Redis(七):Redis高并发高可用(主从复制)
我首先在本地启动了三个Redis服务(我用docker部署的Redis),端口号分别为6379、6380、6381,且三个Redis服务中没有任何数据。
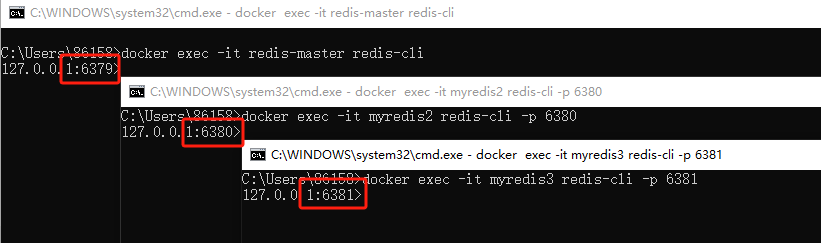
6379设置key value;6380设置自己为6379 的从节点“slaveof 192.168.10.9 6379”;6380会同步6379的数据,输入kyes *发现k1已同步,如下图
ps:因为我是将redis装在了docker中,故需要用局域网IP而不能用127.0.0.1(指代docker容器自己),所以需要指定宿主机的IP
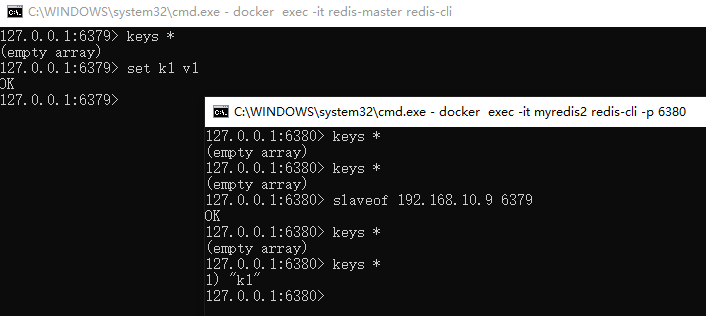
127.0.0.1:6380> info replication
# Replication
role:slave #<--------------------角色为从节点
master_host:192.168.10.9
master_port:6379 #<----------------主节点端口号
master_link_status:up
master_last_io_seconds_ago:6
master_sync_in_progress:0
slave_read_repl_offset:830
slave_repl_offset:830
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:11a5df4c869969ae558cd8792a86c305efcdbbda
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:830
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:467
repl_backlog_histlen:364
slaveof no one 表示不从属于任何主节点
127.0.0.1:6380> slaveof no one
OK
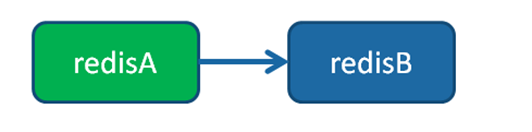
用以上方式可以实现:一主一从、一主多从、树状主从结构
- 一主(redisA)一从(redisB)
redisB:slaveof redisA port - 一主(redisA)多从(redisB、redisC、redisD、redisE)
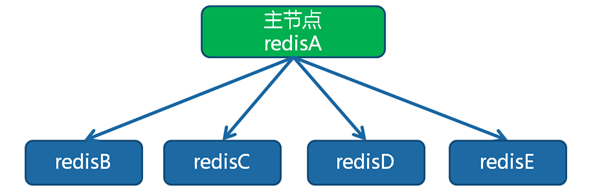
redisB:slaveof redisA port redisC:slaveof redisA port redisD:slaveof redisA port redisE:slaveof redisA port - 树状主从结构 (redisA[redisB[redisD,redisE],redisC])
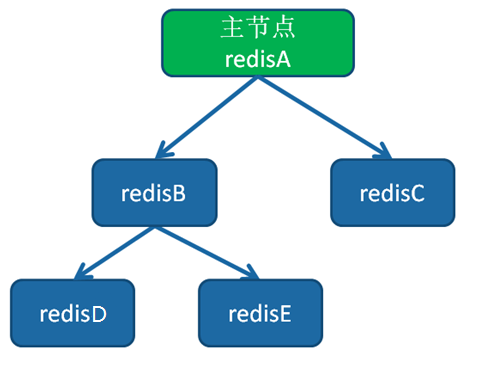
redisB:slaveof redisA portredisC:slaveof redisA portredisD:slaveof redisB portredisE:slaveof redisB port
默认情况下,从节点使用
