“鱼书”深度学习进阶笔记(3)第四章
最近在看斋藤康毅的《深度学习进阶:自然语言处理》,以下按章节做一点笔记。
这本书是《深度学习入门:基于Python的理论与实现》的续作,针对自然语言处理和时序数据处理。如对“鱼书”第一本的笔记感兴趣,可看我之前做的笔记。
01 第四章:word2vec的高速化
本章将重点放在word2vec的加速上,来改善word2vec。
具体而言,将对上一章中简单的word2vec进行两点改进:引入名为Embedding层的新层,以及引入名为Negative Sampling的新损失函数。
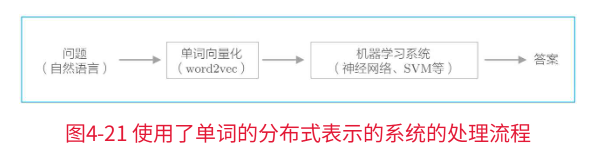
完成优化后,将在PTB数据集(一个大小比较实用的语料库)上进行学习,并实际评估所获得的单词的分布式表示的优劣。
1.1 word2vec的改进(1)
在上一章提到的结构中,如果我们要处理的词汇量有100万及以上(说明输入层和输出层存在100万个神经元),中间层的神经元有100个。中间计算会花费很长时间。
具体来说,以下两个地方的计算会出现瓶颈。
- 输入层的one-hot表示和权重矩阵Win的乘积(第1节解决)
- 中间层和权重矩阵Wout的乘积以及Softmax层的计算(第2节解决)
第1个问题与输入层的one-hot表示有关:
这是因为用one-hot表示来处理单词,随着词汇量的增加,one-hot表示的向量大小也会增加。
此外,还需要计算one-hot表示和权重矩阵Win的乘积,这也要花费大量的计算资源。
使用embedding层来解决。
第2个问题是中间层之后的计算。
首先,中间层和权重矩阵Wout的乘积需要大量的计算。
其次,随着词汇量的增加,Softmax层的计算量也会增加。
引入Negative Sampling(负采样)这一新的损失函数来解决。
1.1.1 embedding层
在上一章的逻辑中,我们将单词转化成了one-hot表示,将其输入到了MatMul层,在MatMul层中计算了该one-hot表示和权重矩阵的乘积。
这里,假设词汇量是100万,中间层的神经元个数是100,则MatMul层中的矩阵乘积如下图所示:
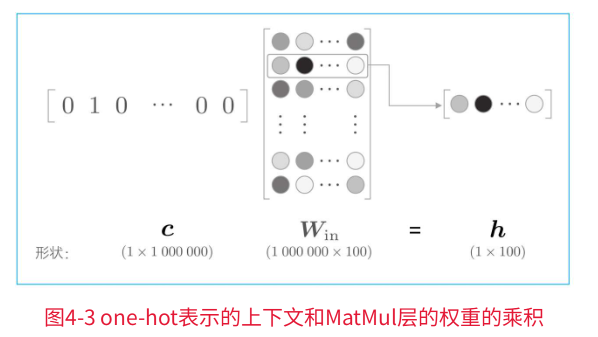
我们需要计算这个巨大向量和权重矩阵的乘积。
如上图的运算,本质上是把矩阵特定的行取出来。因此,直觉上将单词转化为one-hot向量的处理和MatMul层中的矩阵乘法似乎没有必要。
因此,我们创建一个从权重参数中抽取“单词ID对应行(向量)”的层,称为Embedding层。
