凸优化:常见的优化问题,偏统计视角
凸优化问题
概述
- 优化问题的一般描述
- 可微函数的一阶最优准则
- 线性规划(例如基追踪,Dantzig变量选择,Chebyshev不等式)
- 二次优化(例如最小二乘,LASSO,岭回归,投资组合,支持向量机)
- 半定规划(例如低秩矩阵恢复)
优化问题的描述
一个优化问题可以如下表示:
min f(x)s.t. gi(x)≤0,i=1,...,mhi(x)=0,i=1,...,p \begin{aligned} \min\ &f(x)\\ \text{s.t.}\ &g_i(x)\le 0,\quad i=1,...,m\\ & h_i(x)= 0,\quad i=1,...,p \end{aligned} min s.t. f(x)gi(x)≤0,i=1,...,mhi(x)=0,i=1,...,p
- fff是目标函数
- 优化问题的定义域:
D=domf ∩ ⋂i=1mdom gi ∩ ⋂i=1pdom hiD=\text{dom}f\ \cap\ \bigcap_{i=1}^{m} \text{dom}\ g_i\ \cap\ \bigcap_{i=1}^{p} \text{dom}\ h_iD=domf ∩ i=1⋂mdom gi ∩ i=1⋂pdom hi
当x∈Dx\in Dx∈D,称xxx是可行的,所有可行点的集合称为可行集(域)(当优化问为凸优化问题时,其为凸集,因为凸函数的定义域及其下水平集是凸集,而凸集的交集为凸集)
-
在可行域上,f(x)f(x)f(x)的最小值称作最优值,记作f⋆f^\starf⋆
-
若x⋆∈Dx^\star \in Dx⋆∈D,并且f(x⋆)=f⋆f(x^\star)=f^\starf(x⋆)=f⋆,称x⋆x^\starx⋆为最优解。注意,最优解可能不止一个,所有最优点构成的集合称作为最优集
-
若xxx是可行的,且满足f(x)≤f⋆+ϵf(x)\le f^\star + \epsilonf(x)≤f⋆+ϵ,称xxx是ϵ−\epsilon-ϵ−次优解
-
若存在R>0R>0R>0,使得可行点xxx对所有可行的yyy,在满足∥x−y∥≤R\|x-y\|\le R∥x−y∥≤R时,有f(x)≤f(y)f(x)\le f(y)f(x)≤f(y),此时称xxx为局部最优解
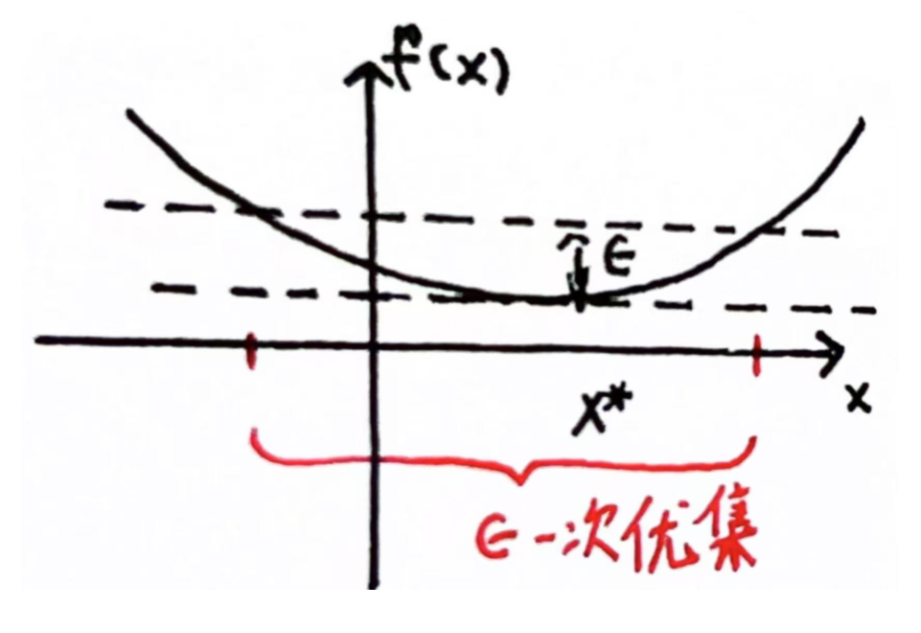
可微函数fff的最优性准则(一阶)
对于一个目标函数可微的凸优化问题:
minf(x),s.t. x∈D\min f(x),\quad s.t.\ x\in Dminf(x),s.t. x∈D
其中DDD为可行集,当且仅当可行点x⋆x^\starx⋆满足∇fT(x⋆)(y−x⋆)≥0,∀y∈D\nabla f^T(x^\star)(y-x^\star)\ge 0,\quad \forall y\in D∇fT(x⋆)(y−x⋆)≥0,∀y∈D,称x⋆x^\starx⋆为最优解。
对于无约束优化,上述最优性条件可化简为:
∇f(x⋆)=0\nabla f(x^\star)=0∇f(x⋆)=0
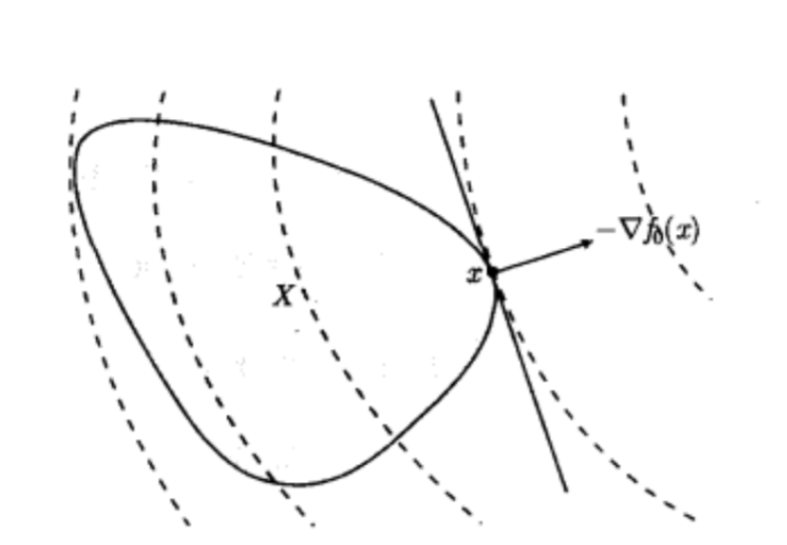
备注:
虚线为目标函数f0f_0f0的等值曲线(三维就是地图上常见的等高线),从支撑超平面的角度来看,−∇f(x⋆)-\nabla f(x^\star)−∇f(x⋆)在x⋆x^\starx⋆处定义了可行集的一个支撑超平面,也是该函数值下降的最速方向。
