main__":base_url = "https://www.ryjiaoyu.com/tag/details/7?page={}"page = 1max_data = 500 # 目标数据量while len(result_list) < max_data:url = base_url.format(page)print(f"爬取第 {page} 页: {url}")html = get_html(url)if not html:print(f"第 {page} 页获取失败,终止爬取")breakparse(html)print(f"当前已获取 {len(result_list)} 条数据")page += 1# 保存前30条到CSVsave_data = result_list[:max_data]save_csv(save_data, "./图书.csv")# 数据库保存部分try:parms = {"host": "127.0.0.1","user": "root", # 替换为实际用户名"password": "123456", # 替换为实际密码"db": "text", # 确保数据库存在"charset": "utf8mb4",}# 创建匹配表结构create_table_sql = """CREATE TABLE IF NOT EXISTS zhongwenwang (id INT AUTO_INCREMENT PRIMARY KEY,BookName VARCHAR(255) NOT NULL,URL VARCHAR(255),Author VARCHAR(100),Price VARCHAR(50)) CHARSET=utf8mb4;"""# 插入SQL(与实际爬取字段匹配)sql = """INSERT INTO zhongwenwang (BookName, URL, Author, Price) VALUES (%s, %s, %s, %s)"""# 创建连接并建表connection = pymysql.connect(**parms)with connection:with connection.cursor() as cursor:cursor.execute(create_table_sql)connection.commit()print("数据表创建/验证成功")# 保存到数据库save_mysql(sql, save_data, **parms)except Exception as e:print("数据库操作失败:", e)我提取了五百条信息,并进行筛选综合
import pandas as pd
from collections import defaultdict
import chardet # 必须导入chardet库才能使用[1,6](@ref)# 1. 读取CSV文件(优化编码处理)
try:# 方法1:使用chardet自动检测编码def detect_encoding(file_path):with open(file_path, 'rb') as f:result = chardet.detect(f.read(10000)) # 读取前10000字节检测[9](@ref)GBKreturn result['encoding']file_encoding = detect_encoding('图书.csv')print(f"检测到的文件编码:{file_encoding}")# 用检测到的编码读取文件df = pd.read_csv('图书.csv', encoding=file_encoding)except (FileNotFoundError, UnicodeDecodeError):try:# 方法2:尝试常见中文编码[1](@ref)df = pd.read_csv('图书.csv', encoding='GB18030') # 兼容性更强的编码[9](@ref)except:print(" 文件读取失败,请检查文件路径或编码")exit()# 2. 数据预处理
def extract_price(price_str):try:# 处理¥符号和逗号分隔符(如¥1,200)clean_str = price_str.replace('¥', '').replace(',', '')return float(clean_str)except:return None# 假设价格在第4列(索引3),根据实际情况调整
df['价格数值'] = df.iloc[:, 3].apply(extract_price)
df_clean = df.dropna(subset=['价格数值']).copy() # 创建独立副本避免警告[1](@ref)# 3. 定义价格区间
bins = [30, 40, 50, 60, 70]
labels = ['30-40元', '40-50元', '50-60元', '60-70元']# 4. 区间统计(避免SettingWithCopyWarning)
df_clean.loc[:, '价格区间'] = pd.cut(df_clean['价格数值'],bins=bins,labels=labels,right=False # 左闭右开区间[30,40)
