GPU 安装
参考原文https://www.lixueduan.com/posts/ai/01-how-to-use-gpu/
文章目录
- 什么是 cuda
- 服务器 GPU 驱动(ubuntu22.04)
- GPU 驱动安装
- 安装 CUDA Toolkit
- 容器中使用 GPU
- 驱动安装
- 配置使用该 runtime
- k8s使用 GPU(HAMI)
- 验证k8spod使用
什么是 cuda
CUDA 不是实物,它是 NVIDIA 推出的一套 “软件层面” 的并行计算平台和编程模型,由一系列软件工具、接口、编译器和运行时库组成,而非物理硬件(如芯片、显卡等实物)。
CUDA 是 NVIDIA 专属的计算平台,只有 NVIDIA 的 GPU 硬件(如 RTX 系列显卡、Tesla 计算卡等)内置了支持 CUDA 的物理核心(CUDA Core),其他品牌(如 AMD、Intel 的显卡)不支持 CUDA。
服务器 GPU 驱动(ubuntu22.04)
GPU 驱动安装
lspci|grep NVIDIA
没有点我去下驱动 gogogo
最终下载得到的是一个.run 文件,直接 sh 方式运行该文件即可
sh NVIDIA-Linux-x86_64-550.54.14.run
#接下来会进入图形化界面,一路选择 yes / ok 就好#运行以下命令检查是否安装成功
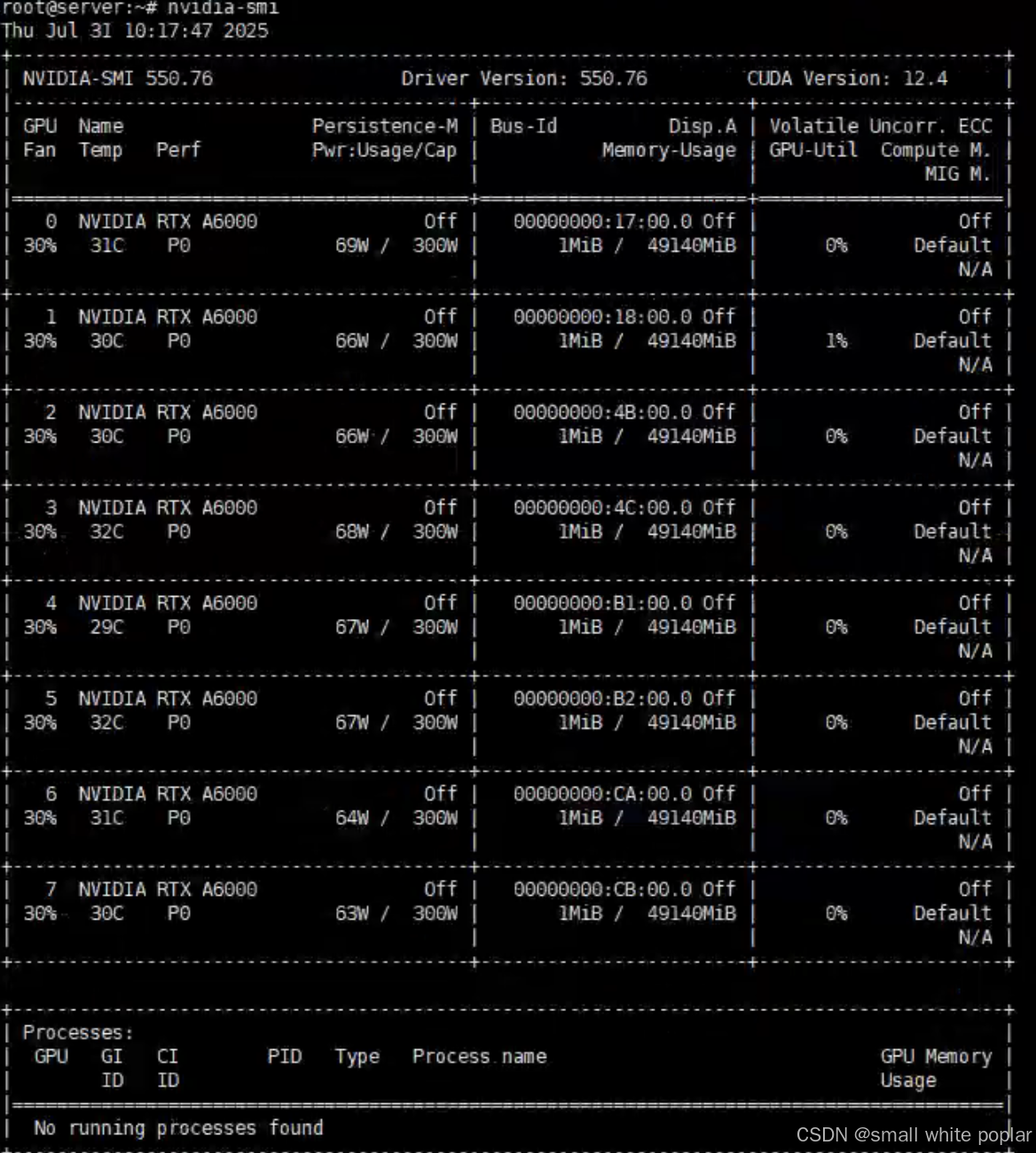
nvidia-smi
至此,我们就安装好 GPU 驱动了,系统也能正常识别到 GPU。
这里显示的 CUDA 版本表示当前驱动最大支持的 CUDA 版本。
安装 CUDA Toolkit
没有点我去下驱动 gogogo
选择我直接运行.run 文件
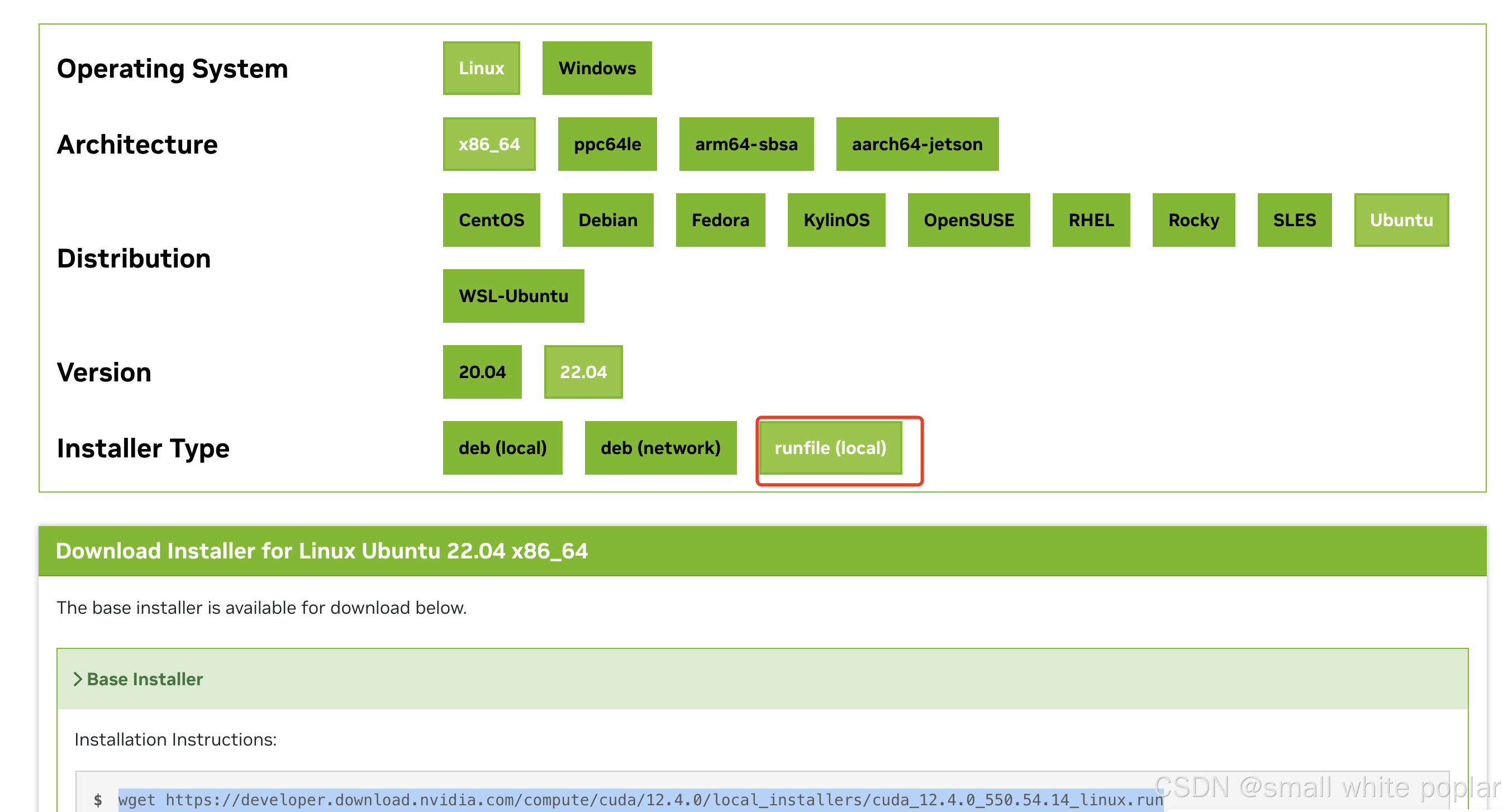
wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run
sh cuda_12.4.0_550.54.14_linux.run
#根据提示配置下 PATH
