学习观察和行动:机器人操作中任务-觉察的视图规划
25年8月来自中山大学、鹏程实验室、新加坡 NUS 和中科院深圳技术院的论文“Learning to See and Act: Task-Aware View Planning for Robotic Manipulation”。
近期用于多任务机器人操作的视觉-语言-动作 (VLA) 模型通常依赖于静态视点和共享视觉编码器,这限制了 3D 感知并导致任务干扰,从而阻碍了鲁棒性和泛化。这项工作提出任务-觉察视图规划 (TAVP),这是一个旨在通过将主动视图规划与特定任务的表示学习相结合来克服这些挑战的框架。TAVP 采用一种高效的探索策略,并通过一种伪环境加速,以主动获取信息丰富的视图。此外,引入了一种混合专家 (MoE) 视觉编码器来解开不同任务之间的特征,从而提高表示的保真度和任务泛化能力。通过学习任务-觉察方式看待世界,TAVP 生成更完整、更具辨别力的视觉表征,在各种操作挑战中表现出显著增强的动作预测能力。在 RLBench 任务上进行的大量实验表明, TAVP 模型比固定视图方法具有更优异的性能。
操作中的多任务学习
通用机器人的核心挑战,在于任务泛化能力和复杂环境下的多任务执行能力。过去,多任务学习 [99, 100, 143, 101] 取得了显著进展。它主要包含两种方法:模块化解决方案将技能分解为可重用的基本单元(例如,感知、规划和控制模块)[95]。尽管这些解决方案可解释,但它们面临着组合爆炸问题——随着任务复杂性的增加,设计接口和模块间协调的成本呈指数级增长,导致系统僵化。例如,ManipGen [98] 消耗了大量训练资源来训练超过 1000 名特定任务专家。相反,端到端解决方案采用单一密集模型将感知直接映射到动作 [38, 40, 41, 30, 42, 43, 97]。虽然简化了流程,但由于不同任务(例如,抓取易碎物体与拧紧螺丝)的视觉特征分布和运动模式存在显著差异,导致模型在训练过程中由于参数冲突而难以收敛。混合专家 (MoE) [12] 通过稀疏激活机制解决了大型模型的扩展瓶颈。SDP [14] 将 MoE 集成到扩散策略中,以解决多任务学习和任务迁移问题。