凸优化问题
当f,gi,i=1,...,mf,g_i,i=1,...,mf,gi,i=1,...,m都是凸函数,等式约束是仿射约束(仿射函数既是凸函数也是凹函数),即hi(x)=aiTx−bi,i=1,...,ph_i(x)=a^T_ix-b_i,i=1,...,phi(x)=aiTx−bi,i=1,...,p,上述优化问题是凸优化问题。对于凸优化问题,局部最小值,即是全局最小值。
备注:
一个凸优化问题是在一个凸集上极小化一个凸函数。
线性规划(目标和约束都是仿射函数)
一般形式的线性规划问题如下:
min cTx+ds.t. Gx⪯hAx=b \begin{aligned} \min\ &c^Tx+d\\ \text{s.t.}\ &Gx\preceq h\\ & Ax=b \end{aligned} min s.t. cTx+dGx⪯hAx=b
其中x∈Rnx\in R^nx∈Rn是决策变量,G∈Rm×n,A∈Rp×nG\in R^{m\times n},A\in R^{p\times n}G∈Rm×n,A∈Rp×n
备注:
截距d可以省略
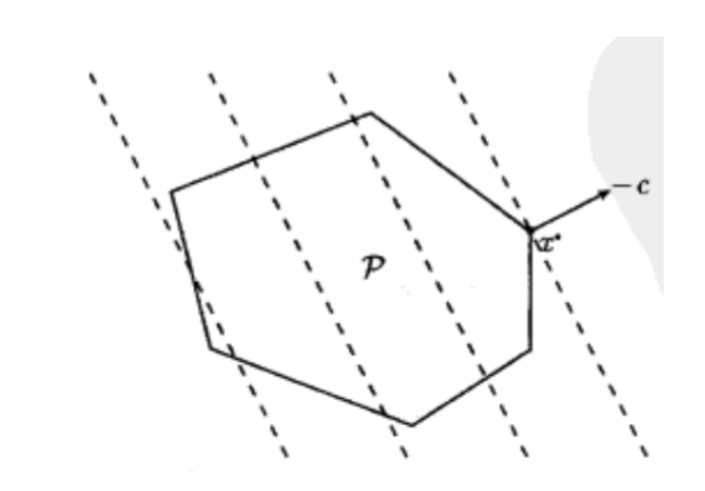
此外线性规划还有以下两种常见变化形式:
- 不等式约束仅为决策变量的非负约束,又称之为标准形式
min cTxs.t. x⪰0Ax=b \begin{aligned} \min\ &c^Tx\\ \text{s.t.}\ &x\succeq 0\\ & Ax=b \end{aligned} min s.t. cTxx⪰0Ax=b
- 引入松弛变量sis_isi,将一般线性规划转换为标准形式的线性规划
min cTxs.t. Gx+s=hAx=bs⪰0 \begin{aligned} \min\ &c^Tx\\ \text{s.t.}\ &Gx+s= h\\ & Ax=b\\ &s\succeq 0 \end{aligned} min s.t. cTxGx+s=hAx=bs⪰0
接着可以将xxx表示成正部x+⪰0x^+\succeq 0x+⪰0和负部x−⪰0x^-\succeq0x−⪰0,即x=x+−x−,∣x∣=x++x−x=x^+-x^-,|x|=x^++x^-x=x+−x−,∣x∣=x++x−,
min cTx+−cTx−s.t. Gx+−Gx−+s=hAx+−Ax−=bs⪰0,x+⪰0,x−⪰0 \begin{aligned} \min\ &c^Tx^+-c^Tx^-\\ \text{s.t.}\ &Gx^+-Gx^-+s= h\\ & Ax^+-Ax^-=b\\ &s\succeq 0,x^+\succeq 0,x^-\succeq0 \end{aligned} min s.t. cTx+−cTx−Gx+−Gx−+s=hAx+−Ax−=bs⪰0,x+⪰0,x−⪰0
示例
基追踪(压缩感知中的一个问题)
给定y∈Rn,X∈Rn×py\in R^n,X\in R^{n\times p}y∈Rn,X∈Rn×p,其中p>np>np>n,寻求欠定线性系统Xβ=yX\beta=yXβ=y的稀疏解
minβ∥β∥0subject toXβ=y \begin{aligned} &\min_{\large\beta}&&\|\beta\|_0\\ &\mathrm{subject~to}&&X\beta=y \end{aligned} βminsubject to∥β∥0Xβ=y
由于0范数不是凸函数,原问题非凸,为此可以用l1l_1l1范数近似0范数,此问题称为基追踪问题