**Embedding来自“词嵌入”(word embedding)**这一术语。即,在这个Embedding层存放词嵌入(分布式表示)。

1.1.2 embedding层的实现
实现代码如下:
class Embedding:def __init__(self, W):self.params = [W]self.grads = [np.zeros_like(W)]self.idx = None # 用来保存前向传播时输入的索引(单词ID),初始化为 Nonedef forward(self, idx):W, = self.paramsself.idx = idx # 保存索引,方便后向传播用。out = W[idx] # 根据索引选出对应的词向量。例如 idx 是 [3, 7],就选 W 中第3行和第7行,形成对应的词向量输出。return outdef backward(self, dout):dW, = self.grads # 用逗号解包 dW, = ...,拿到的是这个梯度数组的引用(不是拷贝).所以 dW 和 self.grads[0] 指向同一个内存地址dW[...] = 0 # 数组所有元素替换为 0,但保留原数组的内存地址np.add.at(dW, self.idx, dout) # 把 dout 对应的梯度,累加到 dW 中对应索引行的位置return None注意,这里直接用书里的代码,因为表达方式现在不用,会有如下报错,进行如下替代即可:
反向传播会稍微难以理解一点。
Embedding层的正向传播只是从权重矩阵W中提取特定的行,并将该特定行的神经元原样传给下一层。
在反向传播时,从上一层(输出侧的层)传过来的梯度,将原样传给下一层(输入侧的层)。不过,从上一层传来的梯度会被应用到权重梯度dW的特定行(idx)。
如下图所示:
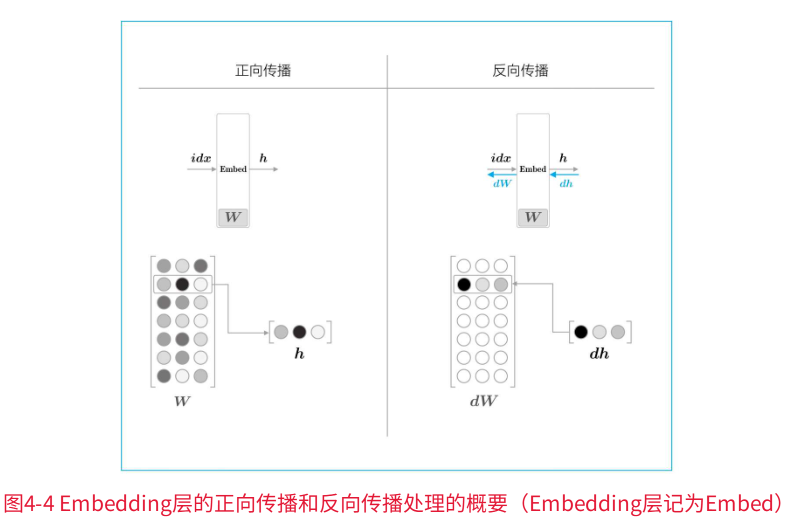
关于反向传播dW的处理,有一点很有趣的设置,讨论情况如下:
1.2 word2vec的改进(2)
1.2.1 中间层之后的计算问题
目前,在以下两个地方还需要较多时间:
- 中间层的神经元和权重矩阵(Wout)的乘积
- Softmax层的计算
1.2.2 从多分类到二分类
负采样的关键思想是二分类(binary classification),更准确地说,是用二分类来拟合多分类(multiclass classification)。
如何思考将多分类问题转化为二分类问题呢?