视觉-语言-动作(VLA)模型
近年来,已提出了许多 VLA 模型 [42, 38, 40, 143, 79]。与涉及姿态估计[110,112]和路径规划[113,114]的传统方法不同,这显著简化了模型流程。随着大语言模型(LLM)和视觉-语言模型(VLM)的进步,这些大型模型已经应用于机器人技术[39,119,73,94,74,111],利用其强大的先验为机器人提供世界知识,从而提高模型的泛化和性能。然而,目前的大多数VLA模型依赖于单一或固定的视点,这使得机器人难以实现对3D空间的全面感知,这限制了动作预测能力。
强化学习在机器人领域的应用
强化学习 (RL) 在机器人技术领域取得了显著成就 [102]。然而,从零开始实施 RL 通常需要复杂的奖励机制和训练范式设计 [103, 108, 107, 105, 106]。近期,多项研究 [104, 88] 通过使用 RL 对预训练模型进行微调,取得了令人欣喜的成果。
如图所示,当机器人接到“把糖放进橱柜”的指令时,三个固定摄像头捕捉到的图像要么漏掉了橱柜,要么没有包含抓取糖的末端执行器。这种不完整的视觉观察会阻碍机器人正确解读场景,最终导致动作不理想甚至失败。
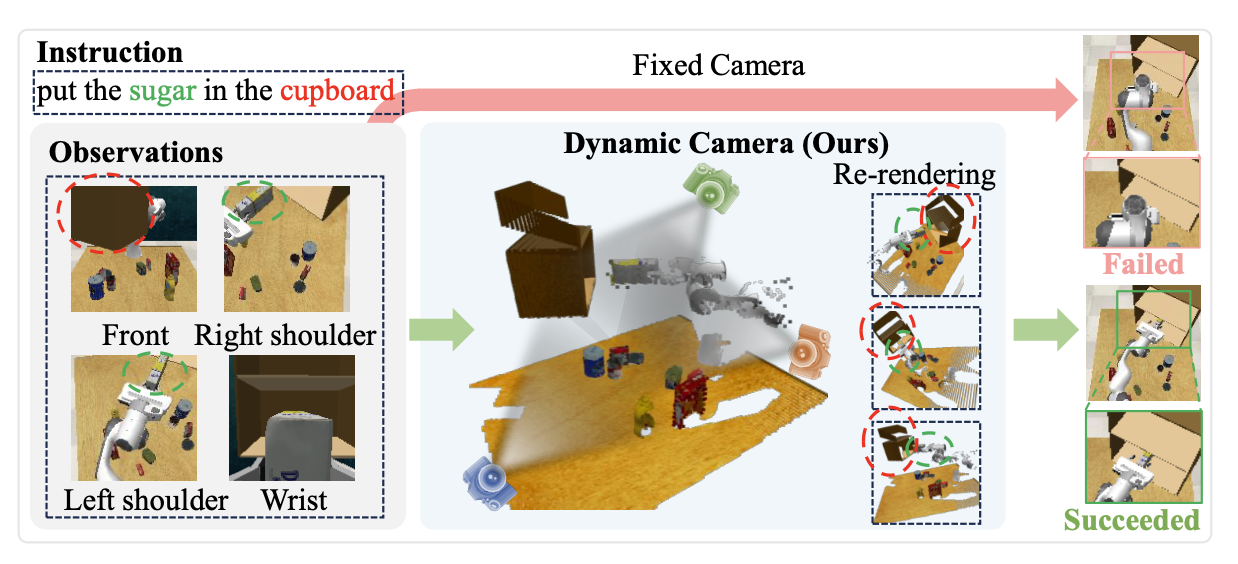
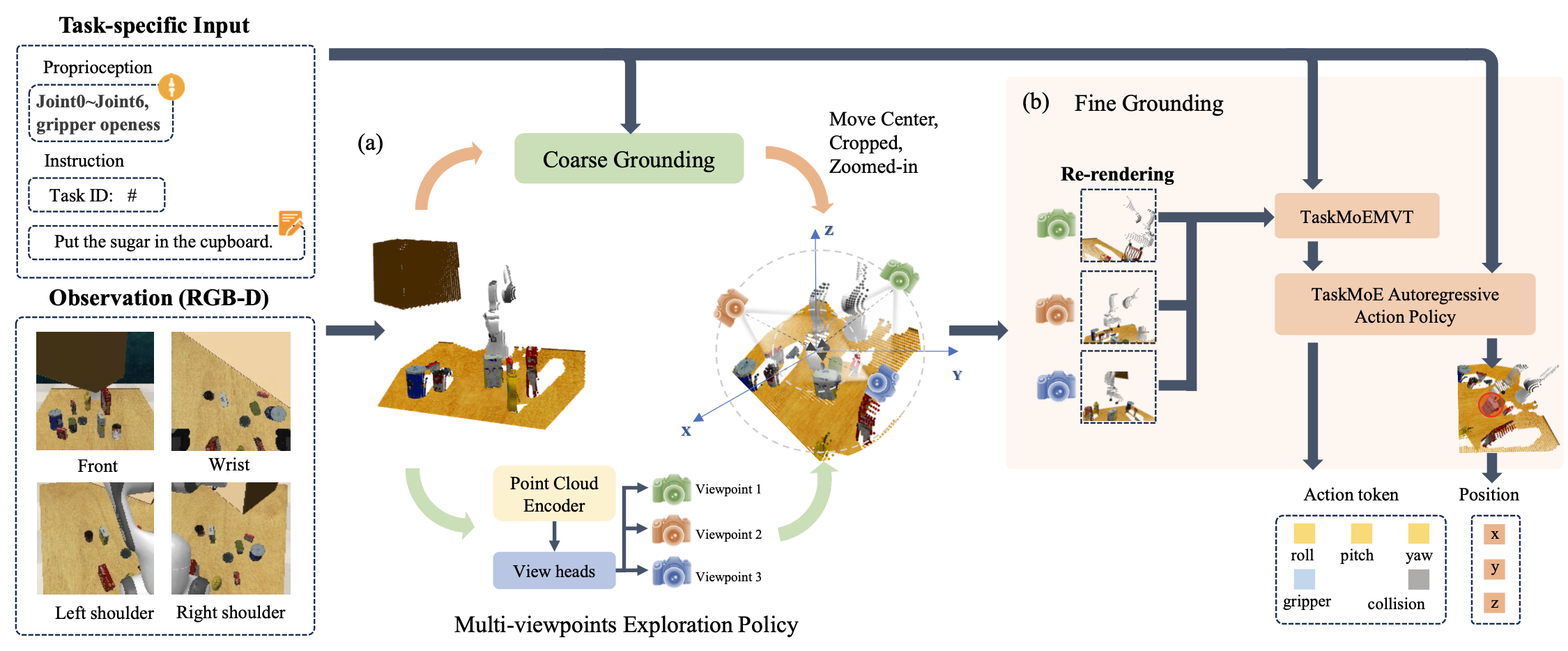
本文提出任务-觉察视图规划 (TAVP) 框架,旨在通过提取特定于任务的视觉特征来识别最佳视点,以实现准确、鲁棒的机器人操作。完整的流程如图所示。TAVP 的输入包括语言指令、来自 RGB-D 摄像机的当前视觉观测以及当前的夹持器状态。为了使模型能够从任意视点探索最佳观测,首先使用输入的 RGB-D 图像重建场景的 3D 点云。为了缩小搜索空间并实现与任务对齐的视图选择,利用 RVT-2 [143] 的粗预测阶段来生成感兴趣的区域。然而,与使用共享多视点 transformer (MVT) 为所有任务提取视觉特征的 RVT-2 不同,在 MVT 之前引入一个任务-觉察混合专家 (TaskMoE) 模块,将指令路由到专门的专家编码器。