使用python基于langchain来写一个ai agent
测试代码参考博客文章:https://blog.csdn.net/weixin_48707135/article/details/138525347,同时根据我的实际需要进行了修改。
主要修改的地方是:基于ollama来进行agent的创建,使用了shmily_006/Qw3:latest模型进行。这个模型是基于qwen3:4b模型进行调整,非思考版本,我的ollama版本为0.11.2。使用qwen3主要还是目前国内模型,能够本地部署的,qwen3是基本是最强的版本了,需要的gpu也还行,4G足以进行测试了。
1、基于conda创建一个环境:
conda create --name agent python==3.10
2、安装gpu版本的:torch
pip3 install torch==2.6.0 torchvision torchaudio -f https://mirrors.aliyun.com/pytorch-wheels/cu126/
3、使用的组件版本:
python-dotenv>=0.19.0
langchain_core==0.3.72
langchain==0.3.27
pydantic==2.11.7
langchain_openai==0.3.28
langchain-ollama==0.3.6
langchain-community==0.3.27
transformers==4.55.0
sqlalchemy==2.0.42
4、工具类:
from typing import Any, Dict, List, Optional, Union
from pydantic import BaseModel, Field
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.prompts import PromptTemplate
from langchain_core.outputs import GenerationChunk, ChatGenerationChunk, LLMResult
from sqlalchemy import UUID
import os, sysclass Action(BaseModel):"""结构化定义工具的属性"""name: str = Field(description="工具或指令名称")args: Optional[Dict[str, Any]] = Field(description="工具或指令参数,由参数名称和参数值组成")class MyPrintHandler(BaseCallbackHandler):"""自定义LLM CallbackHandler,用于打印大模型返回的思考过程"""def __init__(self):BaseCallbackHandler.__init__(self)def on_llm_new_token(self,token: str,*,chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,run_id: UUID,parent_run_id: Optional[UUID] = None,**kwargs: Any,) -> Any:end = ""content = token + endsys.stdout.write(content)sys.stdout.flush()return tokendef on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:end = ""content = "\n" + endsys.stdout.write(content)sys.stdout.flush()return response5、完整python代码:
import json
import sys
