机器学习概念1
了解机器学习
1、什么是机器学习
机器学习是一门通过编程让计算机从数据中进行学习的科学
通用定义:机器学习是一个研究领域让计算机无须进行明确编程就具备学习能力
工程化定义:一个计算机程序利用经验E来学习任务T,性能是P,如果针对任务T的性能P随着经验E不断增长,则称为机器学习
系统用来学习的样例称为训练集
每个训练样例称为训练实例(或样本)
机器学习系统中学习和做出预测的部分称为模型
正例:垃圾邮件过滤器,可以根据给定的垃圾邮件(由用户标记)和普通电子邮件(非垃圾邮件)学习标记垃圾邮件。
在这个示例中,任务T:标记新邮件是否为垃圾邮件,
经验E:训练数据(之前大量的数据邮件),需要定义性能度量P
例如,可以使用正确分类电子邮件的比率,这种性能指标称为精度,用于分类任务。
反例:可以下载所有百度百科文章到电脑,这样计算机会拥有很多数据,但它不会擅长任何任务,这不是机器学习
2、传统流程和机器学习开发流程对比
| 传统开发流程 | 机器学习的开发流程 |
|---|---|
| 明确需求和规则(但一般情况下规则写不全) | 收集数据 |
| 写程序 | 预处理数据 |
| 测试调试(难以泛化,容易误判) | 训练模型(自动从数据中学习规则) |
| 修复bug(高误判/漏判风险) | 调整模型参数、估计性能(从多样化样本中学习泛化特征) |
| 上线维护(难以维护,需要反复更新) | 部署模型,收集反馈再训练(模型再训练,自我改进) |
3、总结
机器学习非常适合:
1. 现有解决方案需要大量微调或一长串规则来解决的问题 (通过训练模型简化代码,而且比传统方法执行的更好)
2. 使用传统方法无法解决的复杂问题,但机器学习技术可能可以找到解决方法 (识别图片里是否有行人;自动标出图片里行人出现的区域)
3. 变化的环境(机器学习系统可以很容易地根据新数据重新训练,保持最新的状态)
4. 定义明确的复杂问题(不是通过定义规则能解决的),且有大量数据
机器学习的类型
一、按数据反馈形式分类
定义模型如何从数据中学习
1、无监督学习
无监督学习的训练数据是未标记的(也就是没有任何标签、明确分类的信息)发现数据内在结构,以下是几种无监督学习的任务和例子:
(1)聚类算法(层次聚类算法)
假设你有大量关于博客访客的数据。你可能想要运行聚类算法来检测相似访客的分组。你不会告诉算法访客属于哪个组:它无须你的帮助即可找到这种关联。
例如,它可能会注意到40%的访客是喜欢漫画书的青少年,通常在放学后阅读你的博客,而20%的访客是喜欢科幻小说的成年人,并通常在周末访问。如果你使用层次聚类算法,它还可以将每个组细分为更小的组。这可以帮助你针对不同的组来发布博客内容。
