大模型学习--第一天
1、大模型问答原理
主要分为几个步骤:
首先大模型需要接收用户的问题或者prompt;第二步,大模型接收到了用户的输入,会根据分词器将输入分解成为一个个的小词组;第三步,大模型会根据分解出来的词组去进行向量的计算,称为向量化;第四步,大模型会根据组合起来的词组的向量去推测出可能的下一个词,最后组成结果放回给用户
大模型的问答工作流程
下面以“ACP is a very”为输入文本向大模型发起一个提问,下图展示从发起提问到输出文本的完整流程。
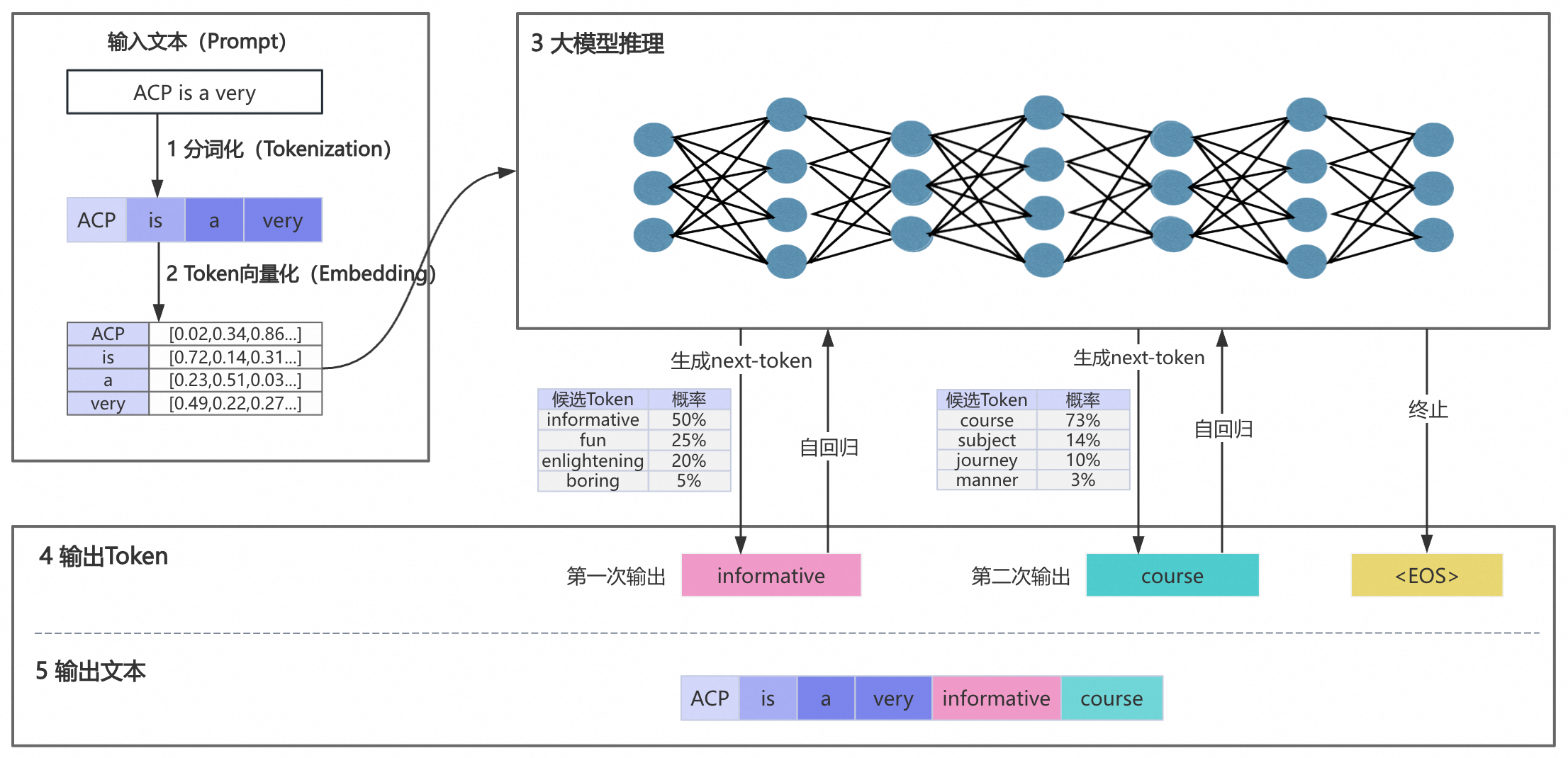
大模型的问答工作流程有以下五个阶段:
第一阶段:输入文本分词化
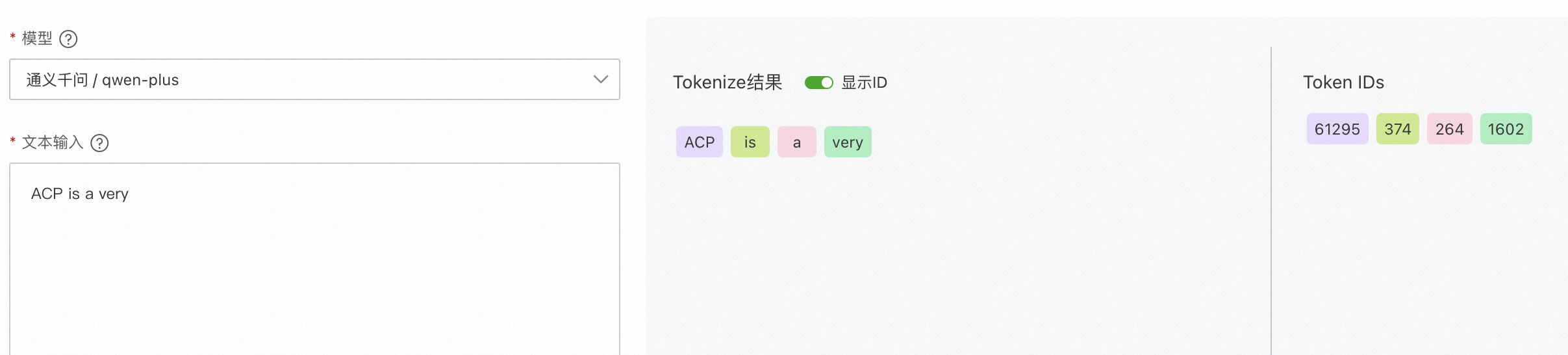
分词(Token)是大模型处理文本的基本单元,通常是词语、词组或者符号。我们需要将“ACP is a very”这个句子分割成更小且具有独立语义的词语(Token),并且为每个Token分配一个ID。如果您对通义千问的tokenizer细节感兴趣,请参考:Tokenization。
第二阶段:Token向量化
计算机只能理解数字,无法直接理解Token的含义。因此需要将Token进行数字化转换(即转化为向量),使其可以被计算机所理解。Token向量化会将每个Token转化为固定维度的向量。