首先,我们先考察一个可以用“Yes/No”来回答的问题。
比如,让神经网络来回答“当上下文是you和goodbye时,目标词是say吗?”这个问题,这时输出层只需要一个神经元即可。可以认为输出层的神经元输出的是say的得分。
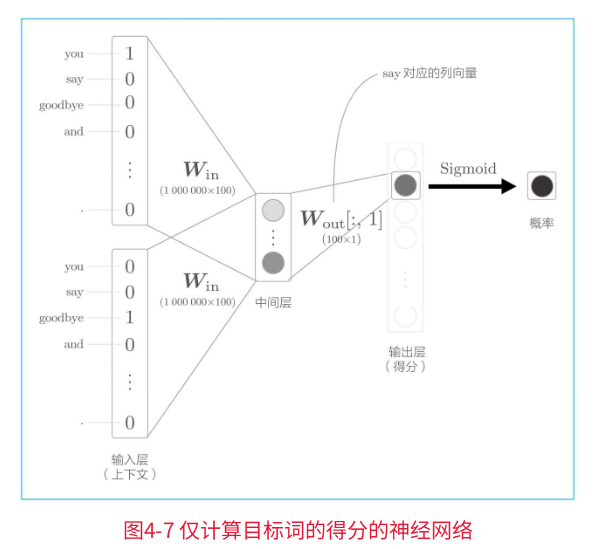
如上图,输出层的神经元仅有一个。
因此,要计算中间层和输出侧的权重矩阵的乘积,只需要提取say对应的列(单词向量),并用它与中间层的神经元计算内积即可。
1.2.3 多分类到二分类的实现
之前,我们清楚二分类神经网络的老套路:使用sigmoid函数将得分转化为概率,使用交叉熵误差作为损失函数。 在多分类里面的套路:输出层使用Softmax函数将得分转化为概率,损失函数使用交叉熵误差。
转化为二分类的基本结构如下:
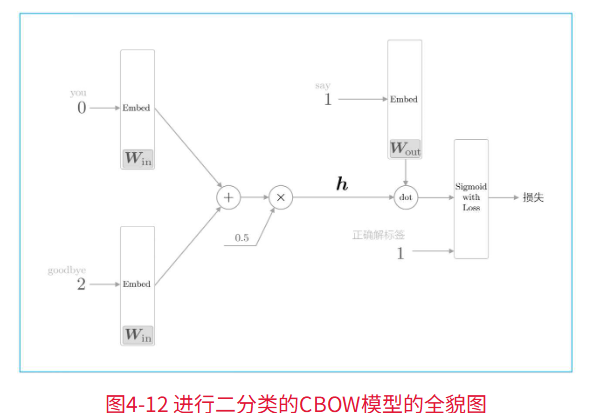
这里,将中间层的神经元记为h,并计算它与输出侧权重Wout中的单词say对应的单词向量的内积。然后,将其输出输入Sigmoid with Loss层,得到最终的损失。
在上图中,向Sigmoid with Loss层输入正确解标签1,这意味着现在正在处理的问题的答案是“Yes”。当答案是“No”时,向Sigmoid with Loss层输入0。
为了进一步简化,引入Embedding Dot层,该层将上图中的Embedding层和dot运算(内积)合并起来处理。则流程图转变为:
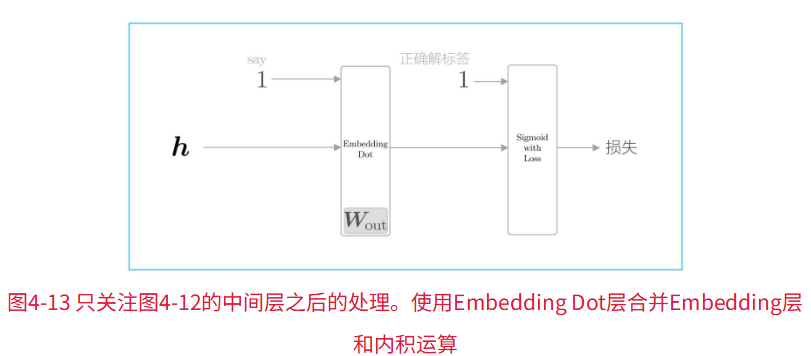
实现代码:
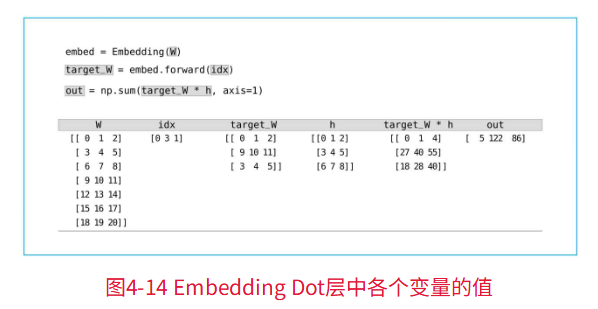
class EmbeddingDot:def __init__(self, W):self.embed = Embedding(W) # embed保存Embedding层self.params = self.embed.paramsself.grads = self.embed.gradsself.cache = None # 占位,用来在 forward 保存正向计算中需要在 backward 