minβ∥β∥1subject toXβ=y \begin{aligned} &\min_{\large\beta}&&\|\beta\|_1\\ &\mathrm{subject~to}&&X\beta=y \end{aligned} βminsubject to∥β∥1Xβ=y
为了将其转换为线性规划问题,引入新的变量z∈Rpz\in R^pz∈Rp,使得每个∣βi∣|\beta_i|∣βi∣都对应一个ziz_izi,那么原问题可改写如下:
minβ,z1Tzsubject toz≥βz≥−βXβ=y \begin{aligned} &\min_{\beta,z}&&1^Tz\\ &\mathrm{subject~to}&&z\geq\beta\\ &&&z\geq-\beta\\ &&&X\beta=y \end{aligned} β,zminsubject to1Tzz≥βz≥−βXβ=y
即写成了标准的线性规划形式。
Dantzig 变量选择
现在允许不精确的等式约束Xβ≈yX\beta\approx yXβ≈y,Dantzig 变量选择:
minβ∥β∥1subject to∥XT(y−Xβ)∥∞≤λ \begin{aligned} &\min_{\large\beta}&&\|\beta\|_1\\ &\mathrm{subject~to}&&\|X^T(y-X\beta)\|_\infty\leq\lambda \end{aligned} βminsubject to∥β∥1∥XT(y−Xβ)∥∞≤λ
其中λ≥0\lambda\ge 0λ≥0是一个惩罚参数,该约束刻画了特征与残差的相关性,使得解的特征不过度解释残差。并且该约束是LASSO对偶问题的KKT条件,该解也确保了解的稀疏性。按照上述改写成线性规划问题:
minz1Tzsubject toz≥βz≥−β−λ1≤XT(y−Xβ)≤λ1 \begin{aligned} &\min_{z}&&1^Tz\\ &\mathrm{subject~to}&&z\geq\beta\\ &&&z\geq-\beta\\ &&&-\lambda\mathbf{1}\le X^T(y-X\beta)\le \lambda\mathbf{1} \end{aligned} zminsubject to1Tzz≥βz≥−β−λ1≤XT(y−Xβ)≤λ1
转换成线性规划问题方便求解。
Chebyshev不等式
考虑离散型随机变量XXX的概率分布:Pi=P(X=ui), i=1,...,nP_i=P(X=u_i),\ i=1,...,nPi=P(X=ui), i=1,...,n,因此由该离散型随机变量概率分布组成的向量满足P⪰0,1TP=1P\succeq 0,\mathbf{1}^TP=1P⪰0,1TP=1。设uiu_iui是固定且已知的,但分布PPP未知,若函数fff是XXX的函数(默认是可测函数),则Ef=∑i=1nf(ui)×PiEf=\sum_{i=1}^nf(u_i)\times P_iEf=∑i=1nf(ui)×Pi,是关于PPP的线性函数,若SSS是RRR的子集,那么P(X∈S)=∑ui∈SPiP(X\in S)=\sum_{u_i\in S}P_iP(X∈S)=∑ui∈SPi也是PPP的线性函数。尽管PPP未知,假设知道XXX的函数期望的上下界:
αi≤aiTP≤βi, i=1,...,m\alpha_i\le a_i^TP\le \beta_i,\ i=1,...,mαi≤aiTP≤βi, i=1,...,m
