LLAVA Visual Instruction Tuning——视觉语言通用模型的先驱
Instruction
1. 研究背景与目标
- 背景: 人类通过视觉、语言等多模态渠道理解世界。当前AI模型虽在单一视觉任务(如分类、检测)上表现出色,但通常是为特定任务设计的,缺乏通用性。
- 目标: 开发一个通用视觉助手,能够像人一样,遵循复杂、开放的多模态指令(结合图像和文本),完成现实世界的多样化任务。
2. 核心方法
- 技术路线: 创造性地将大型语言模型的强大指令跟随与推理能力,与大型视觉模型的开放世界视觉理解能力相结合。
- 关键创新:
- 数据生成: 利用GPT-4等高级语言模型,自动生成大规模、高质量的多模态指令-跟随数据,解决了人工标注成本高昂的难题。(即提出了视觉-文本对的训练数据得到的一个Pipeline)
- 模型架构: 设计了一个简单而高效的端到端训练架构,将视觉编码器和语言解码器连接起来,使模型能够直接处理图像和文本输入并生成文本输出。
3. 主要贡献与成果
- 高性能: 在多模态推理数据集 Science QA 上,通过与GPT-4集成,取得了当时的最佳成绩,证明了其强大的推理能力。
- 新基准: 发布了 LLaVA-Bench,一个专门用于评估多模态指令跟随能力的综合性基准测试,为后续研究提供了重要评估工具。
- 全面开源: 公开了生成的数据集、完整代码库、模型检查点和在线演示。这一举措极大地推动了整个领域的发展,降低了研究门槛。
4. 核心意义
LLaVA 的工作是多模态大模型领域的里程碑。它成功地将ChatGPT式的对话与指令跟随能力扩展到了视觉领域,证明了通过**“语言模型引导 + 高效架构 + 开源生态”**的路径,可以构建出功能强大且通用的视觉智能体,为后续的GPT-4V、Gemini等更先进模型奠定了重要基础。
GPT-assisted Visual Instruction Data Generation
1. 存在的问题
这一部分就是详细阐述在数据集上作出的贡献,目前公开数据集主要的问题是:
- 如LAION虽然数量大,但是内容简单单一,只有一句客观描述
- 数据是陈述句,而不是问句,无法满足对话
2.基础方案
- 思路: 既然有图像和描述,我们可以让GPT-4根据描述自动生成一些相关的问题。
- 示例:原始描述: “一群人站在一辆黑色车旁,周围是各种行李。”
- GPT-4生成的问题: “图片中的人们在做什么?”
- 形成数据对:用户: [问题] [图像]
- 助手: [原始描述]
- 优点: 实现了从0到1的突破,将静态描述转化为了问答形式。
- 缺点: 数据依然单一、缺乏深度。问题和答案都局限于原始描述,没有引入新的视角(如对话、推理、创意)。
3. 核心创新
- 定义对话种子,设计了三种不同的对话场景,作为GPT-4生成对话的起点:
- 类型1:描述->对话
- 种子:给GPT4图像描述
- 指令:基于这个描述,创建一段设计多轮对话的指令
- GPT4会生成类似描述这张图片的指令,并给出包含多轮对话的范例
- 类型2:描述->深度推理
- 种子:图像描述
- 指令:基于这个描述,创建一个需要推理才能回答的指令
- 产出:GPT-4会生成类似图片中的人们可能要去哪里。为什么这样的结合常识才能回答的问题
- 类型3:图像->创意任务
- 这是最大胆的一步。由于GPT-4无法“看”图,作者让GPT-4生成通用的、不依赖具体图像内容的创意指令模板。
