Ollama入门实战
概述
官网,GitHub
Ollama,Ollama公司开发的工具,旨在让用户能够更容易地运行和部署LLMs(包括Llama和其他开源模型)。Ollama使得模型的部署、使用变得更加简单,且通常包括针对Llama等模型的封装与优化。
Ollama特点:
- 简化部署:Ollama提供简化的接口和工具,使开发者可以在本地快速部署和运行Llama等语言模型,而不需要处理底层的复杂性;
- 跨平台支持:Ollama提供跨平台的支持,包括Mac、Linux和Windows等;
- 一体化工具:Ollama还提供一系列工具,用于模型的调用、调试和性能优化,帮助用户轻松集成这些AI模型到他们的应用程序中。
安装
对于Windows,从官网下载exe文件,双击即可,非常简单。CMD打开命令行:
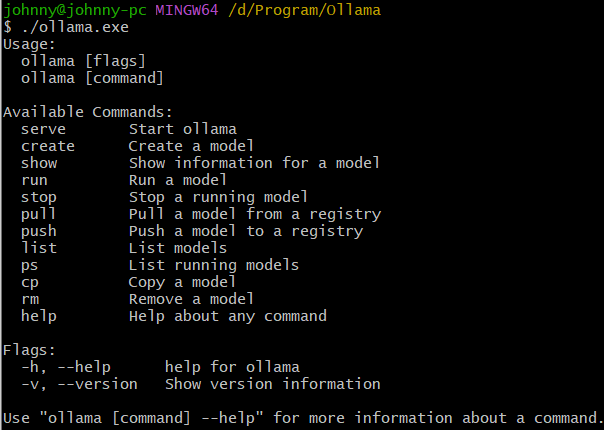
可用命令:
- serve:启动Ollama
- create:根据Modelfile创建模型
- show:显示模型信息
- run:运行模型
- stop:停止模型
- pull:从仓库(registry)拉取模型
- push:往仓库推送模型
- list:列举模型
- ps:类似于docker ps,查看运行中模型
- cp:复制模型
- rm:删除模型
- help:帮助文档
运行ollama serve报错:Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
分析:已成功启动Ollama,试图再次启动,发现端口被占用。
浏览器打开:http://127.0.0.1:11434
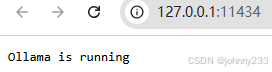
Open WebUI
早起版本的Ollama,没有UI界面,无法在浏览器里对话,只能在命令行窗口下对话。需借助于Open WebUI
安装Open WebUI
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui --restart always \
ghcr.io/open-webui/open-webui:main
打开 http://localhost:3000体验。
注:由于需要下载镜像,需要等几分钟。
新版
安装0.10版本,自带UI;本地未部署任何模型,选择模型后
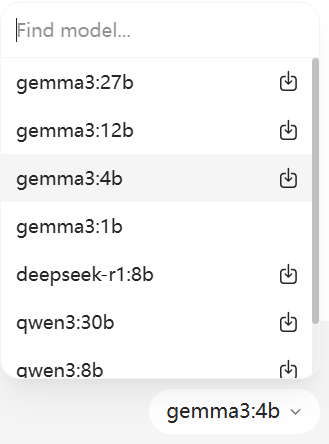
发起Query
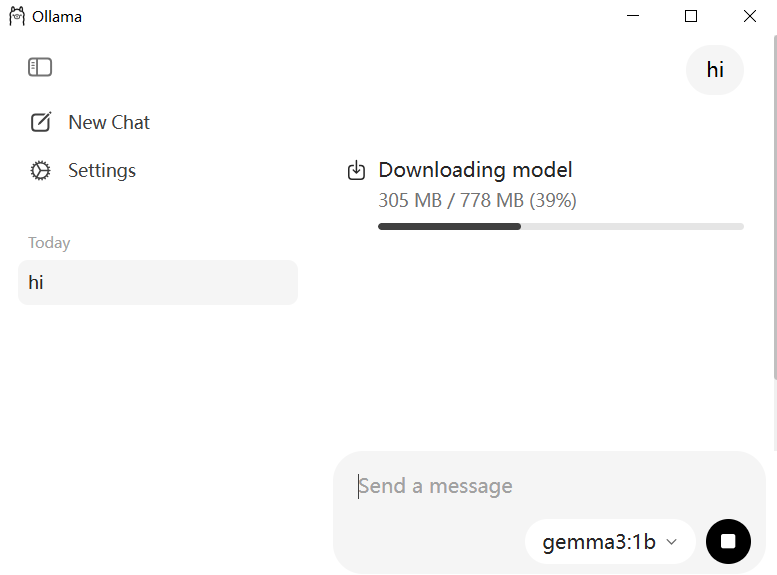
自动下载模型并启动,流畅得一批。
支持设置模型地址,为系统盘腾出空间

目录迁移
默认情况下,Ollama安装在C盘,且安装过程中(或完成后)没有提供修改配置的入口。
确保以管理员身份执行命令:mklink /D "C:\Users\johnn\AppData\Local\Programs\Ollama" "D:\Program\Ollama"。
出现如下报错时:

检查:
- 目录是否输入正确
- 是否已经将源文件夹彻底移动到目标文件夹,并确保源文件夹不再存在。
命令行
上面截图中,聊天窗口右下角只有有限的几个模型待选择:
如果想下载更多模型,怎么知道拼写是否正确?