slave-read-only=yes配置为只读模式。由于复制只能从主节点到从节点,对于从节点的任何修改主节点都无法感知,修改从节点会造成主从数据不一致。
Redis主从复制原理
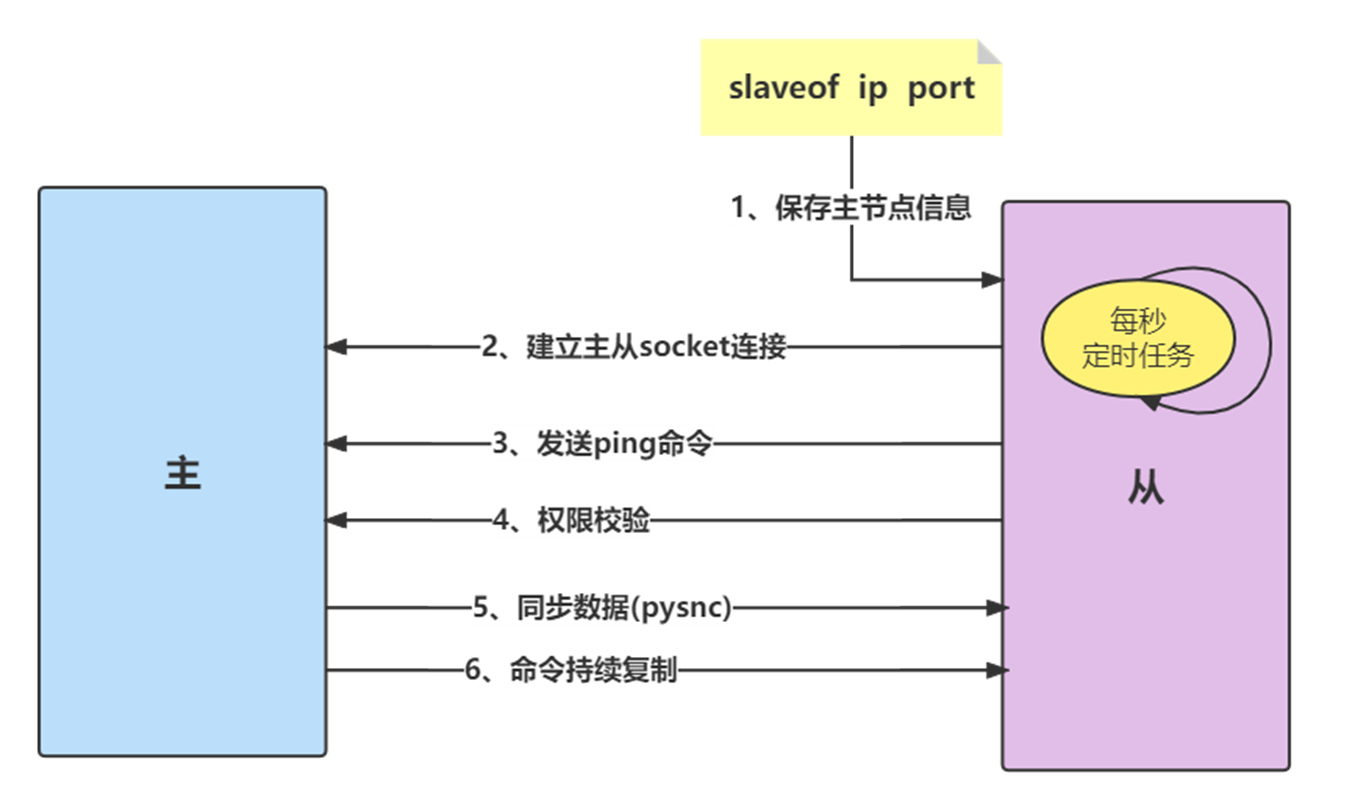
- 保存主节点信息
执行slaveof后从节点只保存主节点的地址信息便直接返回,这时建立复制流程还没有开始。 - 建立主从socket连接
从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接。
从节点会建立一个socket套接字,专门用于接受主节点发送的复制命令。从节点连接成功后打印日志。
如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行slaveof no one取消复制。 - 发送ping命令
连接建立成功后从节点发送ping请求进行首次通信,ping请求主要目的:检测主从之间网络套接字是否可用、检测主节点当前是否可接受处理命令。 - 权限验证
如果主节点设置了requirepass参数,则需要密码验证,从节点必须配置masterauth参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。 - 同步数据集
主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。Redis在2.8版本以后采用新复制命令 psync进行数据同步,原来的sync命令依然支持,保证新旧版本的兼容性。新版同步划分两种情况:全量同步和部分同步。 - 命令持续复制
当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。
2025-08-02 23:33:21 1:S 02 Aug 2025 15:33:21.036 * Connecting to MASTER 192.168.10.9:6379
2025-08-02 23:33:21 1:S 02 Aug 2025 15:33:21.037 * MASTER <-> REPLICA sync started
2025-08-02 23:33:21 1:S 02 Aug 2025 15:33:21.037 * REPLICAOF 192.168.10.9:6379 enabled (user request from 'id=4 addr=127.0.0.1:34912 laddr=127.0.0.1:6381 fd=8 name= age=9960 idle=0 flags=N db=0 sub=0 psub=0 ssub=0 multi=-1 qbuf=46 qbuf-free=20428 argv-mem=23 multi-mem=0 rbs=1024 rbp=0 obl=0 oll=0 omem=0 tot-mem=22447 events=r cmd=slaveof user=default redir=-1 resp=2 lib-name= lib-ver=')
2025-08-02 23:33:21 1:S 02 Aug 2025 15:33:21.038 * Non blocking connect for SYNC fired the event.