(2)可视化算法
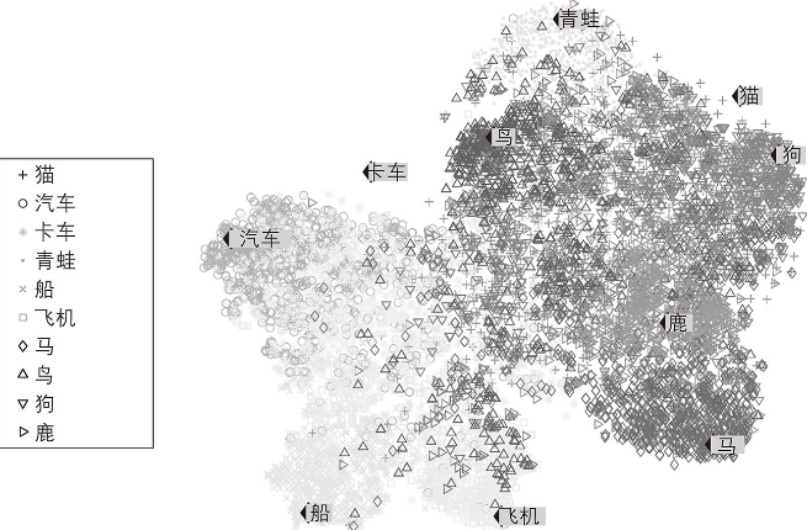
你提供大量复杂且未标记的数据,算法轻松绘制输出2D或3D的数据表示。这些算法试图尽可能多地保留结构(例如,试图防止输入空间中的单独集群在可视化中重叠),以便于你可以了解数据的组织方式,并可能识别出一些未知的模式、趋势和异常。
这张图相当于将词转化为空间中的向量,通过可视化看出词与词之间的相似程度,但没有具体将他们区分出来
(3)降维
降维,其目标是在不丢失太多信息的情况下简化数据。一种方法是将几个相关的特征合并为一个。
例如,一辆汽车的行驶里程可能与其车龄有很强的相关性,因此降维算法会将它们合并为一个代表汽车磨损的特征。这称为特征提取。
在将训练数据提供给另一个机器学习算法(例如监督学习算法)之前,先使用降维算法减少训练数据的维度通常是个好主意。算法会运行得更快,数据会占用更少的磁盘和内存空间,并且在某些情况下,它还可能表现得更好。
(4)异常检测
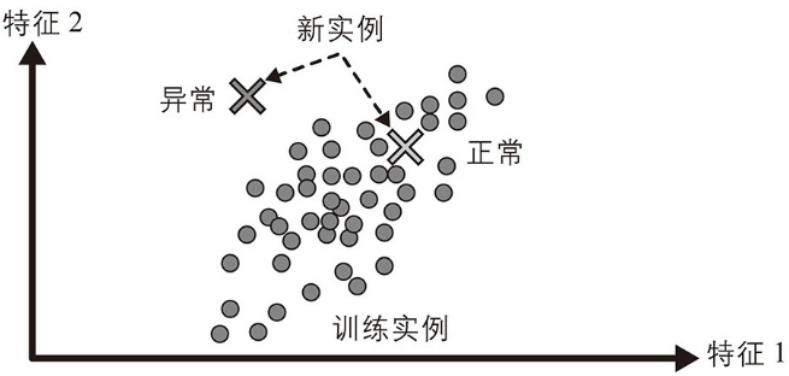
异常检测是一种识别数据中显著偏离正常模式的样本或事件的技术。这些异常可能是由错误、欺诈、故障、罕见事件或其他特殊原因引起的。
例如,检测异常的信用卡交易来防止欺诈、发现制造缺陷,或者在将数据集提供给另一个学习算法之前自动从数据集中删除异常值。系统在训练期间主要使用正常实例,因此它会学习识别它们。然后,当看到一个新实例时,系统可以判断这个新实例看起来是正常的还是异常的。
(5)新颖性检测
它旨在检测看起来与训练集中所有实例不同的新实例。这需要有一个非常“干净”的训练集,没有任何你希望算法能够检测到的实例。
例如,如果你有几千张狗的照片,其中1%代表吉娃娃犬,那么新颖性检测算法不应将吉娃娃犬的新图片视为新颖,将猫的照片视为新颖。但是,异常检测算法可能认为这些狗非常稀有并且与其他狗如此不同,以至于可能会将它们归类为异常。
(6)关联规则学习
其目标是挖掘大量数据并发现属性之间有趣的关系。
例如,假设你开了一家超市,在销售日志上运行关联规则可能会发现购买烧烤酱和薯片的人也倾向于购买牛排。因此,你可能希望将这几样商品摆放得更近一些。
2、监督学习
监督学习的核心特点是理由带有标签的数据训练模型,学习从输入特征到输出标签的映射关系。以下是监督学习的主要任务:
(1)分类(Classification)
其目标是学习输入的特征和标签之间的关系,从而能够根据新输入的特征,得到正确的分类结果。
文章开头所介绍的垃圾邮件分类就是典型的分类任务,根据已经有的数据学习垃圾邮件的特征,之后判断一封邮件是垃圾邮件还是正常邮件