第三阶段:大模型推理
大模型通过大量已有的训练数据来学习知识,当我们输入新内容,比如“ACP is a very”时,大模型会结合所学知识进行推测。它会计算所有可能Token的概率,得到候选Token的概率集合。最后,大模型通过计算选出一个Token作为下一个输出。
这就解释了为什么当询问公司的项目管理工具时,模型无法提供内部工具的建议,这是因为其推测能力是基于已有的训练数据,对它未接触的知识无法给出准确的回答。因此,在需要答疑机器人回答私域知识时,需要针对性地解决这一问题,在本小节第3部分会进一步阐述。
第四阶段:输出Token
由于大模型会根据候选Token的概率进行随机挑选,这就会导致“即使问题完全相同,每次的回答都略有不同”。为了控制生成内容的随机性,目前普遍是通过temperature和top_p来调整的。
2、大模型常见参数
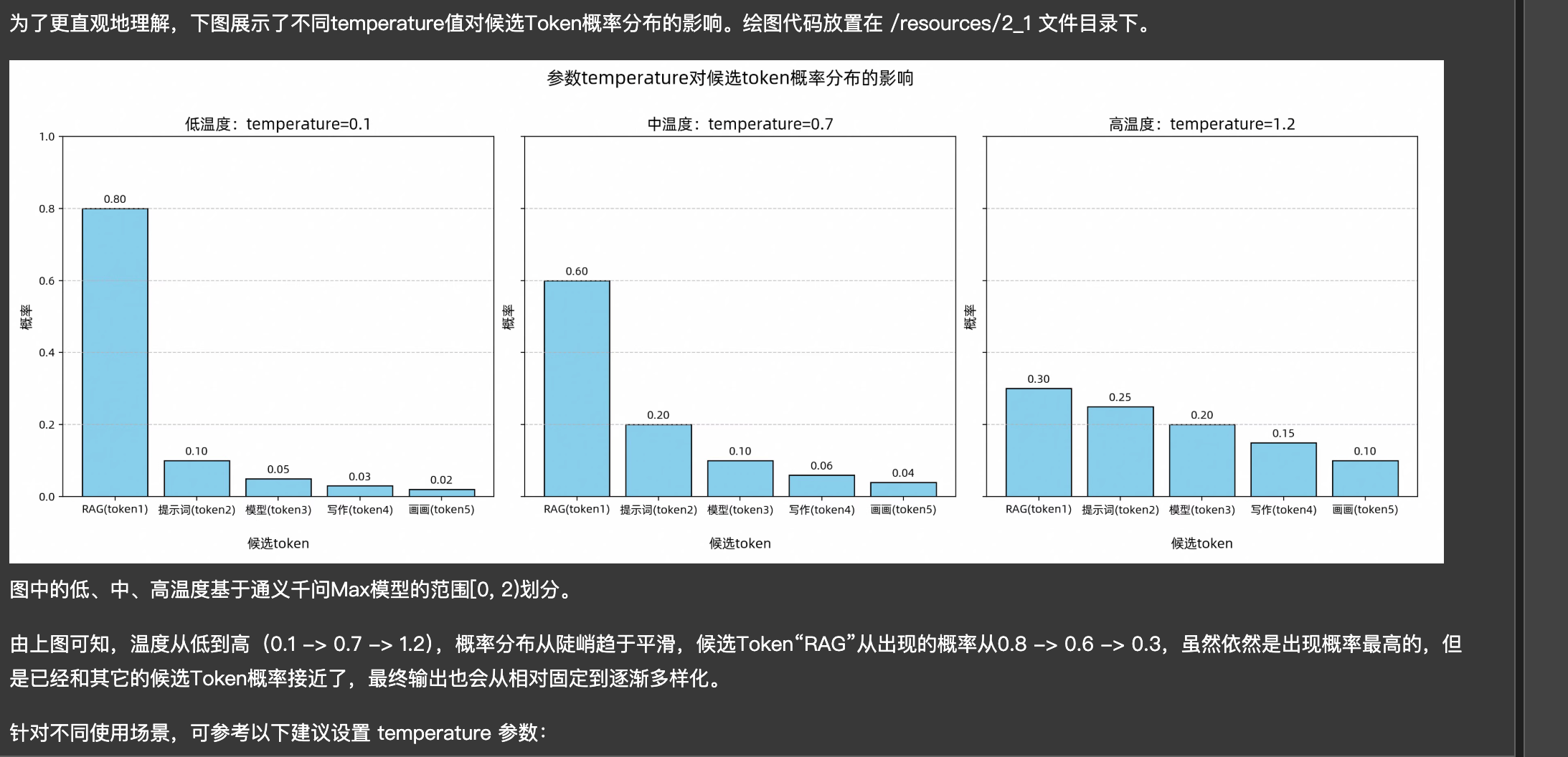
temperature:主要的功能为它能够改变候选token中的一个比例,如图:
top_p:它可以在特定的集合token中进一步筛选出特定的token集合,如图:
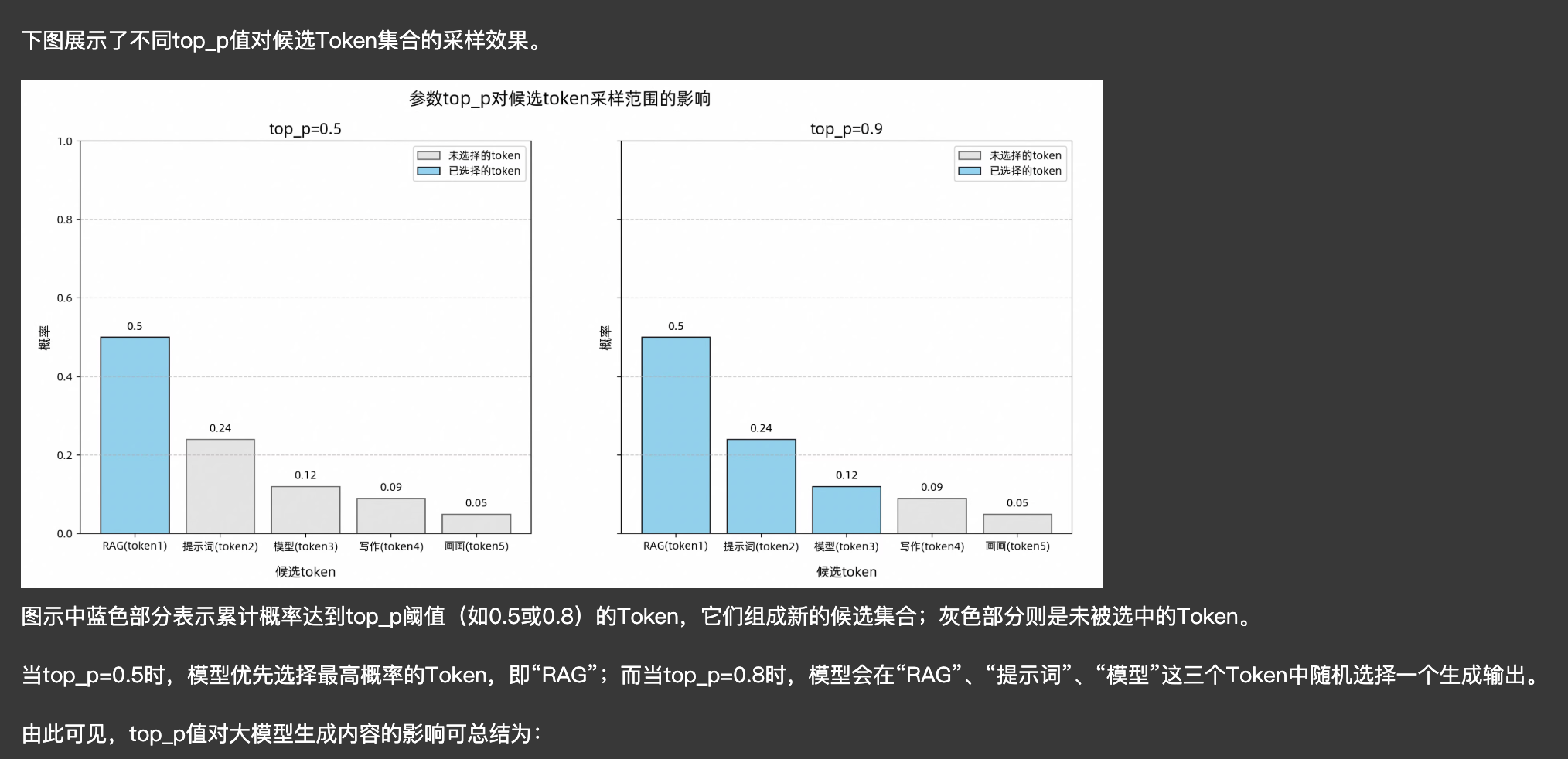
总结一下,如果想要答案稳定,那么temperature越低、top_p 越低,想要创新性越好,那么反之