【LLM】讲清楚MLA原理
需要你对MHA、MQA、GQA有足够了解,相信本文能帮助你对MLA有新的认识。
本文内容都来自https://www.youtube.com/watch?v=0VLAoVGf_74,如果阅读本文出现问题,建议直接去看一遍。
按照Deepseek设定一些参数值:输入token长度n=10,注意力头数目n_h=128,每个注意力头的隐含层维度d_h=128,transformer block层数 l =61,使用fp16存储参数。
先来看MHA的kv-cache计算:
(第一个2是因为要保存K和V,第二个2是因为fp16占2bit)
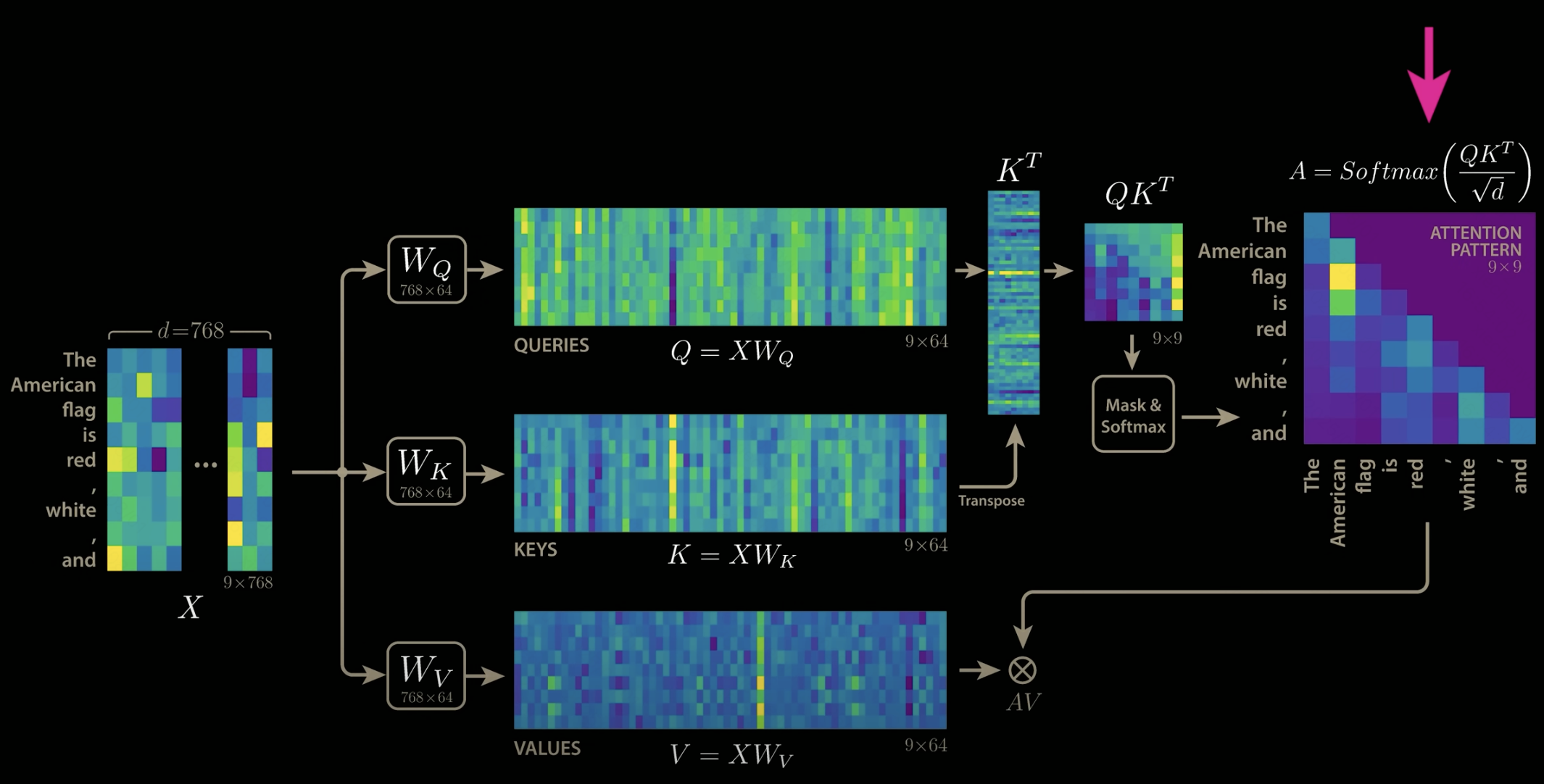
MQA和GQA的思路是通过不同注意力头之间共享参数,减少注意力头数目n_h来达到降低开销的目的。
这样的问题是参数的共享会导致模型效果下降,毕竟原本有128个头,128份KV参数,每份KV参数都会计算出不一样的注意力分布,让模型能更好的根据所有的注意力分布去预测下一个词,而现在128份参数变成了1份,预测效果下降是必然的。
如何解决这个问题?如何只保留1份参数,但又能计算出128个不同的注意力分布呢?