常用的算法:逻辑回归(logisitic)、决策树、支持向量机、随机森林、神经网络
评估指标:精确率、召回率、F1分数、ROC曲线
(2)回归(Regression)
回归任务的目标是预测连续的数值,而不是离散类别。
典型的应用场景是:房价的预测。根据房屋面积、位置、型号等特征来预测房价。
常用的算法:线性回归(linear)、岭回归(Ridge)、套索回归(Lasso)、支持向量机回归(SVR)、梯度提升数
评估指标:均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、分数(越接近)越好
(3)结构化输出
结构化输出任务的输出不是简单的类别或数值,而是复杂的结构化数据。(例如:序列、图结构、空间结构)
典型的应用场景及方法:从文本中识别人名、地点等(条件随机场(CRF))机器翻译(Seq2Seq)、目标检测(YOLO、SSD)、语音识别(RNN+CTC)
评估方法:序列任务:使用BLEU(机器翻译)、PER(语音识别)、F1(NER)。目标检测:使用mAP(Mean Average Precision)衡量检测精度。
3、自监督学习
机器学习的另一种方法可以是从完全未标记的数据集生成完全标记的数据集。同样,一旦标记了整个数据集,就可以使用任何监督学习算法。这种方法称为自监督学习。
例如,如果你有一个很大的未标记图像数据集,你可以随机屏蔽每个图像的一小部分,然后训练一个模型来恢复出原始图像。在训练期间,屏蔽的图像用作模型的输入,原始图像用作标签。生成的模型本身可能非常有用。例如,修复损坏的图像或从图片中删除不想要的对象。但通常情况下,使用自监督学习训练的模型并不是你的最终目标。你通常需要针对稍微不同的任务(你真正关心的任务)来调整和微调模型。
例如,假设你真正想要的是一个宠物分类模型:给定一张宠物的照片,模型会告诉你这只宠物属于什么物种。如果你有大量未标记的宠物照片数据集,则可以先使用自监督学习来训练一个图像修复模型。如果模型表现良好,则它应该能够区分不同的宠物种类:当它修复一张蒙着脸的猫的图像时,它必须知道不要添加狗的脸。假设你的模型架构允许,那么你就可以调整模型,使它能预测宠物种类而不是修复图像。最后一步是在已标记的数据集上微调模型:模型已经知道猫、狗和其他宠物的样子,因此只需要这个步骤,模型就可以学习它已知的物种和我们期望从中得到的标签之间的映射。

有些人认为自监督学习是无监督学习的一部分,因为它处理的是未标记的数据集。但是 自监督学习在训练期间是使用(生成的)标签的,因此在这方面它更接近于监督学习。在处理聚类、降维或异常检测等任务时,通常会使用术语“无监督学习”,而自监督学习侧重于与监督学习相同的任务,主要是分类和回归。最好将自监督学习视为一个单独的类别。