2025-08-02 23:33:21 1:S 02 Aug 2025 15:33:21.040 * Master replied to PING, replication can continue...
2025-08-02 23:33:21 1:S 02 Aug 2025 15:33:21.041 * Trying a partial resynchronization (request 62749822bd8f5562e3b08257d3ee6206b80465d1:1).
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.314 * Full resync from master: 11a5df4c869969ae558cd8792a86c305efcdbbda:6262
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.320 * MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF to disk
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.326 * Discarding previously cached master state.
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.326 * MASTER <-> REPLICA sync: Flushing old data
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.336 * MASTER <-> REPLICA sync: Loading DB in memory
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.457 * Loading RDB produced by version 7.2.4
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.457 * RDB age 0 seconds
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.457 * RDB memory usage when created 1.08 Mb
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.457 * Done loading RDB, keys loaded: 1, keys expired: 0.
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.458 * MASTER <-> REPLICA sync: Finished with success
Redis数据同步
全量同步
Redis早期支持的复制功能只有全量复制(sync命令),它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
Redis在2.8版本以后采用新复制命令psync进行数据同步,原来的sync命令依然支持,保证新旧版本的兼容性。新版同步划分两种情况:全量复制和部分复制。
流程说明
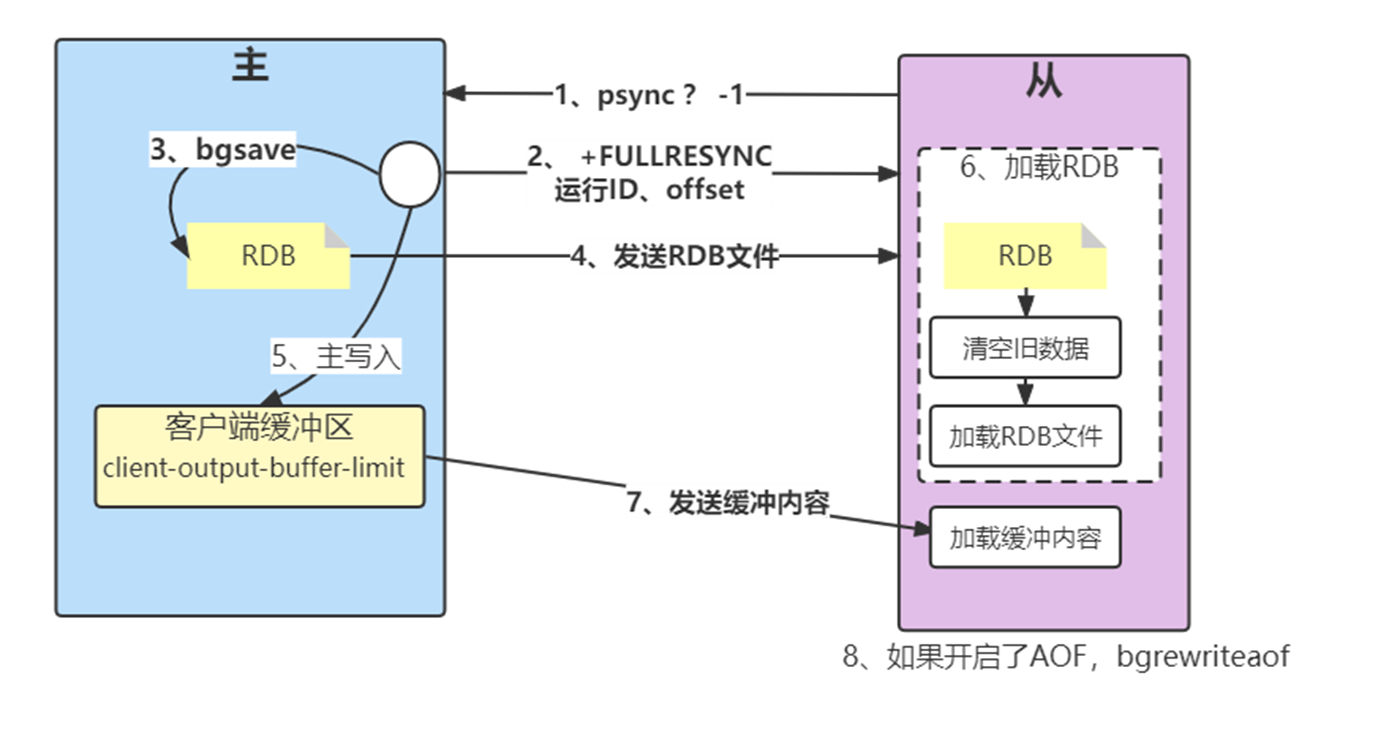