)
counts = df_clean['价格区间'].value_counts().sort_index() #.sort_index()确保区间顺序输出# 5. 输出价格统计结果
print("\n 价格区间统计结果:")
print("*" * 30)
for interval, count in counts.items():print(f"│ {interval.ljust(8)} │ {str(count).center(6)} │")
print("*" * 30)# 6. 版本统计
target_versions = ["微课版", "慕课版", "大赛版", "全彩慕课版","实践篇", "AIGC版", "附微课", "理论篇", "其它"
]version_counts = defaultdict(int)
version_counts["其它"] = 0 # 初始化"其它"类别# 假设书名在第1列(索引0),根据实际情况调整
for index, row in df.iterrows():book_name = str(row.iloc[0]).strip() # 去除首尾空格matched = False# 优化匹配:避免全彩慕课版被计入慕课版for version in sorted(target_versions, key=len, reverse=True): # 优先匹配长关键词if version in book_name:version_counts[version] += 1matched = Truebreakif not matched:version_counts["其它"] += 1# 7. 输出版本统计结果
print("\n 图书版本统计结果:")
print("*" * 30)
for version in target_versions: # 按定义顺序输出count = version_counts[version]print(f"│ {version.ljust(8)} │ {str(count).center(6)} │")
print("*" * 30)# 8. 保存结果(可选)
result_df = pd.DataFrame({"类型": ["价格区间"] * len(counts) + ["图书版本"] * len(version_counts),"分类": list(counts.index) + list(version_counts.keys()),"数量": list(counts.values) + list(version_counts.values())
})
处理丢失数据之用指定内容来替换一些空字段
import pandas as pd
df = pd.read_csv("图书.csv")
df.fillna("暂无信息", inplace = True)
print(df.to_string())
柱状图
import matplotlib.pyplot as plt
import numpy as np
plt.subplot(1, 2, 1)
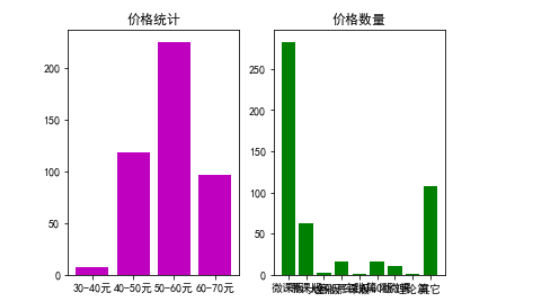
x = np.array(["30-40元","40-50元","50-60元","60-70元"])
y = np.array([7,118,225,96])
plt.title("价格统计")
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.bar(x,y,color = 'm' )
plt.subplot(1, 2, 2)
x = np.array(["微课版","慕课版","大赛版","全彩慕课版","实践篇","AIGC版","附微课","理论篇","其它"])
y = np.array([283,62,2,16,1,16,11,1,108])
plt.title("价格数量")
plt.rcParams["font.sans-serif"]=["SimHei"]
plt.bar(x,y,color = 'g' )
plt.show()
饼图
import matplotlib.pyplot as plt
import numpy as np# 设置全局中文字体(只需设置一次)
plt.rcParams["font.sans-serif"] = ["SimHei"]# 创建1行2列的子图布局
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6)) # 增大画布尺寸# --- 第一个饼图:价格区间分布 ---
y_price = np.array([7, 118, 225, 96])
labels_price = ["30-40元", "40-50元", "50-60元", "60-70元"]
colors_price = ["#d5695d", "#5d8ca8", "#65a479", "#a564c9"]ax1.pie(y_price,labels=labels_price,colors=colors_price,explode=(0.1, 0, 0, 0), # 突出显示30-40元autopct='%.1f%%', # 显示1位小数百分比shadow=True # 添加阴影增强立体感)
