C语言:预处理、 库文件、 文件IO
预处理
预处理功能
条件编译
概念
定义:根据设定的条件选择待编译的语句代码。
预处理机制:将满足条件的语句进行保留,将不满足条件的语句进行删除,交个下一步编译。
语法:
语法1:
根据是否找到标记,来决定是否参与编译(标记存在为真,不存在为假)
#ifdef 标记 // 标记 一般使用宏定义... 语句代码1#else... 语句代码2#endif举例:
#define DEBUG 1 #ifdef DEBUGprintf("调试模式!\n"); // 保留#elseprintf("产品模式!\n"); // 删除#endif说明:
printf("调试模式!\n");和printf("调试模式!\n");只能保留一个。undef取消已定义的宏(使其变为未定义状态)。#define DEBUG 1 // 定义宏#undef DEBUG // 取消定义的宏#ifdef DEBUGprintf("调试模式!\n"); // 删除#elseprintf("产品模式!\n"); // 保留#endif语法2:
根据是否找到标记,来决定是否参与编译(标记不存在为真,存在为假)
#ifndef 标记... 语句代码1#else... 语句代码2#endif举例:
#define DEBUG 1 #ifndef DEBUGprintf("调试模式!\n"); // 删除#elseprintf("产品模式!\n"); // 保留#endif语法3:
根据表达式的结果,来决定是否参与编译(表达式成立为真,不成立为假)
// 单分支#if 表达式... 语句代码1#endif// 双分支#if 表达式... 语句代码1#else... 语句代码2#endif// 多分支#if 表达式1... 语句代码1#elif 表达式n... 语句代码n#else... 语句代码n+1#endif
案例
案例1
#include <stdio.h>// 定义一个条件编译的标记#define LETTER 1 // 默认是大写int main(int argc, char *argv[]){// 测试用的字母字符串char str[26] = "C Language";char c;int i = 0;// 遍历获取每一个字符while ((c = str[i]) != '\0'){#if LETTERif (c >= 'a' && c <= 'z'){c -= 32; // 大写}#elseif (c >= 'A' && c <= 'Z'){c += 32; // 小写}#endifprintf("%c",c);i++;}printf("\n");return 0;}案例2
需求:跨平台适配代码
#ifdef _WIN32 // Windows系统宏(VC编译器定义)#include <windows.h>#else // Linux/Unix系统#include <unistd.h>#endif#include <stdio.h>// 定义一个条件编译的标记#define LETTER 1 // 默认是大写int main(int argc, char *argv[]){#ifdef _WIN32 // Windows系统宏(VC编译器定义)printf("当前是windows平台!\n");#else // Linux/Unix系统printf("当前是Linux平台!\n");#endifreturn 0;}文件包含
概念
所谓“文件包含”处理是指一个源文件可以将另一个源文件的全部内容包含进来。通常用于共享代码、声明或宏定义。一个常规的C语言程序会包含多个源文件(*.c),当某些公共资源需要在各个源文件中使用时,为了避免多次编写相同的代码,我们一般会进行代码的抽取(*.h),然后在各个源文件中直接包含即可。
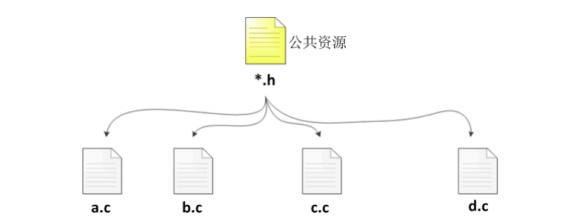
注意:*.h中的函数声明必须要在*.c中有对应的函数定义,否则没有意义。(函数一旦声明,就一定要定义)
基本语法
标准库包含(使用尖括号)(会到/usr/include目录下查找)
