RLHF-V原论文阅读
(零)多模态幻觉相关知识补充
1.传统的RLHF(Reinforcement Learning from Human Feedback)
RLHF是一种通过人类偏好反馈引导 大模型行为的训练方法,典型流程如下:
生成多个候选回答 -> 人类打分排序(就有点像使用GPT的时候会冒出来两个回答,让弄选择那个更好)-> 训练一个reward模型(以人类排序为监督信号训练一个打分器) -> 用强化学习算法训练语言模型
2.DPO(Direct Preference Optimization)
DPO相当于把RLHF转化为监督学习问题而不需要使用强化学习框架
相当于不是在模型评估的时候增加人类偏好而是在输入训练数据的时候就输入人类偏好,从而实现直接训练模型更倾向于人类偏好的回答:
给定三元组:
输入 x
好的回答 y_w
差的回答 y_l
则直接最小化:
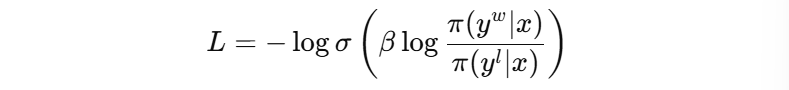
其中Π是当前模型的输出概率,σ是sigmoid。相当于告诉模型“我希望你比起坏回答,更大概率地产生好回答”。
3.DDPO(Dense Direct Preference Optimization)
是DPO的改进版本,用于处理细粒度人类反馈的场景。
对模型输出的某些片段加权优化
比如说某一段话的时间描述是错误的,那么优化时只对“时间相关的 token”赋予更大权重
公式上为:
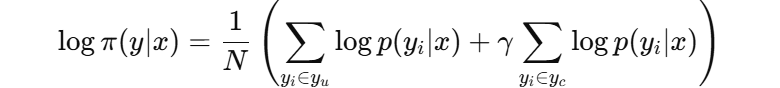
其中y_u是违背修正的token(不重要),而y_i是被纠正的token(很重要,γ>1)
4.还有一个我最一开始的问题:人类注释者是怎么标注幻觉片段的?就直接修改吗?会不会太耗费人力了?
操作流程:
输入图像 + Prompt(如“请描述图片内容”)
MLLM 生成响应(如“图片中有两个女人在沙发上吃苹果”)
人类查看响应与图像是否一致
比如图片中根本没有“两个女人”,只有一个人
对幻觉片段做如下操作:
删除或修改原句
提供一个更符合图像的修正版本
并记录“哪些词被修改了”
是不是很耗人力?
是的,但比传统方式更高效、更准确。为什么?
传统方式:
要在多个长段文本间做整体比较排序(哪一个好?理由是什么?很主观)
难以精准定位问题,训练信号稀疏
RLHF-V 方式:
只要告诉模型:“你这句话不对,应该这样说”
类似直接对 ChatGPT 说:“这块你搞错了,改成这样吧”,更容易标注也更实用
作者用 1400 条这样的标注数据就能打败用了 1 万条数据的 RLHF baseline(LLaVA-RLHF),说明它的人力-收益比是极高的。
(一)Abstract+Introduction
1.Abstract
当前MLLM研究现状:普遍受到幻觉问题影响(trustworthy)+RLHF-V(通过从细粒度纠正性人类反馈的行为对齐)+主要创新点:segment-level和DDPO+实现的效果
2.Introduction
介绍目前MLLM的主要训练流程:visual signals + LLMs,随后进行指令微调(多数是通过监督学习使模型去学习数据中的行为)
介绍当前MLLM中一个明显的问题:幻觉。甚至是最先进的GPT-4V中都存在这个问题。
论文认为问题来源于在指令微调阶段缺少人类的积极/消极反馈,但是仅仅使用之前的RLHF有两个主要的问题:(1)标注歧义(对于标注者而言:对于丰富的图像的好的标注通常是长且复杂的,所以偏好性就没那么明显,而且很难确定哪一个是最优的)(2)学习效率(数据量要求大以及对于模型而言:反馈通常是粗粒度的,很难确定是哪个行为使比分高)
RLHF-V的关键创新点:segment-level(在第二部分详细介绍)和使用DDPO(在第三部分Method那里详细介绍)
主要贡献:(1)提出了RLHF-V方法 (2)收集到了高质量的人类偏好数据 (3)进行综合实验来证明方法的有效性(实现了开源MLLM中最先进的性能)
(二)Human Preferennce Collection
目标:收集一些数据,这些数据能够明确展示出人类偏好,使模型能够选择较好的回答
1.人类偏好数据的潜在因素
y_w表示偏好输出,y_l表示较差的输出,Y表示y_w和y_l的差异,Y可以表示为:
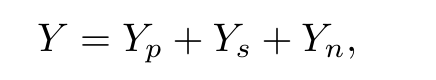
其中Y_p表示偏好的行为,Y_s表示浅层偏差(与数据相关但和人类判断无关的浅层偏差),Y_n表示自然语言变化的随机噪音(同一语义的不同表现方式)。
Y_n和Y_s举例:
Y_n:
"I think this is the right answer."
"In my opinion, this is the correct response."
这两个句子的意义是一样的,但是它们在语言上有所不同。这里的变化就是 Yn,它是自然语言中的随机变化或噪音。
Y_s:
假设某个模型训练数据中,某些常见的高评分回答包含很多使用特定词汇的句子(例如频繁使用“clearly”、“obviously”这类词语),即使这些词汇本身并不代表更高的质量。模型可能学会“使用这些词汇”来提高其评分,这种现象就是 Ys,它代表了模型的偏向性,基于数据中的浅层规律。
2.收集方法
之前的RLHF使用的是utterance-level(展示整个回答的质量),但是会产生标注歧义和学习效率的问题。所以这里使用的是segment-level (fine-grrained huuman preferences).
(1)Segment-Level Corrections的含义:
人类反馈者不再是只对整个AI输出给一个 笼统的“好”或“坏”的评价(utterance-level),也不是只在单个词层面作出修改(token-level),而是定位到生成文本中一个具体的有意义的局部片段,然后指出 这个片段存在幻觉问题,并可能提供或暗示正确的信息应该是什么。
例子:假设上面描述的图片中根本没有“飞盘”,只有一只狗在跑。人类反馈者可能会圈出“追逐一个红色的飞盘”这个片段,标记为“幻觉”,并可能注释“图片中没有飞盘”或“狗只是在草地上跑”。
好处:更具体的反馈,适合纠正幻觉且效率更高。
(2)训练数据
使用DDPO偏好对(chosen_segment, rejected_segment)
例子:“A brown dog is sitting on a park bench and playing with a red ball. A green water bottle is beside him.“(加粗的是幻觉片段)
①基于模型自身生成(常用且高效)
让模型在相同前缀上下文下生成多个备选延续,从中选出不含幻觉的片段作为chosen_segment(
Option A: and looking around. (可能正确,描述一般行为)
Option B: and panting happily. (可能正确,描述状态)
Option C: and chewing on a bone. (新幻觉!)
Option D: with a blue cup beside him. (描述了图片中的正确物体,但位置/连接词可能不太自然)
)
最终偏好对:(chosen_segment, rejected_segment) = (”and looking around“, "and playing with a red ball")
②基于人类建议
要求标注者不仅指出错误片段,还提供一个正确的替代片段。
如人类建议的更正:and resting quietly
最终偏好对:(chosen_segment, rejected_segment) = (”and resting quietly“, "and playing with a red ball")
(三)方法
1.DDPO(Dense Direct Preference Optimization)
RLHF需要对偏好数据单独训练一个奖励模型,这个需要大量模型和样本训练,因此流程复杂且消耗大量算力。
DPO中的reward表示为:
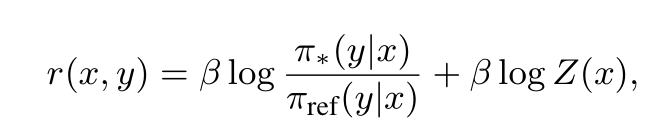
巧妙地把强化学习转化为一个“监督学习”问题:
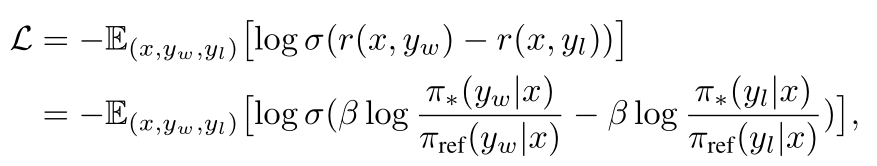
其中
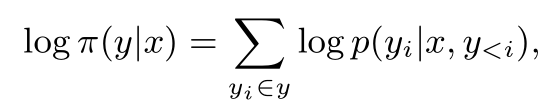
(详细过程可以看B站这个视频:【DPO (Direct Preference Optimization) 算法讲解】 https://www.bilibili.com/video/BV1GF4m1L7Nt/?share_source=copy_web&vd_source=1153a52d01da60d0632a3eb9586f7ffa)
DPO的巧妙之处在于消除了reward model,直接对损失函数梯度下降就可以实现优化而不用再训练一个reward model.


------->DDPO:
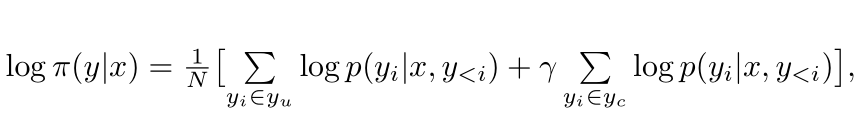
y_u表示不改变的部分,而y_c是幻觉部分。
2.视觉上消除幻觉
幻觉的来源:预训练中低质量的文本;训练中无意识的图像增强
①现在的模型训练时使用的数据大多来自于网页,质量良莠不齐,可能引起幻觉----->在高质量的视觉问答数据集(人类标注的数据集)上进行训练
②数据增强可能会导致图像语义变化---->训练时去除数据增强这个流程
(四)实验
1.实验设置及结果
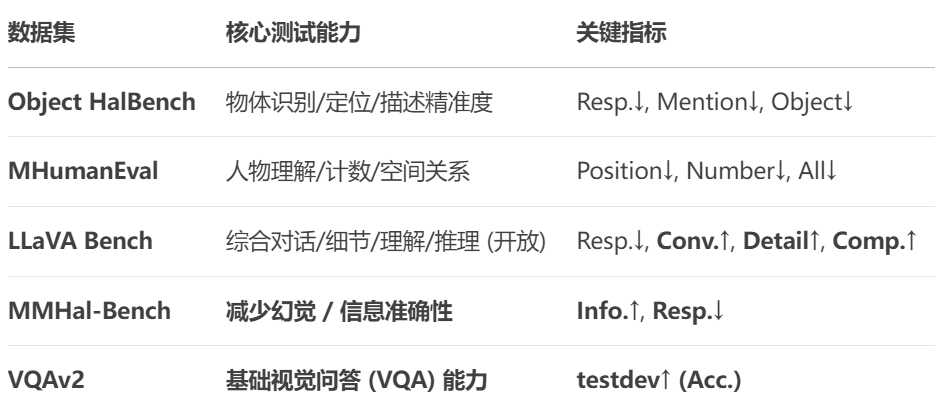
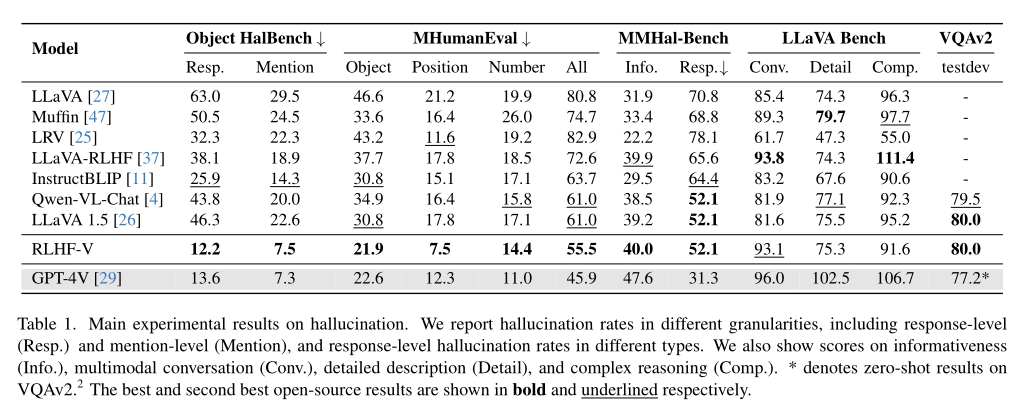
注意:在MMHal-Bench评估中,该评估使用的是GPT-4来进行评估。但过程中发现由于MMHal Bench文本注释的不完整性,GPT-4无法可靠地检测幻觉。因此,仅报告GPT-4的信息性评分,并通过人类评估来评估反应水平幻觉率。
2.结果分析
数据量的影响:随着反馈数据量增加,RLHF-V的幻觉率显著下降,表现出细粒度反馈的有效性。
细粒度反馈的优势:与传统的全局排名标签相比,细粒度修正性反馈提供更高质量的数据,能更快速地减少幻觉。
通用性:RLHF-V不仅在Muffin模型中有效,也能改善其他模型,如LLaVA,减少幻觉。
减少过度泛化的幻觉:RLHF-V在减少由于过度泛化造成的幻觉方面表现尤为突出,优于GPT-4V。
消融研究:DDPO相较传统DPO更有效,VQAv2微调能显著减少幻觉,不可信的数据增强会损害性能。