Introducing Visual Perception Token into Multimodal Large Language Model论文解读
文章目录
- Abstract
- 一、Introduction
- 二、Related Work
-
- 2.1. Visual Prompting
- 2.2. Visual Perception in MLLM
- 三、Visual Perception Token
-
- 3.1. Region Selection Tokens
- 3.2. Vision Re-Encoding Tokens
- 四、MLLM with Visual Perception Token
-
- 4.1 Architecture
- 4.2 Training Data for Visual Perception Token
- 五、Experiments
-
- 5.1. Main Results
- 5.2. Discussion on Region Selection Token
- 5.3. Discussion on Vision Re-Encoding Token
- 五、Conclusion
- 附录
-
- 评估提示模板
- 训练数据示例模板
Abstract
To utilize visual information, Multimodal Large Language Model (MLLM) relies on the perception process of its vision encoder. The completeness and accuracy of visual perception significantly influence the precision of spatial reasoning, fine-grained understanding, and other tasks. However, MLLM still lacks the autonomous capability to control its own visual perception processes, for example, selectively reviewing specific regions of an image or focusing on information related to specific object categories. In this work, we propose the concept of Visual Perception Token, aiming to empower MLLM with a mechanism to control its visual perception processes. We design two types of Visual Perception Tokens, termed the Region Selection Token and the Vision Re-Encoding Token. MLLMs autonomously generate these tokens, just as they generate text, and use them to trigger additional visual perception actions. The Region Selection Token explicitly identifies specific regions in an image that require further perception, while the Vision Re-Encoding Token uses its hidden states as control signals to guide additional visual perception processes. Extensive experiments demonstrate the advantages of these tokens in handling spatial reasoning, improving fine-grained understanding, and other tasks. On average, the introduction of Visual Perception Tokens improves the performance of a 2B model by 30.9%, increasing its score from 0.572 to 0.749, and even outperforms a 7B parameter model by 20.0% (from 0.624). Please check out our repo here.
为了利用视觉信息,多模态大型语言模型(MLLM)依赖其视觉编码器的感知过程。视觉感知的完整性和准确性显著影响空间推理、细粒度理解等任务的精度。然而,MLLM仍缺乏自主控制自身视觉感知过程的能力,例如选择性地查看图像的特定区域或聚焦于与特定对象类别相关的信息。在本研究中,我们提出了视觉感知令牌(Visual Perception Token)的概念,旨在为MLLM提供一种控制其视觉感知过程的机制。我们设计了两种类型的视觉感知令牌,即区域选择令牌(Region Selection Token)和视觉重编码令牌(Vision Re-Encoding Token)。MLLM能够像生成文本一样自主生成这些令牌,并利用它们触发额外的视觉感知动作。区域选择令牌明确标识图像中需要进一步感知的特定区域,而视觉重编码令牌则利用其隐藏状态作为控制信号,指导额外的视觉感知过程。大量实验证明,这些令牌在处理空间推理、提升细粒度理解等任务中具有优势。平均而言,引入视觉感知令牌使2B参数模型的性能提升了30.9%,得分从0.572提高到0.749,甚至比7B参数模型的性能高出20.0%(从0.624提升)。请查看我们的代码仓库。

脑图:
一、Introduction
Multimodal Large Language Model (MLLM) depend on the perception capabilities of their vision encoder to process and utilize visual information. During this process, MLLM utilizes a vision encoder and a projector to embed visual information into the language space. The quality of Visual Perception determines whether MLLMs can accurately distinguish objects in an image [35], whether MLLMs can rely on visual information to answer questions instead of generating textual hallucinations [14], and whether MLLMs can perform precise reasoning about spatial relationships [3], among other tasks. While current MLLM systems demonstrate strong capabilities in visual information understanding [20, 34, 37, 45], they lack the ability to autonomously control their Visual Perception processes. Instead, these systems depend on manually designed pipelines to perform specific image annotations or visual features enhancement [35, 48].