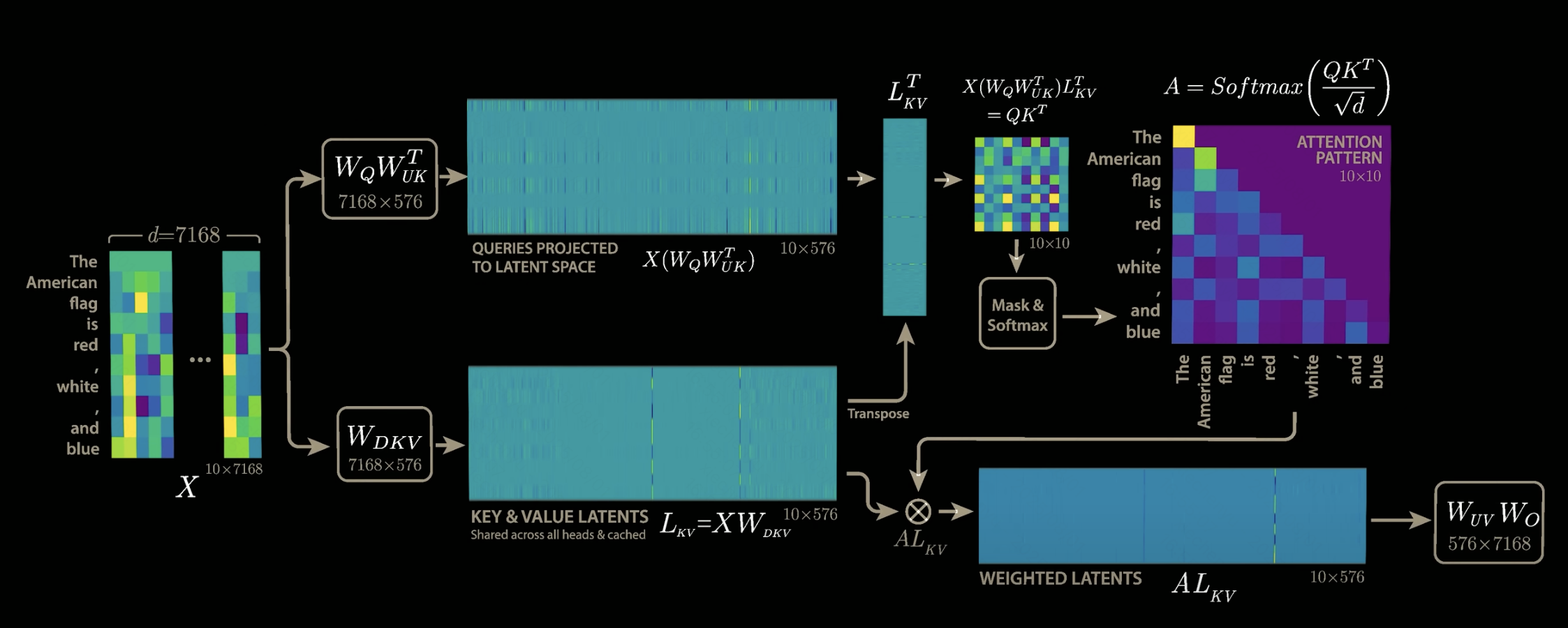
MLA给出的答案是,只保留原本128分参数中共有的部分,而每份参数独有的部分则提取出来,不进行保存。
这里就碰到了MLA第一个比较难理解的点,就是怎么找出128个W_K的共有部分和独有部分?(只以K为例,V也是一样的)
答案是不用去找,而是从一开始就用两个矩阵,分别去学习共有部分和独有部分。