【AI论文】种子扩散模型:一种具备高速推理能力的大规模扩散语言模型
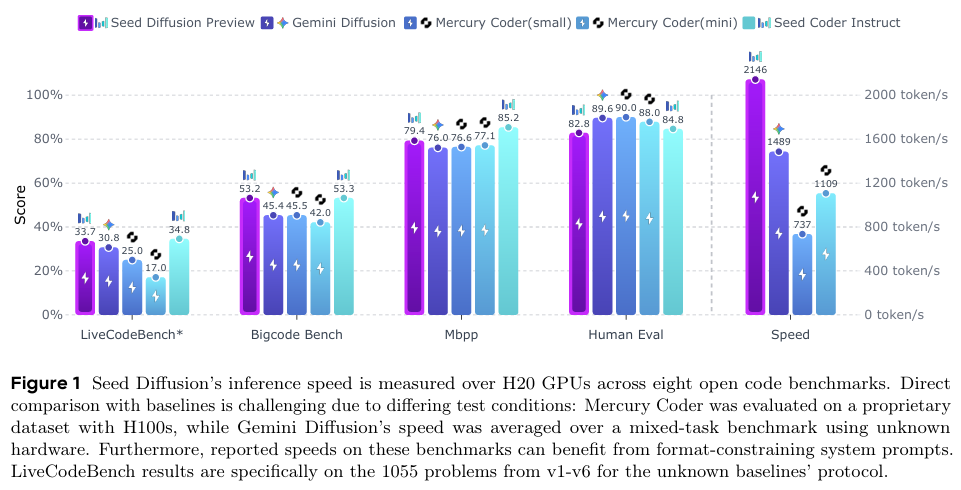
摘要:我们推出种子扩散预览版(Seed Diffusion Preview),这是一款基于离散状态扩散的大型语言模型,具备极为出色的高速推理能力。得益于非顺序、并行生成特性,离散扩散模型大幅提升了推理速度,有效缓解了逐标记解码所固有的延迟问题,近期已有相关研究(如Mercury Coder、Gemini Diffusion)对此进行了验证。种子扩散预览版在H20 GPU上实现了每秒2146个标记(token/s)的推理速度,同时在一系列标准代码评估基准测试中保持了极具竞争力的性能表现,其速度显著快于同时期的Mercury和Gemini Diffusion模型,在代码模型的速度-质量帕累托前沿树立了新的标杆。Huggingface链接:Paper page,论文链接:2508.02193
研究背景和目的
研究背景
随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,其在各种复杂任务中的表现日益突出。然而,传统的语言模型主要依赖于自回归(AR)解码方式,即逐个生成标记(token),这种方式在处理长序列时存在固有的延迟问题,限制了模型的推理速度。为了解决这一问题,研究人员开始探索非自回归(NAR)模型,其中扩散模型(Diffusion Models)作为一种新兴的生成模型,因其独特的生成方式和潜在的高速推理能力而备受关注。
扩散模型最初在图像和视频合成领域取得了显著成功,通过逐步去噪的过程生成高质量的数据。然而,将扩散模型应用于离散的自然语言领域时,面临着一系列挑战。首先,标准扩散过程定义在连续状态空间上,而自然语言是离散的。其次,自然语言的生成通常遵循从左到右的顺序,而扩散模型的并行生成特性可能导致生成顺序的混乱,影响模型性能。
尽管如此,离散扩散模型通过将离散标记映射到连续潜在空间或直接定义离散状态转移矩阵,展现了在自然语言生成中的潜力。然而,实际应用中仍存在两大关键挑战:一是标记顺序建模的归纳偏置问题,即随机顺序学习信号可能对语言建模效率产生不利影响;二是推理效率问题,尽管扩散模型是非自回归的,但其迭代去噪过程仍可能引入严重延迟。
研究目的
本研究旨在通过引入种子扩散预览版(Seed Diffusion Preview)模型,解决离散扩散模型在自然语言生成,特别是代码生成任务中的速度和性能平衡问题。具体目标包括:
- 提升推理速度:通过非顺序、并行生成方式,显著提高语言模型的推理速度,缓解逐标记解码的延迟问题。
- 保持竞争性能:在提高推理速度的同时,确保模型在标准代码评估基准测试中保持与自回归模型相当的性能。
- 探索离散扩散模型的应用潜力:验证离散扩散模型在代码生成任务中的有效性和可行性,为未来更复杂的自然语言处理任务提供基础。
研究方法
模型架构
种子扩散预览版模型采用标准密集Transformer架构,这是为了在初始版本中建立强大且高效的性能基准,故意省略了复杂组件(如LongCoT推理)。模型专注于代码生成任务,因此采用了与开源Seed Coder项目相同的数据管道和处理方法。
两阶段课程训练(TSC)
为了应对离散扩散模型训练中的挑战,研究提出了两阶段课程训练方法:
- 缩放扩散训练:模型使用两种类型的前向腐蚀过程进行训练。前80%的训练步骤采用基于掩码的腐蚀过程,逐渐将原始序列中的标记替换为特殊掩码标记。后20%的训练步骤引入基于编辑的腐蚀过程作为增强,通过控制编辑操作的数量来近似控制语言距离,提高模型的校准能力并消除采样过程中的意外行为(如重复)。