此时求Ef0(x)=a0TPEf_0(x)=a_0^TPEf0(x)=a0TP的下界:
minPa0TPsubject toP⪰0,1TP=1αi≤aiTP≤βi, i=1,...,m \begin{aligned} &\min_{\large P}&&a_0^TP\\ &\mathrm{subject~to}&&P\succeq0,\mathbf{1}^TP=1\\ &&&\alpha_i\le a_i^TP\le \beta_i,\ i=1,...,m \end{aligned} Pminsubject toa0TPP⪰0,1TP=1αi≤aiTP≤βi, i=1,...,m
该问题给出满足约束下,Ef0(x)Ef_0(x)Ef0(x)取得最小值时的分布PPP。
二次优化
二次优化(QP)问题的描述如下:
minx(1/2)xTPx+qTx+rsubject toGx⪯hAx=b \begin{aligned} &\min_{\large x}&&(1/2)x^TPx+q^Tx+r\\ &\mathrm{subject~to}&& Gx\preceq h\\ &&& Ax=b \end{aligned} xminsubject to(1/2)xTPx+qTx+rGx⪯hAx=b
其中目标函数是优化变量的二次型,P∈S+nP\in S^n_+P∈S+n。
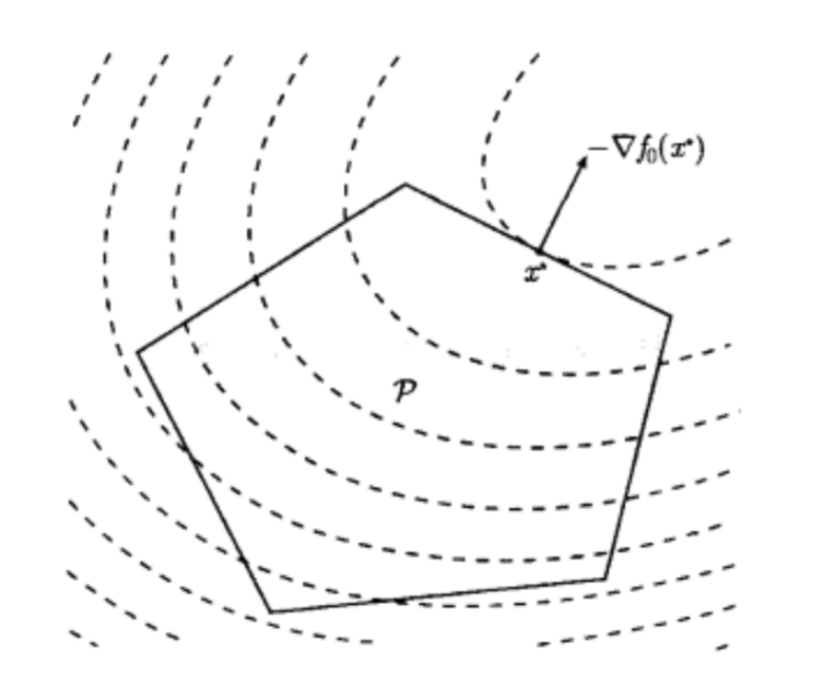
当不等式约束为也为优化变量的二次型时,称之为二次约束二次规划(QCQP)
subject to(1/2)xTPix+qiTx+ri≤0, i=1,...,mAx=b \begin{aligned} &\mathrm{subject~to}&& (1/2)x^TP_ix+q_i^Tx+r_i\le 0,\ i=1,...,m\\ &&& Ax=b \end{aligned} subject to(1/2)xTPix+qiTx+ri≤0, i=1,...,mAx=b
其中Pi∈S+n, i=1,...,mP_i\in S^n_+,\ i=1,...,mPi∈S+n, i=1,...,m。
示例
最小二乘
minβ∥y−Xβ∥22=βTXTXβ−2yTXβ+yTy\min_{\large \beta}\|y-X\beta\|_2^2=\beta^TX^TX\beta-2y^TX\beta+y^Tyβmin∥y−Xβ∥22=βTXTXβ−2yTXβ+yTy
当XTX⪰0X^TX\succeq 0XTX⪰0时,其是关于β\betaβ的无约束二次规划问题。可以对优化变量增加约束,有约束最小二乘
minβ∥y−Xβ∥22subject toli≤βi≤ui,i=1,...,p \begin{aligned} &\min_{\large \beta}&&\|y-X\beta\|_2^2\\ &\mathrm{subject~to}&& l_i\le\beta_i\le u_i,\quad i=1,...,p \end{aligned} βminsubject to∥y−Xβ∥22li≤βi≤ui,i=1,...,p
LASSO
给定y∈Rn,X∈Rn×py\in R^n,X\in R^{n\times p}y∈Rn,X∈Rn×p,LASSO问题描述如下:
minβ∥y−Xβ∥22subject to∥β∥1≤s \begin{aligned} &\min_{\large\beta}&&\|y-X\beta\|_2^2\\ &\mathrm{subject~to}&&\|\beta\|_1\leq s \end{aligned} βminsubject to∥y−Xβ∥22∥β∥1≤s
表示成等价的惩罚形式:
minβ12∥y−Xβ∥22+λ∥β∥1\min_\beta\frac{1}{2}\|y-X\beta\|_2^2+\lambda\|\beta\|_1βmin21∥y−Xβ∥22+λ∥β∥1
引入β\betaβ的正部β+\beta^+β+和负部β−\beta^-β−,得到:
minβ+,β−12∥y−Xβ++Xβ−∥22+λ1Tβ++λ1Tβ−subject toβ+,β−≥0 \begin{aligned} &\min_{\beta^+,\beta^-}&&\frac{1}{2}\|y-X\beta^+ +X\beta^-\|_2^2+\lambda\mathbf{1}^T\beta^++\lambda\mathbf{1}^T\beta^-\\ &\mathrm{subject~to}&&\beta^+,\beta^-\ge 0 \end{aligned} β+,β−minsubject to21∥y−Xβ++Xβ−∥22+λ1Tβ++λ1Tβ−β+,β−≥0
岭回归
可化简成二次约束的二次优化问题。
投资组合
现有nnn种待投资的资产,令xix_ixi表示一定时期内持有资产iii的数量(美元),pip_ipi为第iii个资产相对之前一个时期内的相对价格变动,p∈Rnp\in R^np∈Rn为随机变量,均值向量pˉ\bar{p}pˉ和协方差Σ\SigmaΣ已知,那么有一种投资策略,在极小化总的风险(Cov(xTp)=xTΣxCov(x^Tp)=x^T\Sigma xCov(xTp)=xTΣx)的同时,保证一定的收益即可如下转换为二次规划问题:
minxxTΣxsubject topˉTx≥rmin(表示平均收益下限)1Tx=B(表示投资总额)x≥0 \begin{aligned} &\min_{x}&&x^T\Sigma x\\ &\mathrm{subject~to}&&\bar{p}^Tx\ge r_{\min}(\text{表示平均收益下限})\\ &&&\mathbf{1}^Tx=B(\text{表示投资总额})\\ &&&x\ge 0 \end{aligned} xminsubject toxTΣxpˉTx≥rmin(表示平均收益下限)1Tx=B(表示投资总额)x≥0
支持向量机
给定数据点y∈{−1,1}n,X∈Rn×py\in \{-1,1\}^n,X\in R^{n\times p}y∈{−1,1}n,X∈Rn×p,支持向量机问题可以描述如下:
minβ,β0,ξ12∥β∥22+C∑i=1nξisubject toξi≥0,i=1,…,nyi(xiTβ+β0)≥1−ξi,i=1,…,n \begin{aligned} &\min_{\beta,\beta_0,\xi}&&\frac{1}{2}\|\beta\|_2^2+C\sum_{i=1}^n\xi_i\\ &\mathrm{subject~to}&&\xi_i\geq0,i=1,\ldots,n\\ &&&y_i(x_i^T\beta+\beta_0)\geq1-\xi_i,i=1,\ldots,n \end{aligned} β,β0,ξminsubject to21∥β∥22+Ci=1∑nξiξi≥0,i=1,…,nyi(xiTβ+β0)≥1−ξi,i=1,…,n
