OCR、文档解析工具合集
概述
随着AI技术的快速发展,文档解析作为NLP和计算机视觉领域的关键任务,正逐步从传统的规则引擎和启发式方法向深度学习模型演进。
文档解析的目标是将文档中的文本、表格、公式、图像等内容进行结构化识别和语义理解,从而实现信息的高效提取与处理。
MinerU
论文,由上海人工智能实验室OpenDataLab团队开源,工业级文档解析+数据提取工具,专注于高效解析复杂文档(如PDF、网页、电子书、扫描图像),并将其转换为结构化的机器可读格式(如Markdown、JSON、HTML)。该项目凭借其强大的多模态解析能力,能够精准识别文本、表格、图片、数学公式(支持LaTeX转换)及复杂排版,并自动去除页眉、页脚、页码等冗余信息,保留原始文档的语义逻辑与结构。支持176种语言识别,兼容CPU/GPU/NPU加速,适用于学术研究、企业数据处理、大模型训练等场景。
官网,中文文档,ModelScope,HuggingFace。
技术架构:集成LayoutLMv3(布局分析)+ YOLOv8(视觉识别),支持Docker和CUDA环境。
功能:
- 智能过滤页眉/页脚,精准提取PDF正文
- 支持EPUB/MOBI/DOCX转Markdown/JSON,84种语言
- 内置UniMERNet模型优化公式识别精度
优缺点:
- 企业级安全合规,支持API和图形界面,多格式兼容
- 依赖GPU资源,表格处理速度较慢,配置流程较复杂
功能:
- 全流程解析引擎:PDF文本提取 → OCR多语言识别 → 文档布局重建 → 公式/表格还原
- 37种语言混合支持:中/英/日/韩等主流语言全覆盖,特别优化东亚文字排版识别
- 场景化结构适配:学术论文(参考文献/章节层级)、法律文书(条款编号)、财务报表(跨页表格)均可精准还原
优势
- 高性能解析引擎
| 指标 | 性能表现 | 场景价值 |
|---|---|---|
| GPU吞吐量(4090) | >10,000 tokens/s | 单日处理千页级文档 |
| CPU内存占用 | 最低6GB(纯文本模式) | 老旧设备可运行 |
| 批量处理效率 | 较传统方案提升500% | 企业级文档自动化处理 |
- 极简部署方案
| 使用方式 | 适用场景 | 操作示例 |
|---|---|---|
| 零安装Web版 | 快速体验/临时需求 | 访问https://mineru.net |
| 命令行工具 | Linux/macOS/Windows系统集成 | mineru -p report.pdf -o md |
| Docker GPU加速 | 生产环境一键部署 | docker run -gpus all mineru-sglang:latest |
- 开源生态扩展
# 自定义模型路径,加载本地OCR模型
mineru -ocr_model_path ./custom_ppocrv5
- 核心扩展能力
- 模型热替换:支持PP-OCRv5、Unimernet等自定义模型
- 功能模块化:公式解析(
-formula True)、表格还原(-table True)独立开关 - 离线模式:
-source local完全断网运行 - mcp模式:支持mcp,客户端无缝调用
在线体验
- 访问https://mineru.net
- 拖拽上传,PDF/图片,支持50页批量处理
- 选择输出格式:
- Markdown:适配Obsidian/Notion等笔记工具
- JSON:便于API二次开发
- HTML:保留原始视觉样式
- 实时预览解析结果,一键导出数据
本地部署
# 基础环境配置
conda create -n mineru python=3.10
pip install "mineru[core]" # 安装核心包
# 启用SGLANG加速(需NVIDIA显卡)
mineru -p input.pdf -o outputs -b vlm-sglang-client -u http://localhost:30000