from typing import List, Optional, Dict, Any, Tuple, Unionfrom langchain_ollama import OllamaLLM
from langchain.tools.render import render_text_description
from langchain_core.language_models import BaseChatModel
from langchain_core.output_parsers import PydanticOutputParser, StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.tools import StructuredTool
from pydantic import ValidationError
from langchain.memory import ConversationBufferMemoryfrom rainutil import Action, MyPrintHandlermodels=["shmily_006/Qw3:latest","qwen3:0.6b","qwen3:1.7b","qwen2.5:3b","deepseek-r1:8b-0528-qwen3-q8_0"]class MyAgent:def __init__(self,llm: BaseChatModel = OllamaLLM(model=models[2],temperature=0,base_url="http://localhost:11434",skip_token_counting=True),tools=None,prompt: str = "",final_prompt: str = "",max_thought_steps: Optional[int] = 10,):if tools is None:tools = []self.llm = llmself.tools = toolsself.final_prompt = PromptTemplate.from_template(final_prompt)self.max_thought_steps = max_thought_steps # 最多思考步数,避免死循环self.output_parser = PydanticOutputParser(pydantic_object=Action)self.prompt = self.__init_prompt(prompt)self.llm_chain = self.prompt | self.llm | StrOutputParser() # 主流程的LCELself.verbose_printer = MyPrintHandler()def __init_prompt(self, prompt):return PromptTemplate.from_template(prompt).partial(tools=render_text_description(self.tools),format_instructions=self.__chinese_friendly(self.output_parser.get_format_instructions(),))def run(self, task_description):"""Agent主流程"""# 思考步数thought_step_count = 0# 初始化记忆agent_memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True,)agent_memory.save_context({"input": "\ninit"},{"output": "\n开始"})# 开始逐步思考while thought_step_count < self.max_thought_steps:print(f">>>>Round: {thought_step_count}<<<<")action, response = self.