当文档包含表格时,如何结合大模型和OCR提取数据?
在AI应用极速发展的当下,LLM(大语言模型)与RAG(检索增强生成)系统已成为构建智能问答、知识管理等高阶应用的核心引擎。
然而,许多团队在项目落地时遭遇了现实的挑战:模型的实际表现——无论是回答的准确性、相关性,还是系统整体的响应效率——往往难以达到预期。究其根源,一个常被低估的关键环节浮出水面:文档解析的质量。
核心问题在于输入数据的“可理解性”。现实世界中的知识载体——PDF报告、扫描文件、图文结合的技术文档——本质上是高度非结构化的。传统OCR工具就像个“近视的搬运工”,只能机械地把图像上的文字“抠”下来,却看不懂文档的内在“蓝图”:标题的层级关系迷失了,段落被拆得七零八落,复杂的表格像被撕碎的拼图,跨页的内容彻底断了联系,图表更是成了没有注释的“孤岛”。当这种缺乏结构、语义断裂的“原料”被直接喂入RAG系统时,后果是显而易见的:
- 检索效率低下:系统难以精准定位包含答案的关键片段,在海量碎片中“大海捞针”,耗时费力。
- 答案准确性受损:上下文缺失或错位,导致模型“理解偏差”,生成跑题甚至错误的回答。
- 信息完整性打折:表格数据混乱、跨页信息断裂、图表意义不明,关键细节丢失。
可以说,文档解析的质量,直接锁定了RAG系统乃至整个AI应用效果的上限。优质的解析不是简单的文字提取,而是对文档内容进行深度理解与结构化重建的过程。这正是TextIn xParse智能文档解析引擎致力于解决的痛点。

目前从 PDF、JPG、PNG 等格式的图文混排文档中提取表格数据并转化为 Excel 等可编辑形式,常面临两大难点:一是人工提取效率极低,二是传统 OCR 工具仅能提取文本,无法理解数据逻辑,难以满足精准提取需求。
