随机森林算法详解:从集成学习原理到代码实现
随机森林(Random Forest)是机器学习中最强大且应用广泛的算法之一,它结合了多个决策树的预测能力,在分类和回归任务中都表现出色。本文将深入解析随机森林的工作原理,解释其背后的集成学习数学依据,并提供完整的 Python 实现示例。
集成学习:随机森林的理论基础
随机森林属于集成学习(Ensemble Learning)的一种,其核心思想是 "三个臭皮匠赛过诸葛亮"—— 通过组合多个弱学习器(通常是决策树)的预测结果,获得比单个强学习器更好的性能。
集成学习的数学依据
假设有n个独立的分类器,每个分类器的错误率为p(\(p < 0.5\),即分类器性能略好于随机猜测)。根据大数定律,当使用简单多数投票时,集成分类器的错误率P可以用二项分布表示:
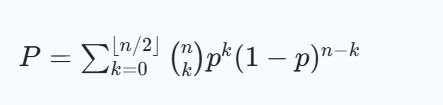
随着n增大,这个错误率会指数级下降并趋近于 0。这就是集成学习能够提高性能的理论基础。
随机森林的两大随机性
随机森林通过引入两种随机性来保证基学习器之间的独立性:
- 样本随机性:每个决策树都基于训练集的 bootstrap 抽样(有放回抽样)构建,每个决策树不会学习到全部数据,因为部分数据不具有代表性,会影响测试结果,为了取核心关键数据,每个决策树都不会完全训练。
- 特征随机性:每个决策树在分裂节点时,仅从随机选择的特征子集里挑选最优分裂特征
这两种随机性使得森林中的决策树具有足够的多样性,从而保证了集成效果。
随机森林的工作流程
随机森林的构建过程可以概括为以下步骤:
- 从原始训练集中通过 bootstrap 抽样生成k个不同的子集
- 为每个子集构建一棵决策树:
- 树的每个节点仅考虑随机选择的特征子集
- 不进行剪枝,让树充分生长
- 对于分类问题,通过多数投票确定最终预测结果;对于回归问题,则取所有树预测的平均值
随机森林的构建步骤
1. 数据采样:Bootstrap 抽样
- 从原始训练集(含 N 个样本)中有放回地随机抽取 N 个样本,形成一个新的训练子集
- 重复此过程 K 次,生成 K 个不同的训练子集(K 为森林中决策树的数量)
- 每个子集都会用来训练一棵独立的决策树
- 未被选中的样本(约 37%)组成 "袋外样本 (OOB)",可用于无额外验证集时的模型评估
2. 决策树构建:引入特征随机性
对每棵决策树,采用 CART 算法构建(默认不剪枝,让树充分生长):
- 在每个节点分裂时,不考虑所有特征,而是随机选择一部分特征(通常为总特征数的√N 或 log2N)
- 从选中的特征子集中,选择最优分裂点(通过 Gini 指数或信息增益等指标)
- 重复分裂过程,直到叶节点只包含同一类样本或达到预设深度
3. 集成预测
- 分类任务:所有决策树投票,得票最多的类别为最终预测结果
- 回归任务:所有决策树预测值的平均值作为最终结果
Python 实现:随机森林分类器
下面我们使用 scikit-learn 库实现一个随机森林分类器,并在经典的鸢尾花数据集上进行测试。
示例代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
from sklearn.tree import plot_tree
import seaborn as sns# 1. 加载数据集
iris = load_iris()
X = iris.data # 特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
y = iris.target # 标签:0, 1, 2 分别代表三种鸢尾花# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42
)# 3. 初始化并训练随机森林模型
# n_estimators: 树的数量
# max_features: 每棵树考虑的最大特征数
# random_state: 随机种子,保证结果可复现
rf_model = RandomForestClassifier(n_estimators=100,max_features='sqrt',random_state=42,n_jobs=-1 # 使用所有可用的CPU核心
)
rf_model.fit(X_train, y_train)# 4. 模型预测
y_pred = rf_model.predict(X_test)
y_pred_proba = rf_model.predict_proba(X_test) # 预测概率# 5. 模型评估
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=iris.target_names, yticklabels=iris.target_names)
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.title('随机森林分类混淆矩阵')
plt.show()# 6. 特征重要性分析
feature_importance = rf_model.feature_importances_
features = iris.feature_namesplt.figure(figsize=(10, 6))
sns.barplot(x=feature_importance, y=features)
plt.xlabel('特征重要性')
plt.ylabel('特征名称')
plt.title('随机森林特征重要性')
plt.show()# 7. 可视化森林中的一棵树(为了简洁只展示一棵树)
plt.figure(figsize=(15, 10))
plot_tree(rf_model.estimators_[0], feature_names=features, class_names=iris.target_names, filled=True, rounded=True)
plt.title('随机森林中的一棵决策树')
plt.show()
代码解析
上述代码实现了一个完整的随机森林分类流程,主要包含以下几个部分:
数据准备:使用 sklearn 内置的鸢尾花数据集,包含 4 个特征和 3 个类别
数据集划分:将数据分为 70% 的训练集和 30% 的测试集
模型训练:
n_estimators=100:创建包含 100 棵决策树的森林max_features='sqrt':每棵树考虑的特征数为总特征数的平方根n_jobs=-1:利用所有可用 CPU 加速训练
随机森林的优缺点
优点
- 性能优异,在许多任务上表现接近或超过 SVM 和神经网络
- 能处理高维数据,无需特征选择
- 不易过拟合,泛化能力强
- 可以输出特征重要性,便于模型解释
- 对缺失值和异常值不敏感
- 可以并行训练,效率高
缺点
- 在噪声较大的数据集上可能过拟合
- 对于某些高维稀疏数据(如文本),表现可能不如线性模型
- 模型结构复杂,单个决策树容易可视化,但整个森林难以直观解释