WeTok Powerful Discrete Tokenization for High-Fidelity Visual Reconstruction
WeTok: Powerful Discrete Tokenization for High-Fidelity Visual Reconstruction
Authors: Shaobin Zhuang, Yiwei Guo, Canmiao Fu, Zhipeng Huang, Zeyue Tian, Ying Zhang, Chen Li, Yali Wang
Deep-Dive Summary:
WETOK:高保真视觉重建的强大离散分词方法
作者:Shaobin Zhuang¹, Yiwei Guo², Canmiao Fu³, Zhipeng Huang⁴, Zeyue Tian⁵
机构:¹上海交通大学, ²微信视觉团队,腾讯公司, ³深圳先进技术研究院,中国科学院, ⁴香港科技大学, ⁵上海人工智能实验室
摘要
视觉分词器是视觉生成中的关键组成部分。然而,现有的分词器在压缩比和重建保真度之间往往面临不令人满意的权衡。为了填补这一空白,我们引入了一种强大且简洁的WeTok分词器,通过两大核心创新超越了之前领先的分词器:(1) 分组无查找量化(GQ)。我们将潜在特征分为多个组,并对每个组执行无查找量化。因此,GQ能够有效克服先前分词器的内存和计算限制,同时通过更具扩展性的码本实现重建突破。(2) 生成式解码(GD)。与之前的分词器不同,我们引入了一个带有额外噪声变量先验的生成式解码器。在这种情况下,GD能够基于离散令牌概率性地建模视觉数据的分布,使WeTok能够在高压缩比下重建视觉细节。在主流基准测试上的广泛实验显示了WeTok的优越性能。在ImageNet 50k验证集上,WeTok实现了创纪录的低零样本rFID(WeTok:0.12,相较于FLUX-VAE:0.18和SD-VAE3.5:0.19)。此外,我们的最高压缩模型在压缩比为768的情况下实现了零样本rFID为3.49,优于Cosmos(压缩比384)的4.57,而后者的压缩率仅为我们的一半。代码和模型已公开:https://github.com/zhuangshaobin/WeTok。
1 引言
在视觉生成领域,像素数据的高计算成本是一个核心挑战(Chen 等人,2020b;Rombach 等人,2022b)。视觉分词器(Visual Tokenizer)是一种关键解决方案,它通过编码器将图像压缩为紧凑的潜在表示,并通过解码器进行重建(Kingma & Welling, 2013;Rezende 等人,2014),从而使生成模型能够在潜在空间中高效运行(Rombach 等人,2022a)。这些分词器主要分为两类:连续型(Kingma & Welling, 2013)和离散型(Van Den Oord 等人,2017)。连续型分词器将图像映射到连续的潜在空间,而离散型分词器则使用量化器生成有限的代码集。这种架构上的差异带来了一项关键的权衡:离散型分词器能够实现更高的压缩比,但这种效率往往以较低的重建保真度为代价,相较于连续型方法。这引发了一个自然的问题:我们能否构建一个离散型分词器,既能保持高压缩比,又能实现高保真重建?
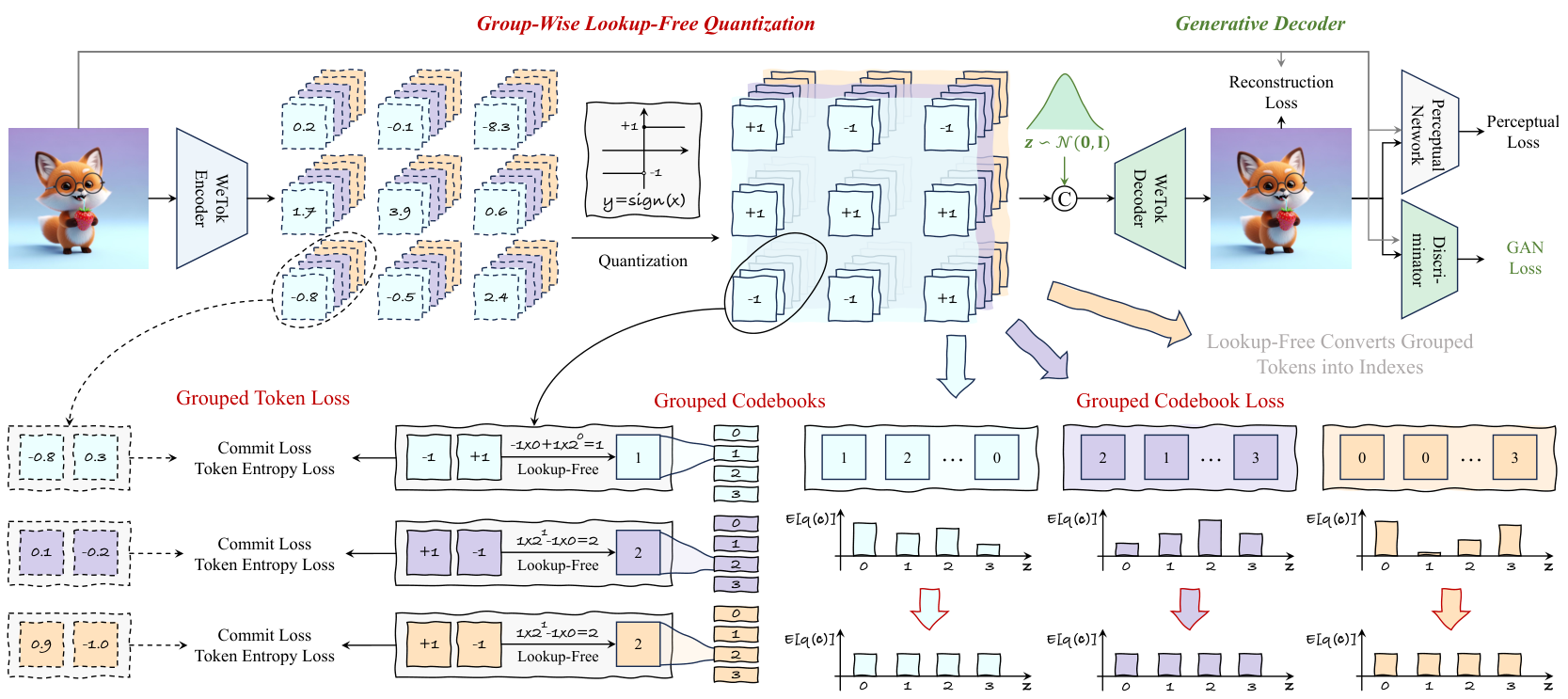
为了实现这一目标,必须解决两个关键问题:(1)可扩展的码本。为了最小化离散型分词器的量化误差,现有方法尝试扩大码本规模(Yu 等人,2024a;Zha0 等人,2024b;Sun 等人,2024)。特别是无查找量化(Lookup-Free Quantization, LFQ)(Yu 等人,2024a)直接对潜在特征进行量化,大幅增加了码本规模以改善重建效果。然而,这需要大量的内存和计算开销。离散型分词器本质上是确定性的,它们并不建模图像的数据分布,而是训练解码器重建图像的期望值(Esser 等人,2020),对应于编码器输出的潜在代码。这种方式在捕捉原始图像的丰富多样性和细致细节方面存在局限,导致重建效果不佳,特别是在高压缩比下。为了填补这一差距,我们引入了一种强大的离散型分词器——WeTok,如图 1 (b) 所示。具体而言,我们提出了两种简洁的设计来解决上述问题。首先,我们开发了分组无查找量化(Group-Wise Lookup-Free Quantization, GQ),将每张图像的潜在特征划分为多个组,并对每个组进行无查找量化。如表 1 所示,我们的 GQ 解决了 LFQ 中熵损失(Chang 等人,2022;Jansen 等人,2019)导致内存使用随码本规模增长的挑战,同时实现了更优的重建性能。其次,我们引入了生成解码器(Generative Decoder, GD),它通过添加额外的噪声变量先验,模仿 GAN 风格的生成器。如图 7 所示,GD 能够有效建模输入图像的数据分布,从而在高压缩比下重建视觉细节。
最后,我们在主流基准数据集上进行了广泛的实验,通过调整 WeTok 的组大小、模型大小和训练数据规模进行扩展。此外,我们在包含 400M 通用领域数据集上对 WeTok 进行了预训练,覆盖多种压缩比。如图 1 (a) 所示,WeTok 持续优于最先进的连续型和离散型分词器,例如在 ImageNet 50k 验证集上的 rFID 指标:WeTok 为 0.12,而 FLUX-VAE 为 0.18(Batifol 等人,2025),SD-VAE3.5 为 0.19(Esser 等人,2024a)。此外,我们的最高压缩模型也实现了卓越的重建性能,例如在 ImageNet 50k 验证集上的 rFID 指标:WeTok 为 3.59,而 Cosmos 为 4.57(Agarwal 等人,2025),而 Cosmos(384)的压缩比仅为 WeTok(768)的一半,展示了 WeTok 的有效性和高效性。
2 相关工作
2.1 连续分词器
在像素空间中进行生成建模通常需要大量的计算资源(Chen 等人,2020a;Ho 等人,2020)。后续工作(Rombach 等人,2022b;Podell 等人,2023;Peebles 等人,2025;Chen 等人,2025)采用了变分自编码器(VAE,Kingma & Welling,2013),将视觉内容从像素投影到潜在特征,从而实现了高效且高分辨率的逼真视觉生成。FLUX-VAE(Batifol 等人,2025)在重建性能上展现了最先进的成果,但因其较低的压缩率而受到批评,因为潜在特征通常以 float32 或 bfloat16 格式存储和计算。因此,能够以 int 或 bool 格式存储数据的离散分词器在压缩能力方面似乎更具潜力。
2.2 离散分词器
离散分词器通常使用向量量化(VQ)将视觉输入转换为离散令牌。但它们都面临由于量化误差导致的重建质量低下以及码本利用不稳定的问题。为了克服这些缺点,后续工作探索了多种路径。一类工作引入了特定的优化策略或模块来提升性能(Lee 等人,2022b;Shi 等人,2024;Zhu 等人,2024;Yu 等人,2024b)。另一类工作则专注于通过使用分组码本缓解码本规模扩展时的训练不稳定性(Ma 等人,2025;Jia 等人,2025;Zhang 等人,2025)。这些方法将输入特征沿通道维度分成多个组,每组使用一个子码本进行查找。然而,尽管有这些改进,基于 VQ 的分词器由于查找操作仍然引入了额外的推理和训练成本(Yu 等人,2021b;Lee 等人,2022b;Fang 等人,2025)。MAGVIT-v2(Yu 等人,2024a)提出了无查找量化(LFQ)来解决这一额外成本,并引入了熵损失(Chang 等人,2022;Jansen 等人,2019)以确保码本的利用率。然而,熵损失随着码本规模线性扩展导致内存成本过高,限制了码本的进一步扩展。二进制球面量化(BSQ)(Zhao 等人,2024a)通过假设二进制码位之间的独立性来缓解这一内存问题,但这种强假设可能导致性能下降,相比 LFQ 有所不足。与上述工作同时,我们的 WeTok 中的 GQ 不依赖显式码本,可以消除熵损失带来的内存使用,同时性能优于 LFQ。
2.3 自回归视觉生成
