【YOLO学习笔记】YOLOv1详解
论文名称:《You Only Look Once: Unified, Real-Time Object Detection》,Axure 流程图
参考视频讲解:【精读AI论文】YOLO V1目标检测,看我就够了
关键词:(1)unified(2)one-stage (3)end-to-end
创新点:一个模型就能处理 目标检测任务中的两个子任务
- object 的 bound box 的位置信息
- bbox对应的类别信息

文章目录
- 一、推理阶段
- 1. 预处理
- 2. 网络结构
- 3. 网络输出详解
- 7x7
- 30
- 4. 后处理
- 二、训练阶段
- 1. 图片预处理
- 2. 标签预处理与标签编码
- 3. 损失函数
- 公式
- 符号说明:
- 举例说明
- 如何判断哪个bbox负责预测物体
- 为啥bbox大小位置误差加开根号
一、推理阶段
就是测试、预测、推理、前向传播阶段,这个阶段就是用训练好的模型对一张图片进行运算得出结果。
1. 预处理
- 对于任意尺寸的图片resize到固定尺寸448x448,因为网络有展平层和全连接层,resize处理后图片会有些变形。
- 零均值化:RGB三个通道分别所有像素值减去该通道的像素均值
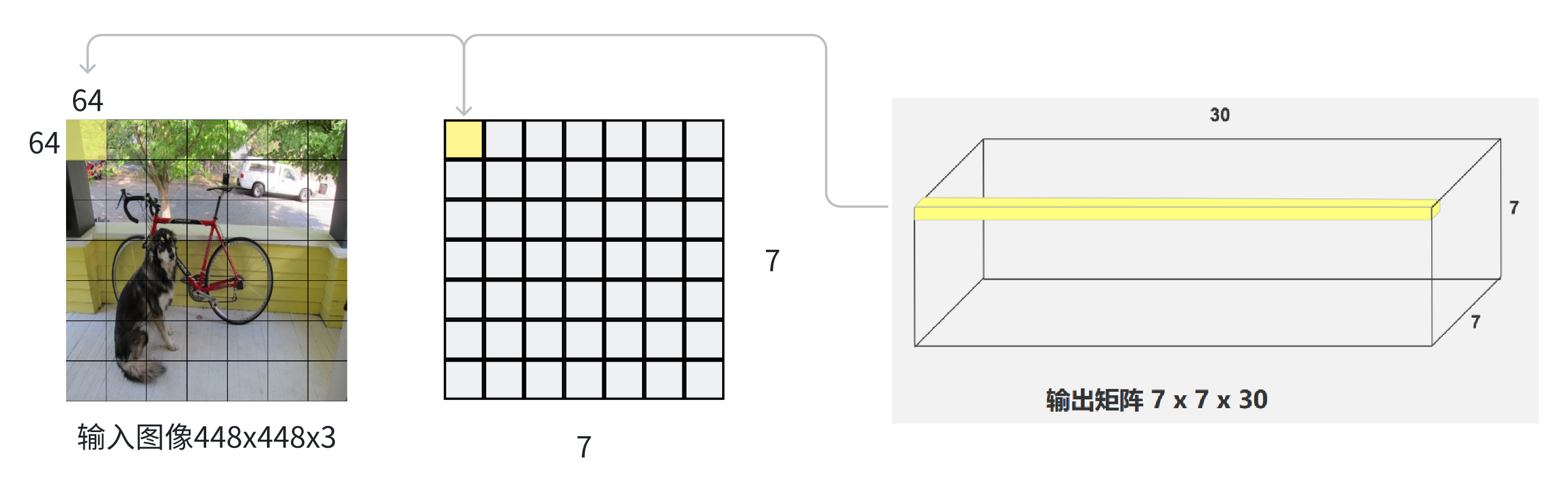
2. 网络结构
- 如图,对于输入的图片经过一些列卷积和池化得到
7x7x1024的张量。 - 再展平,经过两层全连接层得到1470维向量。
- 再reshape成一个
7x7x30的张量。这个张量就是神经网络的最终输出,里面包含了全部的预测结果信息。


3. 网络输出详解
网络的输出是一个7x7x30的张量。
7x7
这个柱体的横切面为7x7的正方形网格,正好对应原图切成的7x7的网格,每一个网格称作Grid cell,每一个grid cell像素尺寸为64x64。
所以7x7x30的张量可以看做事49个30维度向量,每一个向量的30个数的信息,对应原图的一个grid cell所预测出的信息。
30
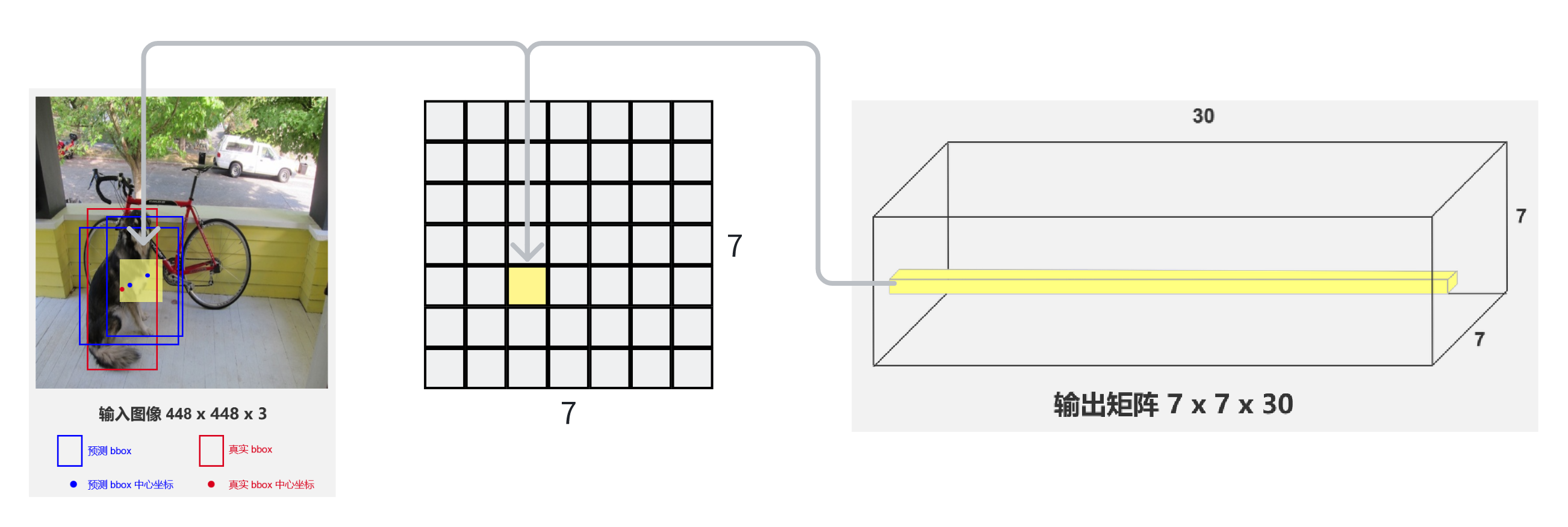
- 真实标签(ground truth)的bbox中心点落在哪个grid cell,这个gril cell就负责预测这个物体。比如图中这个狗的红色框的中心点落在了黄色grid cell中。
- 每个grid cell,只能预测出两个bbox预测框,且两个框的中心点在grid cell中。如图中两个蓝色框
- 同一个grid cell预测出的两个bbox共用一个类别条件概率