多模态大型语言模型(MLLM)依靠其视觉编码器的感知能力来处理和利用视觉信息。在此过程中,MLLM利用视觉编码器和投影器将视觉信息嵌入到语言空间中。视觉感知的质量决定了MLLM能否准确区分图像中的物体[35]、能否依靠视觉信息回答问题而非产生文本幻觉[14],以及能否对空间关系进行精确推理[3]等。尽管当前的MLLM系统在视觉信息理解方面展现出较强的能力[20, 34, 37, 45],但它们缺乏自主控制视觉感知过程的能力。相反,这些系统依赖人工设计的流程来执行特定的图像标注或视觉特征增强[35, 48]。
In this work, we explore the task of enabling MLLMs to autonomously control their Visual Perception processes. Previously, MLLM-based agents and MLLMs equipped with function-calling or tool-use capabilities can be considered as having the ability to control subsequent tasks. They utilize the output of the LLM as arguments for subsequent functions or tool use. However, such control information is confined to the natural language space. The advantage of control signals in the natural language space lies in their interpretability, clear supervision signals, and ease of training data construction. However, these signals are constrained by specific formats. Additionally, natural language inherently contains redundancy, leading to efficiency issues. In this work, we aim to explore control signals beyond the natural language space. However, we also require that these signals remain naturally compatible with the next-token prediction paradigm of LLMs. To address this, we propose the concept of “Visual Perception Tokens”. These tokens are integrated into the MLLM vocabulary and can be generated by the MLLM through next-token prediction, similar to natural language generation. These tokens do not correspond to specific words or characters in natural language; instead, their primary function is to trigger additional Visual Perception processes and convey control information for these processes.
在本研究中,我们探索了让MLLM自主控制其视觉感知过程的任务。此前,基于MLLM的智能体以及具备函数调用或工具使用能力的MLLM,可以被认为具有控制后续任务的能力。它们将LLM的输出作为后续函数或工具使用的参数。然而,此类控制信息局限于自然语言空间。自然语言空间中的控制信号具有可解释性强、监督信号明确以及训练数据易于构建等优势,但这些信号受限于特定格式。此外,自然语言本身存在冗余性,会导致效率问题。在本研究中,我们旨在探索自然语言空间之外的控制信号。但同时,我们也要求这些信号能与LLM的下一个token预测范式自然兼容。为解决这一问题,我们提出了“视觉感知令牌”(Visual Perception Tokens)的概念。这些令牌被整合到MLLM的词汇表中,MLLM可以像生成自然语言一样,通过下一个token预测来生成它们。这些令牌并不对应自然语言中的特定词语或字符,其主要功能是触发额外的视觉感知过程,并传递这些过程的控制信息。
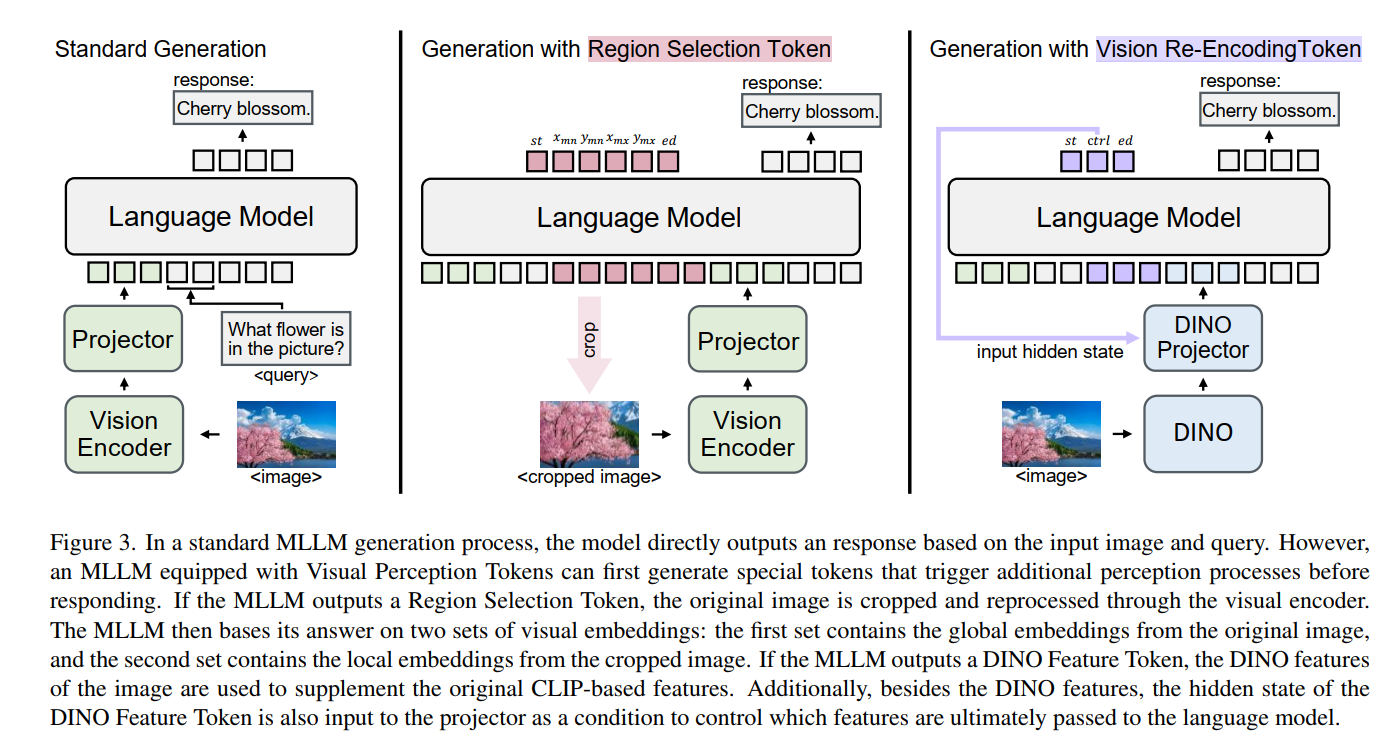
