网络缓冲区的设计以及C++实现
用户态网络缓冲区是什么?
用户态网络缓冲区指在网络数据包处理过程中,由用户态程序直接管理的缓冲区。其核心目标是减少内核态与用户态之间的数据拷贝开销,提升网络吞吐量,适用于高性能网络场景(如DPDK、XDP等)。
为什么要建立缓冲区?
接收缓冲区
粘包问题:需要缓存非完整的数据包,因为tcp是面向字节流的,所以一次接受的可能是半个完整数据包也可能是一个半完整数据包,那么这些不完整的数据包就需要先存下来,等待收到完整数据包后处理
生产者速度大于消费者速度,这是就要缓存来不及处理的数据包
发送缓冲区
可能依次不能把数据全部发送,缓存未发送的数据
生产者速度大于消费者速度也要缓存停止发送的数据
粘包处理
常见的粘包处理方法有
1.以\r\n结尾的才是一个完整包
2.用长度界定完整数据包,常见有用两字节在包头来描述数据包长度
但一般也由服务端和客户端商定怎么来标定完整数据包
Linux如何收发网络包
首先我们先看一下收发网络包的背景
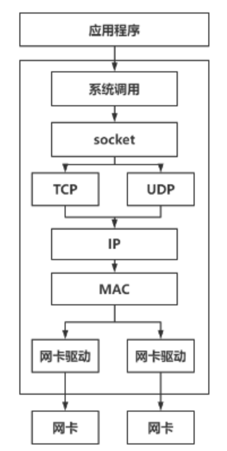
接收网络包流程
1.网卡收到数据包,通过DMA将数据包写入内存
DMA(Direct Memory Access)是一种允许硬件子系统直接读写系统内存的技术,无需中央处理器(CPU)介入。其核心目的是提高数据传输效率,减少CPU负担,适用于高速外设(如磁盘、网卡、显卡)与内存之间的数据交换。
2.网卡向CPU发起硬件中断,CPU收到硬件中断,根据中断表查找中断处理函数,调用中断处理函数
3.中断处理函数将屏蔽中断,发起软件中断,用软中断处理耗时操作,避免执行时间过长,导致CPU无法响应其他硬件中断
4.内核处理软中断,从ringbuffer中逐个取出数据帧到sk_buff
5.从帧头取出 IP 协议,判断是 IPv4 还是 IPv6,去掉帧头帧尾
6.从 IP 头看上一层协议是 tcp 还是 udp,根据五元组找到 socket,并将数据提取出来放到 socket 的接收缓冲区
7.应用程序通过系统调用将 socket 的接收缓冲区的数据拷贝到应用层缓冲区
软中断处理结束后开启硬件中断
发送方网络包流程
1.应用程序通过系统调用将用户数据拷贝 sk buff 并放到 socket 的发送缓冲区
2.网络协议栈从 socket 的发送缓冲区取出 sk buff,并克隆出一个新的 sk buff
udp 没有发送缓冲区
3.向下传递依次增加 TCP/UDP 头部、IP 头部、帧头(MAC 头部)、帧尾
4.触发软中断通知网卡驱动程序,有新的网络包需要发送
5.网卡驱动程序从发送队列依次取出 sk buff写 ringbuffer(内存DMA区域,网卡读到)
6.触发网卡发送,发送成功,触发硬件中断,释放 sk buff和 ringbuffer 内存
7.当收到 tcp 报文的 ack 应答时,将释放原始的 sk buff
网络缓冲区设计
定长buffer
首先我们先思考一下,如果缓冲区使用一块定长的buffer可不可以,如下图
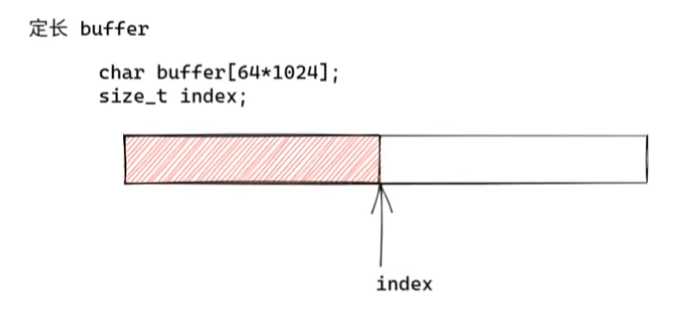
index指针指向写入的最后位置,这种方案其实是有缺点的
1.内存浪费,如果生产者和消费者的速度差不多的话,那index几乎不咋动,就有一半的内存浪费了。
2.伸缩性差,定长的buffer如果面临不够用的情况是非常尴尬的,无法扩展长度
3.频繁腾挪数据,如果经过一段时间的读写,我们占据了buffer的后半段,此时就要将保存的数据移回buffer开始的地方,这也会浪费性能。
ringbuffer
还有一种设计方法就是ringbuffer,如下图

这样解决了频繁腾挪数据的缺点,但是仍然存在内存浪费和伸缩性差的缺点