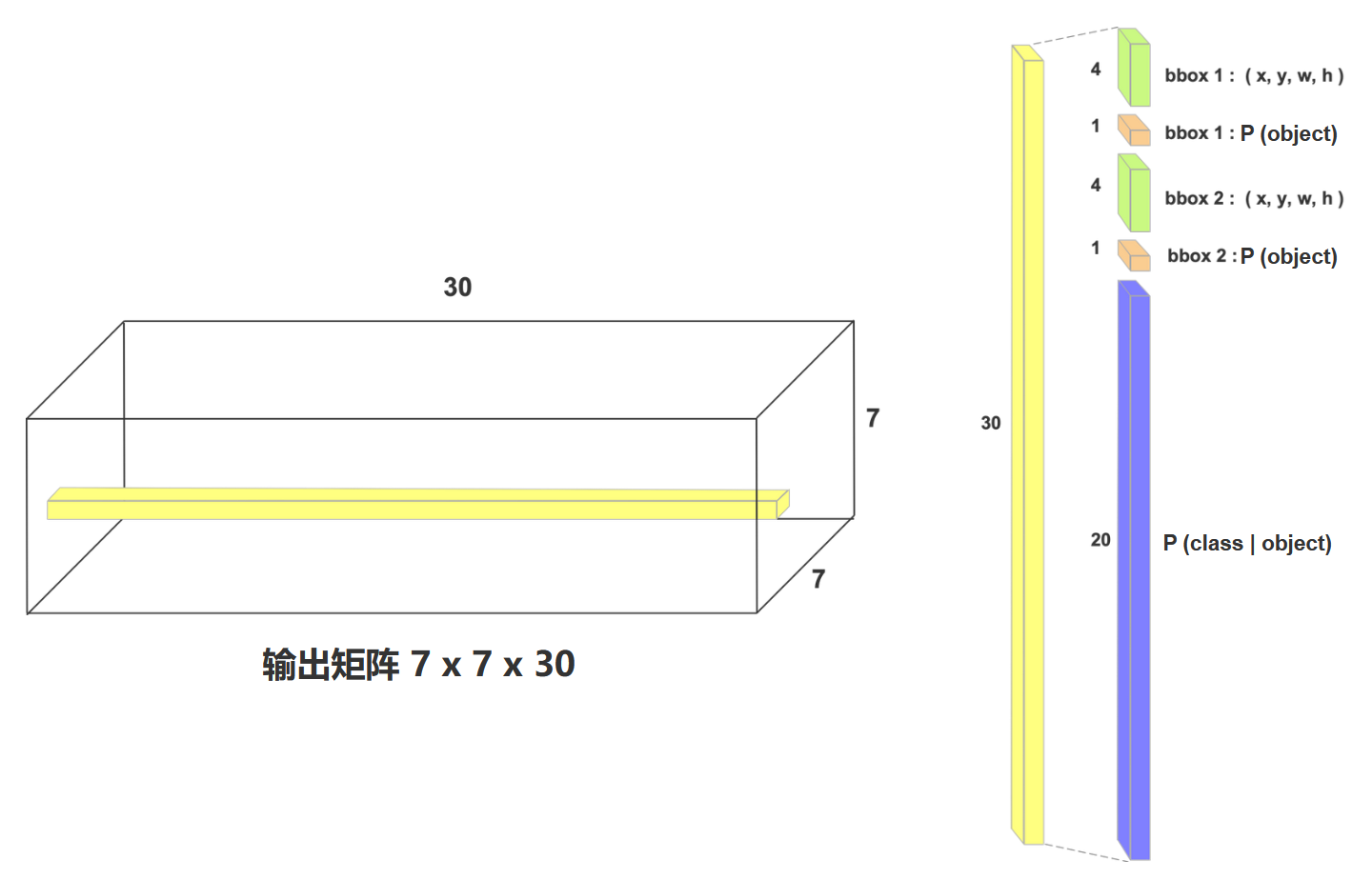
对于每一个30维向量,就是一个长度为30的数字列表。 - 前5个值表示第一个bbox的中心点坐标(x, y),宽高(w, h),含有待检测物体的置信度概率P(不含有是哪个类别)
- 第二个5个值表示第二个bbox的五个信息
- 后20个值,表示这个gird cell预测出的两个框,在已知有物体的条件下,分别对于20个类别的条件概率分别是多少。
![[图片]](https://i-blog.csdnimg.cn/direct/fd89ef47fa374dda8751807a6d9c0b94.png#pic_center)
对于bbox的(x, y, w, h ,p)的具体含义:

这5个值的范围都是0到1的,因为在网络再经过全连接层并resize得到7x7x30的张量,又进行了torch.sigmoid(x)的归一化操作。
- (x, y):是相对于grid cell左上角坐标的相对坐标。例如如果bbox中心点在grid cell右下角的像素位置,那就是(1,1)
- (w, h):相对于原图大小448x448的大小
- p:条件概率
4. 后处理