ax1.set_title("价格区间分布", fontsize=14)
ax1.axis('equal') # 确保饼图为正圆[1,2](@ref)# --- 第二个饼图:版本类型分布 ---
y_version = np.array([283, 62, 2, 16, 1, 16, 11, 1, 108])
labels_version = ["微课版", "慕课版", "大赛版", "全彩慕课版", "实践篇", "AIGC版", "附微课", "理论篇", "其它"]# 生成9种不重复的颜色(使用tab20色系)ax2.pie(y_version,labels=labels_version,colors=colors_version,explode=(0, 0.1, 0, 0, 0, 0, 0, 0, 0), # 突出显示慕课版autopct=lambda p: f'{p:.1f}%' if p > 3 else '', # 仅显示>3%的百分比pctdistance=0.85, # 百分比标签向内移动textprops={'fontsize': 9} # 调小字体避免重叠
)
ax2.set_title("图书版本分布", fontsize=14)
ax2.axis('equal')# 调整布局并展示
plt.tight_layout(pad=3.0) # 增加子图间距[6](@ref)
plt.show()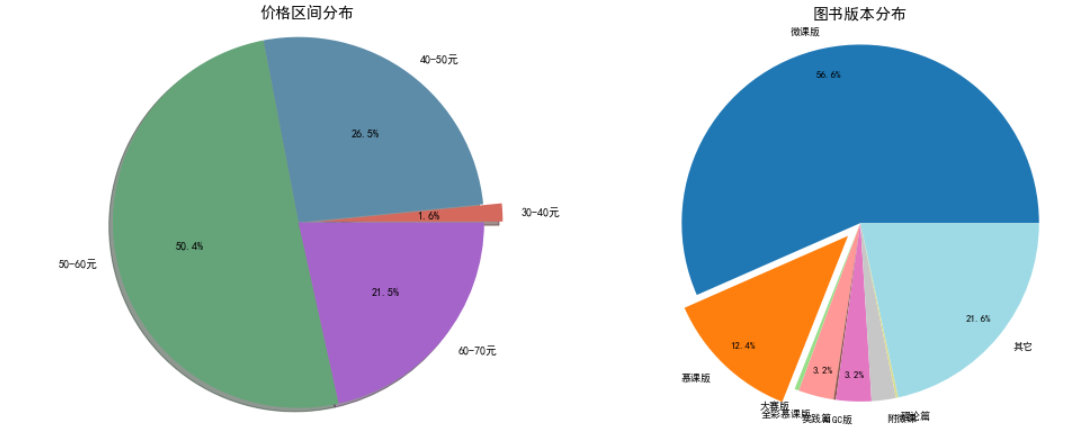
盒须图
import pandas as pd
import matplotlib.pyplot as plt# 设置中文显示
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题# 读取数据并预处理
try:df = pd.read_csv("图书.csv")# 价格处理:提取数字并转换为数值类型df['价格'] = df['价格'].astype(str).str.replace(r'[^\d.-]', '', regex=True)df['价格'] = pd.to_numeric(df['价格'], errors='coerce')df = df.dropna(subset=['价格']) # 移除价格为空的行# 异常值检测函数(使用固定价格范围)def detect_outliers(series):# 固定正常价格范围为 50~70 元lower_bound = 50upper_bound = 70bounds = (lower_bound, upper_bound)# 检测超出范围的异常值outliers = series[(series < lower_bound) | (series > upper_bound)]return outliers, bounds# 执行检测if len(df) > 0: # 只要有数据就可以检测outliers, (lower, upper) = detect_outliers(df['价格'])print(f"正常价格范围:{lower:.2f} ~ {upper:.2f} 元")print(f"异常值数量:{len(outliers)}")if not outliers.empty:print("异常值明细:")print(df.loc[outliers.index, ['书名', '价格']].to_string(index=False))# 绘制盒须图plt.figure(figsize=(10, 6)) # 设置图形大小box = plt.boxplot(df['价格'], showmeans=True, patch_artist=True)# 美化盒须图for patch in box['boxes']:patch.set_facecolor('#E0E0E0') # 设置箱体颜色# 添加参考线plt.axhline(y=lower, color='r', linestyle='-.', label='正常范围下限')plt.axhline(y=upper, color='r', linestyle='--', label='正常范围上限')# 设置标签和标题plt.ylabel('价格(元)', fontsize=12)plt.title('图书价格分布盒须图', fontsize=14)plt.legend()plt.grid(axis='y', linestyle='--', alpha=0.7)plt.tight_layout()plt.show()else:print("没有有效数据可检测")except FileNotFoundError:print("错误:找不到'图书.csv'文件,请检查文件路径是否正确")
except Exception as e:print(f"处理数据时发生错误:{str(e)}")

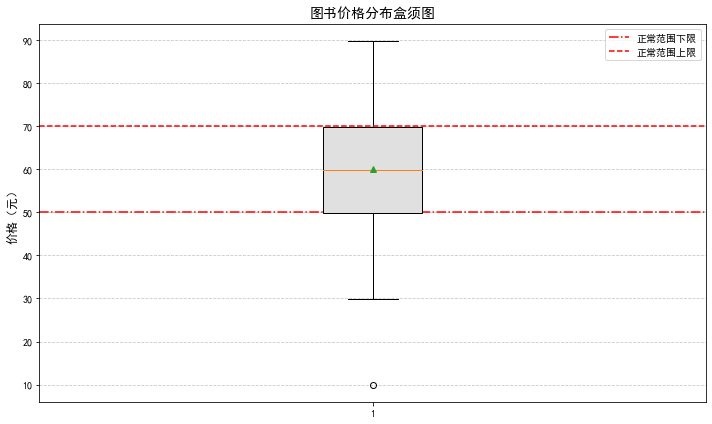
单独出来的圆点为异常值