有的朋友会问,如果这样的缓冲区设计不会把一个数据包分成两段吗,这个问题在linux系统下可以很好解决,linux提供了readv和writev,实现了多段读写
chainbuffer
为了解决以上的问题,我们设计出chainbuffer来解决这些问题,如下图
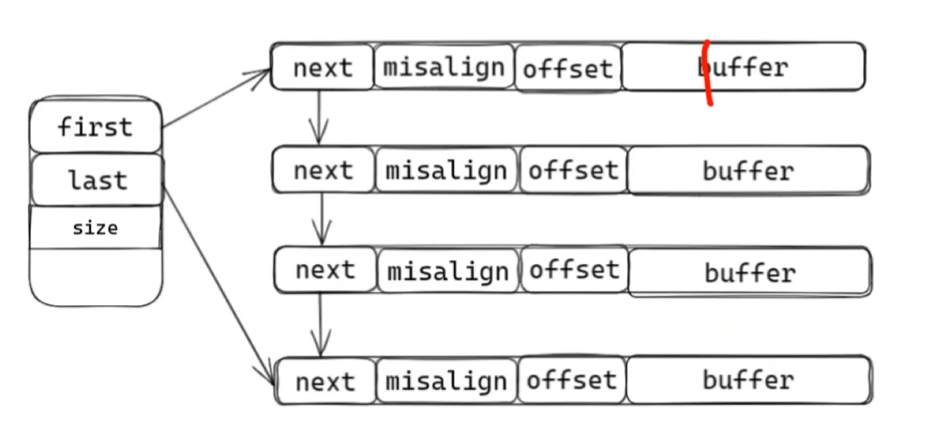
这种设计解决了以上的问题,misalign指已经取出了多少长度的数据,offset存buffer长度和可用内存长度,当可用空间不足时,会新生成一条,与之前的buffer建立连接。
代码实现
chainbuffer时c语言的设计思路,如果到了c++里,其实我们可以把定长buffer和ringbuffer的优点结合起来,因为vector是动态长度的。我们不实现环状结构,但是实在实在没办法的时候腾挪数据和增加buffer长度。
私有成员
private:std::vector<uint8_t> buffer_;std::size_t rpos_;std::size_t wpos_;uint8_t是unsigned_char,毫无疑问,我们需要一个vector,和read的位置write的位置。
构造函数
MessageBuffer() : rpos_(0),wpos_(0) {buffer_.resize(4096);}explicit MessageBuffer(std::size_t size) : rpos_(0),wpos_(0) {buffer_.resize(size);}这是最基本的两个构造函数,传入size和不传入size,注意防止隐式转换,不过多解释
禁用拷贝构造和拷贝赋值
//禁止拷贝MessageBuffer(const MessageBuffer&) = delete;//禁止拷贝赋值MessageBuffer& operator=(const MessageBuffer&) = delete;我们需要知道,我们需要去拷贝另一个线程的缓冲区吗?这显然是不需要的,所以为了发生问题,我们禁用拷贝构造和拷贝赋值。
移动构造和移动赋值
//允许移动MessageBuffer(MessageBuffer&& other) noexcept: rpos_(other.rpos_),wpos_(other.wpos_),buffer_(std::move(other.buffer_)) {other.rpos_ = 0;other.wpos_ = 0;}//允许移动赋值MessageBuffer& operator=(MessageBuffer&& other) {if (this != &other){buffer_ = std::move(other.buffer_);rpos_ = other.rpos_;wpos_ = other.wpos_;other.rpos_ = 0;other.wpos_ = 0; }return *this;}移动构造和移动赋值其实是将这个缓冲区的管理权全权交出去,这种情况是存在的,所以需要移动构造和移动赋值。这里需要注意buffer在调用的时候要转成右值,这样也方便直接清空了原buffer。下面需要注意的是先检验自赋值在进行操作。
杂项接口
uint8_t* GetBasePointer() {return buffer_.data();}uint8_t* GetReadPointer() {return buffer_.data() + rpos_;}uint8_t* GetWritePointer() {return buffer_.data() + wpos_;}std::size_t GetBufferSize() {return buffer_.size();}void ReadCompleted(std::size_t size) {rpos_ += size;}void WriteCompleted(std::size_t size) {wpos_ += size;}std::size_t GetActivateSize() {return wpos_ - rpos_;}std::size_t GetFreeSize() {return buffer_.size() - wpos_;}这些接口不过多解释,一眼就能看懂