这个7x7x30的张量就已经是神经网络的输出,但还需要一下非深度学习的死算法进行后处理。针对一共预测出来的7x7x2=98个框,再做以下三轮筛选:
- 先根据目标存在概率(
P(object)),设定一个阈值threshold1(比如0.1),如果大于阈值就保留框。得到 从98个框筛选到20个左右,记录在contain_index(符合条件的框索引)、contain_prob(对应存在概率 ) - for循环遍历筛出来的框,
- 找每个框类别概率最大的类别,并记录索引值(
class_index、class_prob),作为预测的bbox的类别结果 - 算综合概率
probs = contain_prob * class_prob,即P(是否包含物体)乘P(是类别的概率|有物体) - 再用 第二个阈值
threshold2对probs概率值进行二次筛选,记录符合条件的框坐标、类别索引、综合概率probs。剩下10个左右bbox。
- 找每个框类别概率最大的类别,并记录索引值(
- 最后用非极大值抑制(
NMS)进一步筛选,去除重叠冗余框 ,属于目标检测模型输出处理(如 YOLO 等算法后处理环节 )的典型逻辑 。
二、训练阶段
1. 图片预处理
和推理阶段的预处理有所不同,加上了一些数据增强的步骤。
- 水平翻转
- 尺度调整,对宽度进行缩放