其中ξi\xi_iξi为松弛变量,允许有误分点,但是误分点不宜太多,因此用∑i=1nξi\sum_{i=1}^n \xi_i∑i=1nξi控制误分程度。很明显上述问题也是一个二次规划问题。
半定规划
半定规划是线性规划在矩阵空间中通过广义不等式的推广。目标函数和约束函数均是关于矩阵的线性函数。
备注:
由于是在正常锥中定义的广义不等式,半定规划也是锥规划中正常锥取作S+nS^n_+S+n的特例。
其一般形式如下:
minxcTxsubject tox1F1+⋯+xnFn⪯F0Ax=b \begin{aligned} &\min_x&&c^Tx\\ &\mathrm{subject~to}&&x_1F_1+\cdots+x_nF_n\preceq F_0\\ &&&Ax=b \end{aligned} xminsubject tocTxx1F1+⋯+xnFn⪯F0Ax=b
其中Fj∈Sn,j=0,...,nF_j\in S^n,j=0,...,nFj∈Sn,j=0,...,n,A∈Rm×n,c∈Rn,b∈RmA\in R^{m\times n}\mathrm{,}c\in R^n\mathrm{,}b\in R^mA∈Rm×n,c∈Rn,b∈Rm,
当Fj,j=0,...,nF_j,j=0,...,nFj,j=0,...,n为对角矩阵时,其退化为一般线性规划问题。对比线性规划的标准型,可通过如下构造得到半定规划的标准型:
引入松弛变量SSS,将半定规划的线性矩阵不等式转换为等式
S=F0−∑i=1nxiFi,S⪰0S=F_0-\sum_{i=1}^nx_iF_i,\quad S\succeq0S=F0−i=1∑nxiFi,S⪰0
将原始变量xxx和松弛变量SSS组合成一个更大的半正定矩阵。
X=(diag(x)00S),X⪰0X=\begin{pmatrix}\operatorname{diag}(x)&0\\0&S\end{pmatrix},\quad X\succeq0X=(diag(x)00S),X⪰0
设
C=(diag(c)000)C=\begin{pmatrix}\mathrm{diag}(c)&0\\0&0\end{pmatrix}C=(diag(c)000)
使得原目标函数可以转换为:
C⋅X=cTxC\cdot X=c^TxC⋅X=cTx
其中C⋅X=Tr(CXT)C\cdot X=Tr(CX^T)C⋅X=Tr(CXT)表示矩阵内积。
再来看线性等式约束的转换,设AAA的第iii行为aiTa_i^TaiT,构造如下矩阵AiA_iAi:
Ai=(diag(ai)000),Ai⋅X=aiTx=biA_i=\begin{pmatrix}\operatorname{diag}(a_i)&0\\0&0\end{pmatrix},\quad A_i\cdot X=a_i^Tx=b_iAi=(diag(ai)000),Ai⋅X=aiTx=bi
综上可得到半定规划的标准形式:
minX<C,X>subject to<Ai,X>=bi, i=1,...,mX⪰0 \begin{aligned} &\min_X&&<C,X>\\ &\mathrm{subject~to}&&<A_i,X>=b_i,\ i=1,...,m\\ &&&X\succeq 0 \end{aligned} Xminsubject to<C,X><Ai,X>=bi, i=1,...,mX⪰0
示例
低秩矩阵恢复