自回归(AR)建模范式是现代大型语言模型(LLMs)的基础(Vaswani 等人,2017),已成功应用于视觉生成(Chen 等人,2020a),其中模型学习预测图像(Ramesh 等人,2021b;Ding 等人,2021;Liu 等人,2024)和视频(Hong 等人,2022;Kondratyuk 等人,2023)的离散令牌序列。近期 AR 模型(Sun 等人,2024;Team,2024;Wu 等人,2025a;Wang 等人,2024b;Liu 等人,2025)在图像质量上取得了显著成果,凸显了这一范式的巨大潜力。值得注意的是,AR 模型的成功在很大程度上依赖于视觉分词器。因此,我们将 WeTok 应用于 LlamaGen(Sun 等人,2024)框架,以实现高保真且高效的自回归生成。这表明我们的 WeTok 不仅具有压缩能力,其压缩特征也适用于生成模型。
3 方法
在本节中,我们首先为离散标记化奠定必要的基础。然后,我们引入了组级无查找量化(Group-Wise Lookup-Free Quantization, GQ),以统一无查找量化(Lookup-Free Quantization, LFQ)(Yu 等人,2024a)和二进制球面量化(Binary Spherical Quantization, BSQ)(Zhao 等人,2024b)。最后,我们提出了一种专为高压缩场景设计的生成解码器(Generative Decoder, GD),以从我们的 GQ 生成的紧凑表示中重建高保真输出。
3.1 预备知识
向量量化变分自编码器(Vector Quantized Variational Autoencoder, VQVAE)(Eser 等人,2020)
给定一张图像 I∈RH×W×3I \in \mathbb{R}^{H \times W \times 3}I∈RH×W×3,通过在码本 C∈RK×dC \in \mathbb{R}^{K \times d}C∈RK×d 中搜索最近邻,将其量化为隐码 QQQ:
Q[i,j]=argminck∈C∣∣U(i,j)−ck∣∣2,Q[i,j]=\arg\min_{{\bf c}_{k}\in{\cal C}}||{\cal U}(i,j)-{\bf c}_{k}||^{2}, Q[i,j]=argck∈Cmin∣∣U(i,j)−ck∣∣2,
UΘ=U+sg[Q−U],\mathcal{U}_{\Theta}=\mathcal{U}+\mathrm{sg}[\mathcal{Q}-\mathcal{U}], UΘ=U+sg[Q−U],
其中 sg[⋅]\mathrm{sg}[\cdot]sg[⋅] 是停止梯度操作。最后,通过解码器 GGG 将其重构为图像空间 I^=G(UQ)\hat{I} = G(U_Q)I^=G(UQ)。损失函数由五部分组成:
KaTeX parse error: Expected 'EOF', got '\right' at position 354: …}_{\mathrm{N}})\̲r̲i̲g̲h̲t̲|=\mathrm{sg}({…
这里引入了感知损失(perceptual loss)(Zhang 等人,2018)和生成对抗网络损失(GAN loss)以提升视觉质量。
无查找量化(Lookup-Free Quantization, LFQ)(Yu 等人,2024a)
LFQ 引入了一个隐式且不可学习的码本 CLFQ={−1,1}dC_{LFQ} = \{-1, 1\}^dCLFQ={−1,1}d,对隐特征的每个通道进行无查找量化:
Ω[i,j,k]=sign(U[i,j,k]).\Omega[i,j,k]=\mathrm{sign}(\mathcal{U}[i,j,k]). Ω[i,j,k]=sign(U[i,j,k]).
由于 LFQ 中的码本是固定的,因此在 LFQ 训练过程中不需要码本损失。为了解决 VQVAE 中码本利用率崩溃的问题,LFQ 引入了熵损失:
LEntropy(U)=1hw∑i=1h∑j=1wH(q(c∣U[i,j]))−ζH(1hw∑i=1h∑j=1wq(c∣U[i,j])).{\mathcal{L}}_{\mathrm{Entropy}}(U)={\frac{1}{h w}}\sum_{i=1}^{h}\sum_{j=1}^{w}H(q(\mathbf{c}|U[i,j]))-\zeta\,H({\frac{1}{h w}}\sum_{i=1}^{h}\sum_{j=1}^{w}q(\mathbf{c}|U[i,j]))\,. LEntropy(U)=hw1i=1∑hj=1∑wH(q(c∣U[i,j]))−ζH(hw1i=1∑hj=1∑wq(c∣U[i,j])).
二进制球面量化(Binary Spherical Quantization, BSQ)(Zhao 等人,2024b)
当码本规模增大时,内存消耗会显著增加。为了缓解这一问题,BSQ 首先将标记熵损失重写为从 {−1,1}d\{-1, 1\}^d{−1,1}d 到 ddd 个 {−1,1}\{-1, 1\}{−1,1} 的线性组合计算,显著降低了内存消耗。然而,由于 BSQ 对码本熵损失提出的近似方法,BSQ 中的熵损失计算会引入误差。因此,在相同码本规模下,BSQ 的性能不如 LFQ。
3.2 组-wise无查找量化(GROUP-WISE LOOKUP-FREE QUANTIZATION)
在本文中,作者提出了一种新的量化方法,即组-wise无查找量化(GQ),以解决计算成本和优化误差的问题。如公式5所示,函数H()的计算成本随着码本大小的线性增加。为了同时解决这一问题以及BsQ的优化误差问题,作者提出了首先对潜在特征进行分组,然后执行无查找量化的方法。如图2所示,作者对潜在特征进行分组,其中新增的维度代表组的数量,d’表示组通道。对于第k组,分组可以表示为以下公式:
KaTeX parse error: Undefined control sequence: \j at position 50: …cal{M}[{\bf i},\̲j̲])=\displaystyl…
其中,ck表示将c分成g部分后的第k个潜在代码,即Ck = c[(k - 1)d’ + 1 : kd’]。考虑到熵的加性以及公式6,作者将token熵损失项重写为:
LTakenfatylos=1hw∑i=1h∑i=1wH(q(c∣U[i,j])))=1hw∑i=1h∑i=1w∑k=1gH(qG(ck∣UG[i,j,k])).{\mathcal{L}}_{\mathrm{{Takenfatylos}}}={\frac{1}{h w}}\sum_{i=1}^{h}\sum_{i=1}^{w}H(q(\mathbf{c}|U[i,j])))={\frac{1}{h w}}\sum_{i=1}^{h}\sum_{i=1}^{w}\sum_{k=1}^{g}H(q_{G}(\mathbf{c}_{k}|U_{G}[i,j,k])). LTakenfatylos=hw1i=1∑hi=1∑wH(q(c∣U[i,j])))=hw1i=1∑hi=1∑wk=1∑gH(qG(ck∣UG[i,j,k])).
通过这一变换,原始的token熵损失计算从{-1, 1}d空间转变为分组token熵损失,即g个{-1, 1}d空间熵的线性组合,从而消除了token熵损失作为内存瓶颈的问题。
然而,对于码本熵损失,H(≥ *)操作使得作者无法利用熵的加性将{-1, 1}d空间分解为多个子空间的线性组合。因此,作者提出了一个假设:
∑i=1h∑j=1wq(c∣U[i,j])≈∏k=1g∑i=1h∑j=1wqG(ck∣UG[i,j,k]).\sum_{i=1}^{h}\sum_{j=1}^{w}q({\bf c}|\mathcal{U}[i,j])\approx\prod_{k=1}^{g}\sum_{i=1}^{h}\sum_{j=1}^{w}q_{\mathrm{G}}({\bf c}_{k}|\mathcal{U}_{\mathrm{G}}[i,j,k]). i=1∑hj=1∑wq(c∣U[i,j])≈k=1∏gi=1∑hj=1∑wqG(ck∣UG[i,j,k]).