#include <stdio.h> // 包含标准输入输出库 会到/usr/include目录下查找#include <stdlib.h> // 包含标准库函数自定义文件包含(使用双引号)(会先在当前目录下查找,找不到再到/usr/include目录下查找)
#include "myheader.h" // 包含当前目录下的自定义头文件#include "utils/tool.h" // 包含子目录下的头文件
预处理机制
将文件中的内容替换文件包含指令
使用场景
头文件包含:通常将函数声明、宏定义、结构体定义等放在
.h头文件中,通过#include引入到需要使用的.c文件中。头文件中存放的内容,就是各个源文件的彼此可见的公共资源,包括:
全局变量的声明
普通函数的声明
静态函数的声明(static修饰的函数,建议写在.c文件中)
宏定义
结构体、共用体、枚举常量列表的定义
其他头文件包含
代码复用:可以将一些通用代码片段(如工具函数)放在单独的文件中,通过包含实现复用。
示例代码:
myhead.h
extern int global; // 全局变量的声明extern void func1(); // 普通函数的声明static void func2() // 静态函数的声明,写在.h中,引用此文件的.c文件直接调用,写在.c文件,只能这个.c文件访问{...}#define max(a,b) ((a) > (b) ? (a) : (b)) // 宏定义struct node // 结构体定义{..};union attr // 共用体定义{.. };enum SEX // 枚举常量列表定义{.. };#include <stdio.h> // 引入系统头文件#include "myhead2.h" // 引入自定义头文件
注意事项
避免循环包含(如
a.h包含b.h,同时b.h又包含a.h)为防止头文件被重复包含,通常会使用条件编译保护(推荐):
// 在myheader.h中#ifndef MYHEADER_H // _MYHEADER_H, __MYHEADER_H#define MYHEADER_H... 头文件内容#endif 或者使用#pragma once(非标准但被大多数编译器支持):#pragma once... 头文件内容
多文件开发
myheader.h
#ifndef MYHEADER_H#define MYHEADER_H#include <stdio.h>/*** 求数组的元素累加和*/extern int sum(const int*, int);#endifmyheader.c
#include "myheader.h"/*** 求数组的元素累加和*/int sum(const int* arr, int len){const int *p = arr;int sum = 0;for (; p < arr + len; p++){sum += *p;}return sum;}app.c
#include "myheader.h"int main(int argc, char **argv[]){int arr[] = {11,22,33,44,55};int res = sum(arr, sizeof(arr)/sizeof(arr[0]));printf("数组累加和的结果是%d\n", res);return 0;}多文件编译命令:
gcc app.c myhead.c -o app
其他指令(了解)
#line用于修改当前的行号和文件名(主要用于编译器调试,很少手动使用)。#line 100 "test.c" // 后续代码从行号100开始,文件名标识为test.cprintf("当前行号:%d\n", __LINE__); // 输出100#error在编译阶段当条件满足时抛出错误信息,并终止编译。#if VERSION < 1#error "VERSION必须大于等于1" // 若VERSION<1,编译时会报错并提示此信息#endif#pragma用于向编译器传递特定指令(不同编译器支持的#pragma功能不同),例如:#pragma once:确保头文件只被包含一次(类似#ifndef的效果)。简单但兼容性稍差#pragma pack(n):设置结构体成员的对齐方式为 n 字节。#pragma warning(disable: 1234):禁用特定警告编号的编译警告。