这种设计能够实现更精确、更面向任务的视觉特征提取,有利于视点选择和动作预测。从确定的兴趣区域开始,采用多视点探索策略网络 (MVEPN) 搜索最佳相机姿态,以最大化目标物体和末端执行器的可见性。随后,选定的视点被重新渲染为图像观测,并使用另一个基于 TaskMoE 的多视点 transformer (MVT) 进行处理,然后传递到动作预测模型。对于动作预测,还使用TaskMoE 升级 ARP [79] 中提出的自回归动作序列模型,以实现更针对任务的特征提取和动作预测。
TaskMoE
为了解决多任务学习中复杂操作任务固有的异质性——不同的任务通常需要截然不同的视觉表征和动作策略——本文引入一个任务-觉察混合专家模块 (TaskMoE),如图所示。与以往基于 MoE 的方法 [12, 14] 相比,TaskMoE 引入了两项技术。
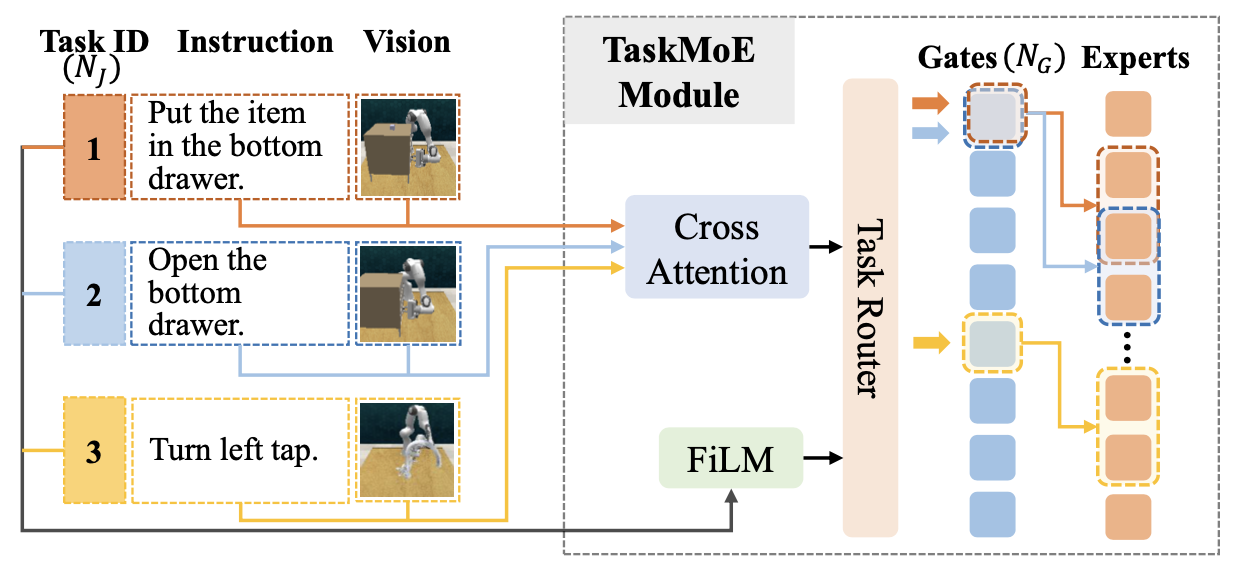
首先,不再仅仅依赖任务标识符进行专家选择,而是融入更丰富的指令和场景相关线索,以更有效地指导专家路由,这对于实现准确的多任务机器人操作至关重要。具体而言,如图所示,设计一个跨模态模块,该模块采用交叉注意机制来建模指令和视觉信息之间的交互。然后,生成的上下文感知特征通过特征线性调制 (FiLM) 层 [181] 与任务标识符融合,从而实现更具自适应性和任务敏感性的专家选择。
其次,为了提高 TaskMoE 的可扩展性和泛化能力,将路由门的数量与任务总数分离。具体而言,为所有 NJ 任务分配 N_G 个门,其中 N_G < N_J。这种设计不仅适应任务多样性,还促进了具有相似视觉或语义特征的任务之间的参数共享。例如,如图 3 所示,任务 1 和任务 2(均涉及打开抽屉)通过同一个门进行路由,但根据其特定的操作要求分配给不同的专家。相反,语义上不同的任务 3 则通过不同的门进行路由。这种设置鼓励发现潜在的任务集群,并提供推广到与可见任务具有结构相似性的未见任务的能力,从而增强了 TaskMoE 的可迁移性和鲁棒性。值得注意的是,所有任务共享一个 N_E 专家池,并且对于每个输入,只有前 k 个专家(基于门控分数)被激活以指导特定任务的视觉特征提取。