硬件配置推荐指南
| 后端模式 | GPU要求 | CPU/内存 | 适用场景 |
|---|---|---|---|
| Pipeline (CPU) | 无需GPU | ≥16核 / 32GB | 合同/发票等简单文档 |
| VLM Transformers | ≥8GB显存 (Turing架构+) | ≥8核 / 16GB | 学术论文(含复杂表格) |
| VLM SGLANG | ≥8GB显存 | ≥16核 / 32GB | 100+页医学报告批量处理 |
2025 V2.0路线图:垂直文本支持(古文献/乐谱)、显存动态回收机制。
markitdown
微软推出的一款开源超强文档转换工具,能将微软Office全家桶文档转换为Markdown格式,还包括PDF、图片、音频、HTML、ZIP(遍历其中内容),URL(直接总结),EPUB电子书等。不是简单的格式转换,能智能识别文档结构,保留原始格式和样式,甚至还能处理表格和图片。
技术架构:集成GPT-4等大模型,支持多格式AI增强转换。
功能:
- 支持Word/Excel/PPT、图像(OCR)、音频(语音转录)转Markdown
- 批量处理ZIP文件,可生成图片描述(需OpenAI API)
适用场景:多格式内容创作,如PPT图表转文档、音视频转录场景。
优缺点:
- 格式支持最全,提供Python API/CLI,开发者友好;
- 依赖外部API,部分功能需付费模型
安装
pip install 'markitdown[all]'
或
git clone git@github.com:microsoft/markitdown.git
cd markitdown
pip install -e 'packages/markitdown[all]'
Marker
采用Surya模型,基于视觉解析技术的开源OCR工具。
技术架构:基于PyMuPDF(PDF解析)+ Tesseract OCR,支持GPU加速(Surya OCR引擎),轻量化设计。
核心功能:
- 专注PDF转Markdown,公式自动转LaTeX,图片内嵌保存;
- OCR识别扫描版PDF,支持多语言文档;
- 处理速度比同类工具快4倍(实测数据)
适用场景:科研文献、书籍等基础格式转换,适合技术用户快速部署。
优缺点:
- 轻量化部署、处理速度极快;
- 复杂布局解析能力弱,依赖本地GPU资源。
安装:
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
docker run -gpus all -itd -p 7231:7231 -name model_pdf_v2 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
mPLUG-DocOwl 1.5
阿里巴巴mPLUG团队在多模态文档图片理解领域的最新开源工作,在10个文档理解benchmark上达到最优效果,5个数据集上提升超过10个点,部分数据集上超过智谱17.3B的CogAgent,在DocVQA上达到82.2的效果。
站点
- ModelScope:https://modelscope.cn/studios/iic/mPLUG-DocOwl/
- HuggingFace:https://huggingface.co/spaces/mPLUG/DocOwl
Mistral OCR
由法国Mistral AI开发的高性能光学字符识别工具,专为处理复杂文档设计,具备高精度解析(支持文本、图像、表格、数学公式等)、多语言识别(覆盖千种语言,准确率达99.02%)、极速处理能力(单节点每分钟2000页)及结构化输出(JSON/Markdown/HTML格式保留原始排版)等核心优势。
目前提供API版本(mistral-ocr-latest),通过开发者平台La Plateforme提供,定价为每1000页1美元。