使用的中间值(cache)def forward(self, h, idx):target_W = self.embed.forward(idx)out = np.sum(target_W * h, axis=1)self.cache = (h, target_W)return outdef backward(self, dout):h, target_W = self.cache # 取出 forward 时保存的中间量dout = dout.reshape(dout.shape[0], 1)dtarget_W = dout * hself.embed.backward(dtarget_W)dh = dout * target_Wreturn dh
对于前向传播,下面的例子会更有利于理解,如下图:
关于后向传播的理解,可参考下面:
1.2.4 负采样
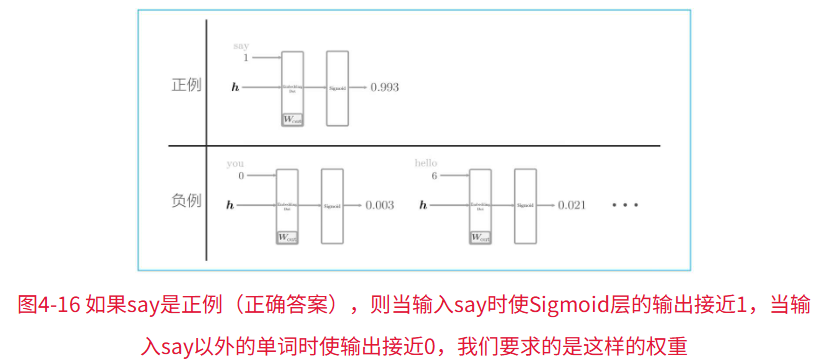
前面的代码只学习了正例(正确答案),那负例(错误答案)会有怎样的结果呢?
我们想要实现的,(基于前面的例子)对于正例(say),使Sigmoid层的输出接近1;对于负例(say以外的单词),使Sigmoid层的输出接近0。
就像下图:
提问,我们需要让所有负例都进行学习吗?
采用一种近似方法,选择若干个(5个或者10个)负例(如何选择将在下文介绍)。也就是说,只使用少数负例。这就是负采样方法的含义。
将这些数据(正例和采样出来的负例)的损失加起来,将其结果作为最终的损失
再次提问,如何抽取负例呢?
关于这一点,基于语料库的统计数据进行采样的方法比随机抽样要好。
即,就是让语料库中经常出现的单词容易被抽到,让语料库中不经常出现的单词难以被抽到。
基于语料库中单词使用频率的采样方法,会先计算语料库中各个单词的出现次数,并将其表示为“概率分布”,然后使用这个概率分布对单词进行采样。
一些注意:

word2vec中提出的负采样对刚才的概率分布增加了一个步骤。对原来的概率分布取0.75次方:
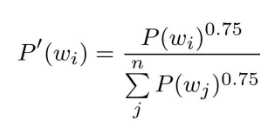
提问,为什么进行如此操作呢?