库文件
什么是库文件
库文件本质上是经过编译后生成的可被计算机执行的二进制代码。但注意库文件不能独立运行,库文件需要加载到内存中才能执行。库文件大量存在于Windows,Linux,MacOS等软件平台上。
库文件的分类
静态库
windows:xxx.lib
linux:libxxxx.a
动态库(共享库)
windows:xxx.dll
linux:libxxxx.so.major.minor (libmy.so.1.1)
注意:不同的软件平台因编译器、链接器不同,所生成的库文件是不兼容的。
静态库与动态库的区别
静态库链接时,将库中所有内容包含到最终的可执行程序中(程序和库合一)。
动态库链接时,将库中的符号信息包含到最终可执行文件中,在程序运行时,才将动态库中符号的具体实现加载到内存中(程序和库分离)。
静态库与动态库的优缺点
静态库
优点:生成的可执行程序不再依赖静态文件
缺点:可执行程序体积较大
动态库
优点:生成的可执行程序体积小;动态库可被多个应用程序共享
缺点:可执行程序运行依然依赖动态库文件
静态库与动态库对比
| 维度 | 静态库 | 动态库 |
|---|---|---|
| 文件体积 | 较大(库代码被复制) | 较小(共享库文件) |
| 部署难度 | 简单(单文件) | 需确保库存在于目标系统 |
| 更新维护 | 需重新编译程序 | 替换库文件即可 |
| 启动速度 | 稍快(无运行时链接开销) | 稍慢(需加载库) |
| 兼容性风险 | 无 | 需处理版本冲突(如DLL Hell) |
库文件创建
Linux系统下库文件的命名规范:libxxx.a(静态库) libxxxx.so(动态库)
静态库文件的生成
将需要生成库文件对应的源文件(
*.c)通过编译(不链接)生成*.o目标文件用
ar命令将生成的*.o打包生成libxxx.a
库的生成

库的使用

动态库文件的生成
将需要生成库文件对应的源文件(
*.c)通过编译(不链接)生成*.o目标文件将目标文件链接为
*.so文件
库的生成

库的使用
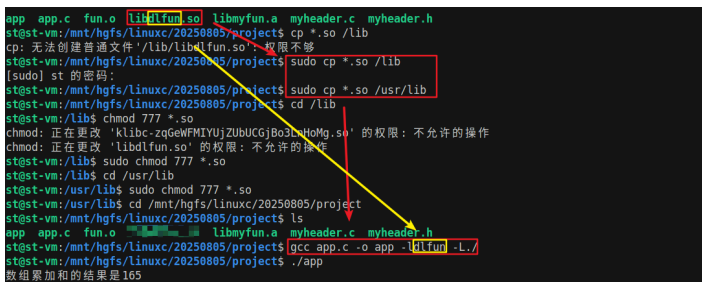
注意:如果在代码编译过程或者运行中链接了库文件,系统会到`/lib`和`/usr/lib`目录下查找库文件,所以建议直接将库文件放在`/lib`或者`/usr/lib`,否则系统可能无法找到库文件,造成编译或者运行错误。
扩展内容
查看应用程序(例如:app)依赖的动态库:

动态库使用方式:
编译时链接动态库,运行时系统自动加载动态库
程序运行时,手动加载动态库
实现:
涉及内容
头文件:
#include <dlfcn.h>接口函数:
dlopen、dlclose、dlsym依赖库:
-ldl句柄handler:资源的标识
- 示例代码:
#include <stdio.h>
#include <dlfcn.h>int main(int argc,char *argv[])
{// 1. 加载动态库 "/lib/libdlfun.so"// - RTLD_LAZY: 延迟绑定(使用时才解析符号,提高加载速度)// - 返回 handler 是动态库的句柄,失败时返回 NULLvoid* handler = dlopen("/lib/libdlfun.so", RTLD_LAZY); if (handler == NULL) {// 打印错误信息(dlerror() 返回最后一次 dl 相关错误的字符串)fprintf(stderr, "dlopen 失败: %s\n", dlerror());return -1;}// 2. 从动态库中查找符号 "sum"(函数名)// - dlsym 返回 void*,需强制转换为函数指针类型 int sum(int *arr, int size);// - 这里假设 "sum" 是一个接受两个int*,int参数、返回 int 的函数int (*paddr)(int*, int) = (int (*)(int*, int))dlsym(handler, "sum");if (paddr == NULL) {fprintf(stderr, "dlsym 失败: %s\n", dlerror());dlclose(handler); // 关闭动态库(释放资源)return -1;}// 3. 