- 指令: “创建一个有趣的视觉问答任务,比如‘扮演一个诗人为这张图写一首诗’。”
- 产出:GPT-4会生成各种创意指令模板,如“请为这张图设计一个海报”、“以图中物体的口吻讲个故事”等。这些模板可以应用到任何图像上。
- 结果:通过这三种方式,作者将简单的图像-描述对,爆炸式地扩展成了包含对话、推理、创意等多种类型的158K高质量、多样化的多模态指令数据集。
- 类型1:描述->对话
Visual Instruction Tuning
4.1 网络架构
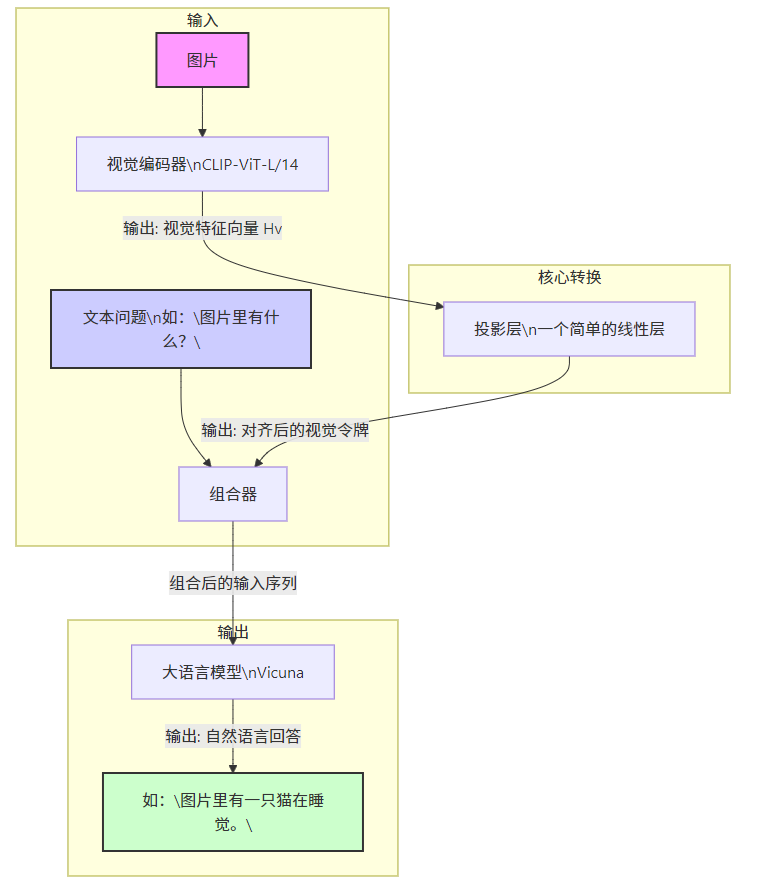
本节的主要目标是有效利用预训练大语言模型(LLM)与视觉模型的能力。网络架构如图 1 所示。
我们选用 Vicuna [9] 作为我们的语言模型,记为 fϕ(⋅)f_\phi(\cdot)fϕ(⋅),其参数为 ϕ\phiϕ。因为 Vucina 在公开模型中具有最强的指令跟随能力 [48, 9, 38]。
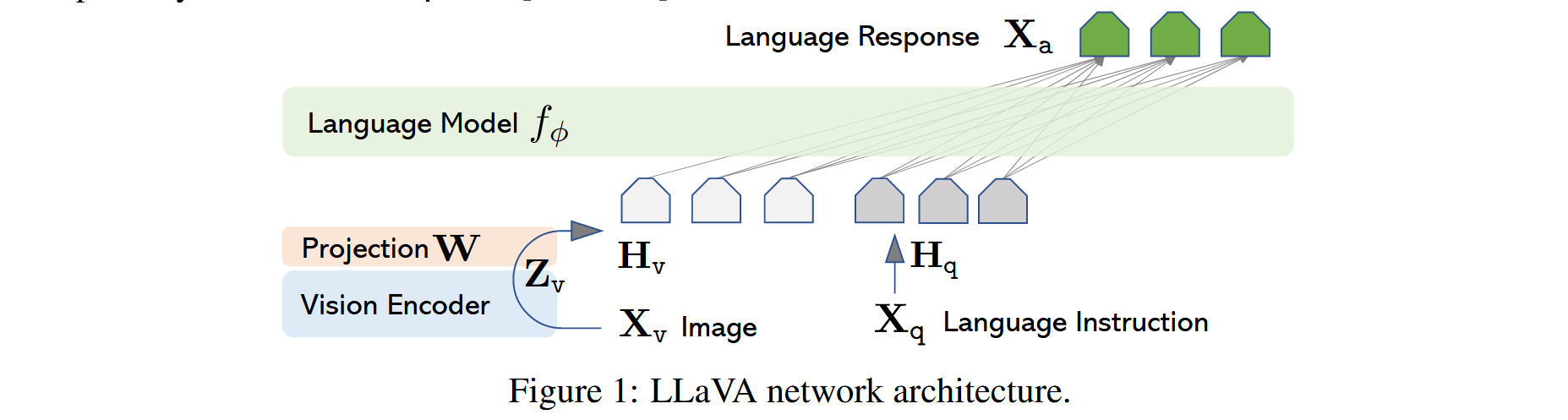
视觉编码器
对于输入图像 XvX_vXv,我们采用预训练的 CLIP 视觉编码器 ViT-L/14 [40],生成视觉特征 Zv=g(Xv)Z_v = g(X_v)Zv=g(Xv)。实验中我们考虑了最后一个 Transformer 层之前和之后的网格特征。
投影层
我们使用一个简单的线性层将图像特征映射到词嵌入空间。具体来说,我们应用一个可训练的投影矩阵 WWW,将 ZvZ_vZv 转换为与语言模型词嵌入维度相同的语言嵌入令牌 HvH_vHv:
Hv=W⋅Zv,其中Zv=g(Xv)(1)
H_v = W \cdot Z_v, \quad \text{其中} \quad Z_v = g(X_v) \tag{1}
Hv=W⋅Zv,其中Zv=g(Xv)(1)
4.2 训练方法
对于每张图像 XvX_vXv,我们生成多轮对话数据 (X1q,X1a,⋯ ,XTq,XTa)(X_1^q, X_1^a, \cdots, X_T^q, X_T^a)(X1q,X1a,⋯,XTq,XTa),其中 TTT 为总轮数。我们将所有答案视为助手的回复,并将第 ttt 轮的指令 XtinstructX_t^{\text{instruct}}Xtinstruct 组织为:
Xtinstruct={随机选择 [X1q,Xv] 或 [Xv,X1q],t=1Xtq,t>1(2)
X_t^{\text{instruct}} =
\begin{cases}
\text{随机选择 } [X_1^q, X_v] \text{ 或 } [X_v, X_1^q], & t = 1 \\
X_t^q, & t > 1
\end{cases} \tag{2}
Xtinstruct={随机选择 [X1q,Xv] 或 [Xv,X1q],Xtq,t=1t>1(2)
这样便形成了如表 2 所示的统一格式的多模态指令跟随序列。我们使用语言模型原有的自回归训练目标,对 LLM 进行指令微调。
具体地,对于长度为 LLL 的序列,我们计算目标答案 XaX_aXa 的概率为:
p(Xa∣Xv,Xinstruct)=∏i=1Lpθ(xi∣Xv,X<iinstruct,X<ia)(3)
p(X_a | X_v, X^{\text{instruct}}) = \prod_{i=1}^L p_\theta(x_i | X_v, X^{\text{instruct}}_{<i}, X^a_{<i}) \tag{3}