多视点探索策略
多视点探索策略 (MVEP) 旨在选择 K 个视点,最大限度地捕捉与操作目标相关的信息区域,从而提高机器人动作预测的准确性。MVEPN 将重建点云 P 及其相关的 RGB 特征 F_img 作为输入,将它们连接起来形成输入表示:
X = Concat(P, F_img)
其中 N 表示 3D 点的数量。融合表示 X 由多层感知器 (MLP) 处理,该感知器预测 K 个相机位姿的参数。
本研究用观察模型 [182] 表示每个相机位姿,该模型通过球面坐标系将相机位置和方向解耦。因此,探索的视角被参数化为五维向量 p_i = (θi, φi, ri, θi_up, φi_up),其中 (θ,φ,r) 表示相对于原点的球坐标系中的相机中心,(θ_up, φ_up) 定义向上向量的方向,i ∈ [0, K − 1] 表示第 i 个视角。因此,所有相机姿态均为 p = {pi|i = 0, …, K − 1}。
为了便于使用强化学习进行基于梯度的策略优化,将相机姿态参数建模为高斯分布的样本。网络不是直接预测视点 pi,而是输出平均值和对数标准差,从而通过重参数化技巧实现可微采样。
为了便于基于梯度优化视点选择策略,将每个相机姿态建模为高斯分布的样本,而不是预测确定性值。具体来说,对于 K 个视点中的每一个,MVEPN 输出 5 维相机姿态参数对角高斯分布的平均值和对数标准差。
为了确保采样的姿态在球面坐标系中保持有效,用 sigmoid 函数将每个分量限制在标准化范围内。
训练策略
任务-觉察视图规划 (TAVP) 模型的整个训练过程包含三个阶段:
阶段 1:在第一阶段,用三个默认渲染视角(正面、左侧和顶部)训练 TAVP 的固定视角变体。此阶段的训练流程与 RVT-2 [143] 类似,其中总体损失由多个部分组成。具体而言,L_hc 和 L_hf 分别表示粗略和精细落地模块生成热图的交叉熵损失。真实热图采用以真实三维位置的二维投影为中心的截断高斯分布生成,如 RVT [155] 中所述。此外,损失还包括末端执行器旋转损失 L_rot(计算为每个欧拉角的交叉熵损失),以及夹持器状态损失 L_gri 和碰撞指示器损失 L_col,它们均以二分类损失的形式表示。