4、强化学习
其核心思想是智能体通过与环境交互 学习最优策略。
强化学习没有静态的标注数据集,而是通过观察环境,选择和执行动作,并获得回报(或负回报形式的惩罚)。然后,它必须自行学习什么是最好的方法,称为策略。以便随着时间的推移获得最大的回报。策略定义了智能体在给定情况下应该选择的动作。
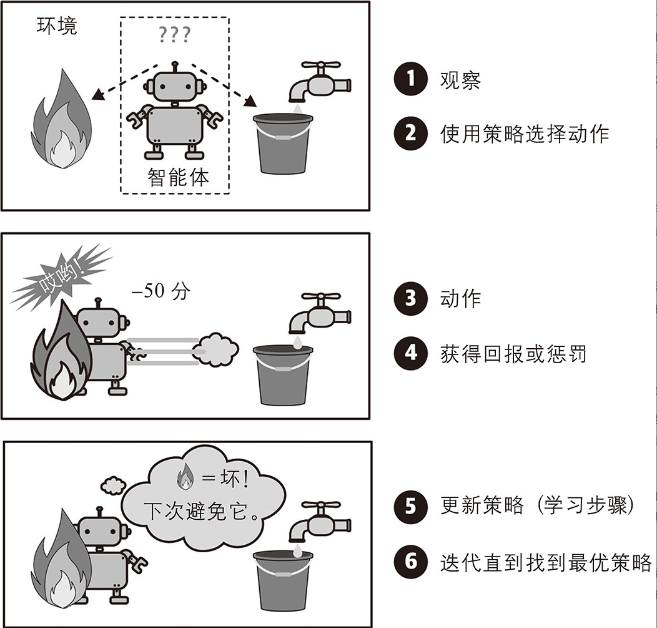
例如,许多机器人采用强化学习算法来学习如何走路。DeepMind的AlphaGo程序也是强化学习的一个很好的示例:它在2017年5月的围棋比赛中打败了当时世界排名第一的柯洁。它通过分析数百万场比赛,然后与自己进行多次对弈,从而习得了获胜策略。请注意,在与人类冠军的比赛中学习过程是被关闭的,AlphaGo只是在应用它已经学到的策略。
二、按数据使用方式分类
1、批量学习&离线学习
在批量学习中,系统无法进行增量学习:它必须一次性使用所有可用的数据进行训练,这成为批量学习。这通常会占用大量的时间和计算资源,因此通常需要离线完成。对系统进行训练后,将其投入生产环境运行,就不再学习了。它只是应用它学到的东西,无法后续更新,这也称为离线学习。
不幸的是,模型的性能往往会随着时间的推移而慢慢变差,因为世界在不断演进发展,而模型却保持不变。这种现象通常称为模型腐烂或数据漂移。解决方案是定期根据最新的数据重新训练模型。你需要多久做一次取决于用例:如果模型对猫和狗的图片进行分类,它的性能会衰减得很慢,但如果模型处理快速变化的系统,例如对金融市场进行预测,那么它很可能会衰减得相当快。
即使是经过训练可以对猫和狗的图片进行分类的模型也可能需要定期重新训练,这不是因为猫和狗会在一夜之间发生变化,而是因为相机会不断变化,图像格式、清晰度、亮度和大小比例也在不断变化。
如果想让批量学习系统理解新数据(比如新型垃圾邮件),需要在完整数据集(不仅是新数据,还有旧数据)上从头开始训练新版系统,然后用新模型替换旧模型。幸运的是,训练、评估和启动机器学习系统的整个过程可以相当容易地自动化,因此即使是批量学习系统也可以适应变化。只需要经常更新数据并从头开始训练新版系统。
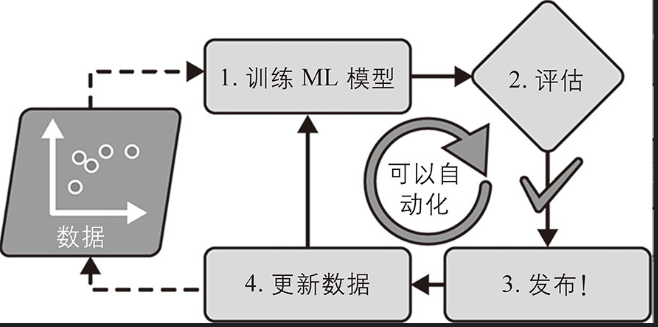
这个解决方案很简单,而且通常效果很好,但使用完整数据集进行训练可能需要花费很多小时,因此通常每24小时甚至每周训练一次新系统。如果你的系统需要适应快速变化的数据(例如,预测股票价格),那么你需要一个更具反应性的解决方案。