p(Xa∣Xv,Xinstruct)=i=1∏Lpθ(xi∣Xv,X<iinstruct,X<ia)(3)
其中 θ\thetaθ 是可训练参数,X<iinstructX^{\text{instruct}}_{<i}X<iinstruct 和 X<iaX^a_{<i}X<ia 分别为当前预测令牌 xix_ixi 之前所有轮次的指令和答案令牌。为了强调图像对所有回答的基础作用,我们在条件概率中显式加入了 XvX_vXv。
LLaVA 的训练采用两阶段指令微调流程:
阶段一:预训练以实现特征对齐
为了在概念覆盖与训练效率之间取得平衡,我们从 CC3M 数据集中筛选出 595K 图文对(筛选细节见附录)。使用第三节中描述的简单扩展方法将其转换为指令跟随数据,每个样本视为单轮对话。
对于图像 XvX_vXv,随机采样一个语言指令 XqX_qXq,要求助手简要描述图像,真实答案 XaX_aXa 即为原始标题。
训练过程中,冻结视觉编码器和语言模型权重,仅训练投影矩阵 WWW,最大化公式 (3) 的似然。这一阶段可理解为为冻结的 LLM 训练一个兼容的视觉 tokenizer。
仅训练投影矩阵WWW,以实现视觉和文本的对齐功能,及训练这个矩阵,能够把视觉的输入投影到对应正确的文本,如何对应呢,即让模型给出一个文本描述,计算其与原本文本描述的差异作为损失。
1. 数学表达
在这个阶段,我们不进行复杂的问答,只做简单的“看图说话”。模型的任务是,根据图片 III,生成一个简短的描述 YcY_cYc(Caption)。我们希望模型学到的概率是:
P(Yc∣I)
P(Y_c | I)
P(Yc∣I)
但是,语言模型 fϕf_\phifϕ 本身不认识图片。所以,我们需要通过投影层 WWW 把图片特征 ZvZ_vZv 变成语言模型能懂的“视觉令牌” HvH_vHv。
Hv=W⋅Zv
H_v = W \cdot Z_v
Hv=W⋅Zv
然后,我们将这个视觉令牌 HvH_vHv 作为“提示”(Prefix),输入给语言模型,让它根据这个提示来生成描述 YcY_cYc。
所以,整个模型的预测过程可以表示为:
P(Yc∣I)=fϕ(Hv)=fϕ(W⋅Zv)
P(Y_c | I) = f_\phi(H_v) = f_\phi(W \cdot Z_v)
P(Yc∣I)=fϕ(Hv)=fϕ(W⋅Zv)
2. 训练目标(损失函数)
我们希望模型生成的描述 YcY_cYc 和数据集中真实的描述 Yc∗Y_c^*Yc∗ 越接近越好。衡量这个“接近程度”的标准是交叉熵损失。
损失函数 L1L_1L1 如下:
L1=CrossEntropy(fϕ(W⋅Zv),Yc∗)
L_1 = \text{CrossEntropy}(f_\phi(W \cdot Z_v), Y_c^*)
L1=CrossEntropy(fϕ(W⋅Zv),Yc∗)
在训练时,我们只更新投影层 WWW 的参数,视觉编码器 fθf_\thetafθ 和语言模型 fϕf_\phifϕ 的参数都保持不变。
3. 举个例子
假设我们有一张图片 III 和它对应的简单描述 Yc∗="一只猫"Y_c^* = \text{"一只猫"}Yc∗="一只猫"。
- 视觉编码:图片 III 被送入 CLIP-ViT 模型,输出一个视觉特征向量 ZvZ_vZv。这个向量是一堆数字,比如