export PATH=/usr/local/cuda-12.4/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH#执行以下命令查看版本,确认安装成功
nvcc -V
我们已经在裸机上安装了 GPU Driver,CUDA Toolkit 等工具,实现了在宿主机上使用 GPU。
容器中使用 GPU
1.安装 nvidia-container-toolkit 组件
2.docker 配置使用 nvidia-runtime
3.启动容器时增加 --gpu 参数
驱动安装
Installing the NVIDIA Container Toolkit
没有点我去下驱动 gogogo
#配置生产存储库:curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
#(可选)配置存储库以使用实验包:sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
#从存储库更新软件包列表:sudo apt-get update
#安装 NVIDIA Container Toolkit 软件包:export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1sudo apt-get install -y \nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}配置使用该 runtime
支持 Docker, Containerd等
例如 RKE2 的 containerd
vi /etc/rancher/rke2/config.yaml.d/00-rbd.yaml
#追加以下内容
default-runtime: nvidia #指定 nvidia 为默认容器运行时systemctl restart rke2-agent.service
nerdctl run --rm --gpus all nvidia/cuda:12.0.1-runtime-ubuntu22.04 nvidia-smi
#正常情况下应该是可以打印出容器中的 GPU 信息即可
k8s使用 GPU(HAMI)
点我去看文档 gogogo
看他的离线安装文档和github的value去找以下镜像 给镜像加代理
cat >> value.yml << EOF
scheduler:kubeScheduler:image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.30.4extender:image: docker.cloud-sea.cloud/projecthami/hamipatch:image: docker.cloud-sea.cloud/jettech/kube-webhook-certgen:v1.5.2imageNew: docker.cloud-sea.cloud/liangjw/kube-webhook-certgen:v1.1.1devicePlugin:image: docker.cloud-sea.cloud/projecthami/hami:v2.6.0monitorImage: docker.cloud-sea.cloud/projecthami/hami:v2.6.0
EOF
helm install hami hami-charts/hami -n kube-system -f value.yml
kubectl get pod -n kube-system
到这再看谁没起来去改控制器加代理docker.cloud-sea.cloud直接拉镜像
验证k8spod使用
cat > cuda-sample.yaml << EOF
apiVersion: v1
kind: Pod
metadata: name: cuda-vectoradd
spec: restartPolicy: OnFailure containers: - name: cuda-vectoradd image: registry.cn-hangzhou.aliyuncs.com/zqqq/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04 resources: limits: nvidia.com/gpu: 1 # 声明使用1张GPU
EOF