这是为了防止低频单词被忽略。更准确地说,通过取0.75次方,低频单词的概率将稍微变高。(书中提到,0.75这个值并没有什么理论依据,也可以设置成0.75以外的值)
上面的这种实现方法被称为UnigramSampler类。
unigram是“1个(连续)单词”的意思。,bigram是“2个连续单词”的意思,trigram是“3个连续单词”的意思。
这里使用UnigramSampler这个名字,是因为我们以1个单词为对象创建概率分布。
如果是bigram,则以‘( you’, ‘say’)、‘(you’,‘goodbye’)……这样的2个单词的组合为对象创建概率分布。
实现代码为:
import collections
class UnigramSampler:def __init__(self, corpus, power, sample_size): # 单词ID列表格式的corpus、对概率分布取的次方值power(默认值是0.75)和负例的采样个数sample_sizeself.sample_size = sample_size # 将sample_size保存为实例变量self.vocab_size = Noneself.word_p = Nonecounts = collections.Counter() # 创建一个Counter对象用于计数for word_id in corpus:counts[word_id] += 1 # 遍历语料库中的每个单词id,同级每个单词id出现的次数+1vocab_size = len(counts) # 词汇表大小等于不同单词ID的数量self.vocab_size = vocab_size # 将词汇表大小保存为实例变量self.word_p = np.zeros(vocab_size)for i in range(vocab_size):self.word_p[i] = counts[i] # 遍历每个单词,将每个单词的出现次数存入数组self.word_p = np.power(self.word_p, power) # 对每个单词的计数取power次方self.word_p /= np.sum(self.word_p) # 归一化处理,得到概率分布def get_negative_sample(self, target):batch_size = target.shape[0]# 使用 NumPy 的 random.choice 从 [0, 1, ..., vocab_size-1] 中按概率 self.word_p 抽样negative_sample = np.random.choice(self.vocab_size, size=(batch_size, self.sample_size),replace=True, p=self.word_p)# size=(batch_size, self.sample_size)表示要生成一个二维数组,每行是一个样本的负例。# replace=True表示允许重复选择(即同一个单词可以被多次选作负例)# p = self.word_p表示按照之前计算的概率分布进行采样return negative_sample
接着实现负采样:
class SigmoidWithLoss:def __init__(self):self.params, self.grads = [], []self.loss = Noneself.y = None # sigmoid的输出self.t = None # 监督标签def forward(self, x, t):self.t = tself.y = 1 / (1 + np.exp(-x))self.loss = cross_entropy_error(np.c_[1 - self.y, self.y], self.t)return self.lossdef backward(self, dout=1):batch_size = self.t.shape[0]dx = (self.y - self.t) * dout / batch_sizereturn dxclass NegativeSamplingLoss:def __init__(self, W, corpus, power=0.75, sample_size=5):self.sample_size = sample_size # 保存负例样本数量self.sampler = UnigramSampler(corpus, power, sample_size) # 创建负采样器实例self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)] # 创建损失层列表,数量为sample_size + 1(1 个正例 + sample_size 个负例),每个都是SigmoidWithLoss层(结合了 Sigmoid 激活和交叉熵损失)self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1)] # 创建嵌入点积层列表,数量同样为sample_size + 1,每个都是EmbeddingDot层(用于计算嵌入向量的点积)self.params, self.grads = [], []for layer in self.embed_dot_layers: # 遍历所有嵌入点积层self.params += layer.paramsself.grads += layer.gradsdef forward(self, h, target):batch_size = target.shape[0] # 获取批次大小negative_sample = self.sampler.get_negative_sample(target) # 