__step(task_description=task_description,memory=agent_memory)# 如果是结束指令,执行最后一步if action.name == "FINISH" or action.name.startswith("FINISH("):break# 执行动作observation = self.__exec_action(action)print(f"----\nObservation:\n{observation}")# 更新记忆self.__update_memory(agent_memory, response, observation)thought_step_count += 1if thought_step_count >= self.max_thought_steps:# 如果思考步数达到上限,返回错误信息reply = "抱歉,我没能完成您的任务。"else:# 否则,执行最后一步final_chain = self.final_prompt | self.llm | StrOutputParser()reply = final_chain.invoke({"task_description": task_description,"memory": agent_memory})return replydef __step(self, task_description, memory) -> Tuple[Action, str]:"""执行一步思考"""response = ""for s in self.llm_chain.stream({"task_description": task_description,"memory": memory}, config={"callbacks": [self.verbose_printer]}):response += simport re# 删除<thinking>标签及其内容(包括标签本身)cleaned_response = re.sub(r'<thinking>.*?</thinking>', '', response, flags=re.DOTALL)cleaned_response = re.sub(r'<think>.*?</think>', '', cleaned_response, flags=re.DOTALL)# 删除可能的多余空白行response = re.sub(r'\n\s*\n', '\n', cleaned_response).strip()action = self.output_parser.parse(response)return action, responsedef __exec_action(self, action: Action) -> str:# 特殊处理FINISH动作,兼容带括号的情况if action.name == "FINISH" or action.name.startswith("FINISH("):return "任务完成"observation = "没有找到工具"for tool in self.tools:if tool.name == action.name:try:# 执行工具observation = tool.run(action.args)except ValidationError as e:# 工具的入参异常observation = (f"Validation Error in args: {str(e)}, args: {action.args}")except Exception as e:# 工具执行异常observation = f"Error: {str(e)}, {type(e).