- 颜色增强(随机调整:色调,饱和度,亮度)
- 平移裁剪
- resize到448x448
2. 标签预处理与标签编码

由于数据增强,所以对图像有一些变换(翻转,resize等等),对应的标签(ground truth)的框的信息也变了,类别信息不变。所以在增强图片同时,也对标签进行预处理。
标签编码:为了损失函数计算更方便,将训练用的没一张图片的标签值同样编码为7x7x30的张量,也就是网络输出的数据结构。
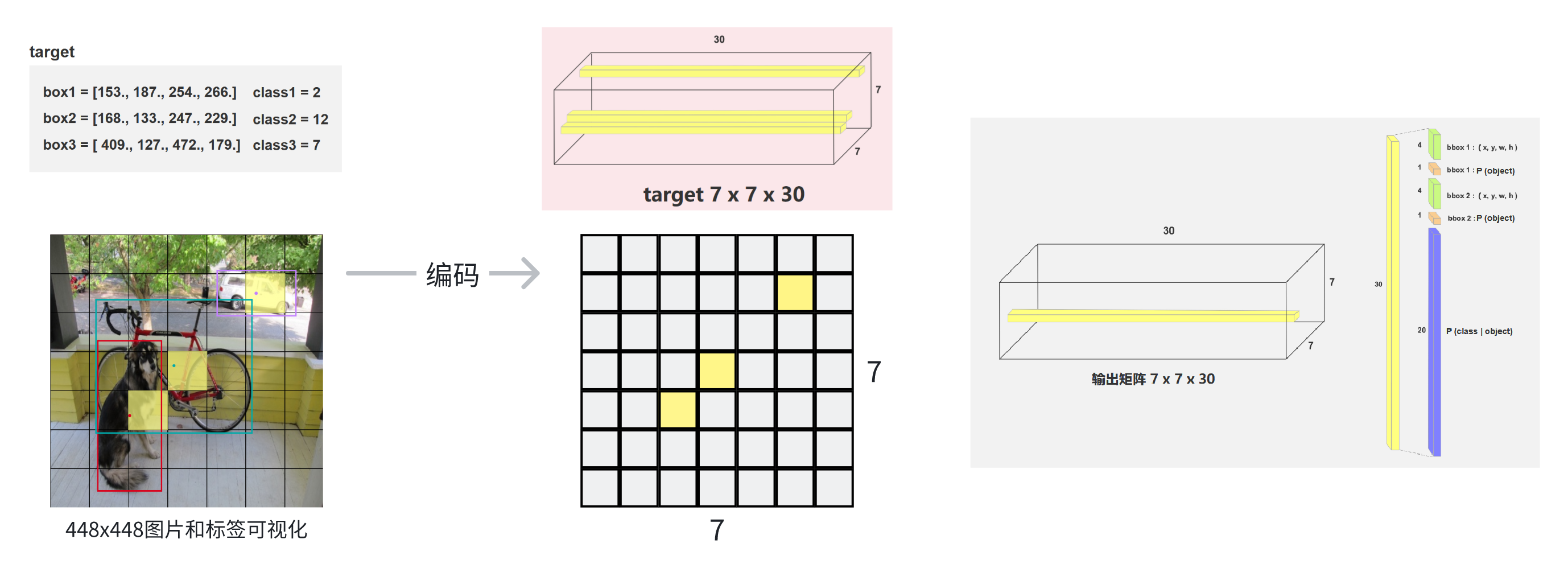
步骤:计算根据标签的框的信息进行处理,填入7x7x30张量的对应位置。
-
bbox位置大小:(xmin, ymin, xmax, ymax)(Pascal VOC 数据集的bbox标注格式,bbox左上角和右下角的绝对坐标),计算出中心点所在的grid cell,再计算出相对坐标和相对宽高(x, y, w, h)。再将这个值填入对应grid cell的向量的两个bbox的位置(如图同绿色的8个位置)。 -
P(object) = 1,如图中橘色的两个位置的值。 -
class对应的类别值为 1,其他类别值为 0 -
其他不包含物体的向量,全是0。如图中灰色。

3. 损失函数
公式