阶段 2:在第二阶段,用阶段 1 中训练的固定视图 TAVP 模型作为基准,改进多视点探索策略 (MVEP)。MVEP 通过近端策略优化 (PPO) 算法 [93] 进行优化,该算法通常需要与物理环境交互才能获得奖励反馈。为了降低此类交互的高时间成本,引入一种伪环境交互机制。
具体而言,将固定视图 TAVP 作为参考模型来监督 MVEP 的训练。给定相同的观察和指令,参考模型的损失为 L_ref = [L_hf,L_rot,L_gri,L_col]。相反,MVEP 为动作预测生成动态视角,导致损失为 L_TAVP = [L′_hf,L′_rot,L′_gri,L′_col]。以参考模型作为性能下限,则目标是使 L_TAVP 小于 L_ref。
其算法如图所示:影子网络 π_shadow(训练前策略的冻结副本)处理观测 o 计算参考损失 L_ref,MVEP π_θ 处理 o 生成相机姿态 p(p 作为策略动作),多视角相机姿态渲染后的观测图像被输入到 TaskMoE 和 TaskMoE-ARP(自回归动作策略)中计算当前策略损失 L_TAVP,然后根据 L_ref、L_TAVP 和 p 计算奖励 r,最后将经验元组 (o, r, p, log π_θ_old (p|o), V_θ_old (o)) 存储在重放缓冲区 B 中用于策略更新。此方法支持批量环境交互,利用现有演示数据改进策略并提高数据利用效率。

除了任务损失奖励之外,还加入基于置信度的奖励,该奖励源自精细落地模块。具体而言,计算落地热图的负平均熵。为了进一步鼓励视点多样性,引入一个基于摄像机位置之间平均成对余弦距离的额外奖励。总奖励通过自适应地归一化和聚合所有组件来计算。自适应归一化使用 Welford 算法[121]进行归一化,保持每个组件的均值和方差,并将最终奖励限定在[-10, 10]范围内,以确保训练稳定性。
在此阶段,只有MVEP可训练,TAVP的所有其他组件均被冻结。