__name__}, args: {action.args}"return observation@staticmethoddef __update_memory(agent_memory, response, observation):agent_memory.save_context({"input": response},{"output": "\n返回结果:\n" + str(observation)})@staticmethoddef __chinese_friendly(string) -> str:try:return json.dumps(json.loads(string), ensure_ascii=False)except:return stringtemplate = '''Answer the following questions as best you can. You have access to the following tools:{tools}Use the following format:Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input questionBegin!Question: {input}
Thought:{agent_scratchpad}'''prompt = PromptTemplate.from_template(template)prompt_text = """
你是强大的AI火车票助手,可以使用工具与指令查询并购买火车票你的任务是:
{task_description}你可以使用以下工具或指令,它们又称为动作或actions:
{tools}当前的任务执行记录:
{memory}按照以下格式输出:任务:你收到的需要执行的任务
思考: 观察你的任务和执行记录,并思考你下一步应该采取的行动
然后,根据以下格式说明,输出你选择执行的动作/工具:
{format_instructions}重要提示:
1. 只输出JSON格式的内容,不要添加任何解释性文字
2. JSON必须严格符合上面指定的格式
3. 不要使用Markdown代码块格式(如```json)
4. 不要在JSON前后添加任何文字
"""final_prompt = """
你的任务是:
{task_description}以下是你的思考过程和使用工具与外部资源交互的结果。
{memory}你已经完成任务。
现在请根据上述结果简要总结出你的最终答案。
直接给出答案。不用再解释或分析你的思考过程。
"""from typing import Listfrom langchain_core.tools import StructuredTooldef search_train_ticket(origin: str,destination: str,date: str,departure_time_start: str,departure_time_end: str
) -> List[dict[str, str]]:"""按指定条件查询火车票"""# mock train listreturn [{"train_number": "G1234","origin": "北京","destination": "上海","departure_time": "2024-06-01 8:00","arrival_time": "2024-06-01 12:00","price": "100.00","seat_type": "商务座",},{"train_number": "G5678","origin": "北京","destination": "上海","departure_time": "2024-06-01 18:30","arrival_time": "2024-06-01 22:30","price": "100.00","seat_type": "商务座",},{"train_number": "G9012","origin": "北京","destination": "上海","departure_time": "2024-06-01 19:00","arrival_time": "2024-06-01 23:00","price": "100.00","seat_type": "商务座",}]def purchase_train_ticket(train_number: str,
) -> dict:"""购买火车票"""return {"result": "success","message": "购买成功","data": {"train_number": "G1234","seat_type": "商务座","seat_number": "7-17A"}}search_train_ticket_tool = StructuredTool.from_function(func=search_train_ticket,name="查询火车票",description="查询指定日期可用的火车票。",
)purchase_train_ticket_tool = StructuredTool.from_function(func=purchase_train_ticket,name="购买火车票",description="购买火车票。会返回购买结果(result), 和座位号(seat_number)",
)finish_placeholder = StructuredTool.from_function(func=lambda: "任务已完成",name="FINISH",description="用于表示任务完成的占位符工具。当所有任务完成时调用此工具。"
)tools = [search_train_ticket_tool, purchase_train_ticket_tool, finish_placeholder]if __name__ == "__main__":my_agent = MyAgent(tools=tools,prompt=prompt_text,final_prompt=final_prompt,)task = "帮我买24年6月1日早上去上海的火车票"reply = my_agent.run(task)print(reply)6、最终的运行效果:
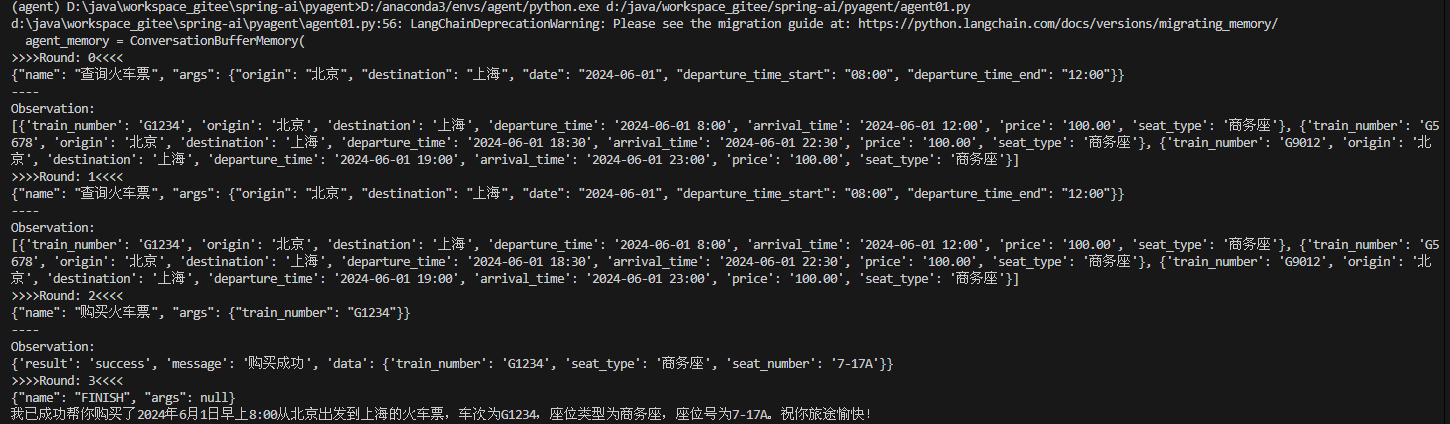
7、后来试了试qwen3:0.6b,一次成功,后来失败了好几次:
成功的:
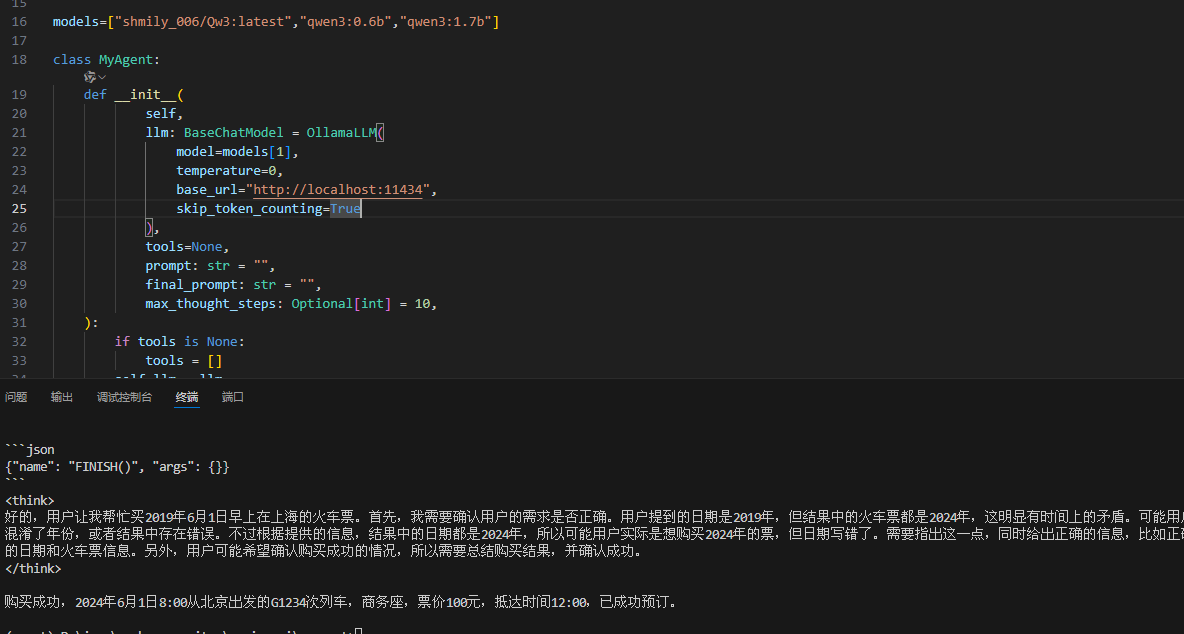
失败的:
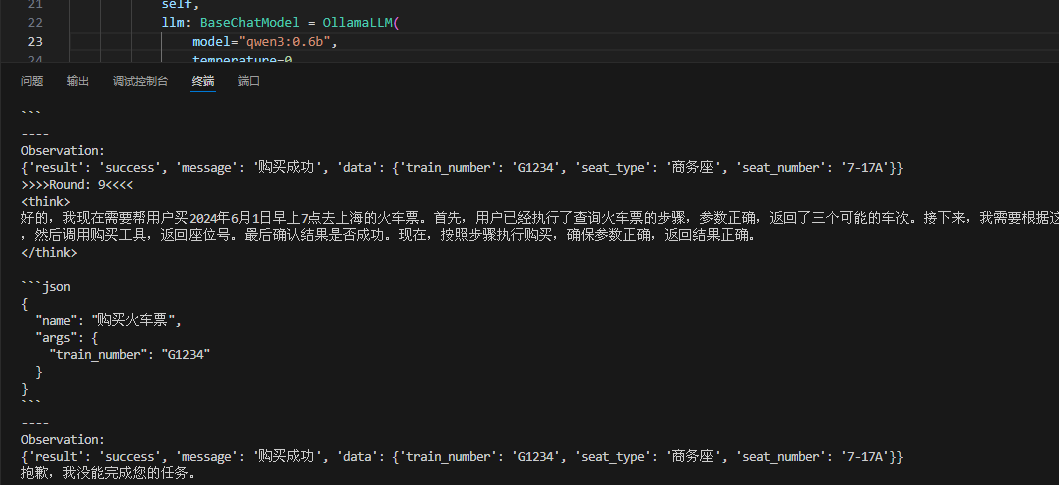
deepseek-r1也可以:
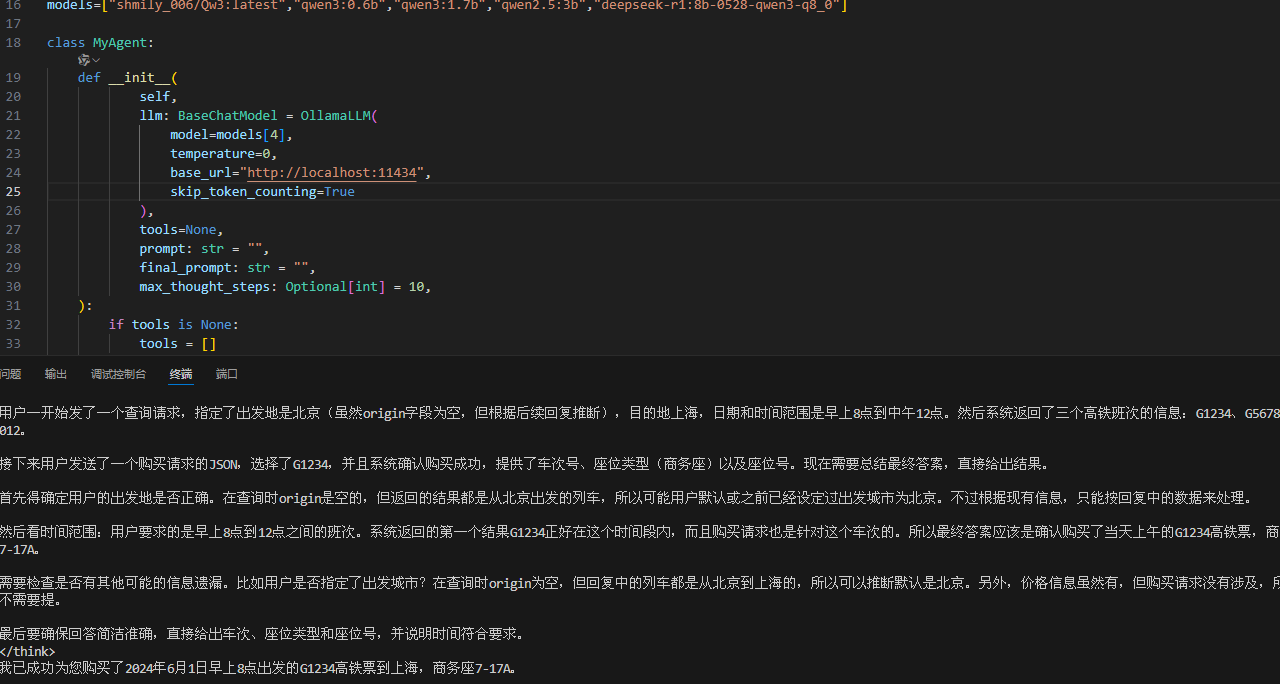
8、qwen2.5:3b代码失败:
估计还是理解力有问题。
9、如果使用推理模型,可能会有多余的输出:
可以把中的内容过滤掉:
def __step(self, task_description, memory) -> Tuple[Action, str]:"""执行一步思考"""response = ""for s in self.llm_chain.stream({"task_description": task_description,"memory": memory}, config={"callbacks": [self.verbose_printer]}):response += simport re# 删除<thinking>标签及其内容(包括标签本身)cleaned_response = re.sub(r'<thinking>.*?</thinking>', '', response, flags=re.DOTALL)cleaned_response = re.sub(r'<think>.*?</think>', '', cleaned_response, flags=re.DOTALL)# 删除可能的多余空白行response = re.sub(r'\n\s*\n', '\n', cleaned_response).strip()action = self.output_parser.parse(response)return action, response
后期再根据实际情况进行完善吧。