[0.12, -0.45, ..., 0.89],计算机知道它代表“猫”,但语言模型不知道。 - 特征投影:投影层 WWW(一个可学习的矩阵)对 ZvZ_vZv 进行线性变换,得到视觉令牌 HvH_vHv。这个 HvH_vHv 是一个在语言模型的词嵌入空间里的向量。可以理解为,WWW 把“计算机视觉语言”翻译成了“自然语言模型能理解的词汇”。
- 文本生成:语言模型 fϕf_\phifϕ 接收到 HvH_vHv 作为输入,开始预测下一个词。它可能会先预测出“一”,然后根据“一”和 HvH_vHv 预测出“只”,再预测出“猫”。
- 计算损失:模型生成的序列是“一只猫”,真实标签 Yc∗Y_c^*Yc∗ 也是“一只猫”。它们完全一致,所以交叉熵损失 L1L_1L1 非常低。如果模型预测错了,比如生成了“一只狗”,损失就会很高。
- 反向传播:这个损失值会通过反向传播算法,只去更新投影层 WWW 的参数,让 WWW 下次翻译得更准一些。经过成千上万张图片的训练,WWW 就学会了如何将各种视觉特征(狗、车、树等)准确地映射到语言模型能理解的对应概念上。
第一阶段小结:就像教一个翻译官背词典。给他看一张猫的图,他必须说出“猫”。说错了就纠正他。反复练习,直到他能准确地将看到的任何东西都翻译成语言大师能听懂的词。
阶段二:端到端微调
在第二阶段,我们始终冻结视觉编码器,继续更新投影层和 LLM 的权重,即 θ={W,ϕ}\theta = \{W, \phi\}θ={W,ϕ}。
我们考虑两种具体应用场景:
1. 多模态聊天机器人
我们使用第三节生成的 158K 语言-图像指令跟随数据进行微调。在三种响应类型中,对话是多轮的,其余两种为单轮。训练时均匀采样这些数据。
2. 科学问答(Science QA)
我们在 ScienceQA 基准 [34] 上评估我们的方法。这是首个大规模多模态科学问答数据集,每个问题附带自然语言或图像形式的上下文,并标注了答案与详细讲解。
助手需以自然语言给出推理过程,并在多个选项中选择答案。我们将数据组织为单轮对话,将问题与上下文作为 XinstructX^{\text{instruct}}Xinstruct,推理过程与答案作为 XaX_aXa。
上面的是原文中的表达,实质上第二阶段,就是在投影矩阵训练完成后,在复杂数据集上进行整体微调,训练整个模型的能力。
1. 数学表达
这个阶段的输入更复杂,包括图片 III 和详细的文本指令 XinstructX_{\text{instruct}}Xinstruct。输出也不再是简单描述,而是包含推理过程的完整回答 YaY_aYa。
模型需要学习的概率是:
P(Ya∣Xinstruct,I)
P(Y_a | X_{\text{instruct}}, I)
P(Ya∣Xinstruct,I)
为了做到这一点,模型需要同时处理文本和视觉信息。我们将文本指令 XinstructX_{\text{instruct}}Xinstruct 和翻译后的视觉令牌 HvH_vHv 拼接在一起,形成一个统一的输入序列,然后送入语言模型。
Hcombined=Concat(Embed(Xinstruct),Hv)=Concat(Embed(Xinstruct),W⋅Zv)
H_{\text{combined}} = \text{Concat}(\text{Embed}(X_{\text{instruct}}), H_v) = \text{Concat}(\text{Embed}(X_{\text{instruct}}), W \cdot Z_v)