基于此,作者利用熵的加性将码本熵损失转化为:
LColeberiolylos=H(1hw∑i=1h∑j=1wq(c∣U[i,j]))=∑k=1gH(1hw∑i=1h∑j=1wqG(ck∣UG[i,j,k])).{\mathcal{L}}_{\mathrm{{Coleberiolylos}}}=H({\frac{1}{h w}}\sum_{i=1}^{h}\sum_{j=1}^{w}q(\mathbf{c}|U[i,j]))=\sum_{k=1}^{g}H({\frac{1}{h w}}\sum_{i=1}^{h}\sum_{j=1}^{w}q_{\mathrm{{G}}}(\mathbf{c}_{k}|U_{G}[i,j,k])). LColeberiolylos=H(hw1i=1∑hj=1∑wq(c∣U[i,j]))=k=1∑gH(hw1i=1∑hj=1∑wqG(ck∣UG[i,j,k])).
与token熵损失类似,作者将码本熵损失的计算从{-1, 1}d空间转变为分组码本熵损失,即g个{-1, 1}d’空间熵的线性组合。
通过组数量g的控制,GQ提供了一种在近似精度和内存成本之间可调的权衡。当g = 1时,GQ退化为LFQ公式,不使用任何近似,因此以高内存消耗为代价获得高精度。相反,当g = d时,GQ类似于BsQ方法,使用强近似以最小化内存使用,但因此会遭受显著的优化误差。在第4.2节的实验中,作者表明通过选择适当的中间值g,GQ可以在引入最小优化误差的同时显著降低内存开销,从而甚至超越标准的LFQ基准。此外,这种可调设计提供了有效扩展码本到几乎无限大小的灵活性。
3.3 生成解码器 (GENERATIVE DECODER)
与连续分词器不同,以往离散分词器(Esser 等人,2021;Yu 等人,2024a)中的解码器适应的是确定性变换。尽管在训练过程中采用了 GAN 损失,如公式 3 所示,其具体形式如下:
KaTeX parse error: Undefined control sequence: \L at position 58: …Omega})\,=\,\Im\̲L̲_{\ \!\overline…
其中 DDD 是判别器。然而,GAN 损失仅用于辅助提升感知质量。在高压缩率场景下,UQUQUQ 与真实数据之间的对应关系可能不是唯一的。在这种情况下,我们需要解码器转变为生成模型。如图 2 所示,我们从正态分布 N(0,I)N(0, I)N(0,I) 中随机采样 zzz,将其与 UQUQUQ 沿通道维度拼接,然后将结果输入解码器。通过这种方式,GAN 损失被重新表述为:
LGAN(UQ)=Ez∈N(0,1)[log(1−D(G(z,UQ))],{\mathcal{L}}_{\mathrm{{GAN}}}({\mathcal{U}}_{\mathcal{Q}})=\mathbb{E}_{\mathrm{{z}}\in{\mathcal{N}}(0,1)}[\log(1-{\mathcal{D}}({\mathcal{G}}(\mathbf{z},{\mathcal{U}}_{\mathcal{Q}}))], LGAN(UQ)=Ez∈N(0,1)[log(1−D(G(z,UQ))],