- 官方网站:https://mistral.ai/news/mistral-ocr
- 在线体验地址:https://mistralocr.org/zh-CN/
Got OCR 2.0
一个基于通用OCR理论(General OCR Theory)的统一端到端模型,由StepFun、旷视科技、中国科学院大学和清华大学联合开源,旨在推动OCR进入OCR-2.0时代。该模型具备处理多种类型内容的能力,包括普通文本、数学公式、分子结构、表格、图表、乐谱等,并通过端到端架构、Flash-Attention技术优化以及动态分辨率处理,实现高效识别与格式化输出(如Markdown/LaTeX)。ModelScope
Dolphin
字节跳动开源的轻量级文档解析模型,体积小、速度快,解析效率提升近2倍。
体验地址:http://115.190.42.15:8888/dolphin/
Umi-OCR
开源免费的离线(无需联网)OCR识别工具。
功能:
- 完全离线运行:所有识别过程均在本地完成,无需上传图片至云端,彻底杜绝数据泄露风险,尤其适合处理敏感文档和隐私信息;
- 多语言识别支持:不仅完美支持中文(简体/繁体)和英文,还可识别日语、韩语、法语等多种语言,满足跨语言文档处理需求;
- 高效准确识别:基于PP-OCR v2.6引擎优化,配备cpu_avx_mkl加速,识别速度快且准确率高,复杂背景图片也能精准提取文字;
- 绿色便携免安装:采用绿色版设计,解压即可使用,无需繁琐安装步骤,不写入系统注册表,占用资源少,兼容Windows全平台;
- 批量处理能力:支持多图片同时识别,可一次性处理大量文件,并支持将结果导出为纯文本格式,大幅提升办公效率;
- 实用辅助功能:
- 快捷键操作,支持截图后自动识别
- 排除区域标记,可手动划定识别范围
- 结果实时复制到剪贴板,方便快速编辑
安装
GitHub进入Release页面。不同版本仅OCR引擎插件不同,其它功能完全一致,附带多国语言识别库。.7z.exe为自解压包,可以用压缩软件打开,也可以在没有安装压缩软件的电脑上直接双击解压。
Paddle引擎插件版:性能好,速度快,占用率高,适合高配机器。不兼容奔腾、赛扬、凌动CPU。如果执行OCR时报错 0xc0000142、[Error] OCR init fail,大概率是CPU不兼容Paddle。
Rapid引擎插件版:速度稍慢,内存占用低,适合低配机器,兼容性好。
源码编译安装:
git clone https://github.com/hiroi-sora/Umi-OCR.git
cd Umi-OCR
# 安装依赖
pip install -r requirements.txt
# 启动应用
python main.py
使用
- 启动软件后,可通过三种方式导入图片:
- 点击"打开图片"按钮选择文件
- 将图片直接拖拽至软件窗口
- 使用快捷键
Ctrl+V粘贴剪贴板截图
- 点击"开始识别"按钮,等待片刻即可获取结果
- 识别完成后,可选择复制文本或导出为TXT文件
MonkeyOCR
论文,华中科技大学与金山办公联合开发的新型开源文档解析模型,其核心创新在于采用 Structure-Recognition-Relation (SRR) 三元组范式。通过将文档解析任务分解为三个核心问题(结构在哪里?内容是什么?它们如何组织?),即结构检测(布局分析)、内容识别和关系预测(逻辑排序)三个阶段,实现对文档内容的高效、精准解析。
在多个中文和英文文档类型上均表现出色,尤其在表格、公式等复杂内容的识别上,相比现有方法有显著提升。支持多页文档的快速解析,30亿参数模型在英文文档解析中超越Gemini 2.5 Pro等大模型,推理速度达到 0.84 页/秒,远超其他主流模型。还可通过特定方式更新配置文件以使用不同模型。可在单块3090 GPU上运行。
模型地址:https://huggingface.co/echo840/MonkeyOCR
在线体验:http://vlrlabmonkey.xyz:7685