也就是下图中的W_DKV和W_UK,其中W_DKV学习共有部分,W_UK学习独有部分。也就是说128个注意力头,会共用W_DKV,但是每个注意力头的W_UK是独有的,这样保证了128个注意力头能计算出128个不同的注意力分布。
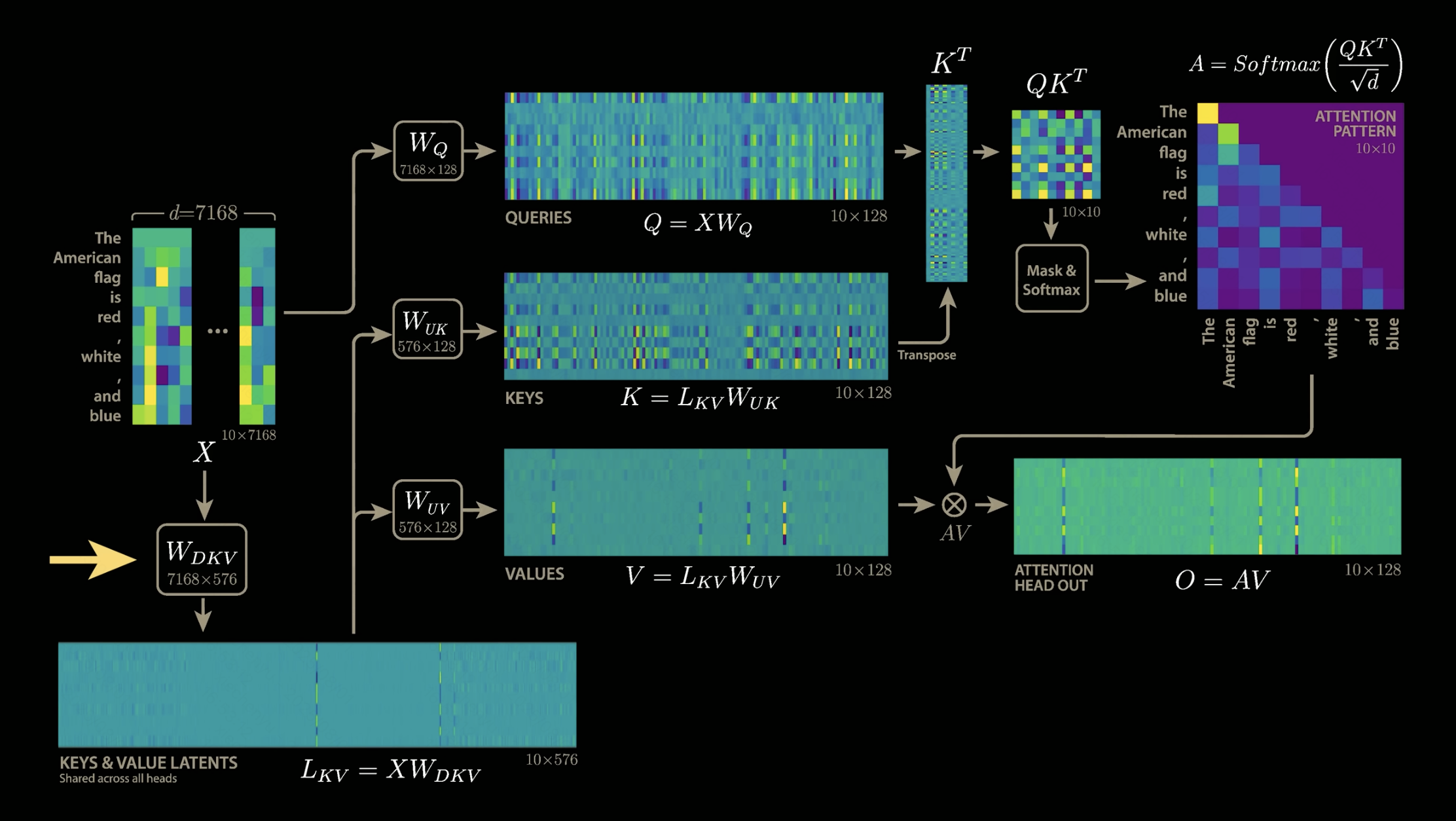
这里就会碰到MLA第二个比较难理解的点,为什么最后kv-cache只用保存L_KV,而不用保存K和V?