打开模型库
$ ./ollama.exe list
$ ./ollama.exe show 8648f39daa8f
Error: model '8648f39daa8f' not found
$ ./ollama.exe show gemma3:1b
$ ./ollama.exe stop gemma3:1b
$ ./ollama.exe run gemma3:1b
$ ./ollama.exe ps
$ ./ollama.exe pull deepseek-r1:1.5b
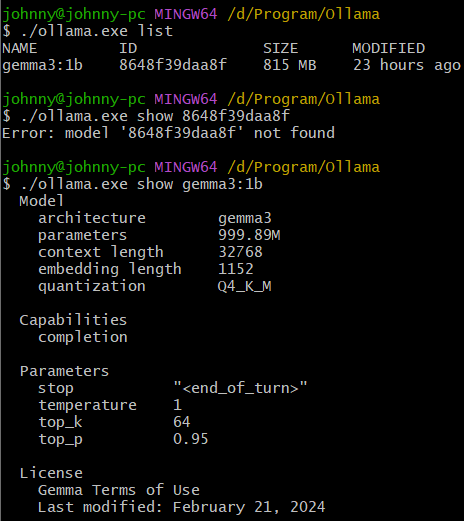
./ollama.exe show展示:
- 模型架构、参数量、上下文长度、词嵌入长度、量化策略、能力(对话)、许可;
- 参数:停止字符、温度、topK、topP。


网络
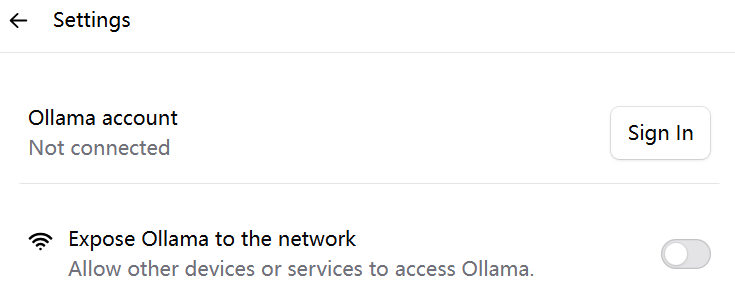
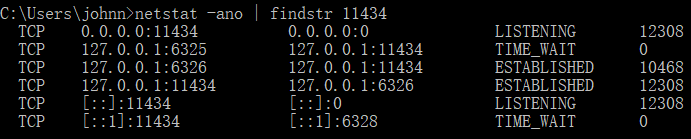
Ollama默认没有开启暴露网络时,netstat命令看到Ollama监听在localhost:11434,只能本机访问:

开启暴露Ollama到网络后,Ollama监听在*:11434,则可局域网访问;如果Ollama运行在公网,就能公网访问。
环境变量
| 变量 | 描述 | 默认值 |
|---|---|---|
| OLLAMA_HOST | 设置网络监听端口。设置为0.0.0.0时,可让任意人外部网络访问 | |
| OLLAMA_PORT | 设置端口 | 11434 |
| OLLAMA_MODELS | 设置模型存储路径 | |
| OLLAMA_KEEP_ALIVE | 模型内存存活时间 | |
| OLLAMA_NUM_PARALLEL | 设置Ollama可同时加载的模型数量 | |
| OLLAMA_MAX_LOADED_MODELS | 可以确保系统资源得到合理分配 |
多模态引擎
Ollama此前主要依赖ggml/llama.cpp项目,专注于易用性和模型可移植性。但随着多模态模型的涌现,原有的架构在支持这些复杂模型时遇到挑战。推出全新多模态引擎,旨在:
- 提升可靠性和准确性:通过模型模块化设计,每个模型都相对独立,减少相互干扰,简化模型集成。新引擎能更准确地处理大图像产生的token,并优化图像的批处理和位置信息。
- 优化内存管理:引入图像缓存机制,并与硬件制造商合作优化内存预估和使用,针对不同模型的特性(如Gemma3的滑动窗口注意力和Llama4的分块注意力)进行KV缓存优化,从而在相同硬件上实现更长的上下文或更高的并发。
- 为未来奠定基础:为未来支持语音、图像生成、视频生成、更长上下文以及更完善的工具支持打下坚实基础。
正式支持视觉模型:
- Meta Llama 4:1090亿参数的MoE Llama 4 Scout,能够对视频帧进行细致分析,甚至回答基于地理位置的问题。
- Google Gemma 3:处理多张图片并理解它们之间关系的能力。
- Qwen 2.5 VL:强大的文档扫描和字符识别能力,例如准确识别支票上的文字信息,甚至能理解并翻译垂直书写的中文春联。
- Mistral Small 3.1
工具调用
Tool Calling,支持流式响应,当模型需要调用外部工具来回答问题时,不必等工具完全执行完毕并返回所有结果后才开始响应。现在,模型可以一边调用工具,一边实时地将已经生成的内容流式地推送给你,同时在适当的时候插入工具调用的指令。
支持此功能的模型包括Qwen3,Devstral,Llama 3.1,Llama 4等。
Ollama开发一个新的增量解析器,不再是简单地等待完整的JSON输出,而是能够:
- 理解模型模板:直接参考模型模板来识别工具调用的前缀。
- 智能处理:即使模型没有严格按照预设的工具调用格式输出,解析器也能处理部分前缀或回退到解析JSON,从而准确分离内容和工具调用。
- 提高准确性:避免之前可能因为模型在回复中引用先前工具调用而导致的重复调用问题。
用户可通过cURL、Python或JS库轻松使用这一功能。模型上下文协议(MCP)对此功能的助益,并建议使用32k或更高的上下文窗口以提升工具调用的性能和结果。
Thinking
推理(或思考)模式,允许AI模型在给出最终答案之前,先展示其内部的推理过程。提供开关,支持开启和禁用;支持此功能的模型包括DeepSeek R1,Qwen3等。
使用:
- CLI:可通过
--think或--think=false参数控制。在交互式会话中,可使用/set think或/set nothink。--hidethinking参数,用于在启用思考但只显示最终答案的场景; - API:
/api/generate和/api/chat接口新增think参数:true/false; - Python/JS库:支持在调用时传递