使用之前创建的采样器生成负例样本,形状为(batch_size, sample_size)# 正例的正向传播score = self.embed_dot_layers[0].forward(h, target) # 使用第一个EmbeddingDot层计算正例的得分(中心词嵌入与目标词嵌入的点积)correct_label = np.ones(batch_size, dtype=np.int32) # 创建正例的标签数组,全部为 1(表示 "相关")loss = self.loss_layers[0].forward(score, correct_label) # 使用第一个损失层计算正例的损失(Sigmoid 交叉熵损失)# 负例的正向传播negative_label = np.zeros(batch_size, dtype=np.int32) # 创建负例的标签数组,全部为 0(表示 "不相关")for i in range(self.sample_size):negative_target = negative_sample[:, i] # 获取第i个负例score = self.embed_dot_layers[1 + i].forward(h, negative_target) # 使用对应的EmbeddingDot层计算该负例的得分loss += self.loss_layers[1 + i].forward(score, negative_label) # 计算该负例的损失并累加到总损失中return lossdef backward(self, dout=1):dh = 0# zip() 是一个内置函数,用于将多个可迭代对象(如列表、元组等)“打包” 成一个迭代器,每次迭代会同时从每个可迭代对象中取出一个元素,组成一个元组for l0, l1 in zip(self.loss_layers, self.embed_dot_layers): # 同时遍历损失层和嵌入点积层dscore = l0.backward(dout) # 给出损失对score的梯度dh += l1.backward(dscore) # 计算并把对 W 的梯度累加到 embedding 参数(通过 Embedding.backward 的 scatter_add)# 所以这里把每个正/负例对 h 的贡献加起来,累积到 dh。最终 dh 是来自正例和所有负例对 h 的总梯度return dh # 返回隐藏层的梯度1.3 改进版word2vec的学习
1.3.1 CBOW模型的实现
改进上一章的简单的SimpleCBOW类:
- 使用Embedding层和Negative Sampling Loss层;
- 将上下文部分扩展为可以处理任意的窗口大小。
class CBOW:def __init__(self, vocab_size, hidden_size, window_size, corpus):V, H = vocab_size, hidden_size# 初始化权重W_in = 0.01 * np.random.randn(V, H).astype('f')W_out = 0.01 * np.random.randn(V, H).astype('f')# 生成层self.in_layers = []for i in range(2 * window_size):layer = Embedding(W_in) # 使用Embedding层self.in_layers.append(layer)self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)# 将所有的权重和梯度整理到列表中layers = self.in_layers + [self.ns_loss]self.params, self.grads = [], []for layer in layers: # 将神经网络中使用的参数和梯度放入成员变量params和grads中self.params += layer.paramsself.grads += layer.grads# 将单词的分布式表示设置为成员变量self.word_vecs = W_indef forward(self, contexts, target):h = 0for i, layer in enumerate(self.in_layers):h += layer.forward(contexts[:, i])h *= 1 / len(self.in_layers)loss = self.ns_loss.forward(h, target)return lossdef backward(self, dout=1):dout = self.ns_loss.backward(dout)dout *= 1 / len(self.in_layers)for layer in self.in_layers:layer.backward(dout)return None实现和训练方法:
# 设定超参数
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10import pickle
import sys,os
import urllib.requestsys.path.append('..')
url_base = 'https://raw.githubusercontent.com/tomsercu/lstm/master/data/'
key_file = { # 原始文本文件名映射(训练/测试/验证)'train':'ptb.train.txt','test':'ptb.test.txt','valid':'ptb.valid.txt'
}
save_file = { # 将处理后的 numpy 数组保存成 .npy 的文件名映射'train':'ptb.train.npy','test':'ptb.test.npy','valid':'ptb.valid.npy'