答案是根本就不存在K和V,MLA很巧妙的利用矩阵乘法,把W_UK与W_Q融合,把W_UV和W_O融合。至于为什么能这样做,可以从公式中找出答案。
说不存在W_UK和W_UV其实并不严谨,但是这样可以更方便去理解,其实这里所谓的把W_UK与W_Q融合是指输入先经过W_Q,紧跟着就经过W_UK,从结果上来看,跟先把W_UK与W_Q相乘得到W_QUK,然后输入经过W_QUK的效果是一样的。
原本,加入W_DKV后,注意力的计算公式为:
按照矩阵运算,上述公式可以写成下述形式:
我们完全可以将视作一个矩阵
,它和W_Q并没有什么本质区别,只是维度需要调整(当然实际实现上还是两个矩阵,分开来学习)。从上式中,我们发现注意力计算公式中的K消失了。
然后是最终输出O的计算:
同理,这样就能把W_V融进W_O中,我们能够发现,最终输出的计算公式中,V也消失了。
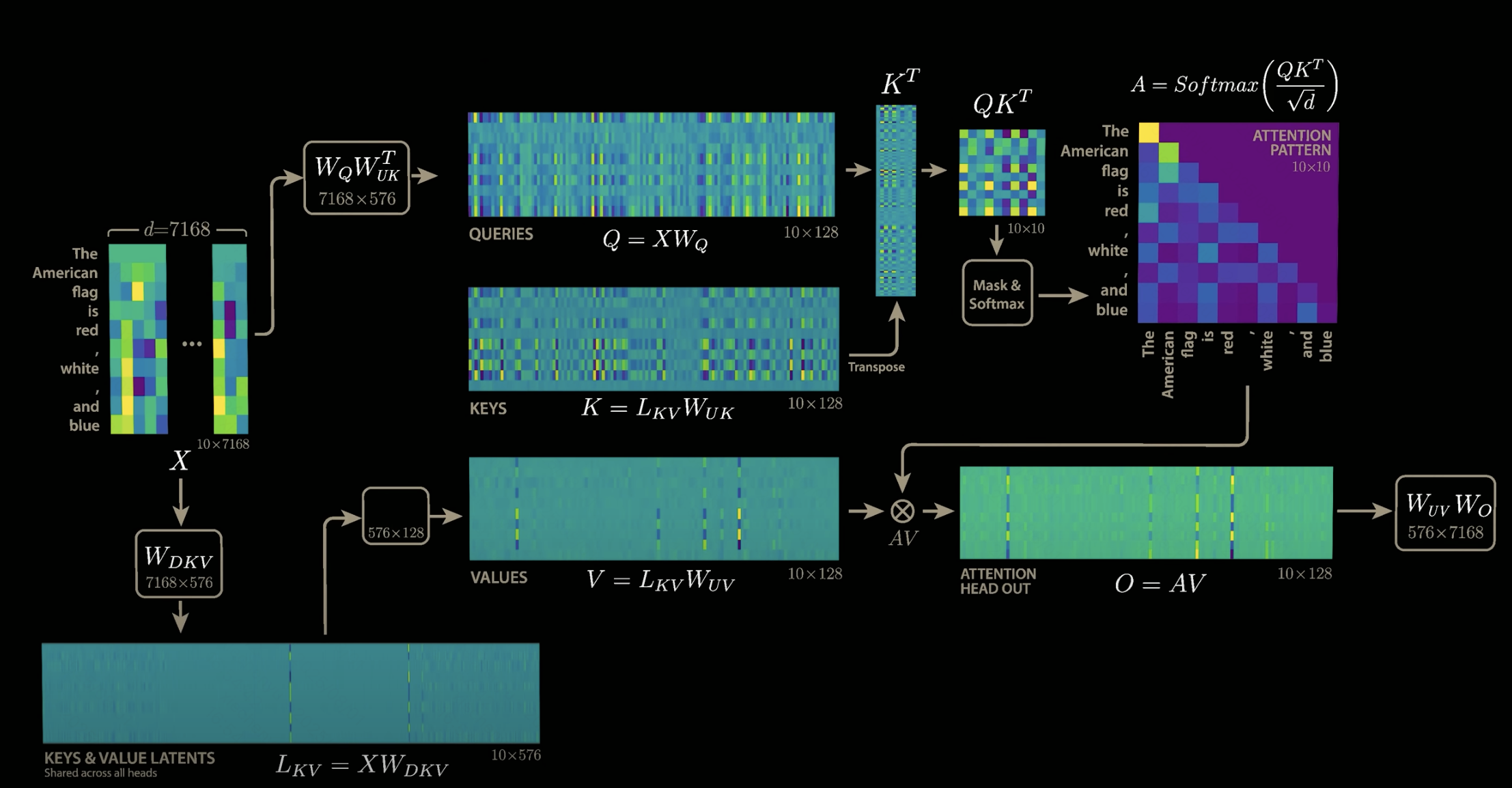
最后的效果如下图,我们需要保存的只有L_KV,它是128个注意力头共用的,所以只需要保存一份,存储开销计算如下,整个计算公式中完全不需要考虑注意力头数目:
开销降低40/0.7,约57倍,也就是deepseek技术报告中公布的压缩倍数。