- 发送psync命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行ID,所以发送psync ? -1。
- 主节点根据psync ? -1解析出当前为全量复制,回复 +FULLRESYNC响应,从节点接收主节点的响应数据保存运行ID和偏移量offset,并打印日志。
- 主节点执行bgsave保存RDB 文件到本地。
- 主节点发送RDB文件给从节点,从节点把接收的RDB文件保存在本地并直接作为从节点的数据文件,接收完RDB后从节点打印相关日志,可以在日志中查看主节点发送的数据量。
- 对于从节点开始接收RDB快照到接收完成期间,主节点仍然响应读写命令,因此主节点会把这期间写命令数据保存在复制客户端缓冲区内,当从节点加载完RDB文件后,主节点再把缓冲区内的数据发送给从节点,保证主从之间数据一致性。
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.320 * MASTER <-> REPLICA sync: receiving streamed RDB from master with EOF to disk
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.326 * Discarding previously cached master state.
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.326 * MASTER <-> REPLICA sync: Flushing old data
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.336 * MASTER <-> REPLICA sync: Loading DB in memory
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.457 * Loading RDB produced by version 7.2.4
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.457 * RDB age 0 seconds
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.457 * RDB memory usage when created 1.08 Mb
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.457 * Done loading RDB, keys loaded: 1, keys expired: 0.
2025-08-02 23:33:26 1:S 02 Aug 2025 15:33:26.458 * MASTER <-> REPLICA sync: Finished with success
问题
通过分析全量复制的所有流程,会发现全量复制是一个非常耗时费力的操作。它的时间开销主要包括:
1、主节点bgsave时间。
2、RDB文件网络传输时间。
3、从节点清空数据时间。
4、从节点加载RDB的时间。
5、可能的AOF重写时间。
因此当数据量达到一定规模之后,由于全量复制过程中将进行多次持久化相关操作和网络数据传输,这期间会大量消耗主从节点所在服务器的CPU、内存和网络资源。
部分同步
部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施。