其中 UQUQUQ 作为生成过程的条件。从公式 10 到公式 11 的发展不仅仅是将 zzz 拼接到解码器的输入中,更重要的是,解码器的学习目标转变为建模从高斯噪声到以 UQUQUQ 为条件的真实数据分布的变换,从而使其成为生成解码器 (GD)。
为确保训练稳定性,我们采用了分阶段训练过程。在第一阶段,我们使用重构损失(即公式 3、7 和 9)训练 WeTok 模型。在第二阶段,我们调整模型以适应生成任务。具体来说,我们扩展了解码器中 conv_in 层的通道维度以接受 zzz 作为额外输入。为了保留第一阶段学习到的强大重构能力,这些新增通道的权重被初始化为零。这一策略确保在第二阶段开始时,解码器的行为与其预训练状态一致。因此,这种灵活的方法使我们的生成解码器能够有效集成到具有相似架构基础的各种预训练离散分词器中。
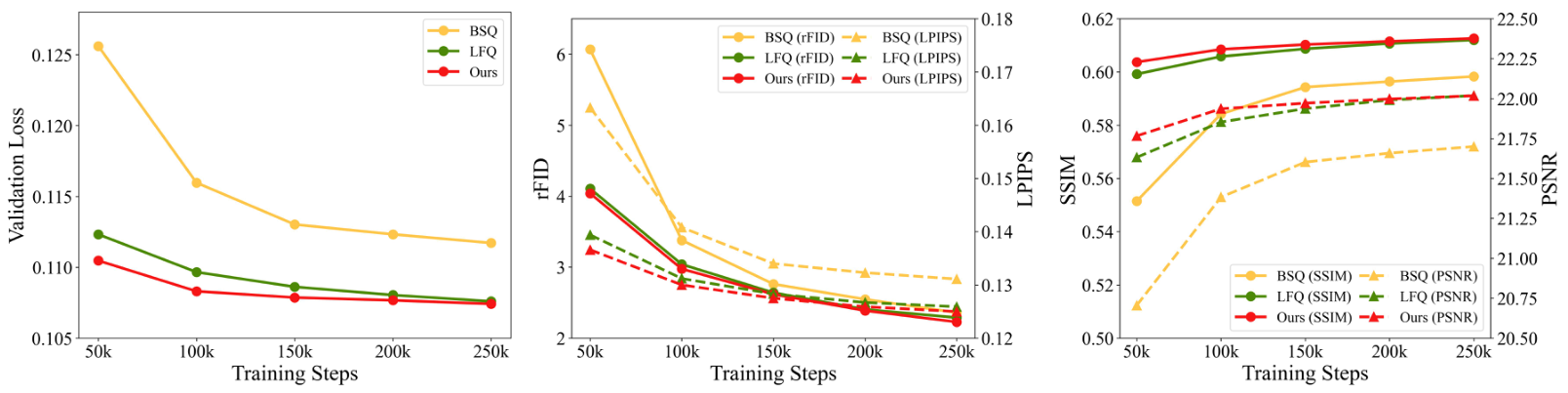
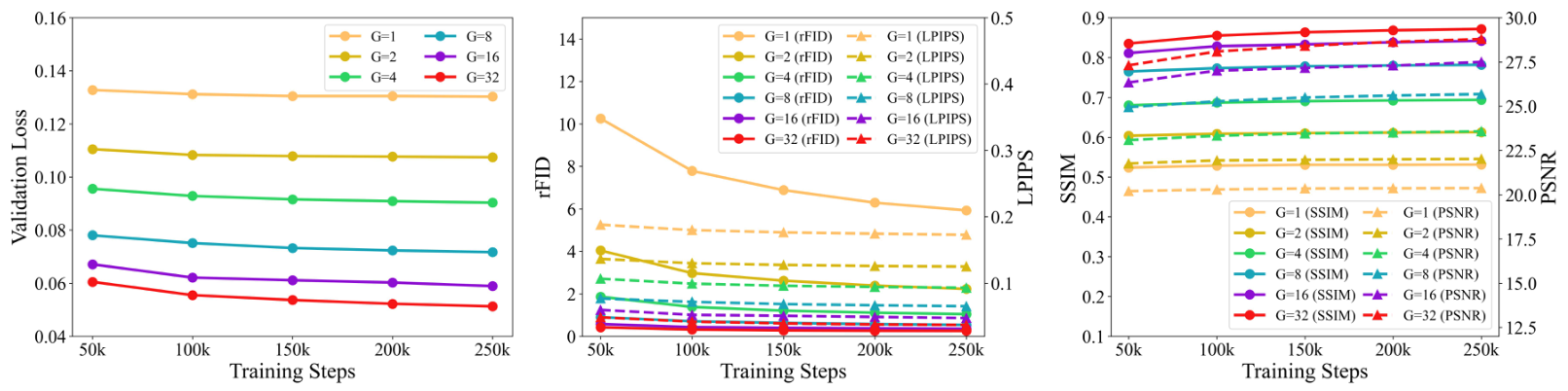
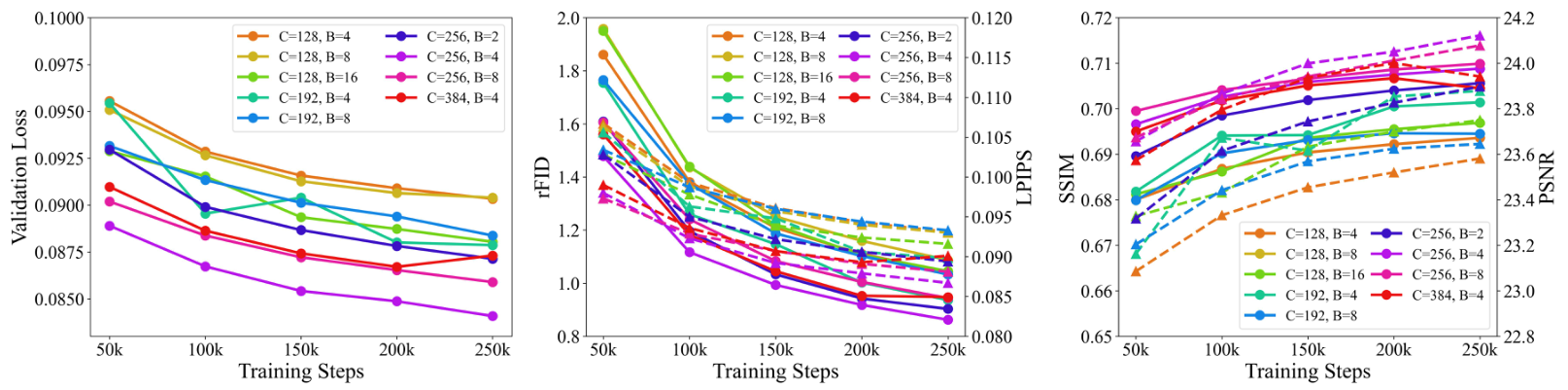
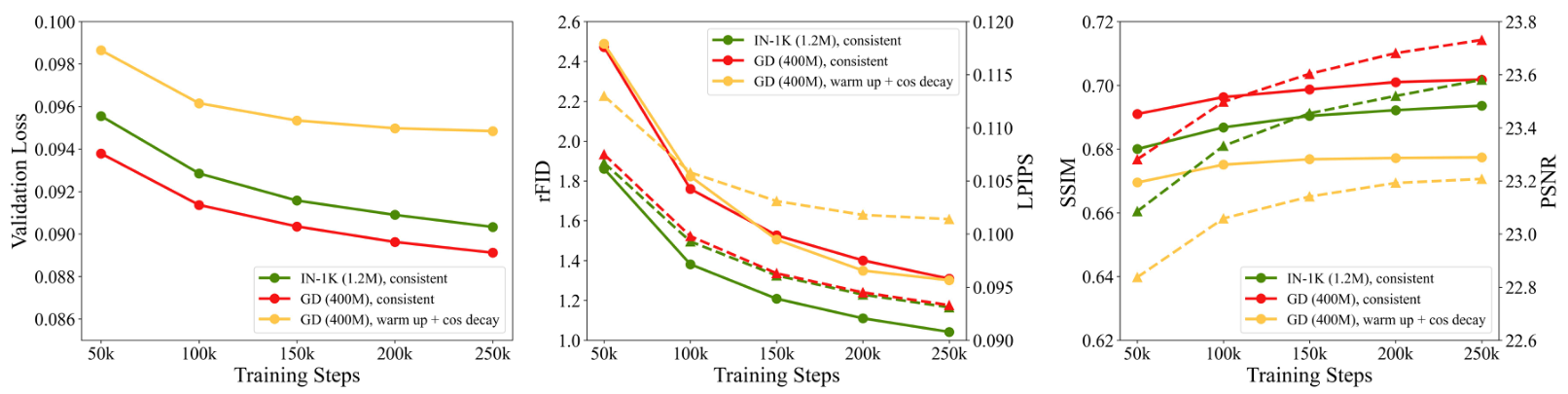

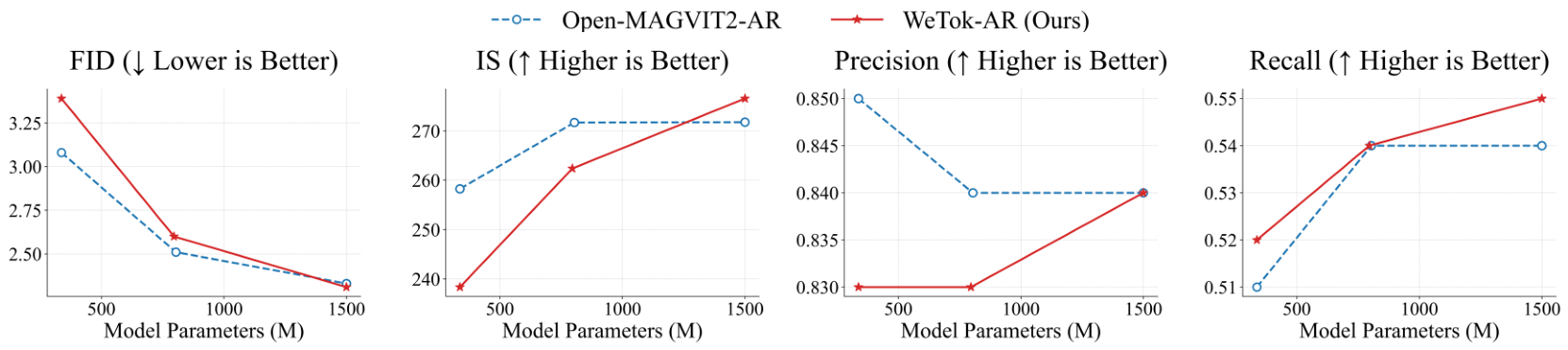
Table 1: Memory usage ablation. We set Table 2: Generative decoder modeling ablation. d’ =8 in GFQ. OOM refers to out of memory. Stage2 refers to generative decoder modeling.


4 实验 # 4.1 实现
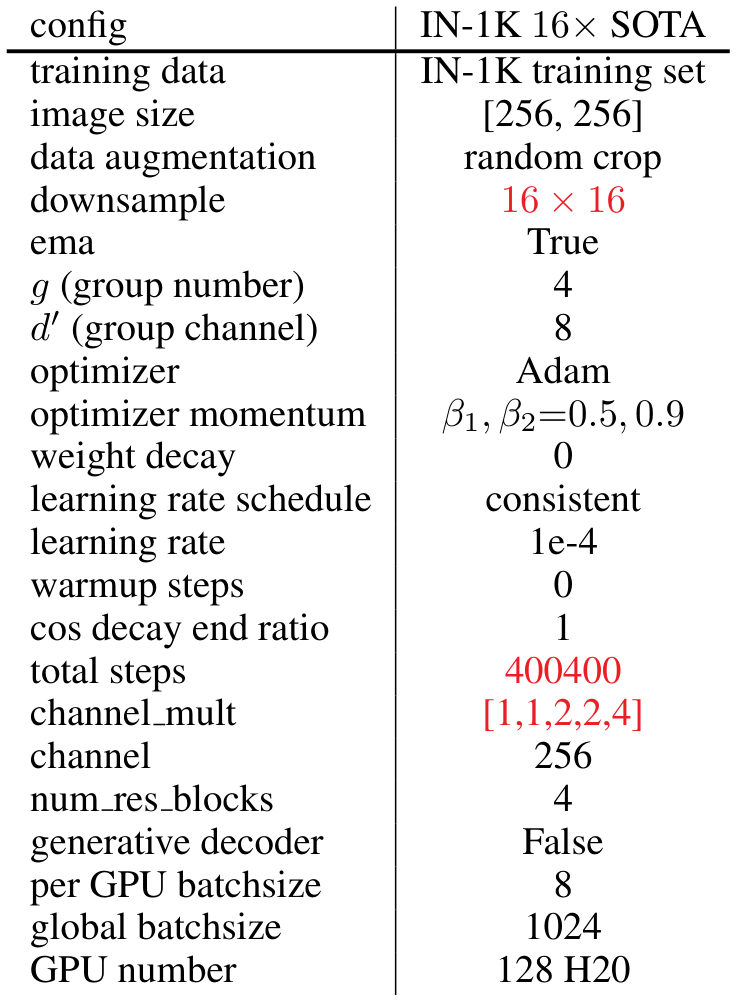
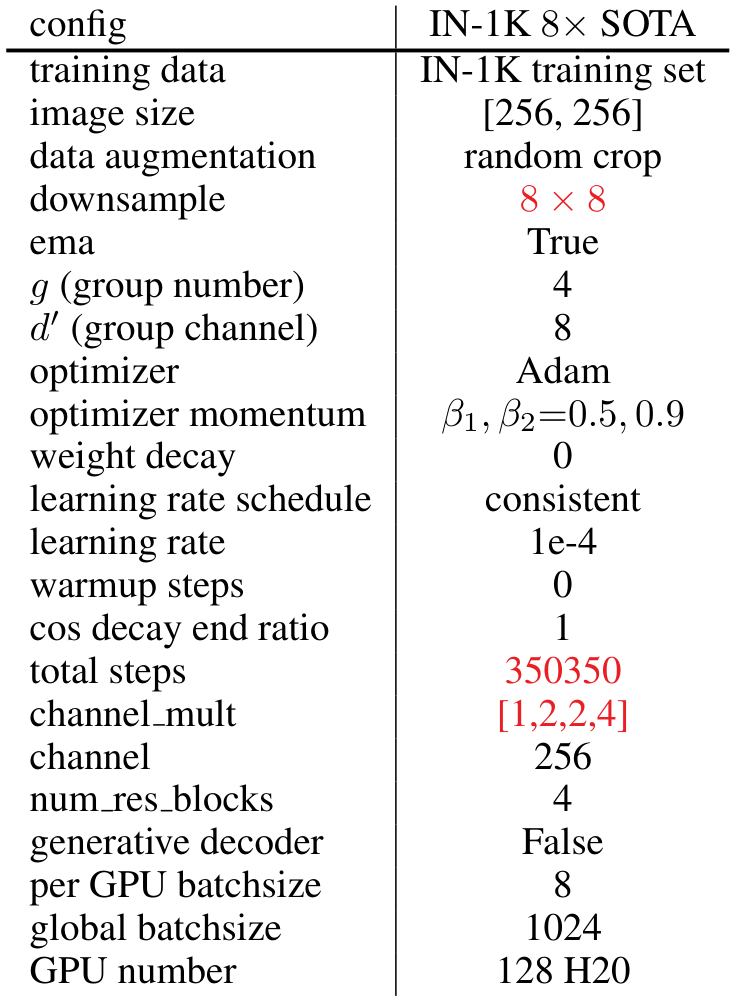
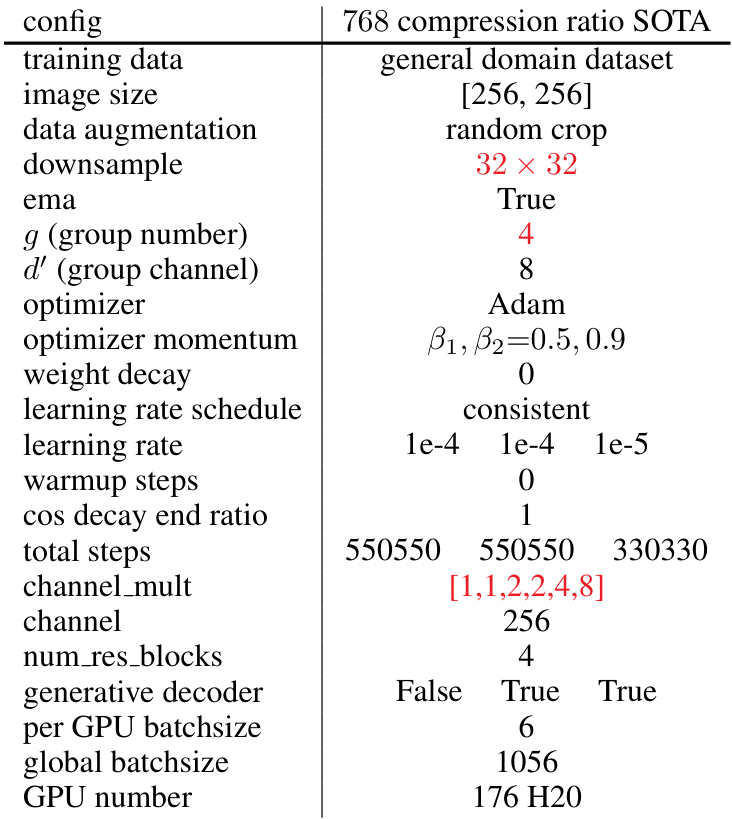
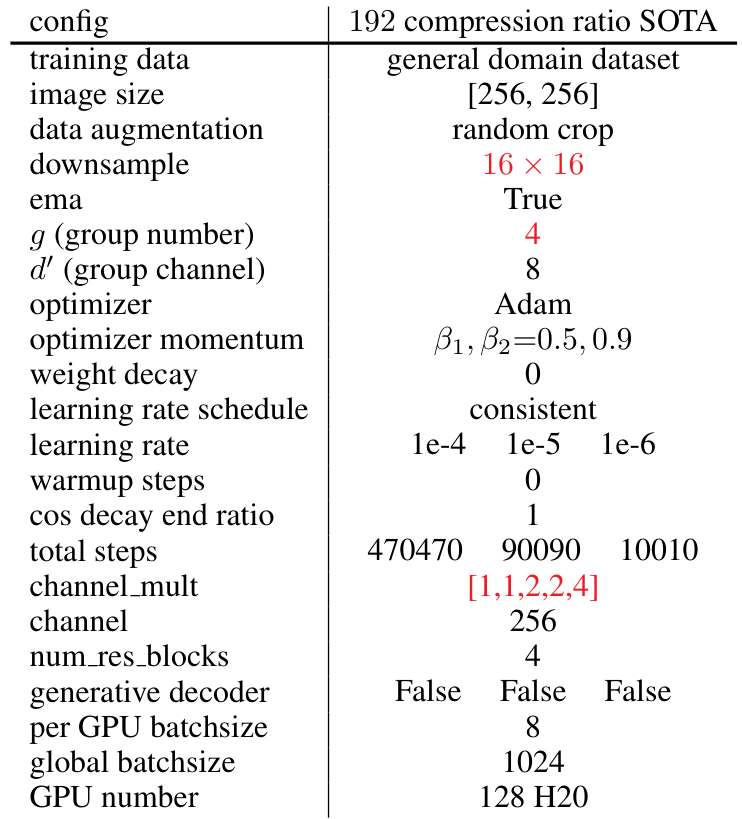
数据集:为了全面评估我们的 WeTok 模型,我们在两个数据集上进行了大规模训练:(i) 1.2M ImageNet 训练集(Russakovsky 等人,2014);(ii) 400M 通用领域数据集。为了与最先进的模型进行比较,我们随后在 ImageNet 50k 验证集和 MS-COCO 2017 验证集(Lin 等人,2014b)上评估了 WeTok 的性能。这种多基准评估确保了我们模型在不同领域和数据分布下的能力得到稳健的评估。除非另有说明,我们在 ImageNet 训练集上进行了一系列消融研究。此外,我们在 ImageNet 训练集上训练类到图像模型,并在验证集上进行测试。
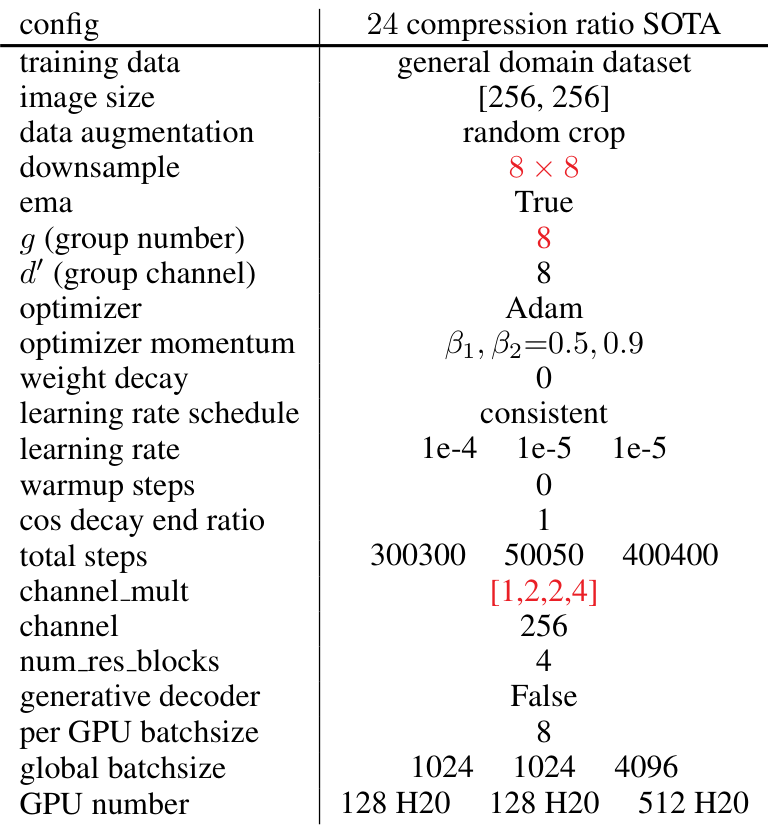