Hcombined=Concat(Embed(Xinstruct),Hv)=Concat(Embed(Xinstruct),W⋅Zv)
这里的 Embed(⋅)\text{Embed}(\cdot)Embed(⋅) 是语言模型自带的文本嵌入层。
由于前面的投影矩阵对齐,在此处语言模型得到的输入就是HcombinedH_{combined}Hcombined
然后,语言模型基于这个组合输入进行预测:
P(Ya∣Xinstruct,I)=fϕ(Hcombined)
P(Y_a | X_{\text{instruct}}, I) = f_\phi(H_{\text{combined}})
P(Ya∣Xinstruct,I)=fϕ(Hcombined)
2. 训练目标(损失函数)
同样,我们使用交叉熵损失来衡量模型生成的回答 YaY_aYa 与标准答案 Ya∗Y_a^*Ya∗ 之间的差距。
损失函数 L2L_2L2 如下:
L2=CrossEntropy(fϕ(Concat(Embed(Xinstruct),W⋅Zv)),Ya∗)
L_2 = \text{CrossEntropy}(f_\phi(\text{Concat}(\text{Embed}(X_{\text{instruct}}), W \cdot Z_v)), Y_a^*)
L2=CrossEntropy(fϕ(Concat(Embed(Xinstruct),W⋅Zv)),Ya∗)
在训练时,我们同时更新投影层 WWW 和语言模型 fϕf_\phifϕ 的参数。视觉编码器 fθf_\thetafθ 依然保持不变。
这里和单独训练WWW其实就是类似的,不过第一阶段只是训练模型在接收到投影层输入HvH_vHv下能否回答正确的图像描述,而现在是在复杂数据上处理,并且输入从原本的纯文本改为了HcombinedH_{combined}Hcombined,能否正确的实现图像问答
3. 举个例子
假设我们有一个多模态指令数据样本:
- 图片 III:一张图片,里面有一个男孩在喂一只长颈鹿。
- 指令 XinstructX_{\text{instruct}}Xinstruct:
"请根据图片回答以下问题:图中的动物是什么?它正在做什么?" - 标准答案 Ya∗Y_a^*Ya∗:
"图中的动物是长颈鹿。它正在低头吃男孩手中的食物。"
- 视觉编码与投影:
- 图片 III 通过视觉编码器 fθf_\thetafθ 得到 ZvZ_vZv。
- ZvZ_vZv 通过投影层 WWW 得到视觉令牌 HvH_vHv。HvH_vHv 现在包含了“男孩”、“长颈鹿”、“喂食”等复杂场景的语义信息。
- 文本嵌入与拼接:
- 指令 XinstructX_{\text{instruct}}Xinstruct被语言模型的嵌入层转换成一系列向量。
- 我们将指令的向量和视觉令牌 HvH_vHv 拼接起来,形成一个长序列。可以想象成,在语言模型的“耳边”悄悄告诉它:“喂,你看到的场景是 HvH_vHv,现在请根据这个场景回答下面的问题:…”。
- 自回归生成:
- 语言模型 fϕf_\phifϕ 接收到这个混合了视觉和文本信息的输入后,开始一个词一个词地生成答案。
- 它可能会先生成“图中的”,然后根据上下文生成“动物”,再生成“是”,接着它需要利用视觉信息 HvH_vHv 了,于是生成了“长颈鹿”。