使用psync {runId} {offset} 命令实现
当从节点(slave)正在复制主节点(master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。
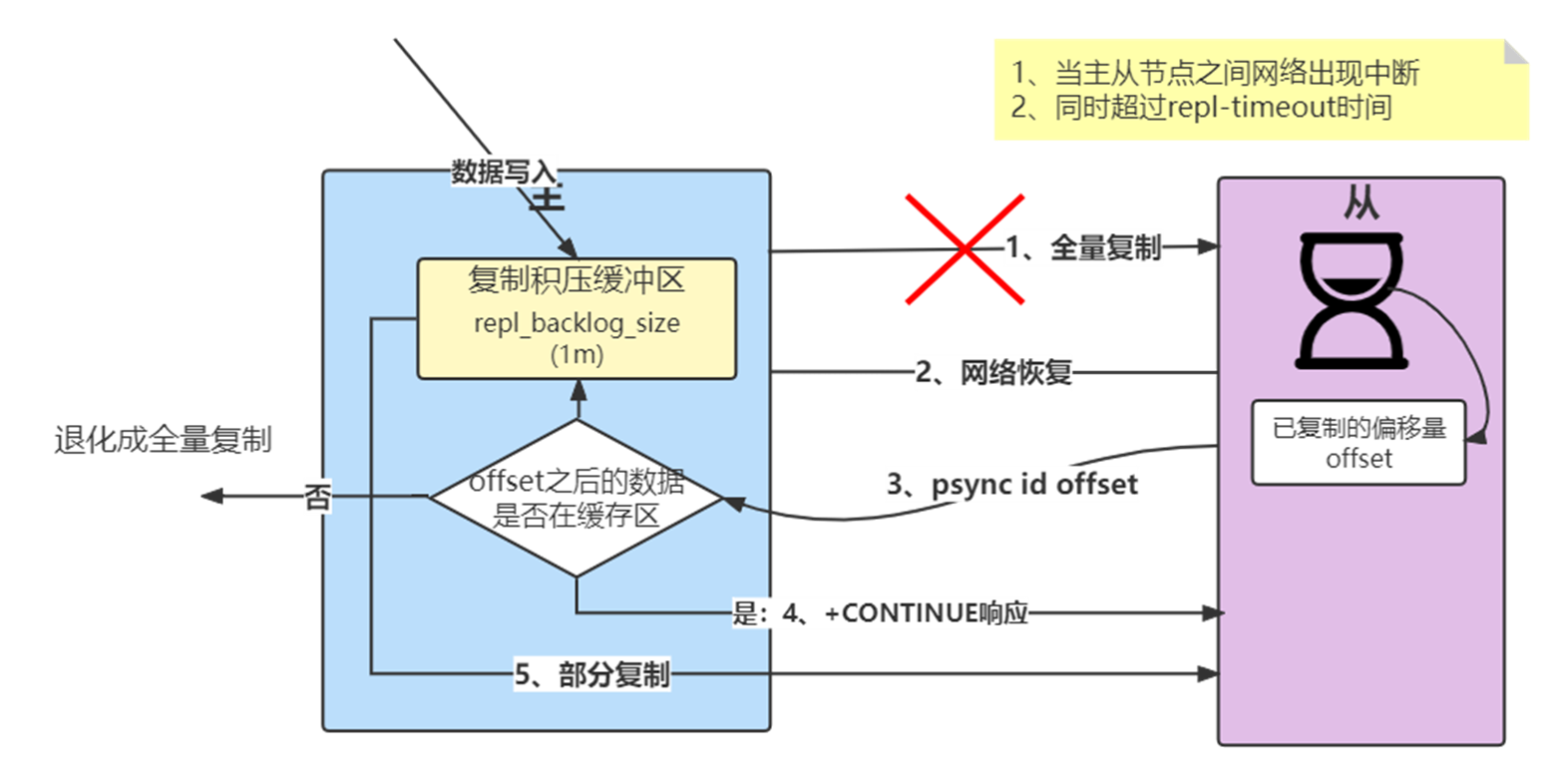
流程说明
- 当主从节点之间网络出现中断时,如果超过repl-timeout时间,主节点会认为从节点故障并中断复制连接,打印日志。如果此时从节点没有宕机,也会打印与主节点连接丢失日志。
- 主从连接中断期间主节点依然响应命令,但因复制连接中断命令无法发送给从节点,不过主节点内部存在的复制积压缓冲区,依然可以保存最近一段时间的写命令数据,默认最大缓存1MB。
- 当主从节点网络恢复后,从节点会再次连上主节点,打印日志。
- 当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和主节点的运行ID。因此会把它们当作psync参数发送给主节点,要求进行部分复制操作。
- 主节点接到psync命令后首先核对参数runId是否与自身一致,如果一致,说明之前复制的是当前主节点;之后根据参数offset在自身复制积压缓冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送+CONTINUE响应,表示可以进行部分复制。如果不再,则退化为全量复制。
- 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。发送的数据量可以在主节点的日志,传递的数据远远小于全量数据。
心跳
主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令。
主从心跳判断机制:
- 主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通信,通过client list命令查看复制相关客户端信息,主节点的连接状态为
flags=M,从节点连接状态为flags=S。 - 主节点默认每隔10秒对从节点发送ping命令,判断从节点的存活性和连接状态。
可通过参数repl-ping-slave-period控制发送频率。 - 从节点在主线程中每隔1秒发送
replconf ack {offset}命令,给主节点上报自身当前的复制偏移量。replconf命令主要作用如下:- 实时监测主从节点网络状态;
- 上报自身复制偏移量,检查复制数据是否丢失,如果从节点数据丢失,再从主节点的复制缓冲区中拉取丢失数据;
- 实现保证从节点的数量和延迟性功能,通过
min-slaves-to-write、min-slaves-max-lag参数配置定义;127.0.0.1:6380> config get min-slaves-max-lag
1)“min-slaves-max-lag”
2) “10”
127.0.0.1:6380> config get min-slaves-to-write
1) “min-slaves-to-write”
2) “0” - 主节点根据replconf命令判断从节点超时时间,体现在info replication统计中的lag信息中,lag表示与从节点最后一次通信延迟的秒数,正常延迟应该在0和1之间。如果超过repl-timeout配置的值((默认60秒),则判定从节点下线并断开复制客户端连接。即使主节点判定从节点下线后,如果从节点重新恢复,心跳检测会继续进行。