此外,在完整的数据集上进行训练需要大量的计算资源(CPU、内存空间、磁盘空间、磁盘I/O、网络I/O等)。如果你有大量的数据,并且你让系统每天从头开始训练,那么最终会花费你很多钱。如果数据量巨大,那么甚至可能无法使用批量学习算法。最后,如果系统需要能够自动学习并且它的资源有限(例如,智能手机应用程序或火星上的漫游机器人),那么携带大量训练数据并占用大量资源来每天训练数小时是不太可能的。在这些情况下,更好的选择是使用能够增量学习的算法。
2、增量学习&在线学习&核外学习
增量学习是机器学习中的一种动态学习范式,其核心目标是让模型能够在不遗忘旧知识的前提下,持续从新数据中学习。而以数据以流式(逐条或者逐批次)输入,实时更新模型,就是在线学习。在线学习都是增量学习,反之不成立。
如果你的计算资源有限,例如,模型是在移动设备上训练的,那么在线学习是一个不错的选择。
此外,对于超大数据集——超出一台计算机的主存储器所能容纳的数据,在线学习算法也同样适用[这称为核外(out-of-core)学习],主要是解决硬件限制,而非数据动态性。该算法加载部分数据,在该数据上运行一个训练步骤,然后重复该过程,直到它在所有数据上运行完,这就是核外学习。
在线学习系统的一个重要参数是它们适应不断变化的数据的速度:这称为学习率。如果设置的学习率很高,那么系统会快速适应新数据,但它也会很快忘记旧数据(并且你也不希望垃圾邮件过滤器只标记最新类型的垃圾邮件)。反之,如果设置的学习率很低,那么系统会有更多的惰性,也就是说,它会学习得更慢,但它对新数据中的噪声或非典型数据点(异常值)序列的敏感度也会降低。
核外学习通常是离线(即不在实时系统上)完成的,因此在线学习可能是一个容易混淆的名字。将其视为增量学习会更合适。在线学习≈增量学习,核外学习≠增量学习。核外学习是数据处理技术,增量学习、在线学习是模型更新策略
在线学习的一大挑战是,如果将不良数据输入系统,系统的性能可能会迅速下降(取决于数据的质量和学习率)。如果它是实时系统,那么你的客户会注意到这个现象。不良数据的来源可能是机器人的传感器故障,或者有人对搜索引擎恶意刷屏以提高搜索结果排名等。为降低这种风险,你需要密切监控系统,并在检测到性能下降时立即关闭学习(并尽量恢复到之前的工作状态)。你可能还想监控输入数据并对异常数据做出反应。例如,使用异常检测算法。
三、按模型构建方式分类
对机器学习系统进行分类的另一种方法是根据它们的泛化方式。
大多数机器学习任务都与做出预测有关。这意味着在给定大量训练样例的情况下,系统需要能够对它以前未见到过的样例做出良好的预测(泛化)。在训练数据上有很好的性能是好的,但还不够,真正的目标是在新实例上表现良好。
泛化方法主要有两种:基于实例的学习和基于模型的学习。
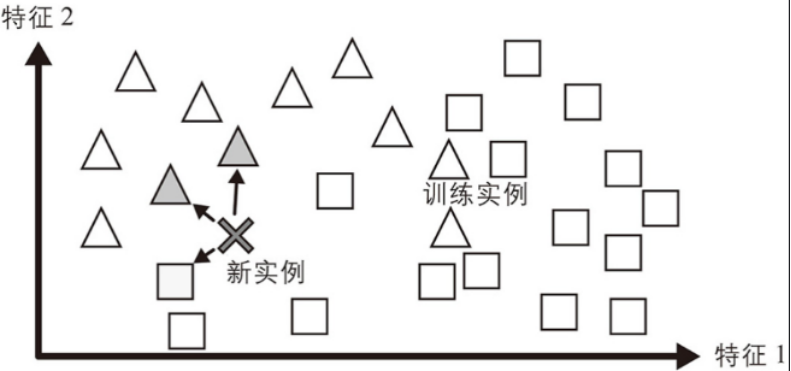