调用动态库中的函数 "sum",计算{11,12,13,14,15}的累加和int arr[5] = {11,12,13,14,15};printf("sum=%d\n", paddr(arr, sizeof(arr)/sizeof(arr[0])));// 4. 关闭动态库(释放内存和资源)dlclose(handler);return 0;
}- 编译命令
gcc demo06.c -ldl
标准I/O
文件基础概念
文件定义
存储在外存储器(磁盘、U盘、移动硬盘等)上的数据集合,是操作系统管理数据的基本单位。
文件操作核心
文件内容的读取(输入操作 Input)
文件内容的写入(输出操作 Output)
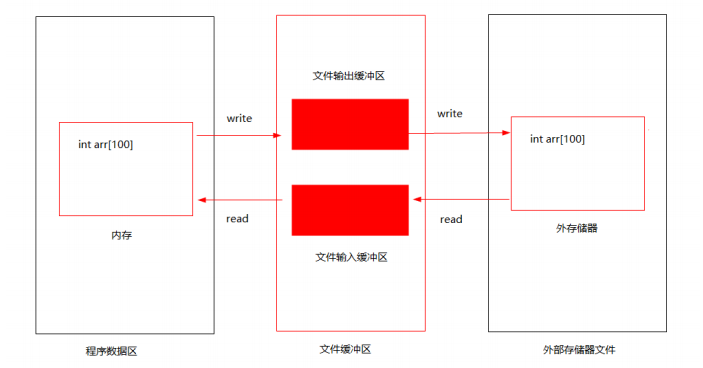
文件缓冲机制
系统为文件在内存中创建缓冲区(通常4KB大小)
程序操作实际上是在缓冲区进行
数据像水流一样流动,称为“文件流”
缓冲机制减少了直接访问外存的次数,提高效率
文件分类
文本文件(ASCII文件)
以ASCII码形式存储
可直接用文本编辑器查看
示例:.txt、.c、.h文件
二进制文件
以二进制形式存储
需要特定程序才能解析
示例:.exe、.jpg、.dat文件
文件标识
文件系统中:路径 + 文件名
Windows示例:
D:\edu\test.txtLinux示例:
/home/user/data.bin
C程序中:文件指针(FILE *类型)
FILE *fp; // 声明文件指针文件操作的基本步骤
- 打开文件:建立程序与文件的连接
- 文件处理/读写文件:读写操作
- 关闭文件:释放资源
文件打开与关闭
fopen()
说明:打开文件 函数原型:
#include <stdio.h>
FILE *fopen(const char *path, const char *mode);参数详解:
path:文件路径(绝对路径或相对路径)mode:打开模式基本模式(ASCII模式):
r以只读方式打开文件,文件指针指向文件起始位置。
r+以读写方式打开文件,文件指针指向文件起始位置。w以写的方式打开文件,如果文件存在则清空,不存在就创建,文件指针指向文件起始位置。w+以读写方式打开文件,如果文件不存在则创建,否则清空,文件指针指向文件起始位置。a以追加方式打开文件,如果文件不存在则创建,文件指针指向文件末尾位置。a+以读和追加方式打开文件,如果文件不存在则创建,如果读文件则文件指针指向文件起始位置,如果追加(写)则文件指针指向文件末尾位置。
二进制模式:
rb、wb、ab等,其实就是基本模式的前提下,加b
特殊模式:
x:独占模式(与w组合,文件必须不存在) 返回值:
成功:返回文件指针(指向FILE结构体)
失败:返回NULL(需要检查errno) 错误处理示例:
FILE *fp = fopen("data.txt","r");
if(fp == NULL)
{perror("文件打开失败!");// 退出进程exit(EXIT_FAILURE); // exit(1) 程序失败退出
}fclose()
说明:关闭文件 函数原型:
#include <stdio.h>
int fclose(FILE *fp);参数
fputc()
说明:单字符的写出 函数原型:
fp(文件指针):指向要关闭的FILE对象的指针,通常由fopen()或类似函数返回。 返回值成功:返回
0(即EXIT_SUCCESS)。失败:返回
EOF(通常是-1),并设置errno指示错误原因(如磁盘已满、文件被占用等)。 注意事项:必须关闭所有打开的文件
程序退出时未关闭的文件可能丢失数据
多次关闭同一文件指针会导致未定义行为 完整示例:
#include <stdio.h> #include <stdlib.h> int main(int argc, char **argv) {// 打开文件FILE *fp = fopen("texst.txt","w");if (!fp){perror("打开文件失败!");return -1; // exit(1);}// 读写文件// 关闭文件if(fclose(fp) != 0){perror("关闭文件失败!");return -1;}return 0; }文件顺序读写
单字符读写
fgetc()
说明:单字符的读取 函数原型:
int fgetc(FILE *fp);参数说明:
fp:待操作的文件指针 返回值:成功:返回字符的ASCII码
失败:或者文件末尾返回EOF(-1)
fputc()
说明:单字符的写出 函数原型:
int fputc(int c, FILE *fp);参数说明:
c:待写出的字符的ASCII码fp:待操作的文件指针 返回值:成功:返回写入的字符的ASCII码
失败:返回EOF(-1)
案例:文件拷贝(字符版)
#include <stdio.h>
int main(int argc,char *argv[])
{if (argc != 3){printf("用法:%s 源文件 目标文件\n", argv[0]);return -1;}// 打开代操做的文件FILE *src = fopen(argv[1],"r");FILE *dest = fopen(argv[2],"w");// 非空校验if (!src || !dest){perror("文件打开失败!");return -1;}// 读写文件int ch;while((ch = fgetc(src)) != EOF) // 循环读取 EOF:-1 返回-1,表示读取结束{// 循环的写入fputc(ch, dest);}// 给文件末尾添加换行fputc('\n', dest);// 关闭文件fclose(src);fclose(dest);return 0;
}行读写(多字符读写)
fgets()
说明:读取字符串(字符数组) 函数原型:
#include <stdio.h>
char* fgets(char *buf, int size, FILE *fp);功能描述: 从指定的文件流(fp)中读取一行字符串(以 \n 结尾),并将其存储到缓冲区 buf 中。
读取的字符数最多为
size - 1(保留一个位置给\0)。如果遇到 换行符
\n或 文件结束符EOF,则停止读取。读取的字符串末尾会自动添加
\0(空字符),使其成为合法的 C 字符串。 参数:buf(缓冲区):用于存储读取数据的字符数组(必须足够大)。size(最大读取长度):最多读取size - 1个字符(防止缓冲区溢出)。fp(文件指针):要读取的文件流(如stdin、fopen()返回的指针等)。 返回值成功:返回
buf的指针(即读取的字符串)。失败或到达文件末尾(EOF):返回
NULL。
fputs()
说明:写入字符串 函数原型:
int fputs(const char *str, FILE *fp);功能描述: 将字符串 str 写入到指定的文件流 fp 中。
不自动添加换行符:与
puts()不同,fputs不会在末尾自动添加\n。遇到
\0停止:写入过程遇到字符串结束符\0时终止(\0本身不会被写入)。 参数:str:要写入的字符串(必须以\0结尾)。fp:目标文件流(如stdout、文件指针等)。 返回值:成功:返回一个非负整数(通常是
0或写入的字符数)。失败:返回
EOF(-1),并设置errno指示错误原因(如磁盘已满、文件不可写等)。
案例:文件拷贝(行处理)
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define MAX_LEN 256
int main(int argc,char *argv[])
{if (argc != 3){printf("用法:%s 源文件 目标文件\n", argv[0]);return -1;}// 打开文件FILE *src = fopen(argv[1],"r");FILE *dest = fopen(argv[2],"w")