- 继续这个过程,生成“。”、“它”、“正在”、“低头”、“吃”… 直到生成完整的答案。
- 计算损失:
- 模型生成的完整答案是
Y_a = "图中的动物是长颈鹿。它正在低头吃男孩手中的食物。"。 - 这个答案和标准答案 Ya∗Y_a^*Ya∗ 完全一致,所以损失 L2L_2L2 很低。如果模型说成了“大象”或者“睡觉”,损失就会很高。
- 模型生成的完整答案是
- 反向传播:
- 这个损失值会同时更新两个部分的参数:
- 更新投影层 WWW:让它能更精确地翻译出“长颈鹿吃食”这种复杂互动场景的语义,而不仅仅是单个物体。
- 更新语言模型 fϕf_\phifϕ:让它学会如何利用视觉信息进行推理。比如,当它看到“动物是什么?”这个问题时,它应该知道要去关注 HvH_vHv 里的主体信息;当它看到“正在做什么?”时,它应该去关注 HvH_vHv 里的动作信息。通过大量数据,语言模型学会了这种“看图说话”的推理能力。
第二阶段小结:就像让整个团队进行实战演练。你给他们一个复杂的任务(指令)和相关资料(图片),要求他们给出一份完整的报告(答案)。如果报告写得不好,你不仅会批评翻译官(WWW),说他资料没翻译好,也会批评语言大师(fϕf_\phifϕ),说他没好好利用资料、逻辑不清。通过反复演练,整个团队配合得越来越默契,最终能出色地完成各种复杂任务。
- 这个损失值会同时更新两个部分的参数:
总结
| 阶段 | 核心任务 | 输入 | 输出 | 公式表示 | 训练目标 | 训练的模块 |
|---|---|---|---|---|---|---|
| 第一阶段 | 特征对齐 | 图片 III | 简单描述 YcY_cYc | P(Yc∣I)=fϕ(W⋅Zv)P(Y_c | I) = f_\phi(W \cdot Z_v)P(Yc∣I)=fϕ(W⋅Zv) | L1=CE(fϕ(W⋅Zv),Yc∗)L_1 = \text{CE}(f_\phi(W \cdot Z_v), Y_c^*)L1=CE(fϕ(W⋅Zv),Yc∗) | 仅投影层 WWW |
| 第二阶段 | 指令微调 | 图片 III + 指令 XinstructX_{\text{instruct}}Xinstruct | 完整回答 YaY_aYa | P(Ya∣Xinstruct,I)=fϕ(Concat(Embed(Xinstruct),W⋅Zv))P(Y_a | X_{\text{instruct}}, I) = f_\phi(\text{Concat}(\text{Embed}(X_{\text{instruct}}), W \cdot Z_v))P(Ya∣Xinstruct,I)=fϕ(Concat(Embed(Xinstruct),W⋅Zv)) | L2=CE(fϕ(Concat(Embed(Xinstruct),W⋅Zv)),Ya∗)L_2 = \text{CE}(f_\phi(\text{Concat}(\text{Embed}(X_{\text{instruct}}), W \cdot Z_v)), Y_a^*)L2=CE(fϕ(Concat(Embed(Xinstruct),W⋅Zv)),Ya∗) | 投影层 WWW + 语言模型 fϕf_\phifϕ |
通过这样“先对齐,后微调”的两步走策略,LLaVA 既高效地建立了跨模态的沟通桥梁,又赋予了模型强大的多模态理解和推理能力,最终实现了一个既能看图、又能听懂指令、还能进行深度思考的智能模型。