阶段3:在第三阶段,为了使MVEP更好地适应动作生成,进一步微调整个TAVP模型(不包括MVEP),使用与阶段1 相同的损失函数。
实验设置
模拟设置。模拟实验基于 RLBench 数据集 [19] 进行,该数据集是 CoppeliaSim 模拟器中实现的多任务学习基准,该模拟器以桌面环境中的 7 自由度 (7-DoF) Franka Emika Panda 机器人为原型。用一个精选子集,包含 18 个不同的操作任务,每个任务包含多个变体。观测数据包括从四个固定视角(正面、左肩、右肩和腕戴)捕获的 RGB-D 图像 (128 × 128)。动作空间将末端执行器位姿表示为 a = ( p_xyz , q_rot , g_gripper , c_collision ),其中 p_xyz 表示笛卡尔坐标,q_rot 是四元数旋转变量,g_gripper ∈ {0, 1} 控制夹持器状态,c_collision ∈ {0, 1} 表示碰撞。
实现设置。在实验中,摄像机视点数量 K = 3,TaskMoE NG 中的门数量 = 8,任务专家数量 NE = 16。对于每个任务,选择 Top −2 个任务专家。摄像机的默认径向约束为 rmin = 0.75 m 和 rmax = 1.3 m。TAVP 模型使用 4× NVIDIA RTX A800 GPU 和 80 GB 内存进行训练。在测试期间,用 1× NVIDIA RTX A800 GPU 顺序验证每个任务并计算平均成功率。
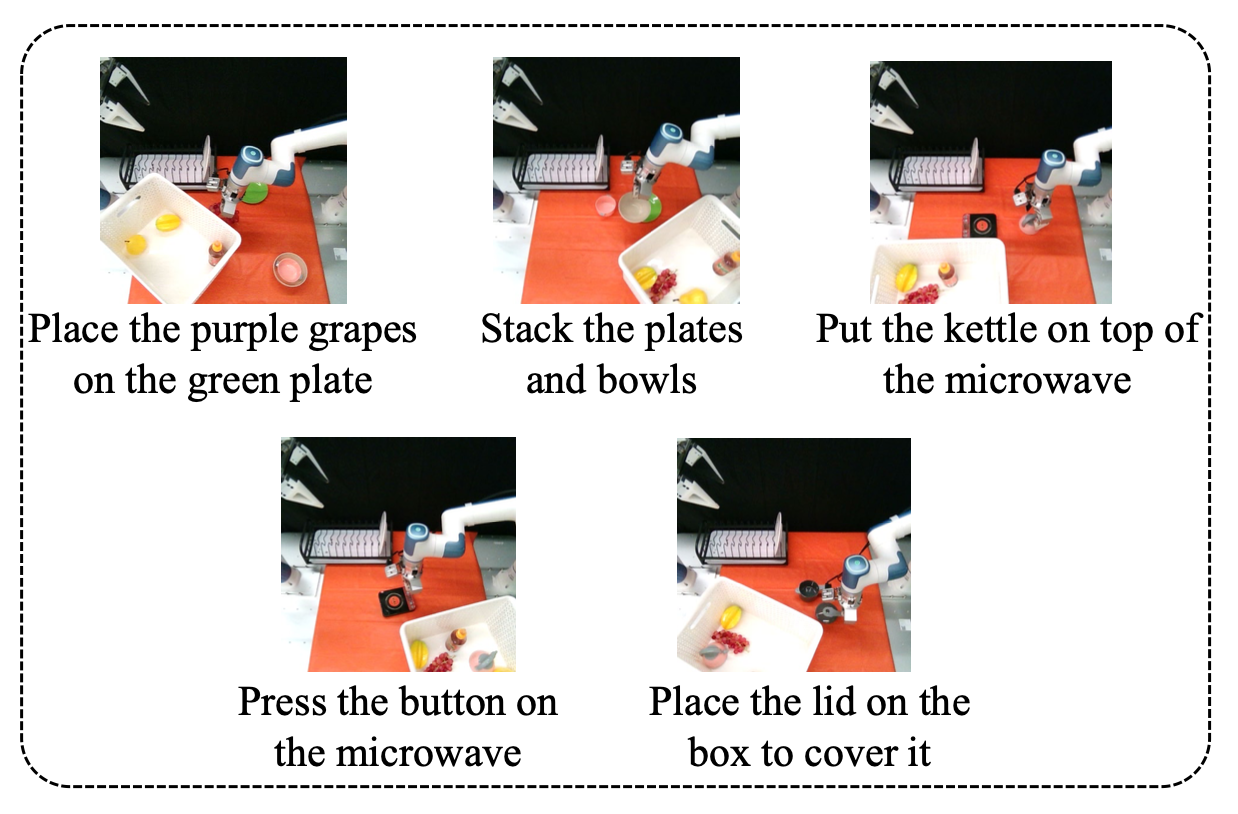
真实机器人设置。用 Dobot Xtrainer 平台,该平台配备两个 6 自由度 (6-DoF) Nova 2 协作机械臂,并配备三个固定安装的英特尔 RealSense D405 深度摄像头:一个位于头顶横向位置,两个机械臂上各有两个腕式摄像头,如图所示。

设计五种不同的操作任务来评估 TAVP 的有效性,包括摆放餐具、烧水、盖上盖子、摘葡萄和按下按钮。收集专家演示,为每个任务生成 100 个演示片段用于训练。如图提供一些样本。为了加快训练效率,从收集的演示中提取关键帧,仅保留重要的关键帧数据。