现实生活中电影评级的缺失矩阵恢复可以看作是一类低秩矩阵恢复问题。假定一个矩阵MMM,其中行变量为用户,列变量为各种电影。其中元素Mi,jM_{i,j}Mi,j是第i个用户对第j部电影的评分。显然当待评分电影较多时,不可能所有人都看完了全部的电影并评分,因此评分矩阵MMM中会有较多的缺失值。为了预测这些缺失值,可以这样考虑,首先记MMM中所有非缺失元素元素下角标的集合为Ω\OmegaΩ,再假定用来恢复的矩阵XXX,当MMM中第(i,j)(i,j)(i,j)个元素未缺失时,令Xi,j=Mi,jX_{i,j}=M_{i,j}Xi,j=Mi,j,显然满足该条件的矩阵XXX有很多个,可以再作如下假定,假设两部电影类型相似,他们收获的评分也会相似,此时MMM不是列满秩。同理,假设两个用户喜欢看相同类型的电影,他们对各电影的评分也会相似,此时MMM不是行满秩。综上,MMM中可能存在低秩结构,因此寻找一个低秩矩阵XXX近似(恢复)MMM是比较合适的:
minX∈Rm×nrank(X)subject toXij=Mij,(i,j)∈Ω \begin{aligned} &\min_{X\in R^{m\times n}}&&\operatorname{rank}(X)\\ &\mathrm{subject~to}&&X_{ij}=M_{ij},(i,j)\in\Omega \end{aligned} X∈Rm×nminsubject torank(X)Xij=Mij,(i,j)∈Ω
由于目标秩不是凸函数,是一个NP难的问题,类比稀疏优化中将l0l_0l0范数用l1l_1l1范数近似,而rank(X)也表示矩阵X中非零奇异值个数。因此这里可以将目标函数用XXX的核范数近似,∥X∥∗=∑iσi(X)\|X\|_*=\sum_{i}\sigma_i(X)∥X∥∗=∑iσi(X),矩阵XXX奇异值的和。
minX∈Rm×n∥X∥∗subject toXij=Mij,(i,j)∈Ω \begin{aligned} &\min_{X\in R^{m\times n}}&&\|X\|_*\\ &\mathrm{subject~to}&&X_{ij}=M_{ij},(i,j)\in\Omega \end{aligned} X∈Rm×nminsubject to∥X∥∗Xij=Mij,(i,j)∈Ω
接下来尽可能转换为半定规划的形式(转换为标准形式较复杂,略)。对于(i,j)∈Ω(i,j)\in\Omega(i,j)∈Ω,定义Ak∈Rm×nA_k\in R^{m\times n}Ak∈Rm×n,其第(l,m)(l,m)(l,m)个元素如下:
(Ak)lm={1当(l,m)=(i,j)0其他(A_k)_{lm}=\begin{cases}1&\text{当}(l,m)=(i,j)\\0&\text{其他}\end{cases}(Ak)lm={10当(l,m)=(i,j)其他
因此有:
Ak∙X=tr(AkTX)=XijA_k\bullet X=\operatorname{tr}(A_k^TX)=X_{ij}Ak∙X=tr(AkTX)=Xij
原等式约束可写作如下形式:
A(X)=(A1∙X⋮Ap∙X)=(Mi1j1⋮Mipjp)=bA(X)=\begin{pmatrix}A_1\bullet X\\\vdots\\A_p\bullet X\end{pmatrix}=\begin{pmatrix}M_{i_1j_1}\\\vdots\\M_{i_pj_p}\end{pmatrix}=bA(X)=A1∙X⋮Ap∙X=Mi1j1⋮Mipjp=b