We designed two types of Visual Perception Tokens. The first type is Region Selection Token, which instruct the MLLM to crop the input image and encode again the important regions relevant to the query using the vision encoder. The second type is the Vision Re-Encoding Token, which signals the model to input the image into (additional) vision encoder and use the resulting vision features to supplement the original MLLM’s vision features. A projector takes both the additional vision features and the hidden state of the Vision Re-Encoding Token as inputs, enabling fine-grained control beyond merely triggering the vision encoder. In this work, we explore using an additional DINO model, a SAM model, or the model’s original vision branch as the vision encoder. During the generation process, if the MLLM outputs any Visual Perception Token, the corresponding additional perception process is triggered, and the extra embedding sequence derived from the image is concatenated to the original LLM input. The LLM then continues generating the response in the form of next-token prediction. Fig. 1a illustrates the VQA process incorporating visual perception tokens. Fig. 3 provides a more detailed depiction of how visual perception tokens are generated by the MLLM and how they are utilized to control the visual perception process.
我们设计了两种类型的视觉感知令牌。第一种是区域选择令牌(Region Selection Token),它指示MLLM裁剪输入图像,并使用视觉编码器对与查询相关的重要区域重新进行编码。第二种是视觉重编码令牌(Vision Re-Encoding Token),它向模型发出信号,指示将图像输入(额外的)视觉编码器,并利用生成的视觉特征来补充原始MLLM的视觉特征。投影器将额外的视觉特征和视觉重编码令牌的隐藏状态作为输入,从而实现超越单纯触发视觉编码器的细粒度控制。在本研究中,我们尝试使用额外的DINO模型、SAM模型或模型原有的视觉分支作为视觉编码器。在生成过程中,如果MLLM输出任何视觉感知令牌,就会触发相应的额外感知过程,并且从图像中衍生出的额外嵌入序列会被拼接至原始的LLM输入中。随后,LLM以下一个token预测的形式继续生成响应。图1a展示了整合视觉感知令牌的视觉问答(VQA)过程。图3更详细地描述了视觉感知令牌如何由MLLM生成,以及如何被用于控制视觉感知过程。
To train the MLLM to use Visual Perception Tokens, we constructed the Visual Perception Token training dataset, which includes 829k samples spanning four task categories: General VQA, Fine-Grained VQA, Spatial Reasoning, and Text/OCR-Related VQA. Experiments demonstrated that Visual Perception Token significantly enhances the MLLM’s ability to autonomously control and refine its visual perception.