}
vocab_file = 'ptb.vocab.pkl' # 保存词表映射(word_to_id, id_to_word)的文件名dataset_dir = os.path.dirname(os.path.abspath(__file__)) # 当前脚本所在目录def _download(file_name):file_path = dataset_dir + '/' + file_name # 构建本地目标文件路径if os.path.exists(file_path): # 如果已经存在就直接返回,不重复下载returnprint('Downloading ' + file_name + ' ... ') # 提示用户开始下载try:urllib.request.urlretrieve(url_base + file_name, file_path) # 尝试直接从 GitHub 下载except urllib.error.URLError:import sslssl._create_default_https_context = ssl._create_unverified_context # 忽略 SSL 验证(必要时)urllib.request.urlretrieve(url_base + file_name, file_path) # 再次下载(有时企业/环境的证书会阻止)print('Done')def load_vocab():vocab_path = dataset_dir + '/' + vocab_fileif os.path.exists(vocab_path):with open(vocab_path, 'rb') as f:word_to_id, id_to_word = pickle.load(f)return word_to_id, id_to_wordword_to_id = {} # 新建空字典:词->idid_to_word = {} # 新建空字典:id->词data_type = 'train' # 用训练集文本来构建词表(通常是最大的语料)file_name = key_file[data_type] # 对应的文件名file_path = dataset_dir + '/' + file_name_download(file_name) # 确保原始文本在本地(会跳过已存在的情况)words = open(file_path).read().replace('\n', '<eos>').strip().split()# 打开训练文本,读取为字符串:# 1) 把换行符替换成特殊标记 '<eos>'(end-of-sentence)# 2) strip() 去掉首尾空白# 3) split() 把字符串按空白分割成词列表for i, word in enumerate(words):if word not in word_to_id:tmp_id = len(word_to_id)word_to_id[word] = tmp_idid_to_word[tmp_id] = wordwith open(vocab_path, 'wb') as f:pickle.dump((word_to_id, id_to_word), f) # 把构建好的词表保存到本地,方便下次直接加载return word_to_id, id_to_worddef load_data(data_type='train'):''':param data_type: 数据的种类:'train' or 'test' or 'valid (val)':return:'''if data_type == 'val': data_type = 'valid'save_path = dataset_dir + '/' + save_file[data_type]word_to_id, id_to_word = load_vocab()if os.path.exists(save_path):corpus = np.load(save_path)return corpus, word_to_id, id_to_wordfile_name = key_file[data_type]file_path = dataset_dir + '/' + file_name_download(file_name)words = open(file_path).read().replace('\n', '<eos>').strip().split()corpus = np.array([word_to_id[w] for w in words])np.save(save_path, corpus)return corpus, word_to_id, id_to_word# 读入数据
corpus, word_to_id, id_to_word = load_data('train') # 加载训练语料(id 序列)和词表
vocab_size = len(word_to_id) # 词汇表大小(V)contexts, target = create_contexts_target(corpus, window_size)
# create_contexts_target: (外部函数)把连续的 corpus 转成 CBOW/skip-gram 所需的上下文矩阵 contexts
# 和中心词向量 target。通常:
# - contexts 形状为 (N, 2*window_size)
# - target 形状为 (N,)# 生成模型等
model = CBOW(vocab_size, hidden_size, window_size, corpus)