think参数。
结构化输出
Ollama结合使用高级语言模型和Pydantic等模式验证框架,无缝地提供结构化输出。使用Pydantic等工具定义输出的预期结构,将这些结构传递给聊天API,AI会被提示生成符合指定模式的内容。
优势:
- 一致性:确保输出可预测和机器可读的。
- 验证:任何与定义结构的偏差都会被标记,从而减少下游流程中的错误。
- 灵活性:开发人员可以为各种用例定义模式,从简单的数据结构到复杂的嵌套输出。
通过将基于模式的验证直接集成到生成过程中,Ollama最大限度地减少数据清理所需的工作量,并确保根据需求定制可靠的结果。
示例:
from ollama import chat
from pydantic import BaseModel
from typing_extensions import List, Literal, Optional# Define the schema for structured output
class Object(BaseModel):name: strconfidence: floatattributes: strclass ImageDescription(BaseModel):summary: strobjects: List[Object]scene: strcolors: List[str]time_of_day: Literal['Morning', 'Afternoon', 'Evening', 'Night']setting: Literal['Indoor', 'Outdoor', 'Unknown']text_content: Optional[str] = Nonepath = 'image.png'
# Call Ollama's chat function with a schema
response = chat(model='llama3.2-vision',format=ImageDescription.model_json_schema(), # Pass the schemamessages=[{'role': 'user','content': 'Analyze this image and describe what you see, including any objects, the scene, colors, and any text you can detect.','images': [path],},],options={'temperature': 0}, # Set temperature to 0 for deterministic output
)
# Validate and parse the response into the schema
image_description = ImageDescription.model_validate_json(response.message.content)
print(image_description)
解读:基于Llama视觉模型(Llama3.2-vision)分析图像并根据预定义的架构生成结构化描述。
拓展
Gollama
GitHub,一个管理Ollama模型的工具,提供一个TUI(文本用户界面)用于列出、检查、删除、复制和推送Ollama模型,以及可选地将它们链接到LM Studio。允许用户使用热键以交互方式选择模型、排序、过滤、编辑、运行、卸载并对其执行操作。
简单类比,Gollama之于Ollama,k9s之于k8s。
功能:
- 列出可用模型、运行中模型
- 模型操作:排序(按名称、大小、修改日期、量化级别、系列等)、选择、查看元数据、复制、重命名、删除、运行、卸载
- 编辑/更新模型的模型文件
- 将模型链接到LM Studio
- 将模型推送到注册表
命令行模式:
-l:列出所有可用模型并退出-L:将所有可用的模型链接到LM Studio并退出-s <search term>:按名称搜索模型OR('term1|term2'):返回与任一术语匹配的模型AND('term1&term2'):返回同时匹配两个术语的模型-e <model>:编辑模型文件,新建模型-ollama-dir:自定义模型目录-lm-dir:自定义LM Studio模型目录-cleanup:删除所有符号链接模型和空目录并退出-no-cleanup:不要清理损坏的符号链接-u:卸载所有正在运行的模型-v:打印版本并退出
Hollama
GitHub,轻量级WebUI,定位等同于Open WebUI。
特点
- 大型提示字段
- 带语法高亮的Markdown渲染
- 代码编辑器功能
- 可自定义的系统提示
- 复制代码片段、消息或整个会话
- 编辑并重试消息
- 将数据存储在浏览器本地
- 响应式布局
- 明暗主题
- 直接从UI下载Ollama模型