例如在金融、科研等对数据依赖性强的领域,这类问题更为突出。例如金融机构需解析上市公司年报、行业研报中的大量表格数据,这些文件多为 PDF、图片格式,甚至存在加密 PDF,批量处理难度极大。因此,如何高效、准确地提取表格数据,成为影响后续分析工作的关键。
针对这一问题,【TextIn】文档解析工具作为大模型加速器,为解决这一难点量身定制。TextIn文档解析上架新功能——图表解析,通过线上参数配置即可调用,完成全文解析,无需对样本进行预先分割或其他预处理。其核心优势在于:
- 技术融合:结合 OCR 的文本识别能力与大模型的语义理解能力,不仅能提取文本,更能解析表格数据逻辑,将非结构化数据转化为结构化数据。
- 操作便捷:无需对文档进行预先分割、格式转换等预处理,通过线上参数配置即可直接调用功能,完成全文解析。
- 适用广泛:支持 PDF(包括加密 PDF)、JPG、PNG 等多种格式,既能处理有明确数值标注的表格,也能对无具体数值的复杂图表进行精确测量并给出预估数值,充分挖掘数据价值。
- 赋能大模型:解析后生成的结构化数据(如 Markdown 格式)可直接输入大模型,避免原始图表对大模型理解的干扰,提升大模型处理效率和回答准确性。
让我们来看几个例子:
案例1:密集少线表格识别
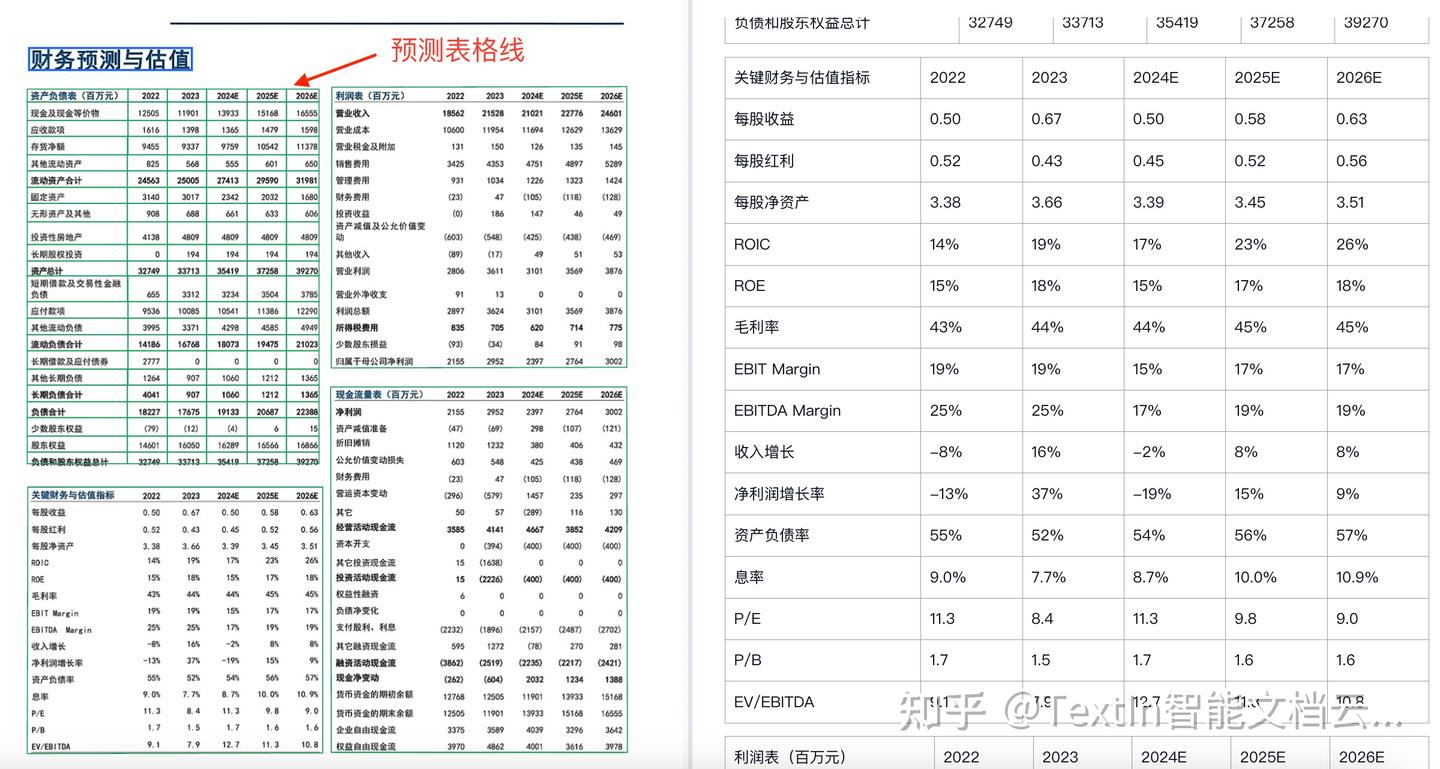
前端支持选中表格并在原图上显示模型预测的单元格,如图中左上表格效果。
案例2:跨页表格合并、页眉页脚识别

案例3:图表识别
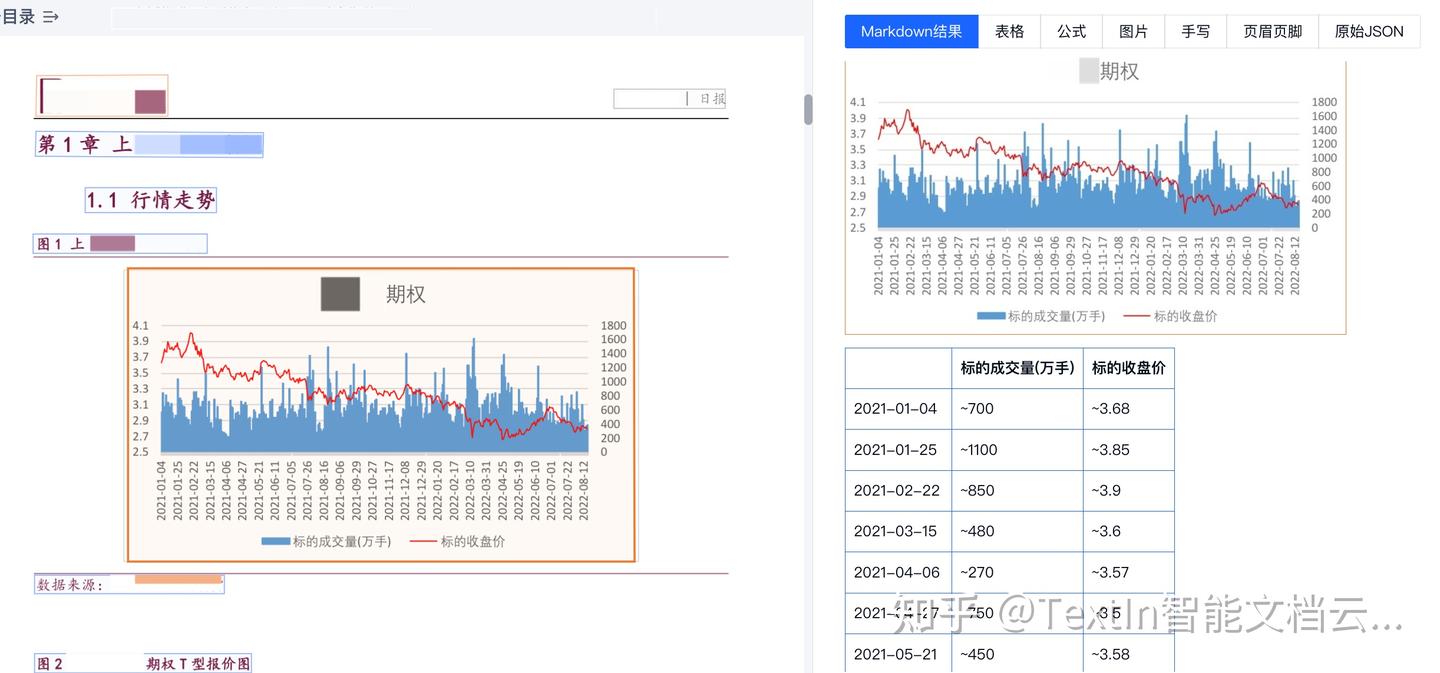
对于肉眼读取困难的图表,TextIn xParse也会通过精确测量给出预估数值,帮助挖掘更多有效数据信息,完成分析及预测工作。
操作步骤讲解