设置:WeTok 采用了 Open-MAGVIT2(Luo 等人,2024)中提出的架构,使用 CNN 架构作为编码器、解码器和判别器。训练时,图像被随机裁剪为 256 × 256 尺寸。在消融研究中,所有模型均训练 250K 步,使用一致的超参数设置,包括固定的学习率 1e-4,最大的全局批次大小为 128,以及 Adam 优化器(Kingma & Ba,2014),其中 β1=0.5β_1 = 0.5β1=0.5 和 β2=0.9β_2 = 0.9β2=0.9。在大规模训练中,我们使用了相同的 Adam 优化器设置,但将最大的全局批次大小增加到 1024。在此阶段,其他超参数针对每个模型单独调整以实现最佳性能。对于类到图像生成,我们采用了 LlamaGen(Sun 等人,2024)中的生成变换器架构。所有实验均使用 H20 GPU 和 Pytorch 进行。更多细节请参见补充材料 A。
4.2 消融研究
我们对WeTok的关键组成部分进行了全面的消融研究,以验证其有效性。首先,我们验证了两个重要算法GQ和GD的有效性。然后,我们分析了不同维度对WeTok性能提升的影响,包括GQ中的组数ggg、模型架构、训练数据和学习率调度。此外,我们基于WeTok对AR模型进行了参数消融实验。更多实现细节见补充材料A.1。我们使用验证损失、rFID(Heusel等人,2017)、LPIPS(Zhang等人,2018)、SSIM(Wang等人,2004)和PSNR来评估消融研究的质量。
量化方法:我们在相同压缩比(即d=gd′=16d = gd' = 16d=gd′=16)下对量化方法进行了消融研究。如表1所示,我们的GQ在量化过程中几乎没有像BSQ那样增加GPU内存使用量。在图3中,我们为3种不同的量化方法设置了相同的压缩比(LFQ:g=1,d′=16g=1, d'=16g=1,d′=16;BSQ:g=16,d′=1g=16, d'=1g=16,d′=1;GQ:g=2,d′=8g=2, d'=8g=2,d′=8),结果表明GQ的表现优于LFQ,且远超BSQ。
生成解码器:当模型在第一阶段的重建训练后性能饱和时,我们进行了第二阶段的生成训练。如表2所示,结果表明GD能够继续提升模型的重建性能,特别是在rFID指标上。此外,我们在图7中展示了定性消融结果。将解码器转换为生成模型后,重建图像更加真实且符合视觉逻辑,证明了GD的有效性。
GQ中的组数:我们以2的幂次增加组数ggg。如图4所示,结果表明随着ggg的增加,模型的重建性能持续显著提升,且不会像LFQ那样遇到内存瓶颈。
模型架构:我们对离散分词器进行扩展的消融研究,重点关注编码器和解码器中的基础通道数和残差块数量。如图5所示,在9种不同设置中,基础通道数为256、残差块数为4的配置实现了最佳重建性能。此最优架构的编码器和解码器分别包含1.98亿和2.61亿参数。
训练数据:我们比较了在1.2M ImageNet训练集上训练的模型和在更大规模的4000万通用领域数据集上训练的模型。如图6所示,在通用领域数据集上训练的模型在验证损失、SSIM和PSNR分数上表现更好。然而,其rFID和LPIPS分数较差。我们将其归因于数据分布差距。ImageNet训练和验证集是同分布的,而通用领域数据的多样性显著更高。这揭示了泛化能力和特定同分布评估指标性能之间的权衡。