# model = SkipGram(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)# 开始学习
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()# 保存必要数据,以便后续使用
word_vecs = model.word_vecs
params = {}
params['word_vecs'] = word_vecs.astype(np.float16)
params['word_to_id'] = word_to_id
params['id_to_word'] = id_to_word
pkl_file = 'cbow_params.pkl' # or 'skipgram_params.pkl'
with open(pkl_file, 'wb') as f:pickle.dump(params, f, -1) # -1 指用最高协议保存(兼容性与压缩)会跑10个epoch,如果想快点看到结果,可自己修改小一点。
一般而言,当窗口大小为2~10、中间层的神经元个数(单词的分布式表示的维数)为50~500时,结果会比较好。
在学习结束后,取出权重(输入侧的权重),并保存在文件中以备后用(用于单词和单词ID之间的转化的字典也一起保存)。
上面代码中,使用Python的pickle功能进行文件保存。pickle可以将Python代码中的对象保存到文件中(或者从文件中读取对象)。

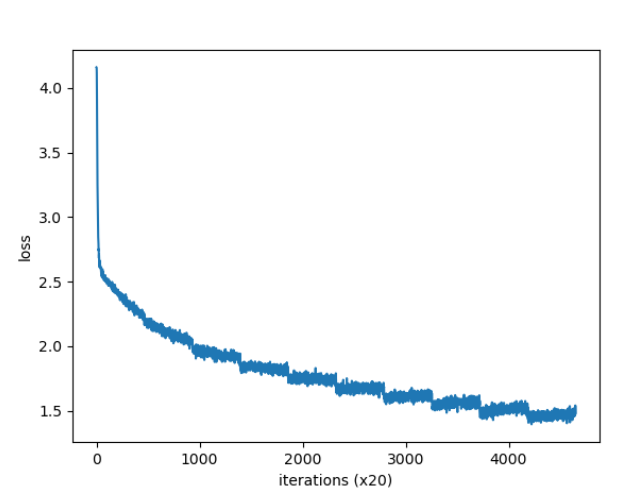
得到的迭代图为:
1.3.2 CBOW模型的评价
利用前面章节实现的most_similar()函数,显示几个单词的最接近的单词:
def cos_similarity(x, y, eps=1e-8):'''计算余弦相似度:param x: 向量:param y: 向量:param eps: 用于防止“除数为0”的微小值:return:'''nx = x / (np.sqrt(np.sum(x ** 2)) + eps)ny = y / (np.sqrt(np.sum(y ** 2)) + eps)return np.dot(nx, ny)def most_similar(query, word_to_id, id_to_word, word_matrix, top=5):'''相似单词的查找:param query: 查询词:param word_to_id: 从单词到单词ID的字典:param id_to_word: 从单词ID到单词的字典:param word_matrix: 汇总了单词向量的矩阵,假定保存了与各行对应的单词向量:param top: 显示到前几位'''if query not in word_to_id:print('%s is not found' % query)returnprint('\n[query] ' + query)query_id = word_to_id[query]query_vec = word_matrix[query_id]vocab_size = len(id_to_word)similarity = np.zeros(vocab_size)for i in range(vocab_size):similarity[i] = cos_similarity(word_matrix[i], query_vec)count = 0for i in (-1 * similarity).argsort():if id_to_word[i] == query:continueprint(' %s: %s' % (id_to_word[i], similarity[i]))count += 1if count >= top:returnpkl_file = 'cbow_params.pkl'
# pkl_file = 'skipgram_params.pkl'with open(pkl_file, 'rb') as f:params = pickle.load(f)word_vecs = params['word_vecs']word_to_id = params['word_to_id']id_to_word = params['id_to_word']# most similar task
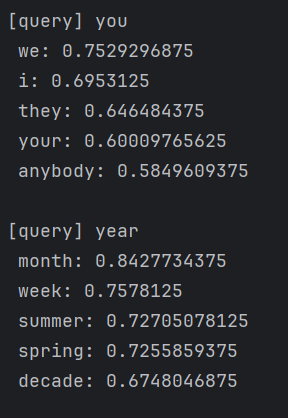
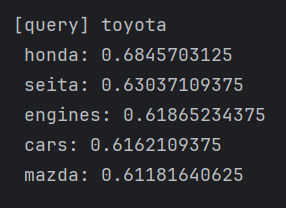
querys = ['you', 'year', 'car', 'toyota']
for query in querys:most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
由word2vec获得的单词的分布式表示不仅可以将近似单词聚拢在一起,还可以捕获更复杂的模式,其中一个具有代表性的例子是因“king-man+woman=queen”而出名的类推问题(类比问题)。
即,使用word2vec的单词的分布式表示,可以通过向量的加减法来解决类推问题。
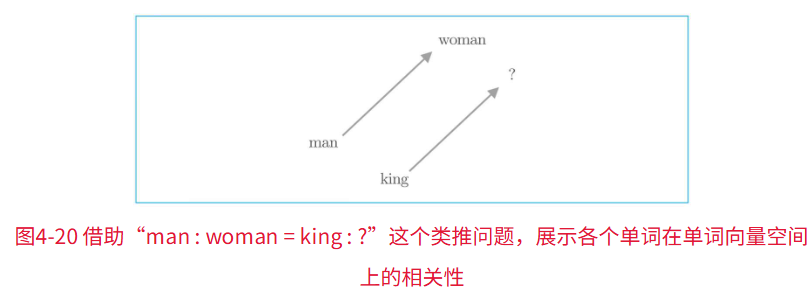
同样,也可以思考,这样的逻辑是否也可以推理出单数与复数、原型和比较级、现在时和过去时等等的词汇呢。
上面代码的结果展示:
1.4 word2vec相关的其他话题
使用word2vec获得的单词的分布式表示可以用来查找近似单词。
单词的分布式表示还可以用在迁移学习上。
关于这点如何理解呢,gpt老师是这样解释的:



在解决自然语言处理任务时,一般不会使用word2vec从零开始学习单词的分布式表示,而是先在大规模语料库(Wikipedia、Google News等文本数据)上学习,然后将学习好的分布式表示应用于某个单独的任务。
常用逻辑: