Syzkaller实战教程10: MoonShine复现Trace2syz功能演示
Moonshine 是 Syzkaller 的改进项目,由哥伦比亚大学团队开发,是一种为操作系统模糊测试工具提供紧凑且多样化种子的策略与工具,旨在提升模糊测试的效率和效果,更好地发现内核级别的漏洞。相关内容如下:
- 核心功能:通过分析现实世界程序的系统调用跟踪来生成种子。它利用轻量级静态分析检测不同系统调用之间的依赖关系,能够移除不必要的调用,保留最有可能触发漏洞的部分,从而生成更高效的测试种子。
- 实现方式:通过扩展 strace 实现了 tracer,以捕捉系统调用的名称、参数和返回值,并采用 kcov 进行代码覆盖率测量。同时,使用 smatch,一个对 C 进行静态分析的框架,来进行控制流分析,通过注册不同的 hook 来检测条件语句和赋值语句,以此确定系统调用之间的显式依赖(explicit dependencies)和隐式依赖(implicit dependencies)。
- 效果:从包含 280 万个系统调用的 3220 个真实世界程序跟踪中,可将其精炼到 14000 个左右的调用,同时保留 86% 的原始代码覆盖率。基于这些精炼的种子系统调用序列,Moonshine 平均可将 Syzkaller 对 Linux 内核的代码覆盖率提高 13%,还发现了 17 个 Syzkaller 未发现的 Linux 内核新漏洞。
- 技术栈:主要使用 Go 语言开发,借助 Ragel(状态机编译器)和 Goyacc(解析器生成器)将原始的跟踪数据转换为可用的格式。
- 使用限制:目前 Moonshine 只能为 Linux 上的 Syzkaller 生成种子,且只能解析通过 strace 收集的跟踪,建议使用版本大于等于 4.16 的 strace。
一.Moonshine复现
| SQL |
|
|
|
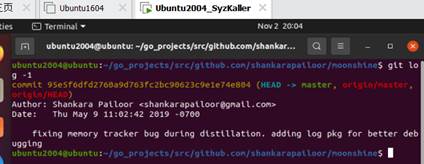
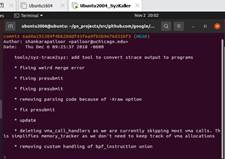
安装tips:
| SQL |
1. 安装Go
MoonShine主要是用Go编写的,所以需要先安装Go。请按照以下步骤进行:
| Bash |
确保Go已正确安装并运行go version来确认版本。
2. 安装Ragel
Ragel用于扫描和解析MoonShine中的trace。通过以下命令安装Ragel:
| Bash |
3. 安装Goyacc
MoonShine使用Goyacc来解析trace。安装Goyacc:
| Bash |
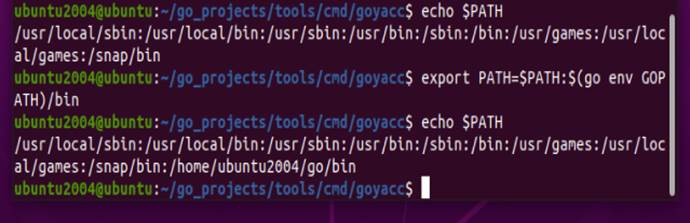
然后确保Goyacc所在目录在你的PATH中,完成安装:
| Bash |
4. 下载和编译MoonShine
获取MoonShine的代码并构建:
| Bash |
克隆syzkaller项目到本地并指定版本:
| SQL |
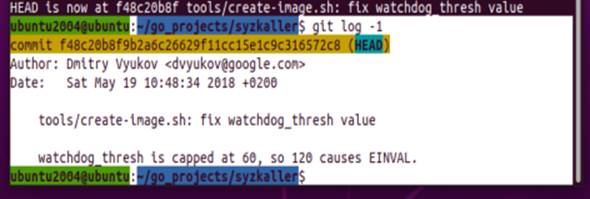
编译moonshine
| SQL |
| SQL |
5. 运行MoonShine
构建完成后,可以参考如下命令模板运行MoonShine并生成Syzkaller所需的种子:
| Bash |
- -dir [tracedir]:要解析的日志文件目录。目录内应包含使用 strace 生成的系统调用日志文件。
- -distill [distillConfig.json]:指定配置文件,用于设定提取策略(例如“隐式依赖(implicit)”或“仅显式依赖(explicit)”)。
- 如果日志文件中不包含调用覆盖信息或不需要提取,可以省略此参数,trace2syz 将按原样生成 Syzkaller 程序。
- 示例配置文件 distill.json 可以在 getting-started/ 目录中找到。
- 示例trace文件getting-started/sampletraces则需要通过moonshine的github项目给出的google云盘去下载作者提供的示例trace文件,也可以采用作者指定版本和补丁修改后的strace手动捕获示例。如果没有样例日志,可以从 Google Drive 上下载官方提供的样例日志压缩包,将其解压到 getting-started/ 目录中,以便进行示例测试。
google drive
- 如果指定了 -deserialize 参数,trace2syz 还会将解析的 Syzkaller 程序存储在指定目录下,以便手动检查转换效果。
- 如果不使用 -distill 参数,则 trace2syz 会直接转换日志内容,无需进行额外提取处理。经测试,不使用参数去蒸馏trace时,corpus.db的大小从80kb上升到360kb
6. 运行实例分析
- 运行记录:
| trace内容 | 文件数量 | 蒸馏策略 | 转换后数量 | 转换后corpus.db大小 | 分析 |
| 样例trace | 346 | 显式+隐式 | 385 | 80kb | 已验证可用 |
| 样例trace | 346 | 无 | 485 | 361kb |
|
|
1. 运行如下命令来处理作者提供的示例trace:
| Bash |
|
|
|
成功执行后,trace2syz 将输出类似以下内容:
| Plain Text |
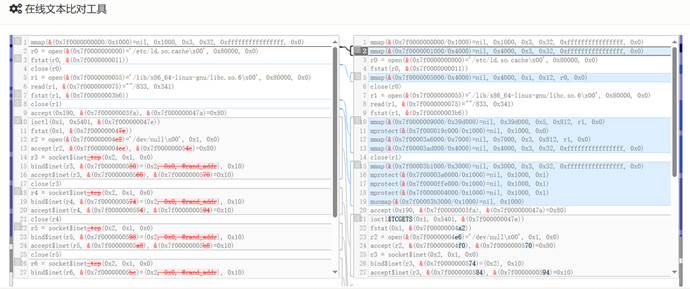
生成的corpus.db文件可以用于Syzkaller进行模糊测试,deserialize保存了反序列后的文本格式的系统调用序列。
转换前后的结果如下:
|
|
|

2. 若采用非指定strace(为进行trace2syz的转换,作者对strace进行了修改,指定了采用的strace版本和补丁号)获取的trace实例:
| SQL |
转换后的结果如下:
|
|
|
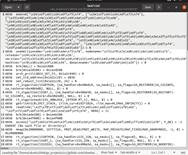
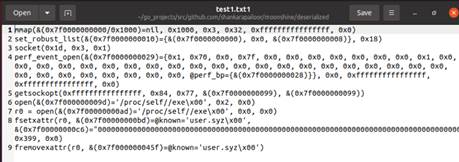
3. 使用 strace 跟踪 ls 命令: 在终端中运行以下命令,以生成系统调用跟踪文件 trace:
| SQL |
这个命令将会跟踪 ls 命令的系统调用,并将结果保存到 trace 文件中。
运行 syz-trace2syz 转换 trace 文件: 假设 syz-trace2syz 已编译完成并可以执行,请运行以下命令以将 trace 文件转换为 Syzkaller 格式:
| SQL |
此命令会解析 trace 文件,并将其转化为 Syzkaller 测试用例格式,适合作为 Syzkaller 的种子输入。
7. 收集带有覆盖率trace
| SQL |
1. 安装Strace并应用补丁。克隆strace仓库并切换到指定的commit:
| Bash |
2. 应用MoonShine的kcov补丁:
| Bash |
3. 构建strace:
| Bash |
4. 使用Strace采集trace
通过以下命令来使用patched strace采集带有覆盖率的trace:
| Bash |
采集不带有覆盖率的trace,即仅进行格式转换,去掉-k参数:
| SQL |
-o tracefile: 将输出写入到指定的文件中。
/path/to/executable arg1 arg2 .. argN: 指定要跟踪的可执行文件及其参数。
必需参数
① -s [val]:
- 作用:指定每个调用的最大数据写入量。
- 默认值:通常设置为 65500 字节。
- 意义:控制输出的字节数,以防止过多数据导致输出难以处理。
② -v:
- 作用:要求 strace 输出未缩写的参数信息。
- 意义:提供更详细的输出,便于分析每个系统调用的参数。
③ -xx:
- 作用:以十六进制格式输出字符串。
- 意义:有助于以更可读的形式查看二进制数据和字符串,适合调试。
可选参数
① -f:
- 作用:捕获子进程的跟踪信息(支持在 fork 后继续跟踪)。
- 意义:对于需要分析多进程应用的情况非常有用,可以提供完整的执行跟踪。
② -k:
- 作用:捕获每个调用的覆盖率。
- 限制:仅在经过补丁的 strace 中支持,需要内核编译时启用 CONFIG_KCOV=y。
- 意义:用于分析测试覆盖率,特别是在调试或性能分析时。
二.trace2syz复现
1. 蒸馏与Syzkaller模糊器最小化程序有何不同?
|
作者有两个主要好处: 1) 它允许我们将来自真实程序的非常大的跟踪序列化为紧凑的 Syzkaller 跟踪。即使是几秒钟的跟踪(比如 Chrome?)也太大了,甚至无法序列化为有效的 Syzkaller 程序。蒸馏可以预先创建紧凑而有趣的种子。 2) 现有的 fuzzer 最小化效果很好,因为 Syzkaller 自然会生成紧凑的程序;但是,根据我的经验,这无法有效地扩展即使是 100 个调用的程序(例如这些)。例如,Syzkaller 似乎试图预先减少起始种子,对吗?我记得只提供了少数几个这些转换后的程序,在我杀死它之前,最小化还持续了一天半。 |
|
|
|
|
moonshine工具被分为 2 个独立的工具:
一个将 strace 转换为 syzkaller 程序,一个用于实现trace的蒸馏。
第一个工具被重构为两个包:parser 和 proggen。parser 只是将 strace 输出转换为中间表示,而 proggen 将 IR 转换为 syzkaller 程序。
使用步骤:
要运行 trace2syz 并生成 Syzkaller 的种子,可以按照以下步骤操作:
2. 编译trace2syz
trace2syz已经被合并至syzkaller项目tools文件夹内,该文件夹内包含了多种syzkaller扩展工具,例如syz-db用户管理corpus.db。
1.首先,需要构建 syz-trace2syz 工具,步骤如下:
切换到 syzkaller 的源代码目录。
第一种方法:使用 make trace2syz 命令构建 trace2syz 工具:
| Bash |
第二种方法:手动切换到 tools/syz-trace2syz 目录,然后运行:(并未奏效)
| Bash |
确保 trace2syz 已经成功构建。trace2syz 应位于 ./bin/trace2syz(采用第二种方式时,需要将可执行文件复制到/bin目录下),并且 distillConfig.json 配置文件也已准备好(在moonshine仓库中的getting_started文件下找到)。
3. 运行命令
使用以下命令运行 syz-trace2syz 来解析日志目录并生成 Syzkaller 程序种子:
./bin/syz-trace2syz -dir tracedir -distill getting-started/distill.json参数说明:
- -dir [tracedir]:要解析的日志文件目录。目录内应包含使用 strace 生成的系统调用日志文件。
- -distill [distillConfig.json]:指定配置文件,用于设定提取策略(例如“隐式依赖”或“仅显式依赖”)。
- 如果日志文件中不包含调用覆盖信息或不需要提取,可以省略此参数,trace2syz 将按原样生成 Syzkaller 程序。
- 示例配置文件 distill.json 可以在 getting-started/ 目录中找到。
- 如果指定了 -deserialize 参数,trace2syz 还会将解析的 Syzkaller 程序存储在指定目录下,以便手动检查转换效果。
- 如果不使用 -distill 参数,则 trace2syz 会直接转换日志内容,无需进行额外提取处理。
4. 示例
运行示例命令:
./bin/syz-trace2syz -dir getting-started/sampletraces/ -distill getting-started/distill.json
./bin/syz-trace2syz -dir getting-started/sampletraces
./bin/syz-trace2syz -dir getting-started/test1成功执行后,trace2syz 将输出类似以下内容:
| Plain Text |
5. 生成的输出文件
生成的 corpus.db 文件包含已序列化的 Syzkaller 程序,准备好用于 Syzkaller 的模糊测试。生成的 corpus.db 文件将存放在运行 trace2syz 命令的当前目录下。在运行过程中,trace2syz 会将所有转换生成的 Syzkaller 程序序列化为 corpus.db,默认不支持指定存储位置,因此确保运行命令的工作目录具有写权限,方便保存生成的 corpus.db 文件
https://github.com/google/syzkaller/issues/3508
| SQL |
使用 strace 跟踪 ls 命令: 在终端中运行以下命令,以生成系统调用跟踪文件 trace:
| SQL |
这个命令将会跟踪 ls 命令的系统调用,并将结果保存到 trace 文件中。
运行 syz-trace2syz 转换 trace 文件: 假设 syz-trace2syz 已编译完成并可以执行,请运行以下命令以将 trace 文件转换为 Syzkaller 格式:
| SQL |
此命令会解析 trace 文件,并将其转化为 Syzkaller 测试用例格式,适合作为 Syzkaller 的种子输入。
6. 复现配置记录
检查它的提交历史
| SQL |
| Bash |
两个版本go的路径都在go_projects下,goroot是1.22.1,go是1.11.13.
| SQL |
参考文献
moonshine仓库
trace2syz仓库