学习率调度:通常在训练模型时广泛采用由预热阶段和余弦衰减组成的学习率调度。然而,我们发现这种惯例对于离散分词器的训练可能并非最佳。如图6所示,使用恒定学习率的模型表现出明显更好的性能。基于此,我们在WeTok的所有后续大规模训练中均采用了恒定学习率调度。
自回归模型参数:如图8所示,我们对基于WeTok的AR模型的参数规模进行了消融实验,并将其与基于Open-MAGVIT2的AR模型进行了比较。实验结果表明,当参数规模较小时,基于WeTok的AR模型性能略逊于基于Open-MAGVIT2的AR模型。然而,随着参数规模的增加,基于WeTok的AR模型在所有指标上均超越了基于Open-MAGVIT2的AR模型。

4.3 与最先进技术的比较
视觉重建
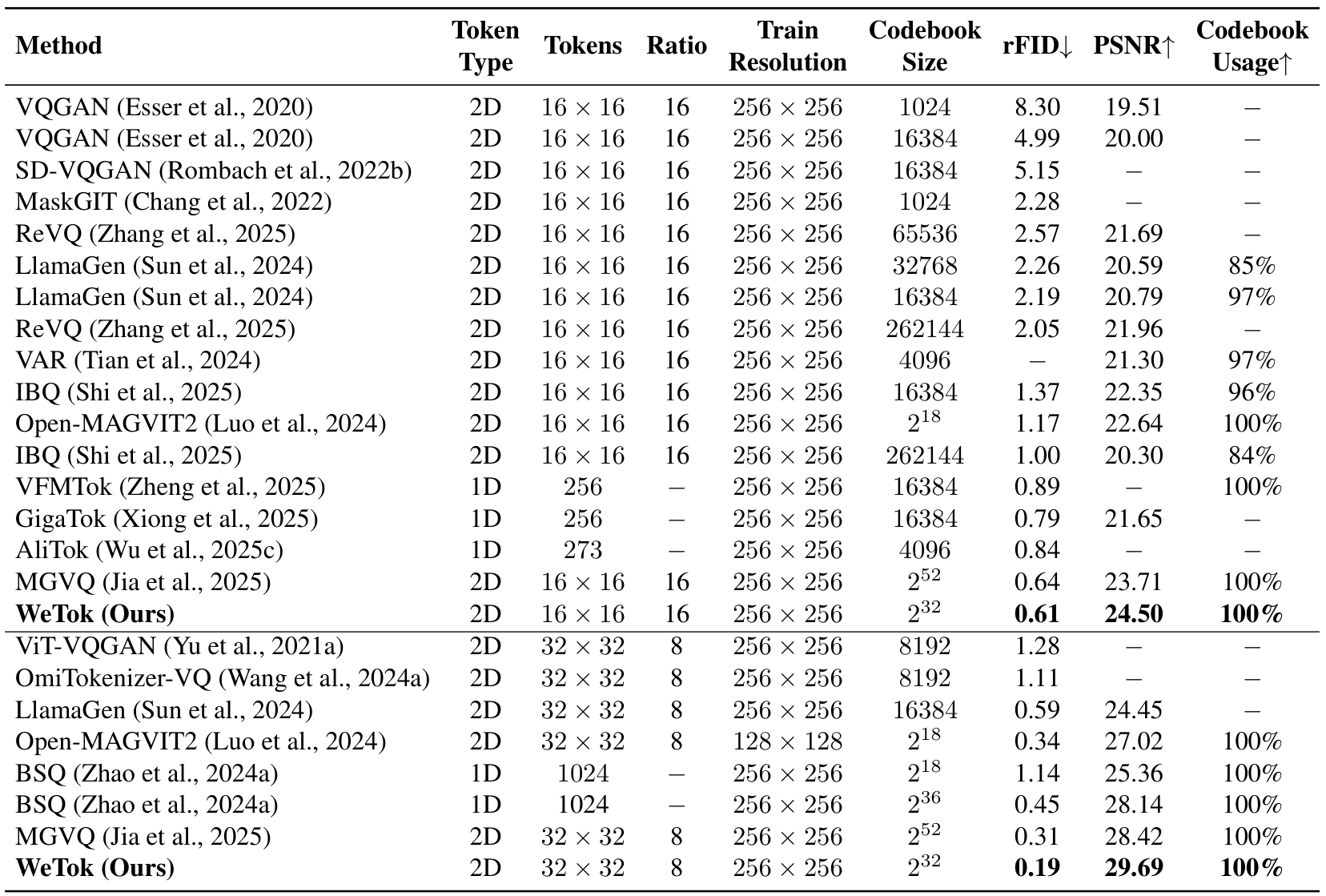
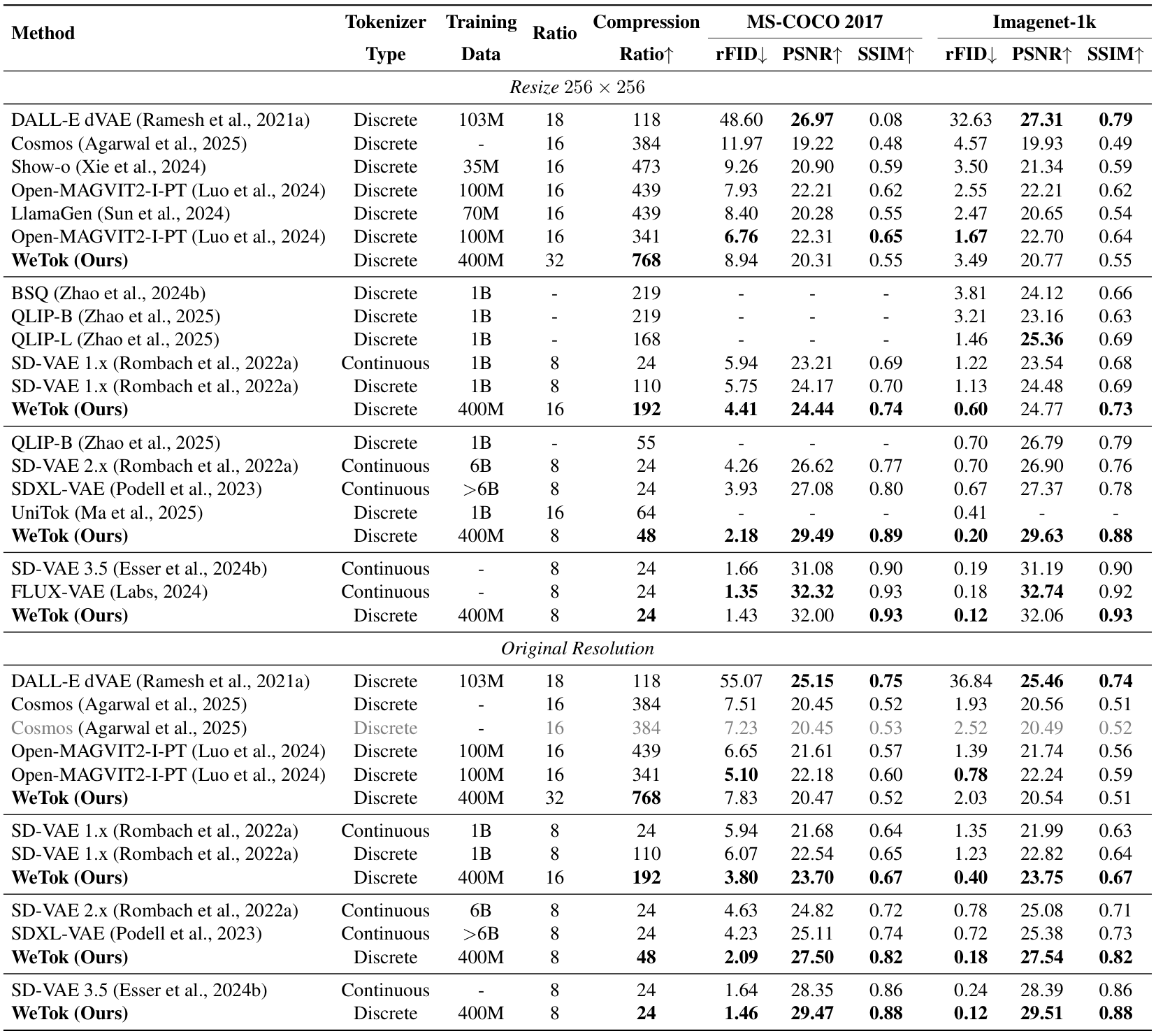
我们首先在分布内设置中评估了 WeTok 的性能,其中训练和验证数据均来自 ImageNet 数据集。这在解决更复杂的分布差距挑战之前,确立了我们模型的核心有效性。如表 3 所示,WeTok 在不同的下采样比例下实现了最先进的重建性能,优于现有的方法。随后,我们将 WeTok 与其他方法进行比较,所有模型都在大规模通用领域数据集上进行训练。为了确保公平和无偏见的比较,我们仔细过滤了该数据集,排除了 ImageNet 和 MS-COCO(Lin 等人,2014a)中的任何数据样本。这一步至关重要,可防止潜在的数据泄露,并确保评估准确衡量模型从广泛数据分布到特定目标领域的泛化能力。如表 4 所示,我们的 WeTok 在广泛的压缩比场景中展示了最先进的重建性能。它不仅在离散分词器中表现出最强的性能,甚至超越了当前最强的连续分词器 FLUX-VAE(Labs,2024)和 SD-VAE 3.5(Esser 等人,2024a)。此外,我们在 TokBench(Wu 等人,2025b)上展示了定性比较结果,如图 9 所示。

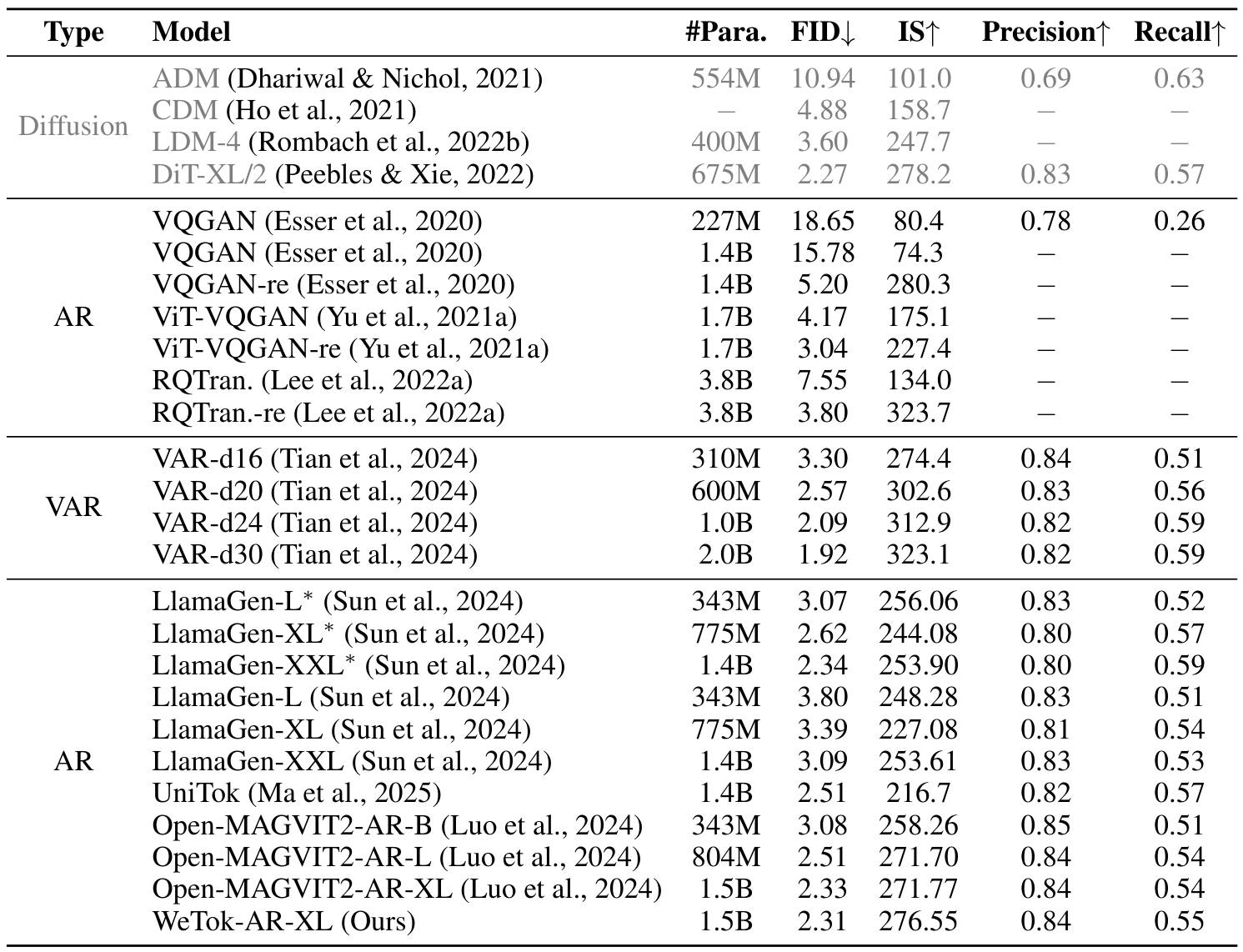
与广泛使用的 SDXL-VAE(Podell 等人,2023)和 SD-VAE 1.5(Rombach 等人,2022b)相比,WeTok 在相同压缩比下的重建性能显著优越。
视觉生成
为了评估 WeTok 在图像重建之外的能力,我们将其应用扩展到视觉生成。我们采用基于 LlamaGen 修改的自回归模型 Open-MAGVIT2 来完成此任务,主要是因为此类模型具有良好的可扩展性。具体来说,我们使用表 3 中具有 16 倍下采样的分布内 WeTok 作为图像分词器。更多训练细节可在补充材料 A.2 中找到。如表 5 所示,我们基于 WeTok 的生成模型在 ImageNet 50K 验证集上实现了最先进的性能。这一结果表明,我们的 WeTok 不仅在图像重建方面是一个高效的分词器,而且在高保真视觉生成任务中也表现出色。如图 10 所示,我们展示了 WeTok-AR-XL 逼真且多样的图像生成结果。