Normalize
void Normalize() {if(rpos_ > 0) {std::memmove(buffer_.data(),buffer_.data() + rpos_,GetActivateSize());wpos_-= rpos_;rpos_ = 0;}}这个是格式化结构,指的是将buffer里的数据都挪到起点。
EnsureFreeSpace
void EnsureFreeSpace(std::size_t size) {if(GetBufferSize() - GetActivateSize() < size) {Normalize();buffer_.resize(buffer_.size() + std::max(size,buffer_.size()/2));}else if(GetFreeSize() < size) {Normalize();}}这个是确保剩余空间可以方式size大小的数据,如果不能放下,就扩容buffersize的一半或者传入的size。
Write
void Write(const uint8_t *data, std::size_t size) {if(size > 0) {EnsureFreeSpace(size);std::memcpy(GetWritePointer(),data,size);WriteCompleted(size);}}先调却表空间接口,memcpy写入,在收尾
这里其实有个缺点,我们考虑写数据时,需要把数据从内核拷贝到数组,再把数组拷贝到内核,经历了两次拷贝,那么能不能实现内核到内核的一次拷贝呢?
Recv
int Recv(int fd,int *err) {char extra[65535];struct iovec iov[2];iov[0].iov_base = GetWritePointer();iov[0].iov_len = GetFreeSize();iov[1].iov_base = extra;iov[1].iov_len = sizeof(extra);std::size_t n = readv(fd,iov,2);if(n < 0) {*err = errno;return n;}else if(n == 0) {*err = EBADE;return 0;}else if(n <= GetFreeSize()) {WriteCompleted(n);return n;} else {WriteCompleted(GetFreeSize());std::size_t extra_size = n - GetFreeSize();Write(reinterpret_cast<uint8_t*>(extra),extra_size);return n;}这个函数就实现了从内核到内核只拷贝一次的操作,这里要注意结构体构成如下
struct iovec{void *iov_base; /* Pointer to data. */size_t iov_len; /* Length of data. */};
同时数组中会把0的位置作为主缓存,1作为副缓存,执行readv会直接写入buffer,有写不下的才写入1位置即extra,后续再把extra写入即可。
更多资料在:https://github.com/0voice查询