1、基于实例的学习
如果你以这种方式来创建垃圾邮件过滤器,那么它只会标记所有与用户已标记的电子邮件相同的电子邮件——这虽然不是最坏的解决方案,但肯定不是最好的。垃圾邮件过滤器不仅可以标记与已知垃圾邮件相同的电子邮件,还可以对其进行编程来标记与已知垃圾邮件非常相似的电子邮件。这需要衡量两封电子邮件之间的相似性。两封电子邮件之间的(非常基本的)相似性度量可以是计算它们共有的单词数。如果一封电子邮件与已知的垃圾邮件有很多相同单词,那么系统会将其标记为垃圾邮件。
这称为基于实例的学习:系统学习样例,然后通过使用相似性度量将它们与学习到的样例(或它们的子集)进行比较来泛化到新实例。例如,在图中,新实例被归类为三角形,因为大多数最相似的实例都属于该类。
2、基于模型的学习
对于一组样例进行泛化的另一种方法是为这些样例构建一个模型(先假设模型,之后训练模型得到较好的参数,实现理想的效果),然后使用该模型进行预测,这称为基于模型的学习。
基于模型的学习的过程:研究数据 →选择模型→使用训练数据进行训练→引用该模型对新实例进行预测(希望得到很好的泛化效果)
四、其他分类
1、半监督学习
由于标记数据通常既耗时又昂贵,因此你通常会有很多未标记的实例而很少有已标记的实例。一些算法可以处理一部分已标记的数据。这称为半监督学习。
一些照片托管服务(例如Google相册)就是很好的示例。一旦你将所有的家庭照片上传到该服务,它会自动识别出同一个人A出现在照片1、5和11中,而另一个人B出现在照片2、5和7中。这是算法(聚类)的无监督部分。现在系统只需要你告诉它这些人是谁。你只需为每个人添加一个标签,系统就可以为每张照片中的每个人命名,这对于搜索照片非常有用。
大多数半监督学习算法是无监督和监督算法的组合。例如,可以使用聚类算法将相似的实例分组在一起,然后每个未标记的实例都可以用其集群中最常见的标签进行标记。一旦标记了整个数据集,就可以使用任何监督学习算法。
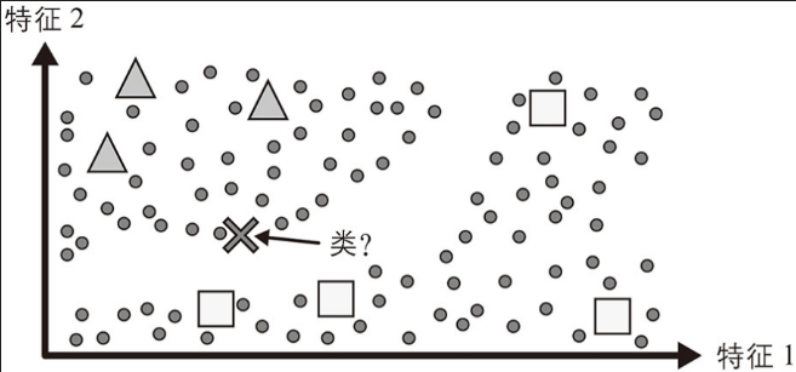
这张图中先是将数据分为两类(无监督学习的聚类算法),之后分别给他们打上▲和⬜的标签,之后就是监督学习了。 X 通过监督学习到了▲一类,之后被标记成▲。
2、迁移学习
迁移学习的核心是知识复用,将从一个任务(源领域,source domain)中学到的知识迁移到另一个相关任务(目标领域,target domain),以提升目标任务的性能。其核心假设是:
源任务和目标任务之间存在共享的知识或模式(如底层特征、统计规律)。
源领域的知识可以减少目标领域对数据或计算资源的需求。
迁移学习典型的方法:预训练+微调、特征提取、领域自适应、多任务学习