5 结论
在本文中,我们介绍了WeTok,一个强大的离散视觉分词器,旨在解决压缩效率与重建保真度之间的长期冲突。我们的主要贡献包括分组无查找量化(Group-Wise Lookup-Free Quantization, GQ)方法,该方法为码本提供了一个可扩展且内存高效的解决方案,以及生成解码器(Generative Decoder, GD),即使是从高度压缩的表示中也能生成高保真图像。通过广泛的实验,我们展示了WeTok在各种压缩比下的分布内和零样本重建任务中始终优于现有的最先进的离散和连续分词器。此外,通过将WeTok集成到自回归框架中,我们在类别条件图像生成中实现了最先进的性能,证实了其学习的令牌在下游生成任务中非常有效。WeTok建立了一个新的性能标准,证明离散分词器可以在不牺牲其固有的压缩优势的情况下实现卓越的重建质量。
参考文献
(此处保留原文参考文献内容,未进行翻译或修改,保持原格式)
更多实现细节
(此处保留原文标题,内容未提供具体细节,未进行翻译或修改)
A.1 消融研究
量化方法:如表6、7和8所示。
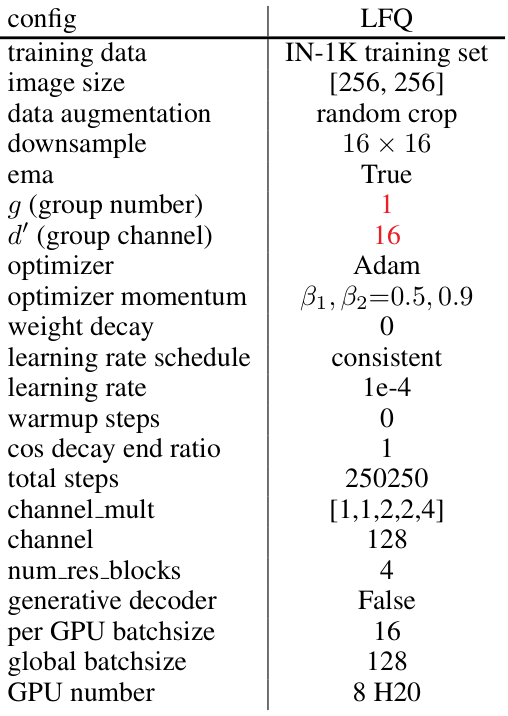
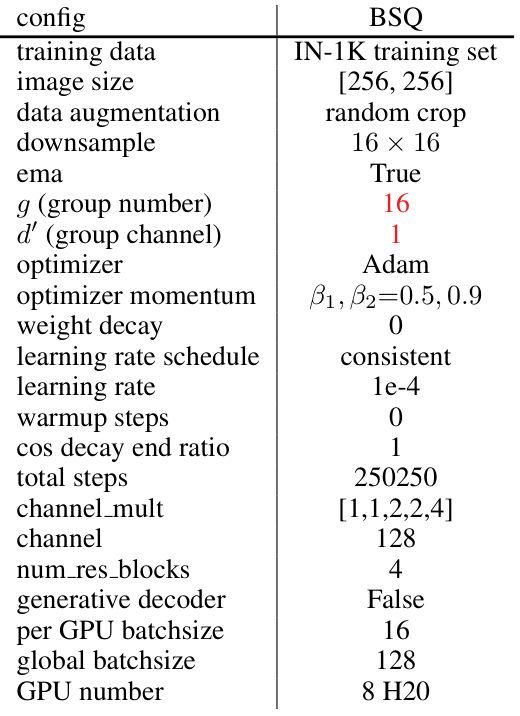
生成式解码器:如表9和10所示。


GQ中的分组数量:如表11、12、13、14、15和16所示。
模型架构:如表17、18、19、20、21、22、23、24和25所示。
训练数据:如表26和27所示。
学习率调度:如表28所示。
自回归模型参数:如表29、30和31所示。



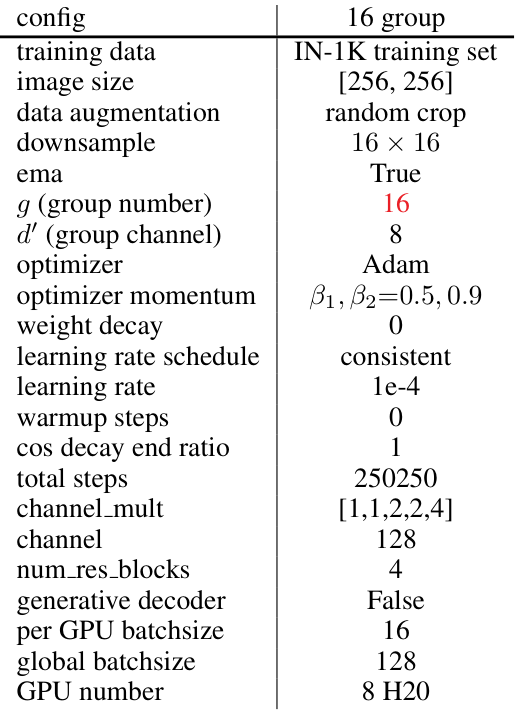
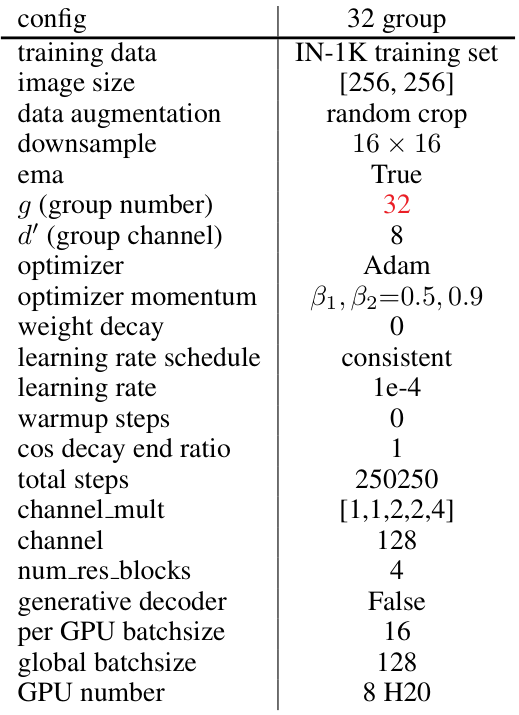



Table 21: 128 channel 16 blocktraining setting.



Table 24: 384 channel 4 blocktraining setting.






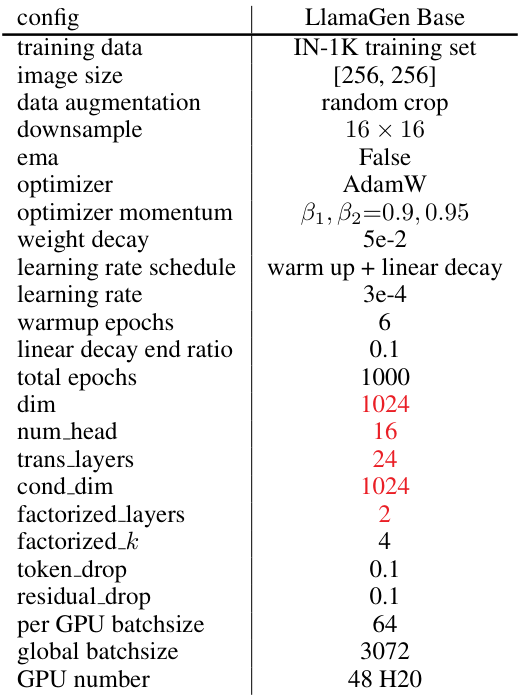
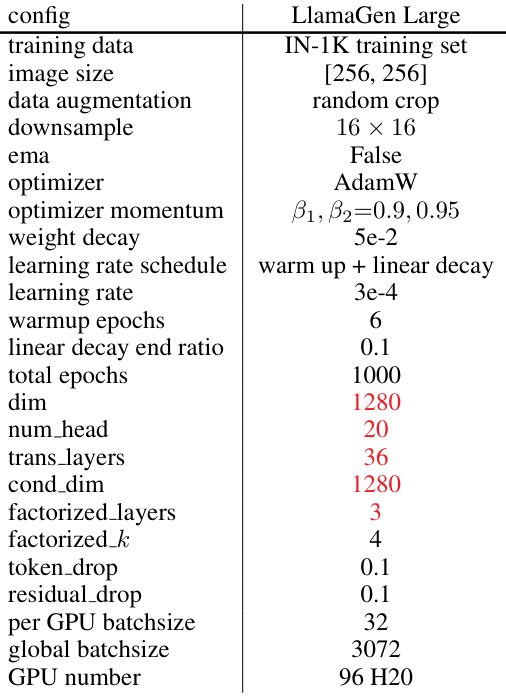
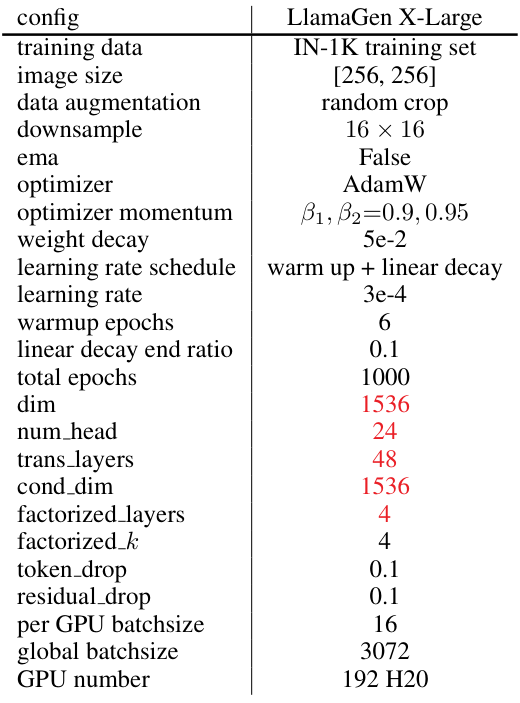
A.2 与最先进方法的比较
视觉重建:分布内比较的设置如表32和33所示。通用领域比较的设置如表34、35、36和37所示。
视觉生成:如表31所示。

Original Abstract: Visual tokenizer is a critical component for vision generation. However, the
existing tokenizers often face unsatisfactory trade-off between compression