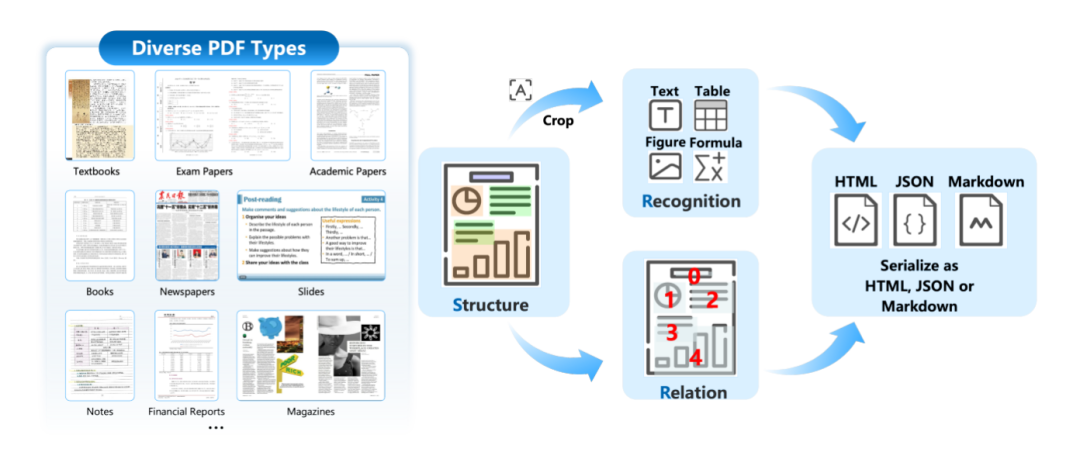
功能
- 多语言支持
支持中英文双语文档的解析,能够处理中文和英文的文本、表格、公式等复杂内容。对于中文场景,还可使用专门的结构检测模型layout_zh.pt来提高识别效果。 - 多格式支持
模型支持对PDF、图像等多种格式的文档进行解析。用户可通过命令行或Gradio界面上传文件,并获取结构化输出。 - 高精度识别
在多个基准测试中,如表格识别、公式识别等表现优异。例如,相比MinerU,MonkeyOCR在表格识别任务上的TEDS(Textual Edit Distance)提升8.6%,在公式识别任务上的CDM(Correct Document Match)提升15.0%。 - 快速部署
支持多种部署方式,包括命令行工具、 Docker容器和FastAPI服务。用户可以根据需求选择合适的部署方案,快速启动模型并进行测试。
技术原理
核心思想是将文档解析任务分解为三个关键步骤:
- 结构检测(Structure Detection) :使用基于YOLO的文档布局检测器,通过布局分析,识别文档中的各个区域(如文本块、表格、公式、图像等),并为其分配类别标签和边界框坐标。
- 内容识别(Recognition):对每个检测到的区域进行内容识别,包括文本、表格、公式等,使用统一的VLM进行识别,避免传统管道的错误传播。
- 关系预测(Relation Prediction) :通过专用的块级阅读顺序模型,预测各个区域之间的逻辑关系,重建文档的结构化内容,确保输出的语义一致性。
有效结合流水线方法的模块化优势和端到端方法的全局优化能力,既保证解析的准确性,提升处理效率。
MonkeyDoc数据集
为了支持MonkeyOCR的训练和评估,研究团队开发MonkeyDoc,这是目前最全面的文档解析数据集之一;包含390万个块级实例,涵盖5个核心文档解析任务和10多种文档类型,支持中英文双语标注。数据集的构建过程包括:
- 结构检测:从多个公开数据集中提取并统一标注,补充合成高质量中文样本。
- 内容识别:通过自动标注和人工校验,确保文本、表格、公式等的识别准确。
- 关系预测:通过多任务学习和模型辅助策略,建立区域之间的逻辑关系。
MonkeyDoc的多任务、多语言、多领域的覆盖能力,为模型的泛化训练提供坚实基础。
基准测试
OmniDocBench是一个用于评估真实世界文档解析能力的基准测试,包含981个PDF页面,涵盖9种文档类型、4种布局风格和3种语言类别。通过这个基准测试,能够对MonkeyOCR的文档解析能力进行全面评估。
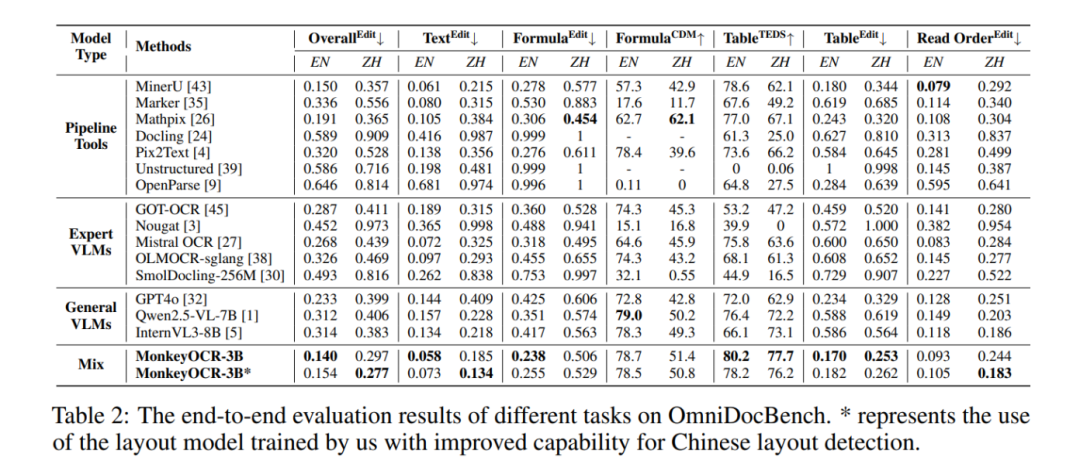
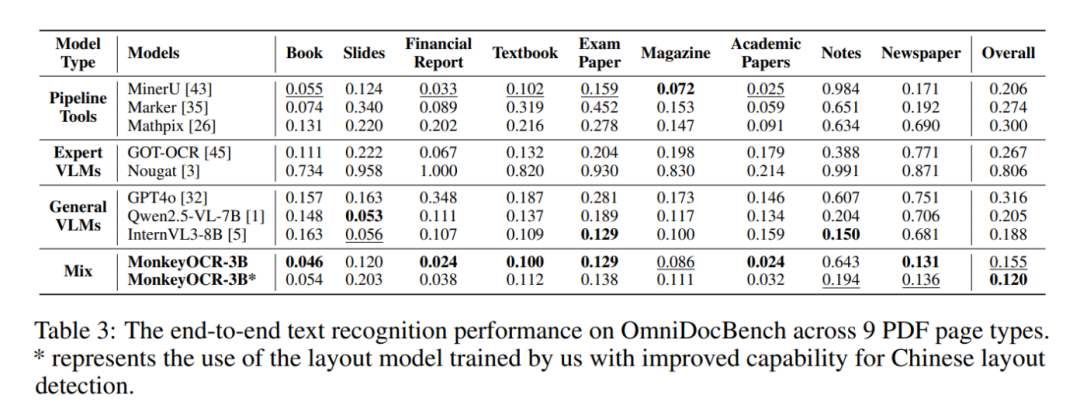
性能表现:
- 与 MinerU 相比,在中英文文档上平均提升 5.1%,公式识别提升 15.0%,表格识别提升 8.6%。
- 3B 参数模型在英文文档解析任务上超越更大的模型,如 Qwen2.5-VL(72B)和 Gemini 2.5 Pro。
- 多页文档处理速度达0.84页/秒,优于MinerU(0.65)和 Qwen2.5-VL-7B(0.12)。
安装及使用
# 创建conda环境
conda create -n MonkeyOCR python=3.10
conda activate MonkeyOCR
# 克隆代码
git clone https://github.com/Yuliang-Liu/MonkeyOCR.git
cd MonkeyOCR
# 安装依赖
# Install pytorch, see https://pytorch.org/get-started/previous-versions/ for your cuda version
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 -index-url https://download.pytorch.org/whl/cu124
pip install -e .pip install huggingface_hub
python tools/download_model.pypython parse.py path/to/your.pdf
pyhton parse.py path/to/your/image
# 指定输出路径和模型配置文件路径
python parse.py path/to/your.pdf -o ./output -c config.yaml
# 启动Gradio界面
cd demo
python demo_gradio.py
Agentic-Doc
一个由LandingAI开发强大的Python库,由Agentic文档提取(ADE) 提供支持,可从 PDF和图像等复杂文档中提取结构化、视觉化的数据,使文档自动化变得简单可靠。
ADE是一种AI驱动的方法,提供功能:
- 了解视觉布局:识别表格、图片、标题、段落、图表等。
- 提供真实边界框:准确显示在页面上找到每个数据块的位置。
- 返回结构化输出:以分层方式组织内容,并包含位置和类型信息。
agestic-doc是ADE API的Python包装器。它通过以下方式使开发人员更轻松地提取文档:
- 支持1000多页的PDF
- API错误或超时自动重试
- 从图像、URL、云存储等中提取
- 提供可视化和调试提取的工具
功能
- 支持所有文件类型:PDF、图像和URL。
- 处理长文档:自动拆分并并行处理大文件。
- 批处理和并行处理:高效地同时从多个文件中提取。
- 结构化输出:易于使用的JSON和Markdown。
- 可视化调试:通过边界框图像查看每个块的提取位置。
- 弹性:使用智能退避逻辑重试失败的请求。
- 助手:简单的 Python 函数来处理大多数任务。
- 灵活的配置:环境变量和
.env批量大小、日志记录、重试的支持。 - 云就绪:Google Drive、Amazon S3、本地文件夹、URL 甚至内存中的字节。
安装
pip install agentic-doc
export VISION_AGENT_API_KEY=<your-api-key>
.env环境配置文件:
BATCH_SIZE = 4
MAX_WORKERS = 2
MAX_RETRIES = 80
MAX_RETRY_WAIT_TIME = 30
RETRY_LOGGING_STYLE =log_msg
使用
from agentic_doc.parse import parse, parse_documents
from pydantic import BaseModel, Field
from agentic_doc.parse import parse
from agentic_doc.connectors import GoogleDriveConnectorConfig, S3ConnectorConfig, LocalConnectorConfigconfig = LocalConnectorConfig(recursive=True)
results = parse(config, connector_path="docs/")result = parse("path/to/document.pdf")
print(result[0].markdown)
print(result[0].chunks) # 以结构化JSON格式提取数据
result = parse("https://example.com/report.pdf")
result = parse("path/to/image.png")class ExtractedFields(BaseModel):name: str = Field(description="Employee name")amount: float = Field(description="Gross pay")address: str = Field(description="Employee address")
results = parse("salary_slip.pdf", extraction_model=ExtractedFields)
fields = results[0].extraction
meta = results[0].extraction_metadata
print(f"Name: {fields.name}, Confidence: {meta.name.confidence}")config = GoogleDriveConnectorConfig(client_secret_file="credentials.json",folder_id="your-folder-id"
)
results = parse(config)config = S3ConnectorConfig(bucket_name="my-bucket",region_name="us-east-1"
)
results = parse(config)results = parse_documents([ "report.pdf" ], grounding_save_dir= "groundings/" )
# 每个块的边界框作为图像保存在输出文件夹中
docext
由Nanonets开源OCR模型,由VLM提供支持的全面的本地文档智能工具包,基于Qwen2.5-VL-3B微调,运行至少需要9G显存。
功能:
- PDF/image转Markdown:将文档转换为具有智能内容识别的结构化标记,包括LaTeX公式、签名、水印、表和语义标记。
- 文档信息提取:从发票、护照等文档中无OCR地提取结构化信息(字段、表等),并进行置信度评分。
- 智能文档处理排行榜:一个全面的基准测试平台,跟踪和评估视觉语言模型在OCR、关键信息提取(Key Information Extraction,KIE)、文档分类、表提取和其他智能文档处理任务中的性能。
- ModelScope:https://www.modelscope.cn/studios/nanonets/Nanonets-ocr-s/summary
OCR Flux
基于VLM的开源工具包,专为将PDF文档和图像转换为结构清晰、可读性强的Markdown文本而设计。一张12GB的RTX-3090显卡即可部署运行。官网。
Doc2x
商业版:https://doc2x.noedgeai.com/
OLM OCR
Allen Institute for Artificial Intelligence(AI2)的AllenNLP团队开源,旨在将PDF文件和其他文档高效地转换为纯文本,同时保留自然的阅读顺序。支持表格、公式、手写内容等。
官网:https://olmocr.allenai.org
技术架构:基于LLM,分布式架构+GPU加速推理(SGLang)。
核心功能:
- 高质量提取复杂PDF中的结构化文本,正确处理多栏布局、表格、公式和手写内容;
- 100 万页 PDF 处理成本约 190 美元,性能超过Marker、MinerU等工具。
优缺点:
- 解析质量高,成本低于商业 API,性能突出
- 使用门槛高(多系统依赖),早期开发阶段文档不完善,仅支持 PDF / 图片
Docling
GitHub,技术架构:模块化设计,集成Unstructured、LayoutParser等库,支持本地化处理。
功能:
- 解析PDF/DOCX/PPTX等多格式文档,保留阅读顺序和表格结构;
- 支持OCR和LangChain集成,输出Markdown/JSON用于RAG知识库构建
优缺点:
- 与IBM生态兼容,多格式混合处理能力强
- 需CUDA环境,部分功能依赖商业模型
Smol Docling
SmolDocling(SmolDocling-256M-preview )是开源高效轻量级的多模态文档处理模型。能将文档图像端到端地转换为结构化文本,支持文本、公式、图表等多种元素识别,适用于学术论文、技术报告等多类型文档。模型参数量256M。使其能够在消费级显卡(如 RTX 3060 等)上流畅运行。
huggingface:https://huggingface.co/spaces/ds4sd/SmolDocling-256M-Demo
Zerox
开源OCR工具,支持复杂PDF/图片(含表格、手写字)转Markdown,利用视觉模型。
特性:
- 零样本OCR识别,开箱即用
传统OCR工具需要大量样本训练才能精准识别文字,而Zerox基于GPT-4o-mini模型,无需任何预训练即可处理复杂布局文档,包括表格、图表甚至手写体,准确率远超同类工具。 - 输出Markdown格式,完美保留结构
无论是PDF、DOCX还是扫描图片,Zerox都能将内容转换为结构化Markdown,自动生成标题、列表、表格等元素。例如,发票中的金额表格能直接转为Markdown表格,方便二次编辑。 - 手写体识别“杀手锏”
许多OCR工具对打印体效果尚可,但对手写体束手无策。Zerox通过多模型兼容技术,对手写笔记、签名等内容的识别准确率高达90%以上,堪称“打工人救星”。 - 支持API集成,企业级效率工具
开发者可通过Node或Python SDK快速集成Zerox,实现批量文档处理自动化。适用于法律合同解析、学术论文整理等场景,节省80%人工整理时间
对比:
- 格式兼容性:支持20+文件格式(包括冷门的WPS、ODT等),而多数工具仅限PDF/图片;
- 并发处理:可同时处理多页文档,速度比传统工具快3倍;
- 开源免费:代码完全公开,企业可二次开发,避免商业OCR的高额授权费。
安装:
npm install zerox # Node
pip install zerox # Python
使用
import { zerox } from "zerox";
const result = await zerox({filePath: "invoice.pdf", // 支持本地文件或URLopenaiAPIKey: "YOUR_API_KEY",
});
console.log(result.pages[0].content); // 输出Markdown
Llamaparse
开源,技术架构:结合Azure OpenAI和KDB AI向量数据库,优化语义检索。核心功能:
- 解析含表格/图表的复杂PDF,输出Markdown/LaTeX/Mermaid图表
- 支持生成知识图谱,企业级安全合规设计
优缺点:
- 解析精度高,支持半结构化数据语义优化
- 处理速度较慢,免费额度有限,需API密钥
Llama OCR
内部使用 Llama 3.2 Vision 模型。官网
安装:npm i llama-ocr
使用:
const { ocr } = require("llama-ocr");(async () => {try {const markdown = await ocr({filePath: "./yz_ocr_example.png",model: "Llama-3.2-90B-Vision",apiKey: ""});console.log("OCR 结果:", markdown); } catch (error) {console.error("发生错误:", error); }
})();
选型
| 需求场景 | 推荐工具 | 核心优势 |
|---|---|---|
| 科研文献快速转换 | Marker | 轻量化、处理速度极快 |
| 企业级高精度解析 | MinerU | 多语言支持、安全合规 |
| 多格式混合处理 | Markitdown | 微软生态兼容、AI 增强转换 |
| RAG知识库构建 | Docling/Llamaparse | 语义优化、向量数据库集成 |
| 复杂布局处理 | olmOCR | 大模型驱动,多栏 / 表格解析强 |