- 约束顺序扩散训练:在两阶段扩散学习后,创建最优生成轨迹的蒸馏数据集。通过预训练扩散模型生成大量候选轨迹,并基于最大化证据下界(ELBO)的标准筛选出高质量轨迹,用于微调模型。这一步骤旨在减少冗余和有害的生成顺序对模型性能的影响。
在策略扩散学习
为了充分发挥并行解码的潜力,研究提出了在策略学习范式:
- 优化目标:优化从全掩码序列开始的反向过程轨迹,使用模型基础的验证器确保采样过程收敛到合理/正确的样本。
- 渐进式替代损失:观察到直接最小化轨迹长度导致训练动态不稳定,研究优化了基于轨迹样本步数和Levenshtein距离之间比例关系的渐进式替代损失,以实现稳定的训练过程。
块级并行扩散采样
为了平衡计算和延迟,研究采用了块级并行扩散采样方案,保持块间的因果顺序。生成第n个块时,反向过程依赖于先前生成的块,使用KV缓存来条件后续块的生成。尽管存在引入潜在偏差的风险,但实证观察表明生成质量没有显著下降,这可能归因于约束顺序轨迹的蒸馏作用。
研究结果
推理速度
种子扩散预览版模型在H20 GPU上实现了每秒2146个标记的推理速度,显著快于同时期的Mercury和Gemini Diffusion模型。这一速度提升主要归因于非顺序、并行生成方式,有效缓解了逐标记解码的延迟问题。
性能表现
在标准代码评估基准测试(如HumanEval、MBPP、BigCodeBench和LiveCodeBench)中,种子扩散预览版模型保持了与自回归模型相当的性能表现。具体来说,模型在HumanEval和MBPP基准测试中展示了强大的基本编码能力,在BigCodeBench中展现了处理涉及多工具使用的现实世界编程任务的能力,并在LiveCodeBench中展示了解决竞争性编码问题的能力。
编辑能力
在Aider和CanItEdit等代码编辑基准测试中,种子扩散预览版模型展示了强大的代码编辑能力。模型能够准确理解并执行编辑指令,无需人工干预即可自动应用修改,这在现实世界中的代码维护和优化任务中具有重要意义。
研究局限
尽管种子扩散预览版模型在推理速度和性能表现上取得了显著成果,但仍存在以下局限:
- 标记顺序建模的归纳偏置:尽管通过两阶段课程训练和约束顺序扩散训练缓解了这一问题,但随机顺序学习信号仍可能对模型性能产生不利影响。
- 推理效率的进一步提升:尽管实现了显著的推理速度提升,但扩散模型的迭代去噪过程仍可能引入延迟,特别是在处理长序列时。
- 数据依赖性和泛化能力:模型性能高度依赖于训练数据的质量和多样性,可能在面对未见过的代码模式或复杂任务时表现不佳。
未来研究方向
针对研究局限,未来研究可从以下几个方面展开:
- 改进标记顺序建模:探索更有效的标记顺序建模方法,减少随机顺序学习信号对模型性能的不利影响。例如,可以研究基于注意力机制的顺序建模方法,或利用外部知识库指导生成顺序。
- 优化推理效率:进一步研究并行生成和迭代去噪过程的优化方法,减少推理延迟。例如,可以探索更高效的采样策略或引入近似推理方法。
- 增强数据多样性和泛化能力:通过引入更多样化的训练数据和增强模型对未见过的代码模式的适应能力,提高模型的泛化性能。例如,可以利用数据增强技术生成更多样化的代码示例,或研究少样本学习(Few-shot Learning)和零样本学习(Zero-shot Learning)方法。
- 探索更复杂的自然语言处理任务:将种子扩散模型应用于更复杂的自然语言处理任务,如机器翻译、文本摘要和问答系统等。通过在这些任务中验证模型的有效性和可行性,进一步推动离散扩散模型在自然语言处理领域的应用和发展。