- 登录平台:访问【TextIn】官网完成用户登录。
- 上传文档:在文档解析功能界面,上传需要处理的含表格文档(支持 PDF、JPG、PNG 等格式,包括加密 PDF)。
- 参数配置:根据文档特点和提取需求,在线设置解析参数(如是否需要预估无数值图表的数值等)。
- 执行解析:确认参数后,点击解析按钮,工具将自动完成文档扫描、表格识别与数据结构化处理。
- 获取结果:解析完成后,可获取结构化数据(如表格形式)或 Markdown 格式文件,直接用于 Excel 导入、数据入库、大模型输入等后续操作。
客户案例
某头部券商研究所日常需处理大量上市公司年报、行业研报,其中包含数百张表格数据,传统人工提取方式耗时且易出错,严重影响研究效率。
应用TextIn后的效果数据:
- 效率提升:单份含 20 张表格的 PDF 文档,人工提取需 3-4 小时,使用后仅需 5-8 分钟,效率提升约 95%;批量处理(100 份文档)时,总耗时从原本的 300 + 小时缩短至 15 小时以内。
- 准确性提升:人工提取数据误差率约 3%-5%,TextIn对有明确数值的表格提取准确率达 99.2%,对无数值的复杂图表预估数值误差率控制在 2% 以内。
- 大模型协作效果:将解析后的 Markdown 文件输入大模型,相比直接上传原始 PDF,大模型对表格数据的理解准确率从 65% 提升至 98%,回答质量显著提高(如针对 “全球工业机器人销售额趋势” 的问题,原始 PDF 因图表干扰导致大模型回答模糊,解析后大模型能基于结构化数据给出精准的数值分析和趋势判断)。
通过【TextIn】的图表解析功能,该研究所不仅降低了数据提取的人力成本,更通过结构化数据赋能大模型,加速了研究报告的产出效率,为投资决策提供了更及时、准确的数据支持。