对于经过前向传播得到的输出7x7x30的张量,和标签编码后得到的7x7x30的张量可以计算损失值。

分为三大部分:
-
定位损失:中心点误差+宽高误差。注意数学公式表达中,前两个式子可以合并在用中括号。
-
含物体的置信度损失:负责检测物体的bbox+不负责检测物体的bbox。前向传播得到的不是CiC_iCi,而是计算相对于ground truth框的IoU得到CiC_iCi。标签值Ci=0or1C_i=0 or 1Ci=0or1
-
类别损失:负责检查物体的grid cell的类别损失
所有的损失都用的是误差平方和。
符号说明:
下标:
- iii:第 iii 个 grid cell,共49个 grid cel,iii取值0到48
- jjj:第 jjj 个 bbox,每个 grid cell 有2个 bbox ,jjj取值0到1
二元变量(0-1变量):
-
1i,jobj=0\mathbb{1}_{i,j}^{\text{obj}} = 01i,jobj=0 第 iii 个 grid cell 的第 jjj 个 bbox 负责检测 object
1i,jobj=1\mathbb{1}_{i,j}^{\text{obj}} = 11i,jobj=1 第 iii 个 grid cell 的第 jjj 个 bbox 不负责检测 object -
1i,jnoobj=0\mathbb{1}_{i,j}^{\text{noobj}} = 01i,jnoobj=0 第 iii 个 grid cell 的第 jjj 个 bbox 不负责检测 object
1i,jnoobj=1\mathbb{1}_{i,j}^{\text{noobj}} = 11i,jnoobj=1 第 iii 个 grid cell 的第 jjj 个 bbox 负责检测 object注意:1i,jobj\mathbb{1}_{i,j}^{\text{obj}}1i,jobj和1i,jnoobj\mathbb{1}_{i,j}^{\text{noobj}}1i,jnoobj对立,也就是必定一个时0,另一个是1
-
1iobj=0\mathbb{1}_{i}^{\text{obj}} = 01iobj=0 第 iii 个 grid cell 负责检测 object
1iobj=1\mathbb{1}_{i}^{\text{obj}} = 11iobj=1 第 iii 个 grid cell 不负责检测 object
权重:
- λcoord=5\lambda_{\text{coord}} = 5λcoord=5
- λnoobj=0.5\lambda_{\text{noobj}} = 0.5λnoobj=0.5