为了训练MLLM使用视觉感知令牌,我们构建了视觉感知令牌训练数据集,该数据集包含829k个样本,涵盖四个任务类别:通用视觉问答(General VQA)、细粒度视觉问答(Fine-Grained VQA)、空间推理(Spatial Reasoning)和文本/光学字符识别相关视觉问答(Text/OCR-Related VQA)。实验表明,视觉感知令牌显著增强了MLLM自主控制和优化其视觉感知的能力。
Our contributions can be summarized as follows:
- We explored a novel task: enabling MLLMs to autonomously control their visual perception process.
- We designed two types of Visual Perception Tokens: one enabling the MLLM to select regions of interest, and another allowing the MLLM to incorporate additional vision features and control the final embeddings input to the language model.
- Experimental results demonstrate the effectiveness of our approach. On tasks such as Spatial Reasoning and Fine-Grained VQA, models equipped with Visual Perception Tokens achieved performance improvements of 34.6% and 32.7% over the 7B baseline model, respectively.
我们的贡献可总结如下: - 我们探索了一项新任务:使MLLM能够自主控制其视觉感知过程。
- 我们设计了两种类型的视觉感知令牌:一种使MLLM能够选择感兴趣的区域,另一种允许MLLM整合额外的视觉特征并控制输入到语言模型的最终嵌入。
- 实验结果证明了我们方法的有效性。在空间推理和细粒度视觉问答等任务上,配备视觉感知令牌的模型相较于7B基线模型,性能分别提升了34.6%和32.7%。
二、Related Work
2.1. Visual Prompting
From a technical perspective, our approach can also be regarded as a learnable visual prompting method. Visual prompting is a key technique in vision models, especially for segmentation tasks [11, 16, 27]. It uses a prompt encoder to interpret manual annotations, such as points and masks, to control segmentation granularity and assist instance selection. Recent advancements show that LVLMs can interpret visual cues like circles and color masks in a zero-shot manner without an additional encoder [29, 44]. Building on this, [41] and [42] have utilized segmentation model-generated masks as visual prompts, enhancing LVLM performance in segmentation and grounding. However, these methods are query-agnostic, while VQA tasks require adapting visual information based on the query. [48] addresses this by using an auxiliary VLM to generate query-specific visual prompts, overlaying attention maps to guide focus on relevant regions.
从技术角度而言,我们的方法也可被视为一种可学习的视觉提示方法。视觉提示是视觉模型中的一项关键技术,尤其在分割任务中[11, 16, 27]。它通过提示编码器解读人工标注(如点和掩码),以控制分割粒度并辅助实例选择。最新研究进展表明,大型视觉语言模型(LVLMs)无需额外编码器,就能以零样本方式解读圆形和彩色掩码等视觉线索[29, 44]。在此基础上,[41]和[42]利用分割模型生成的掩码作为视觉提示,提升了LVLM在分割和定位任务中的性能。然而,这些方法与查询无关,而视觉问答(VQA)任务需要根据查询调整视觉信息。[48]通过使用辅助视觉语言模型(VLM)生成特定于查询的视觉提示,叠加注意力图以引导模型聚焦于相关区域,从而解决了这一问题。
Built on these learning-free methods, [28] trains the MLLM to output bounding boxes of important regions. The image is then cropped and re-input for inference, creating a “crop and re-input” CoT process. Compared to [28], our design of Region Selection Tokens does not rely on bounding box information in the natural language space but instead uses specialized tokens to indicate the location of important regions. This design simplifies training and mitigates the issue of MLLMs having difficulty aligning the image coordinate system with coordinat