ratios and reconstruction fidelity. To fill this gap, we introduce a powerful
and concise WeTok tokenizer, which surpasses the previous leading tokenizers
via two core innovations. (1) Group-wise lookup-free Quantization (GQ). We
partition the latent features into groups, and perform lookup-free quantization
for each group. As a result, GQ can efficiently overcome memory and computation
limitations of prior tokenizers, while achieving a reconstruction breakthrough
with more scalable codebooks. (2) Generative Decoding (GD). Different from
prior tokenizers, we introduce a generative decoder with a prior of extra noise
variable. In this case, GD can probabilistically model the distribution of
visual data conditioned on discrete tokens, allowing WeTok to reconstruct
visual details, especially at high compression ratios. Extensive experiments on
mainstream benchmarks show superior performance of our WeTok. On the ImageNet
50k validation set, WeTok achieves a record-low zero-shot rFID (WeTok: 0.12 vs.
FLUX-VAE: 0.18 vs. SD-VAE 3.5: 0.19). Furthermore, our highest compression
model achieves a zero-shot rFID of 3.49 with a compression ratio of 768,
outperforming Cosmos (384) 4.57 which has only 50% compression rate of ours.
Code and models are available: https://github.com/zhuangshaobin/WeTok.
PDF Link: 2508.05599v1
部分平台可能图片显示异常,请以我的博客内容为准