因为计算定位损失仅用到了几个(比如三个)负责检测物体的bbox,而计算置信度损失还用到的不负责检测物体bbox置信度。
为了防止不均衡,给定位损失加大权重,给不负责检测物体bbox的置信度损失调小权重。
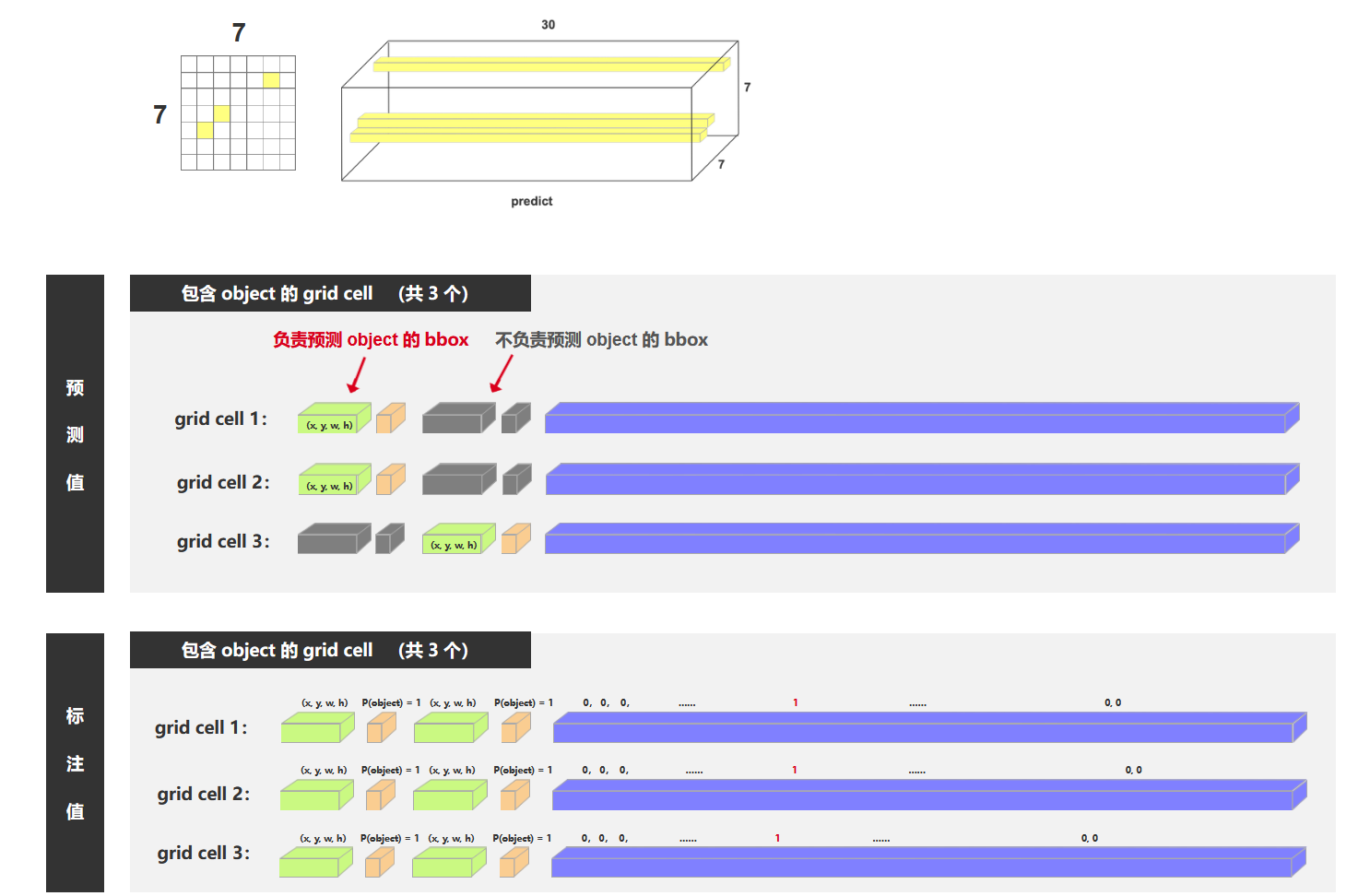
举例说明
负责预测物体的三个bbox对应的三个向量:
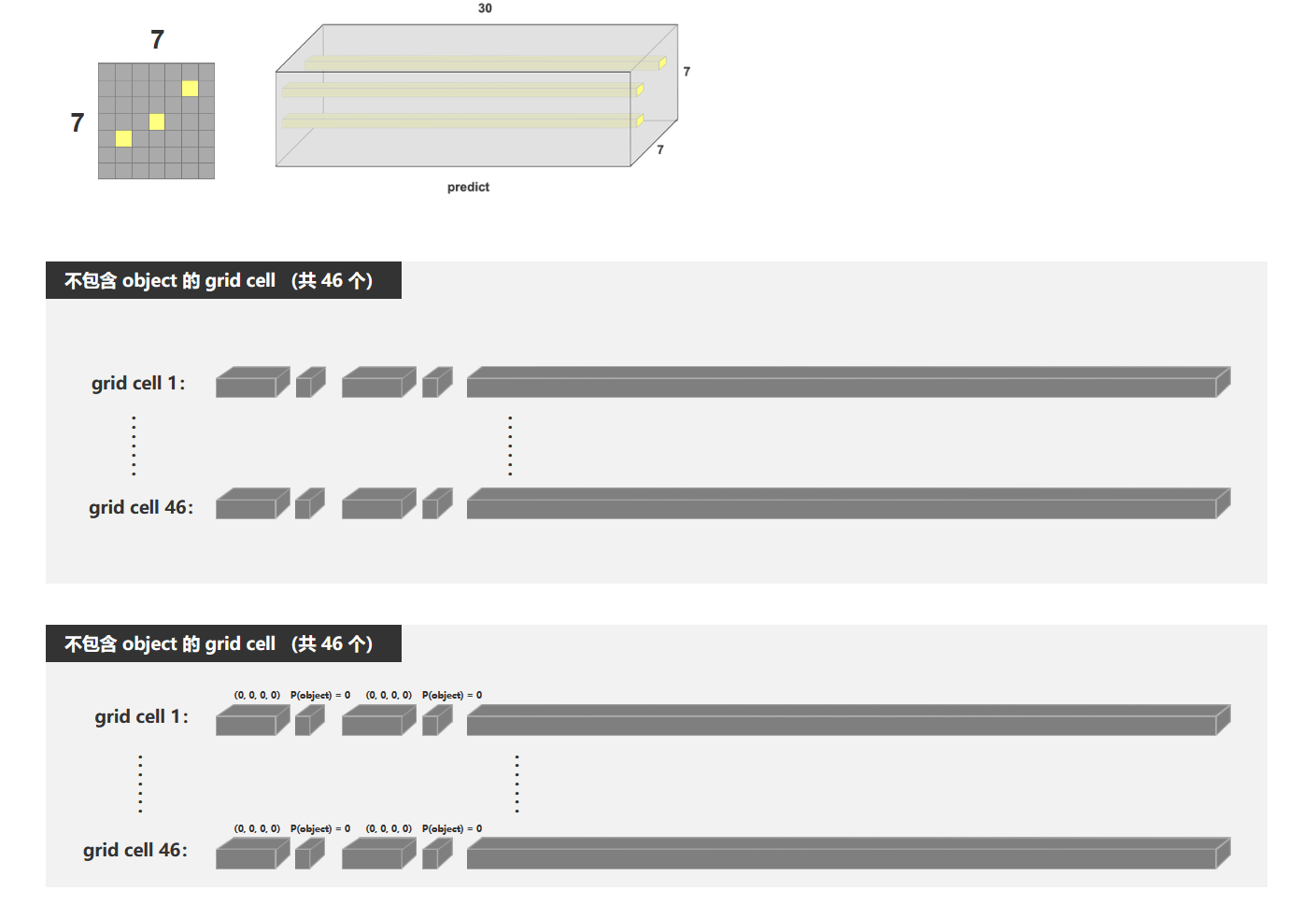
不负责检测物体的剩下的46个向量:
如何判断哪个bbox负责预测物体
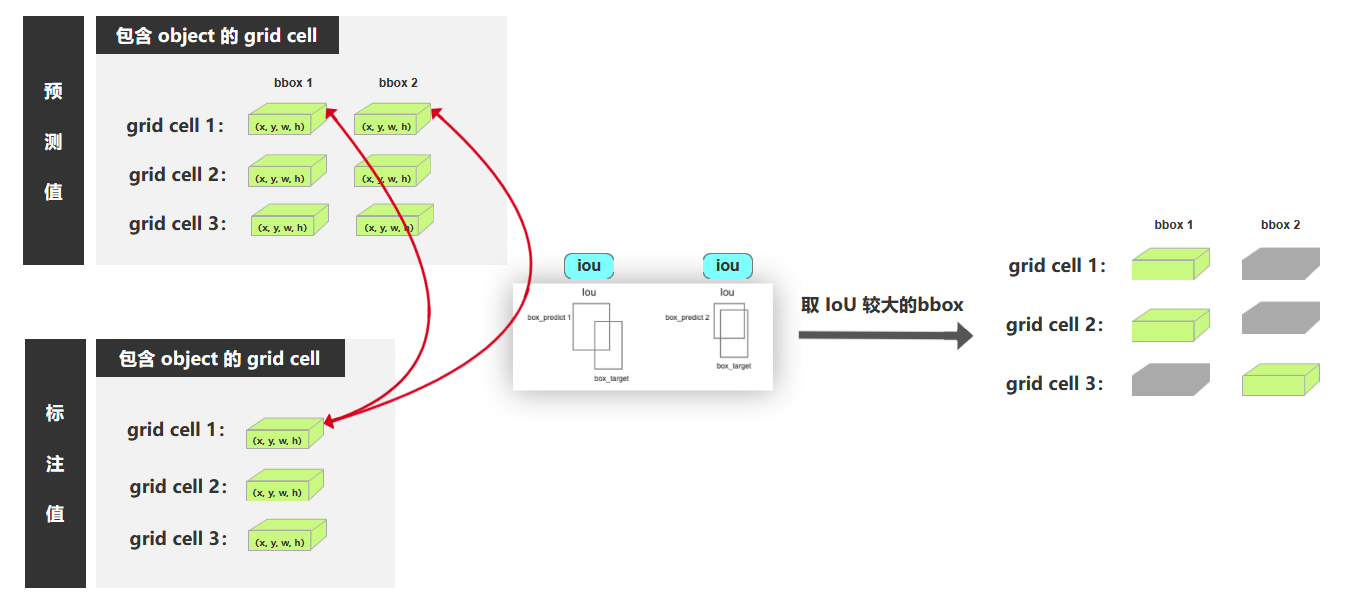
对于一个含有ground truth中心点的grid cell,经过前向传播得到的两个bbox。分别与ground truth标签bbox计算IoU。IoU较大的负责检测物体。
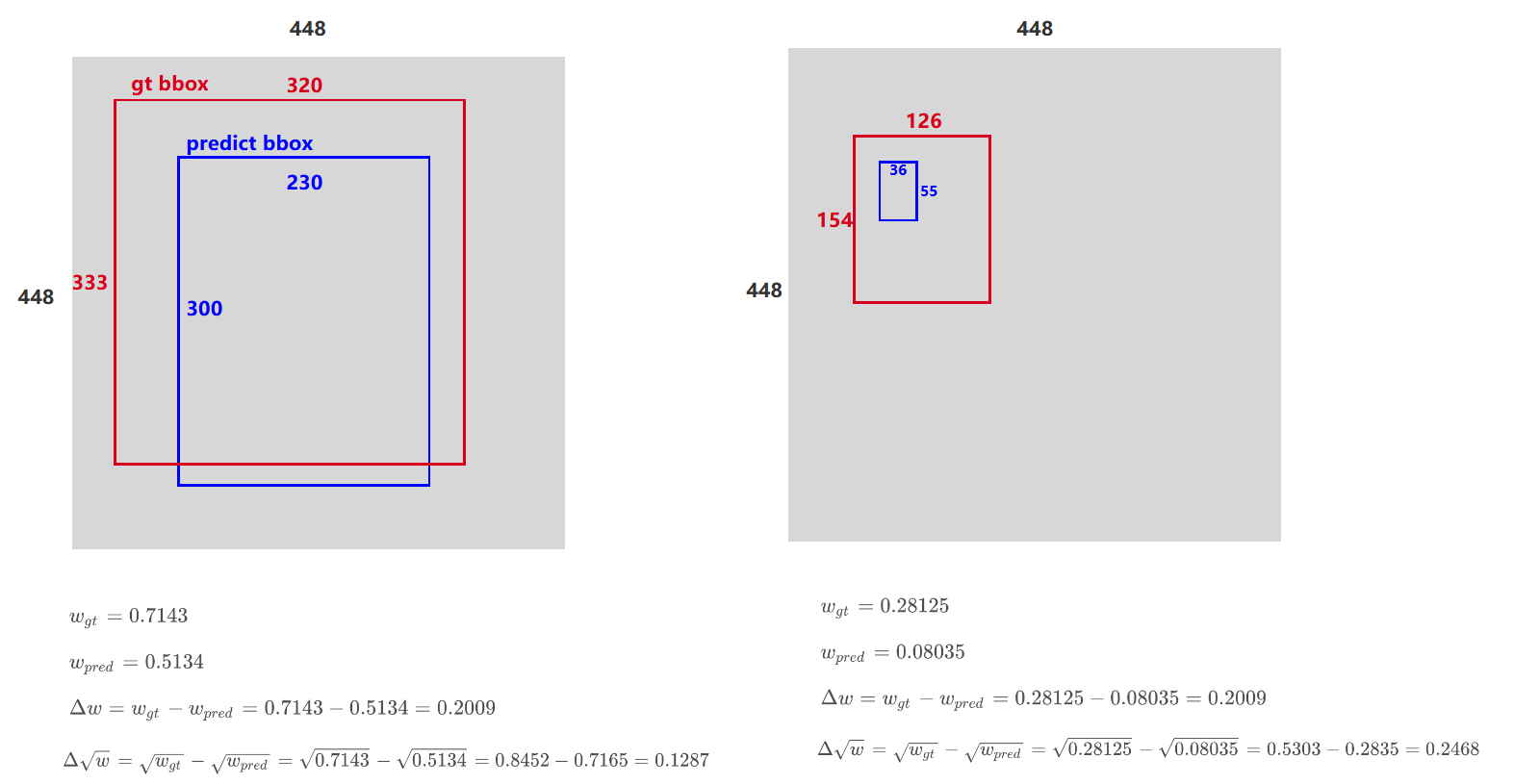
为啥bbox大小位置误差加开根号

举个例子,有两种大目标和小目标物体。在Δw\Delta wΔw一样的时候,肉眼感觉大目标误差不是很大,而小目标误差就更大一些,所以直接计算差值是不公平的。
所以开根号后,当值较大时,误差感知会小一些。放大了w较小时的损失结果。